2개 H100이면 충분하다, Command A+가 겨냥한 사설 에이전트
Cohere Command A+는 Apache 2.0 오픈 가중치와 2개 H100 배포 조건으로 사설 에이전트 경쟁의 기준을 낮추려 합니다.

- 무슨 일: Cohere가
Command A+를 Apache 2.0 오픈 가중치 모델로 공개했습니다.- 218B 전체 파라미터, 25B 활성 파라미터 MoE 모델이며 W4A4 기준 2개 H100 또는 1개 B200 실행을 내세웁니다.
- 의미: 오픈 모델 경쟁의 질문이 점수에서 사설 배포 가능한 에이전트 운영비로 이동합니다.
- 주의점: H100 두 장도 작은 비용은 아니며, 내부 North 평가는 재현 가능한 외부 검증과 분리해서 읽어야 합니다.
Cohere가 2026년 5월 20일 Command A+를 공개했습니다. 표면적으로는 새 오픈 가중치 LLM 출시입니다. 하지만 이번 발표에서 더 중요한 문장은 "가장 강한 모델"보다 "2개 H100 또는 1개 B200에서 실행"입니다. AI 팀이 에이전트를 실제 업무 흐름에 넣으려 할 때 부딪히는 문제는 모델 점수만이 아닙니다. 데이터가 조직 밖으로 나가도 되는지, 추론비를 감당할 수 있는지, 지연시간이 에이전트 루프를 망치지 않는지, 보안팀이 배포 방식을 받아들일 수 있는지가 함께 따라옵니다.
Cohere의 공식 발표는 Command A+를 "sovereign agentic capabilities"라는 말로 포장합니다. 마케팅 문구처럼 보일 수 있지만, 이번에는 모델 카드의 숫자가 그 문구를 뒷받침하려 합니다. Command A+는 218B 전체 파라미터를 가진 sparse MoE 모델이지만, 한 번의 추론에서 활성화되는 파라미터는 25B입니다. 컨텍스트는 128K 입력과 64K 최대 출력을 지원하고, 텍스트뿐 아니라 이미지 입력, reasoning, tool use를 한 모델에 묶습니다. 라이선스는 Apache 2.0입니다.
이 조합은 개발자에게 꽤 선명한 신호를 줍니다. Cohere는 "API로만 쓰는 기업용 모델"과 "커뮤니티가 내려받지만 실서비스에 올리기 어려운 대형 오픈 모델" 사이의 공간을 겨냥하고 있습니다. Command A+가 실제로 그 공간을 차지할지는 별개의 문제입니다. 다만 이번 발표는 오픈 모델 경쟁에서 중요한 질문을 바꿉니다. 이제는 "이 모델이 벤치마크에서 몇 점인가"와 함께 "이 모델을 우리 데이터 경계 안에서 에이전트로 돌릴 수 있는가"를 물어야 합니다.
Cohere가 지금 꺼낸 숫자
발표의 핵심 사양부터 보겠습니다. Cohere 문서는 모델 ID를 command-a-plus-05-2026으로 적고, capability로 reasoning, multilingual, image inputs, citations, tool use, structured outputs를 나열합니다. 같은 문서는 Command A+가 Cohere의 첫 Mixture-of-Experts 모델이며 48개 언어를 지원한다고 설명합니다. 여기서 중요한 부분은 기능 목록보다 하드웨어 조건입니다. 문서는 MoE 구조가 정확도와 처리량, 지연시간, GPU 요구량 사이의 균형을 잡기 위한 선택이라고 말합니다.
Hugging Face W4A4 모델 카드는 더 노골적입니다. 공개된 양자화는 BF16, FP8, W4A4 세 가지입니다. 예시 최소 GPU 요구량은 BF16이 4개 B200 또는 8개 H100, FP8이 2개 B200 또는 4개 H100, W4A4가 1개 B200 또는 2개 H100입니다. Cohere는 세 양자화 사이의 품질 차이가 "negligible"하다고 설명하며, 대부분의 사용 사례에 W4A4를 권장합니다. 이 주장은 독립 검증이 필요하지만, 메시지는 분명합니다. 사내 배포의 최소선을 낮추겠다는 것입니다.
이는 단순히 "저렴해졌다"는 말과 다릅니다. H100 두 장은 여전히 개인 개발자나 작은 팀에게 가벼운 장비가 아닙니다. 하지만 엔터프라이즈 AI 예산에서는 다른 의미를 갖습니다. API 사용량이 많고, 데이터 보안 요구가 강하며, 특정 지역이나 전용 인프라에서 모델을 돌려야 하는 조직이라면, 2개 H100은 "불가능한 연구 모델"과 "검토 가능한 운영 옵션"의 경계가 될 수 있습니다. 특히 에이전트는 한 번의 답변보다 반복 호출이 많습니다. 도구 선택, 검색, 검증, 재시도, 파일 읽기, 표 계산이 이어지면 토큰과 지연시간이 빠르게 쌓입니다. 그래서 에이전트용 모델의 비용은 챗봇 가격표보다 더 민감합니다.
