2개 H100에 올라간 218B, Cohere가 던진 주권형 에이전트
Cohere Command A+는 Apache 2.0, 218B MoE, 2개 H100 실행 경로로 프라이빗 에이전트 모델 경쟁을 밀어붙입니다.

- 무슨 일: Cohere가 Command A+를 Apache 2.0 오픈소스 모델로 공개했습니다.
- 공식 발표 기준
218B total,25B active,128K입력 문맥, 이미지와 도구 호출을 지원합니다.
- 공식 발표 기준
- 핵심 숫자: W4A4 양자화 기준 2개 H100 또는 1개 B200에서 실행 가능한 경로를 제시했습니다.
- 의미: 에이전트 경쟁이 모델 점수뿐 아니라 프라이빗 배포 비용과 운영 통제권으로 내려가고 있습니다.
- 한국어 토큰 효율도 16% 개선했다고 밝혀 비영어권 엔터프라이즈 비용 문제와 직접 연결됩니다.
Cohere가 2026년 5월 20일 Command A+를 공개했습니다. 표면적으로는 또 하나의 오픈 모델 출시처럼 보입니다. 그러나 이번 발표의 후킹 포인트는 모델 이름보다 배포 조건입니다. Cohere는 Command A+를 218B 전체 파라미터의 sparse MoE 모델이라고 설명하면서도, 실제 토큰마다 활성화되는 파라미터는 25B라고 밝힙니다. 그리고 W4A4 양자화 기준으로 2개 NVIDIA H100 또는 1개 B200에서 실행 가능한 최소 경로를 제시했습니다.
이 조합이 중요한 이유는 명확합니다. 에이전트가 사내 문서, 데이터베이스, 업무 시스템, 클라우드 권한, 고객 정보에 접근하기 시작하면 "어느 모델이 가장 똑똑한가"만으로는 구매 결정을 내리기 어렵습니다. 기업은 모델이 어디에서 실행되는지, 로그와 프롬프트가 어디에 남는지, 비용이 어떤 단위로 튀는지, 내부 보안 정책과 감사 체계 안에 넣을 수 있는지를 함께 봅니다. Command A+는 바로 이 지점에서 "프런티어 클라우드 API만이 답은 아니다"라는 메시지를 냅니다.
물론 Cohere가 OpenAI나 Anthropic을 단숨에 밀어낸다는 뜻은 아닙니다. OpenAI는 Codex와 ChatGPT Enterprise, Anthropic은 Claude와 Claude Code, Google은 Gemini와 Vertex AI를 통해 모델과 제품 경험을 깊게 통합하고 있습니다. 하지만 Cohere가 이번에 강조한 단어는 "sovereign"입니다. 기업이나 국가가 모델을 직접 내려받아 실행하고, 자체 환경에서 통제하고, 필요한 워크플로에 맞게 붙일 수 있어야 한다는 주장입니다. 그래서 Command A+는 단순한 모델 릴리스보다 주권형 AI 인프라 경쟁의 한 장면에 가깝습니다.
Command A+의 실제 모양
Cohere의 공식 발표와 Hugging Face 모델 카드를 종합하면 Command A+의 사양은 꽤 공격적입니다. 모델명은 command-a-plus-05-2026이고 라이선스는 Apache 2.0입니다. 구조는 sparse Mixture-of-Experts입니다. 전체 파라미터는 218B이지만 토큰 처리 시 활성화되는 파라미터는 25B입니다. 입력은 텍스트와 이미지를 받으며, 출력은 텍스트, reasoning, tool use를 포함합니다.
문맥 길이는 128K input context, 최대 생성은 64K입니다. 지원 언어는 48개이며, 한국어도 목록에 들어 있습니다. Cohere는 이 모델을 reasoning, agentic workflows, RAG, multilingual, multimodal document processing에 최적화했다고 설명합니다. 지원 프레임워크로는 vLLM과 Transformers가 제시됐고, 모델 카드에는 SGLang, Docker Model Runner 예시도 포함되어 있습니다.
여기서 중요한 것은 "오픈소스 모델"이라는 문구와 "에이전트 워크플로"라는 문구가 동시에 나왔다는 점입니다. 오픈 모델 시장은 그동안 채팅, RAG, 코드 생성, 로컬 실행을 중심으로 성장했습니다. 반면 기업용 에이전트는 도구 호출, 장기 문맥, 메모리, 파일 시스템, 데이터베이스, 권한 모델, 감사 로그가 같이 붙어야 합니다. Command A+는 이 두 세계를 연결하려는 제품입니다. Hugging Face에서 내려받을 수 있지만, Cohere의 North와 Model Vault 같은 엔터프라이즈 경로와도 연결되어 있습니다.
