Datadog AI 보고서, 에이전트 장애의 60%는 rate limit
Datadog의 2026 AI Engineering 보고서는 production LLM 오류의 다수가 rate limit에서 시작된다고 봅니다. 운영 병목과 대응책을 짚습니다.

- 무슨 일: Datadog이 State of AI Engineering 2026에서 production LLM telemetry 기반 운영 데이터를 공개했습니다.
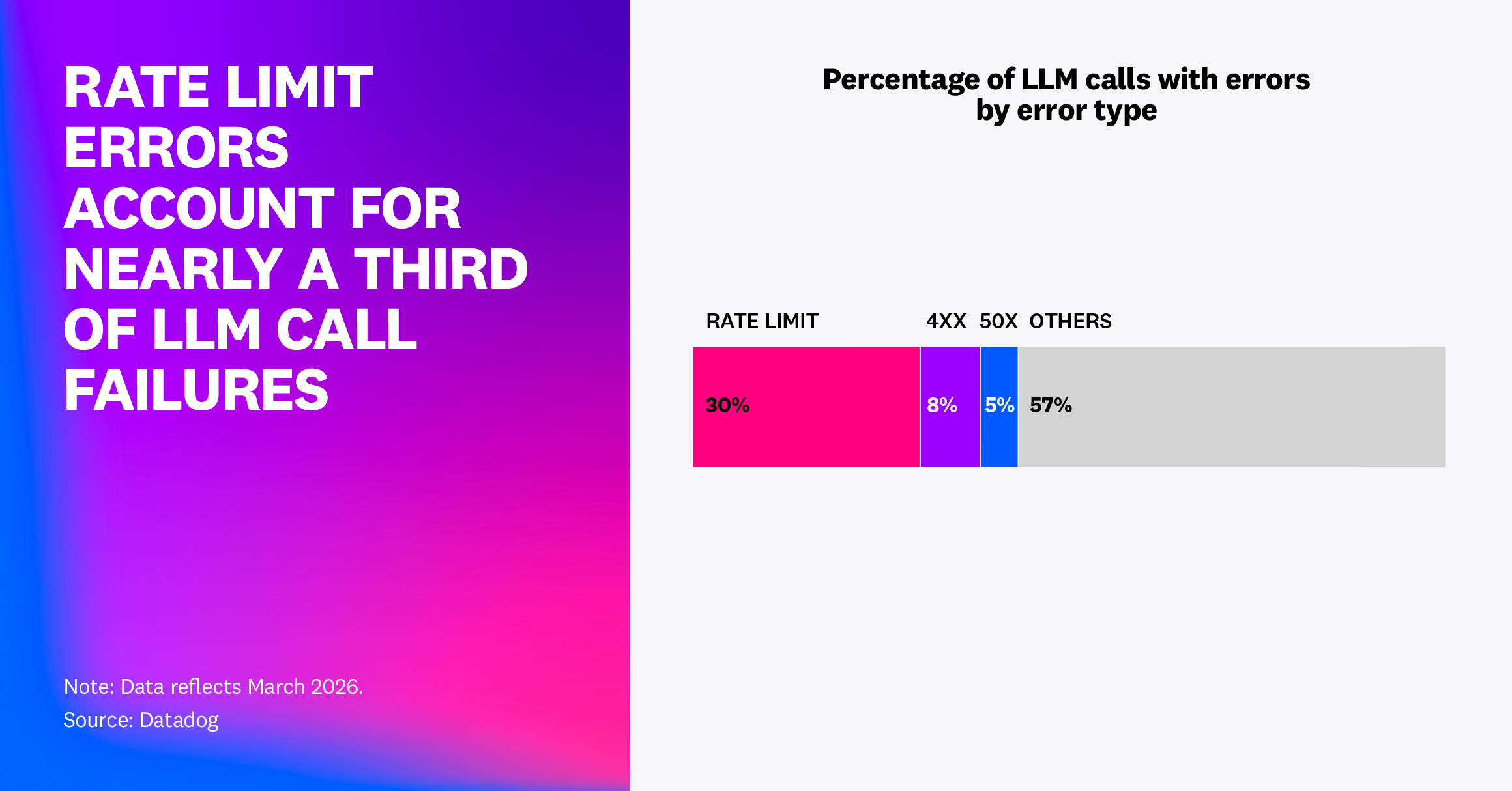
- 2026년 2월 LLM call span의 5%가 error였고, 그중 60%는 rate limit 초과였습니다.