218B보다 중요한 25B active
Command A+의 숫자 중 가장 잘 팔리는 숫자는 218B입니다. 하지만 운영 관점에서 더 중요한 숫자는 25B active입니다. MoE 모델은 모든 파라미터를 매번 쓰지 않습니다. 입력에 따라 일부 expert만 활성화하고, 그 결과 큰 전체 용량과 낮은 활성 계산량 사이의 절충을 시도합니다. 이것이 잘 작동하면 모델은 다양한 업무를 처리할 표현력을 유지하면서도 추론 비용을 낮출 수 있습니다. 반대로 라우팅, 캐시, 양자화, 커널 최적화가 불안정하면 스펙표의 장점이 실제 서비스에서 흐려집니다.
Cohere가 이번 발표에서 North를 반복해서 언급하는 이유도 여기에 있습니다. North는 Cohere의 엔터프라이즈 업무용 AI 플랫폼입니다. 발표문은 Command A+가 지난 1년 동안 North를 고객과 배포하며 얻은 요구에서 나왔다고 설명합니다. 다시 말해 이 모델은 오픈 채팅 리더보드만 겨냥한 모델이 아니라, 기업 문서, 파일 시스템, 스프레드시트, 메모리, 도구 호출을 계속 만지는 업무형 에이전트를 염두에 둔 모델이라는 주장입니다.
그 주장이 흥미로운 이유는 에이전트 품질이 일반적인 대화 품질과 다르기 때문입니다. 에이전트는 한 문장을 그럴듯하게 쓰는 것보다, 제한된 컨텍스트 안에서 지시를 잊지 않고, 도구를 잘 고르고, 실패 후 복구하고, 근거를 남기고, 같은 작업을 여러 번 반복해도 비용과 지연시간이 폭주하지 않아야 합니다. 모델이 조금 더 똑똑하더라도 느리고 비싸면 루프 전체가 무거워집니다. 반대로 모델이 최고 점수가 아니더라도 충분히 빠르고 안정적이면 특정 업무에서는 더 좋은 선택이 될 수 있습니다.
벤치마크는 에이전트 방향을 말합니다
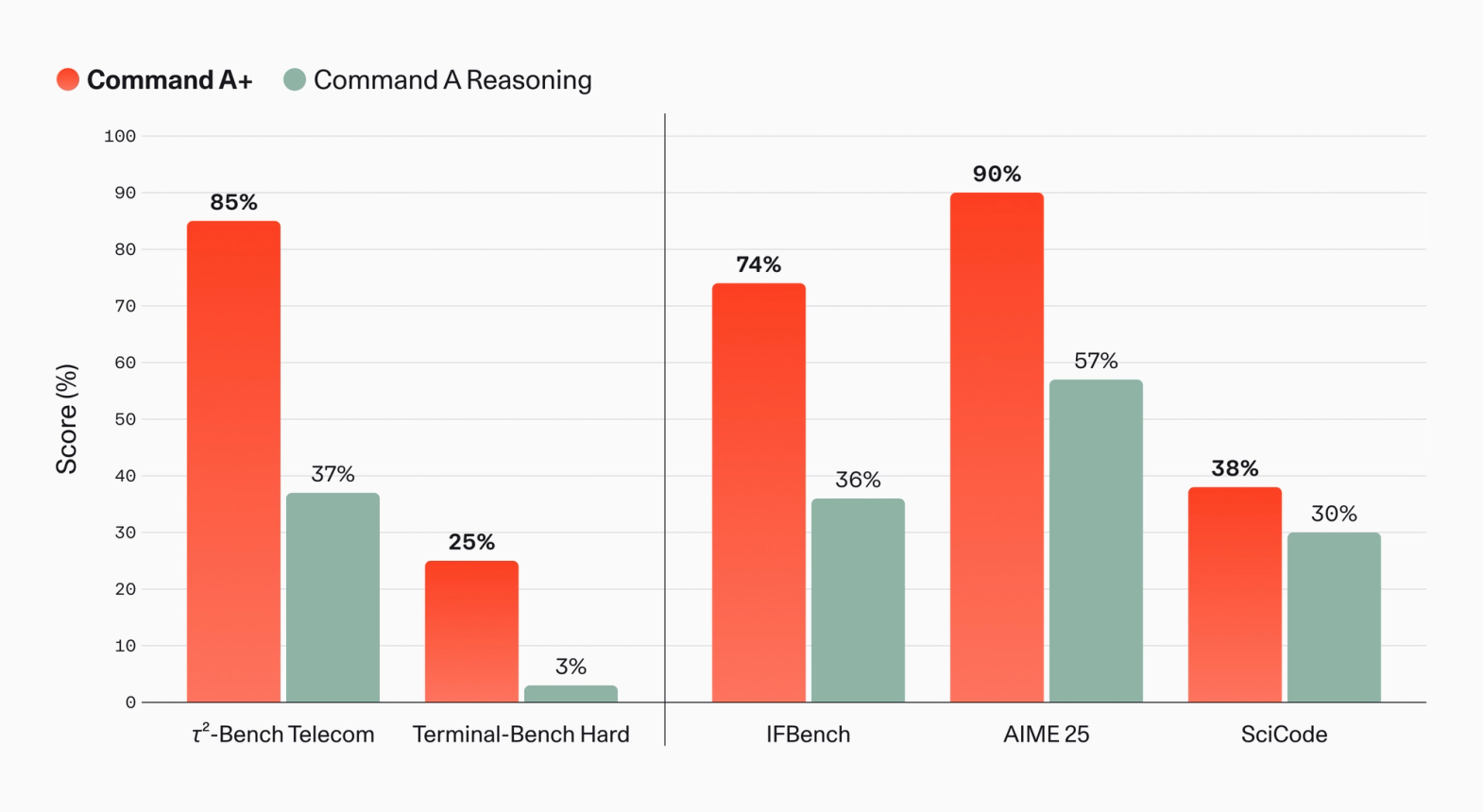
Cohere가 공개한 차트에서 눈에 띄는 항목은 전통적인 수학 점수만이 아닙니다. Command A+는 Command A Reasoning 대비 tau2-Bench Telecom에서 37%에서 85%, Terminal-Bench Hard에서 3%에서 25%로 개선됐다고 제시됩니다. IFBench는 36%에서 74%, AIME 25는 57%에서 90%, SciCode는 30%에서 38%입니다. 여기서 Terminal-Bench Hard와 tau2-Bench Telecom은 에이전트와 코드 실행 흐름을 보는 독자에게 더 직접적인 신호입니다. 특히 Terminal-Bench 계열은 모델이 터미널 환경에서 긴 작업을 얼마나 수행하는지 보려는 벤치마크입니다.