두 H100이라는 메시지
이번 발표에서 가장 눈에 띄는 숫자는 2 x H100입니다. Cohere는 Command A+가 16-bit BF16, 8-bit FP8, 4-bit W4A4 양자화로 제공된다고 밝혔습니다. 모델 카드의 최소 GPU 요구 사항은 BF16이 4 x B200 또는 8 x H100, FP8이 2 x B200 또는 4 x H100, W4A4가 1 x B200 또는 2 x H100입니다. 추천 경로는 W4A4입니다. Cohere는 세 양자화 사이에서 벤치마크 품질 차이가 거의 없고, W4A4가 더 작은 하드웨어 footprint와 더 나은 속도·지연 특성을 가진다고 설명합니다.
이 숫자는 엔터프라이즈 팀에게 꽤 직접적인 신호입니다. 218B라는 전체 파라미터만 보면 사내 배포가 어렵게 느껴집니다. 그러나 25B active MoE와 4-bit weight/activation 양자화를 조합하면, 모델을 고성능 워크스테이션이나 작은 서버 노드 단위로 실험할 수 있다는 이야기가 됩니다. 물론 2개 H100은 여전히 싸지 않습니다. 하지만 "프런티어급 클라우드 API를 계속 호출하거나, 자체 GPU 풀에서 추론을 운영할 것인가"라는 계산을 시작할 수 있는 수준입니다.
Cohere는 속도 수치도 함께 제시했습니다. 동일한 양자화와 동시성 조건에서 Command A+가 Command A Reasoning보다 output tokens per second를 최대 63% 높이고, time to first token을 최대 17% 낮춘다고 밝혔습니다. W4A4 양자화는 추가로 47% 속도 증가와 13% 지연 감소에 기여한다고 설명합니다. 또 MoE 구조에 맞춘 speculative decoding으로 텍스트와 멀티모달 입력 모두에서 1.5-1.6배 추가 가속을 얻었다고 합니다.
이 주장은 아직 독립 재현이 충분히 쌓인 상태는 아닙니다. Cohere의 측정 조건은 공식 발표 각주에 적혀 있습니다. 단일 NVIDIA HGX B200 노드, 8 GPU, vLLM tensor parallelism 8, LiveCodeBench, 약 3K prompt와 8K max output 같은 조건입니다. 따라서 이 수치를 바로 모든 사내 워크로드의 속도로 번역하면 위험합니다. 다만 발표의 방향은 분명합니다. 모델 회사들이 이제 "더 큰 모델"만 외치는 것이 아니라, "이 모델을 어떤 GPU 구성에서 어떤 지연 시간으로 돌릴 수 있는가"를 제품 메시지의 중앙에 두고 있습니다.