- 의미: agent 장애는 모델 품질만이 아니라 quota, fallback, prompt cache, context size 같은 운영 변수에서 시작됩니다.
- 실무 영향: AI 팀은 model router, backpressure, per-tool budget을 서비스 SLO와 함께 봐야 합니다.
- Datadog은 조직의 70% 이상이 3개 이상 모델을 쓰고, prompt caching span은 지원 모델 호출의 28%에 그친다고 봤습니다.
Datadog이 공개한 State of AI Engineering 2026 보고서는 모델 순위표가 아니라 production telemetry 보고서입니다. 보도자료는 2026년 4월 21일에 나왔고, 보고서 본문은 Datadog LLM Observability product에서 수집한 고객 metrics와 metadata를 바탕으로 작성됐다고 설명합니다. 숫자가 말하는 가장 직접적인 사건은 오류입니다. 2026년 2월 LLM call span의 5%가 error를 보고했고, 그 error의 60%는 rate limit 초과였습니다.
이 수치는 AI 에이전트 운영팀에 불편합니다. 모델이 답을 틀리는 문제는 eval과 prompt engineering으로 설명하기 쉽습니다. 그러나 rate limit은 capacity planning, retry, queue, fallback provider, budget allocation 문제입니다. 에이전트가 여러 tool을 호출하고, 같은 작업 안에서 모델 호출을 반복하고, 실패하면 다시 계획을 세우는 구조라면 quota 초과는 사용자에게 "잠시 후 다시 시도"보다 복잡한 장애로 보입니다.
 .
.
Datadog은 2026년 3월에는 전체 LLM span error rate가 2%였고, rate limit error가 거의 3분의 1이었다고 적었습니다. 절대량으로는 약 840만 건에 가깝습니다. 2%라는 평균만 보면 낮아 보일 수 있습니다. 그러나 에이전트 요청 하나가 여러 모델 호출과 tool call로 구성될 때 span 단위 error는 request 단위 장애로 증폭됩니다. 사용자가 보는 것은 한 span의 실패가 아니라 "작업이 멈췄다"는 결과입니다.
보고서의 두 번째 단서는 multi-model입니다. Datadog은 2026년 3월 OpenAI의 provider share가 63%로 여전히 가장 크다고 설명합니다. 동시에 Google Gemini와 Anthropic Claude의 share는 2025년 같은 시점 대비 각각 20, 23 percentage point 증가했습니다. 조직의 70% 이상은 3개 이상 모델을 사용합니다. AI 제품이 한 모델에 붙어 있지 않고, provider portfolio를 운영하는 단계로 넘어갔다는 뜻입니다.
여기서 model router는 편의 기능이 아니라 장애 대응 장치가 됩니다. 특정 provider가 rate limit을 반환하면 다른 provider, 더 작은 모델, cached answer, degraded workflow 중 하나로 내려가야 합니다. Datadog은 OpenRouter를 예시로 들며 2025년 1월 두 달도 되지 않아 downstream provider보다 3.5배 많은 request를 처리했다고 적었습니다. routing layer가 model selection UI를 넘어 capacity abstraction 역할을 맡기 시작한 사례입니다.
다만 다중 모델은 새 복잡도를 만듭니다. 같은 prompt라도 provider마다 tokenization, tool calling schema, safety policy, latency, caching 조건이 다릅니다. fallback을 붙였다고 같은 품질의 응답이 보장되지 않습니다. 운영팀은 "주 모델이 막히면 보조 모델로 보낸다"에서 멈추면 안 됩니다. retry 횟수, user-visible degradation, tool write permission, output validation, 비용 cap을 함께 정의해야 합니다.