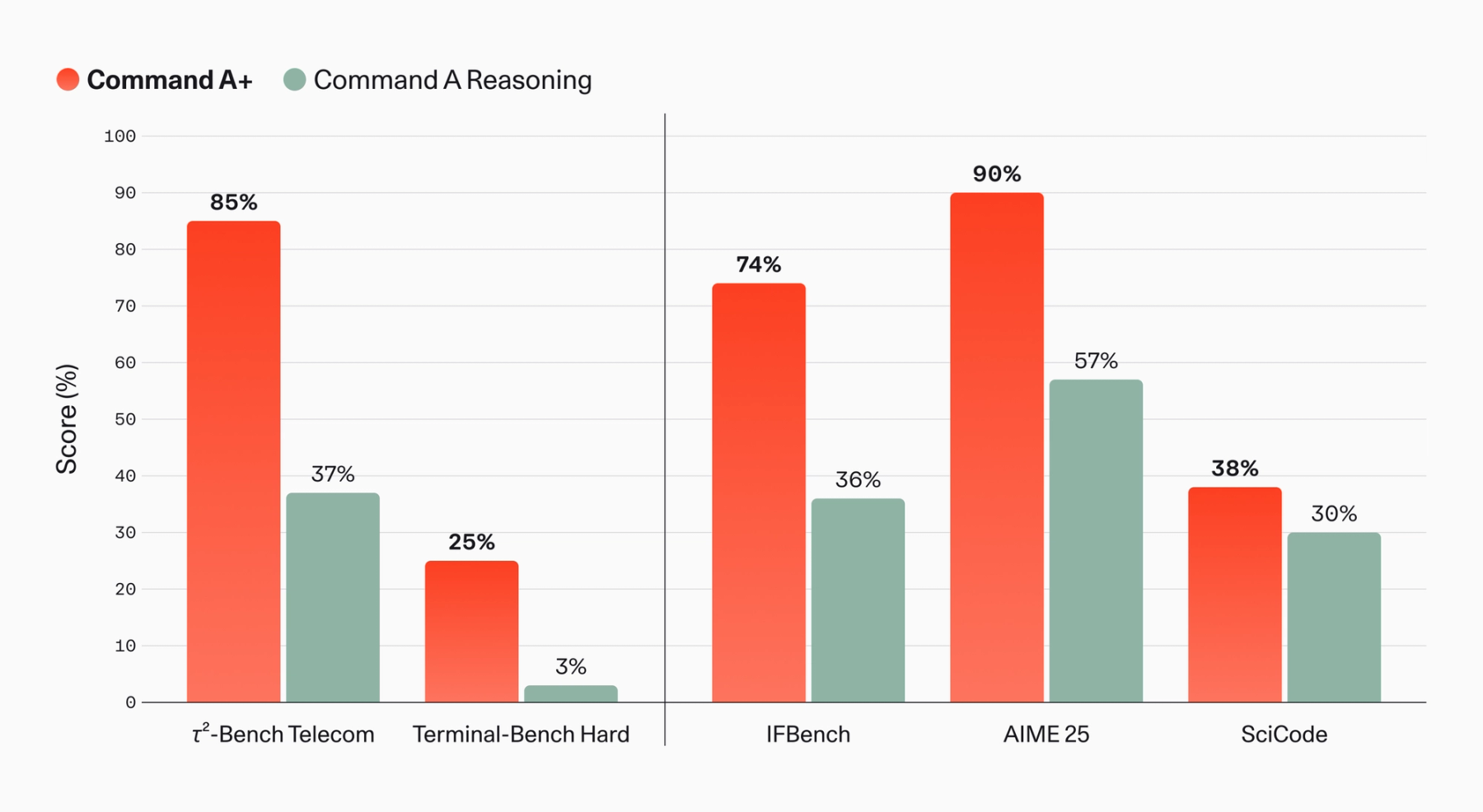
에이전트 모델에서 벤치마크가 바뀌는 방식
Command A+의 성능 주장은 일반 채팅 벤치마크보다 엔터프라이즈 에이전트 업무에 맞춰져 있습니다. Cohere는 Command A Reasoning 대비 2-Bench Telecom 점수가 37%에서 85%로 올랐고, Terminal-Bench Hard의 agentic coding 성능이 3%에서 25%로 올랐다고 밝혔습니다. North 애플리케이션 안에서는 Agentic Question Answering 정확도가 20%, spreadsheet analysis 품질이 32% 개선됐고, 메모리 성능은 Command A Reasoning 39%에서 Command A+ 54%로 올라갔다고 설명합니다.
이 지표들이 흥미로운 이유는 에이전트 제품의 병목을 더 잘 드러내기 때문입니다. 기업용 AI에서 질문 하나에 답하는 능력은 시작점일 뿐입니다. 실제 업무에서는 문서 저장소에서 관련 파일을 찾고, 표 데이터를 해석하고, 이전 대화나 저장된 메모리를 참조하고, 필요하면 API나 데이터베이스를 호출해야 합니다. Cohere가 North 내부 평가를 앞세운 것은 Command A+를 독립 모델이 아니라 업무 에이전트 플랫폼의 실행 엔진으로 설계했다는 뜻입니다.
다만 여기에는 주의점도 있습니다. North 내부 평가는 외부 독자가 그대로 검증하기 어렵고, LLM-as-a-judge 방식도 평가 설계에 민감합니다. 모델 카드와 블로그는 공개 벤치마크를 함께 제시하지만, 실제 구매자에게 중요한 것은 자기 조직의 파일, 자기 언어, 자기 도구, 자기 보안 정책에서의 결과입니다. Command A+가 오픈소스로 공개된 것은 이 점에서 장점입니다. 팀이 직접 내려받아 벤치마크를 재현하거나, vLLM과 Transformers 환경에서 자체 평가를 돌릴 수 있기 때문입니다.
한국어 16% 토큰 효율의 의미
Command A+ 발표에서 놓치기 쉬운 숫자가 하나 더 있습니다. Cohere는 최신 토크나이저를 적용해 같은 응답을 생성하는 데 필요한 토큰 수를 줄였고, 특히 비유럽 주요 언어에서도 개선이 있었다고 밝혔습니다. Arabic은 20%, Korean은 16%, Japanese는 18% tokenization efficiency가 개선됐다는 설명입니다.
한국어 독자에게 이 숫자는 단순한 현지화 포인트가 아닙니다. LLM 비용은 보통 입력 토큰과 출력 토큰 단위로 움직입니다. 한국어가 영어보다 더 많은 토큰으로 쪼개지는 모델에서는 같은 업무를 해도 비용과 지연 시간이 늘어날 수 있습니다. 사내 문서, 계약서, 고객 상담, 지원 티켓, 코드 주석, 지식베이스가 한국어로 쌓여 있는 조직이라면 토크나이저 효율은 모델 품질만큼 현실적인 비용 변수입니다.
물론 16% 개선이 모든 한국어 업무에서 그대로 비용 16% 절감으로 이어진다고 말할 수는 없습니다. 프롬프트 구조, 검색된 문서 길이, tool call 결과, reasoning 토큰, 캐시 정책이 함께 작동합니다. 그래도 비영어권 엔터프라이즈 AI에서 토크나이저는 점점 중요한 경쟁 요소가 됩니다. 모델이 한국어를 "지원한다"는 선언과, 한국어를 비용 효율적으로 처리한다는 주장은 다릅니다. Command A+가 후자를 명시했다는 점은 주목할 만합니다.
주권형 AI라는 단어의 실제 무게
AI 업계에서 sovereign AI라는 표현은 자주 정치적·마케팅적 문구로 쓰입니다. 그러나 에이전트가 업무 시스템 안으로 들어오면 이 단어는 꽤 구체적인 운영 요구가 됩니다. 금융, 제조, 공공, 의료, 국방, 법률 조직은 데이터를 외부 클라우드 API로 보낼 수 없거나, 보내더라도 매우 제한된 조건을 요구합니다. 모델 업데이트, 로그 보존, 접근 권한, 데이터 residency, 사고 조사 절차도 중요합니다.
Command A+의 Apache 2.0 라이선스와 Hugging Face 배포는 이 요구에 맞춰져 있습니다. 팀은 모델을 받아 내부 인프라에서 돌릴 수 있고, 필요하면 자체 inference gateway나 vLLM 클러스터에 붙일 수 있습니다. Cohere는 별도로 Model Vault라는 관리형 inference 환경도 제시합니다. 즉, 완전 자체 운영과 관리형 프라이빗 배포 사이를 잇는 선택지를 만들려는 구조입니다.
이 흐름은 최근 AI 인프라 경쟁과도 이어집니다. NVIDIA는 GPU뿐 아니라 CPU orchestration, 네트워크, 컴파일러, 추론 최적화를 강조하고 있습니다. 클라우드 사업자들은 관리형 에이전트 런타임과 MCP 서버, 샌드박스, 관측성을 묶고 있습니다. 모델 회사들은 API의 편의성과 자체 배포의 통제권 사이에서 제품 라인을 나눕니다. Command A+는 이 전체 전선에서 "모델 weight를 열고, 에이전트 기능을 넣고, 하드웨어 요구를 낮추는" 쪽에 서 있습니다.
개발자와 AI 팀이 확인해야 할 것
개발자 관점에서 가장 먼저 볼 것은 실행 경로입니다. Hugging Face 모델 카드는 Transformers 예제, vLLM serve 예제, SGLang launch server 예제, Docker Model Runner 경로를 제시합니다. W4A4는 vLLM 0.21.0 이상과 Cohere의 melody library가 필요하다고 적혀 있습니다. tool call parser와 reasoning parser도 Cohere Command4용 설정을 사용합니다. 즉, 단순히 모델명을 바꿔 기존 오픈 모델 서빙 코드에 꽂는 수준은 아닐 수 있습니다.
두 번째는 도구 호출 형식입니다. 모델 카드는 JSON schema로 tool description을 제공하고, 모델이 plan과 tool call을 생성한 뒤 tool 결과를 대화 이력에 추가하는 흐름을 설명합니다. 이는 OpenAI-compatible API, Anthropic tool use, MCP 기반 도구 계층과 함께 비교해야 할 부분입니다. 에이전트 시스템을 이미 운영 중인 팀이라면 모델 성능보다 tool call 안정성, 인용 span, 실패 복구, sandbox 정책이 더 중요할 수 있습니다.