Datadog의 세 번째 단서는 context입니다. 보고서는 median 고객의 request token 평균이 1년 동안 두 배 이상 늘었고, 90th percentile power user에서는 네 배 증가했다고 설명합니다. 또 customer traces의 input token 중 69%가 system prompt라고 적었습니다. 많은 AI 앱의 비용과 지연이 사용자 질문보다 시스템 지시문, policy, tool description, retrieval context에서 생긴다는 뜻입니다.
이 숫자는 에이전트 제품에서 더 무겁습니다. 에이전트는 단순 Q&A보다 긴 system prompt를 갖습니다. tool 사용 규칙, 권한 경계, 출력 형식, 실패 처리, 회사 정책, domain glossary를 모두 넣기 쉽습니다. 여기에 대화 기록과 retrieved documents가 붙으면 context window는 빠르게 커집니다. 모델이 길어진 context를 처리할 수 있어도, latency와 비용과 cache miss는 별도 문제로 남습니다.
Prompt caching 수치도 낮습니다. Datadog은 prompt caching을 지원하는 모델의 LLM call span 중 cached-read input token이 있는 비율이 28%라고 봤습니다. 즉 대다수 호출은 caching 이점을 얻지 못했습니다. cache가 동작하려면 system prompt와 긴 prefix가 안정적으로 반복되어야 하고, provider별 caching 조건을 맞춰야 합니다. prompt를 매 요청마다 동적으로 조립하면 좋은 모델을 써도 비용 절감 효과가 줄어듭니다.
AI 팀이 이 보고서에서 바로 가져갈 작업은 prompt를 기능별 artifact로 관리하는 것입니다. system prompt를 코드 문자열로만 두면 변경 이력과 cache impact를 보기 어렵습니다. prompt version, static prefix, dynamic slot, tool schema, retrieval budget을 나눠야 합니다. 긴 정책 문구를 매번 넣는 대신 tool permission과 middleware로 빼낼 수 있는 부분도 찾아야 합니다.
Datadog은 agent framework adoption도 추적했습니다. Agent framework를 쓰는 organization 비율은 2025년 초 9%를 조금 넘었고, 2026년 초에는 거의 18%가 됐습니다. framework를 쓰는 service 수도 두 배 이상으로 늘었습니다. 이 숫자는 LangChain, LangGraph, Pydantic AI, Vercel AI SDK 같은 orchestration layer가 production AI에서 실험 도구를 넘어 운영 단위로 들어가고 있음을 보여줍니다.
Framework adoption이 늘어도 agentic request가 항상 복잡한 것은 아닙니다. Datadog은 agentic application request 중 59%가 service call 1회만 수행했고, 3회 이상 service call은 18%였다고 설명합니다. 이름은 agent지만 많은 production workflow는 아직 single-step automation에 가깝습니다. 이 결과는 "에이전트가 아직 과장됐다"는 뜻이 아니라, production 팀이 multi-step autonomy를 조심스럽게 열고 있다는 증거로 읽는 편이 안전합니다.
한 번의 service call만 하는 agent도 운영상 agent일 수 있습니다. 입력을 해석하고, tool을 고르고, permission을 검사하고, structured output을 만들면 기존 API handler보다 더 많은 관측 지점이 필요합니다. 다만 Datadog 수치는 장기 실행 agent를 설계할 때 baseline을 제공합니다. 대부분의 request가 single-step이라면, 먼저 그 경로의 latency, cost, error budget을 안정화하고 multi-step flow에는 더 엄격한 cap을 두는 방식이 맞습니다.
Rate limit 문제는 여기서 다시 돌아옵니다. Multi-step agent는 rate limit을 더 빨리 소모합니다. 하나의 사용자 요청이 plan, retrieve, tool call, reflect, summarize로 이어지면 provider quota는 request 수보다 span 수에 반응합니다. 실패 후 무제한 retry를 허용하면 같은 user action이 더 많은 quota를 태웁니다. 따라서 agent runtime에는 retry policy만이 아니라 backoff, circuit breaker, queue priority, partial completion strategy가 필요합니다.
관측성도 prompt log 저장으로 끝나지 않습니다. Datadog 보고서가 span 단위로 error, provider, model, token, framework, service call을 보듯이 운영팀도 같은 차원을 가져야 합니다. 어떤 tool에서 rate limit이 많이 생기는지, 어떤 모델 fallback이 품질을 떨어뜨리는지, system prompt 변경 후 token이 얼마나 늘었는지, cache hit rate가 어떤 release에서 꺾였는지 추적해야 합니다.
보안과 compliance 팀은 rate limit을 성능 문제가 아니라 control 문제로 봐야 합니다. Provider fallback이 붙으면 같은 사용자 데이터가 다른 모델 회사로 넘어갈 수 있습니다. 긴 system prompt에는 내부 정책과 운영 절차가 포함될 수 있습니다. Agent framework가 여러 service call을 묶으면 감사 로그도 request 단위와 tool 단위로 나뉘어야 합니다. Datadog의 수치는 AI 운영이 SRE, platform engineering, security의 공통 과제가 됐다는 사실을 보여줍니다.
커뮤니티 반응도 이 방향에 가깝습니다. Reddit의 AI quality와 SRE 토론에서는 rate limit이 단순한 vendor 오류가 아니라 agent failure mode라는 지적이 나왔습니다. 일부 개발자는 multi-provider routing을 load balancer처럼 다뤄야 한다고 봤고, 다른 쪽은 fallback이 품질과 보안 정책을 흐릴 수 있다고 우려했습니다. 이 반응은 보고서의 결론과 잘 맞습니다. Production AI의 병목은 모델 선택 화면이 아니라 운영 제어면에 있습니다.
Datadog은 관측성 회사이기 때문에 보고서의 관점도 telemetry 중심입니다. 이 점은 장점과 한계를 동시에 만듭니다. 장점은 실제 production span에서 나온 error, token, framework adoption을 볼 수 있다는 점입니다. 한계는 Datadog 고객과 Datadog LLM Observability를 쓰는 워크로드에 표본이 기울 수 있다는 점입니다. 보고서 수치를 전체 AI 산업의 절대 평균으로 읽기보다, production AI가 어떤 운영 변수에서 흔들리는지를 보여주는 강한 표본으로 읽는 편이 맞습니다.
그럼에도 이 보고서가 주는 기준은 분명합니다. AI 기능을 출시한 팀은 모델 성능표만으로 운영 준비를 끝낼 수 없습니다. Rate limit budget, provider fallback, prompt cache, context growth, agent framework trace, per-tool SLO를 함께 봐야 합니다. 특히 에이전트가 고객 데이터나 내부 시스템을 쓰는 경우에는 "정답률"보다 "실패했을 때 어디서 멈추는가"가 더 먼저입니다.
다음 분기 AI 로드맵을 짜는 팀이라면 Datadog 보고서를 네 가지 질문으로 바꿀 수 있습니다. 첫째, 가장 많이 실패하는 LLM span의 원인은 무엇인가. 둘째, 주요 provider가 rate limit을 반환할 때 사용자에게 어떤 degraded path를 제공하는가. 셋째, system prompt와 tool schema가 input token의 몇 퍼센트를 차지하는가. 넷째, agent framework가 만든 trace를 기존 service trace와 함께 볼 수 있는가.
Datadog의 2026년 보고서가 보여준 사건은 AI가 production service가 됐다는 점입니다. Production service가 되면 모델은 dependency가 되고, prompt는 config가 되고, token은 비용 단위가 되고, rate limit은 장애 원인이 됩니다. 에이전트가 더 많은 일을 맡을수록 이 문장은 더 중요해집니다. AI 팀의 다음 과제는 더 똑똑한 모델을 고르는 것만이 아니라, 실패를 예측 가능한 운영 사건으로 만드는 일입니다.