세 번째는 평가입니다. Cohere가 제시한 2-Bench Telecom, Terminal-Bench Hard, MMMU, MathVista, North 내부 평가가 의미 없는 것은 아닙니다. 그러나 사내 에이전트 도입에서 더 중요한 것은 "우리 업무의 실패 비용"입니다. Command A+를 검토한다면 고객 데이터 질의, 사내 문서 RAG, 코드베이스 분석, 스프레드시트 분석, 다국어 번역, 장문 보고서 작성 같은 실제 태스크를 작은 벤치마크 세트로 만들고, 프런티어 API 모델 및 다른 오픈 모델과 같은 조건에서 비교해야 합니다.
경쟁은 모델 점수에서 운영권으로 이동합니다
Command A+는 Cohere가 프런티어 모델 경쟁을 포기했다는 신호가 아닙니다. 오히려 경쟁 축을 조금 다르게 잡았다는 신호입니다. OpenAI와 Anthropic이 강력한 모델과 통합 제품을 앞세워 agentic coding과 업무 자동화를 밀고 있다면, Cohere는 기업이 자체 환경에서 모델을 통제할 수 있어야 한다는 메시지를 강화합니다. 이 차이는 단순 철학이 아니라 판매 방식, 배포 방식, 보안 검토 방식, 비용 모델의 차이로 이어집니다.
여기서 오픈 모델의 역할도 바뀝니다. 몇 년 전 오픈 모델은 "폐쇄형 API보다 싸게 돌릴 수 있는 대안"으로 많이 소비됐습니다. 이제는 에이전트 운영의 안전장치가 됩니다. 모델 weight를 보유하고, inference path를 통제하고, 로그와 권한을 내부 정책 안에 넣고, 필요하면 특정 도메인에 맞게 평가·튜닝할 수 있는지가 중요해졌습니다. Command A+의 Apache 2.0 공개는 이 방향에 힘을 싣습니다.
그러나 오픈 weight만으로 충분하지는 않습니다. 기업은 모델만 사는 것이 아니라 운영 체계를 삽니다. 모니터링, rate limit, secrets 관리, tool sandbox, prompt injection 방어, 데이터 거버넌스, 평가 자동화, incident response가 함께 필요합니다. Cohere가 North와 Model Vault를 함께 말하는 이유도 여기에 있습니다. 모델을 열어 커뮤니티와 개발자의 실험을 끌어들이면서, 실제 기업 배포는 관리형 또는 프라이빗 플랫폼으로 연결하려는 전략입니다.
남은 질문
Command A+의 가장 큰 질문은 독립 검증입니다. Cohere의 공식 수치는 인상적이지만, 에이전트 모델은 벤치마크보다 운영 환경에서 드러나는 차이가 큽니다. 128K 문맥을 실제로 오래 유지할 때 비용과 품질이 어떻게 변하는지, tool call이 복잡한 다단계 업무에서 얼마나 안정적인지, 한국어 문서 RAG와 표 분석에서 어느 정도 개선을 보이는지, W4A4 양자화가 긴 reasoning trace에서 어떤 오류 패턴을 만드는지는 앞으로 커뮤니티와 기업 평가가 쌓여야 합니다.
또 하나는 생태계입니다. OpenAI와 Anthropic은 코딩 도구, IDE, CLI, 모바일 승인, 엔터프라이즈 정책, 보안 프로그램을 빠르게 묶고 있습니다. Google은 Gemini와 Vertex AI, Android, Workspace를 연결합니다. Cohere가 Command A+로 모델 weight와 배포 효율을 앞세웠다면, 다음 싸움은 개발자가 이 모델을 실제 에이전트 런타임에 얼마나 쉽게 넣을 수 있느냐입니다. vLLM과 Transformers 지원은 좋은 출발이지만, 운영 품질은 SDK와 예제보다 훨씬 긴 싸움입니다.
그래도 이번 발표가 던진 질문은 선명합니다. 에이전트 시대의 모델 선택은 "가장 높은 점수의 API를 호출할 것인가"에서 끝나지 않습니다. 어디서 실행할 수 있는가, 어떤 GPU 예산이 필요한가, 어떤 언어에서 토큰 비용이 불리하지 않은가, 도구 호출과 메모리를 어떻게 통제할 것인가가 같이 묶입니다. Command A+는 그 질문을 218B 모델과 2개 H100이라는 대비로 압축했습니다. 그래서 이번 뉴스의 핵심은 새 모델 하나가 아니라, 프라이빗 에이전트 두뇌의 가격표가 점점 구체화되고 있다는 점입니다.