물론 벤치마크는 결론이 아니라 질문입니다. Cohere의 차트는 모델이 어떤 방향으로 좋아졌는지를 보여주지만, 실제 팀이 궁금한 것은 자기 작업에서의 실패율입니다. 예를 들어 사내 코드베이스에서 PR을 고치는 에이전트라면 테스트 실행, 로그 해석, 파일 탐색, patch 적용, 리뷰 코멘트 반영이 모두 필요합니다. 고객지원 에이전트라면 티켓 상태, CRM, 지식베이스, 권한 경계, 감사 로그를 함께 다뤄야 합니다. 통신사나 금융사라면 내부 용어와 시스템 제약이 더 큽니다. 공개 벤치마크는 이런 복잡성을 압축한 지표일 뿐입니다.
Cohere도 내부 평가를 따로 공개했습니다. 발표문에 따르면 North 애플리케이션에서 Agentic Question Answering 정확도는 Command A Reasoning 대비 20%, spreadsheet analysis quality는 32% 개선됐습니다. Memory performance는 39%에서 54%로 올랐다고 합니다. 다만 이 내부 평가는 LLM-as-a-judge 방식이라고 명시되어 있습니다. LLM-as-a-judge는 빠르게 제품 품질을 비교하는 데 유용하지만, 평가 프롬프트, judge 모델, 샘플 구성에 민감합니다. 따라서 이 숫자는 "Cohere가 어떤 업무를 중요하게 보고 있는가"를 읽는 데는 좋지만, 외부 재현 가능한 성능으로 받아들이기에는 아직 조심해야 합니다.
오픈 모델의 경쟁축이 바뀝니다
최근 오픈 모델 경쟁은 여러 방향으로 갈라졌습니다. DeepSeek과 Qwen은 강한 성능과 넓은 개발자 접근성을 보여줬고, Mistral은 유럽 기반 오픈 모델과 엔터프라이즈 배포를 결합해 왔습니다. Meta Llama 계열은 생태계 규모와 툴체인 영향력이 큽니다. Cohere는 같은 경기장에 들어오면서도 다른 단어를 앞세웁니다. "sovereign", "private deployment", "enterprise workhorse", "North"입니다.
이 단어들은 개발자에게 조금 지루하게 들릴 수 있습니다. 하지만 실제 구매와 운영에서는 지루한 단어가 예산을 움직입니다. 데이터가 어디로 가는지, 로그가 남는지, 모델 가중치를 검토할 수 있는지, 특정 리전에 배포할 수 있는지, 고객 데이터를 학습에 쓰지 않는지, 장애 대응과 SLA를 어떻게 잡는지가 중요합니다. 오픈 가중치 모델이 이 요구를 모두 자동으로 해결하지는 않습니다. 그래도 모델을 내려받아 직접 검증하고, 사설 인프라에 올리고, 필요하면 미세 조정하거나 라우팅 전략을 바꾸는 선택권은 생깁니다.
Apache 2.0도 이 맥락에서 중요합니다. 많은 "오픈" 모델은 실제 상업 사용 조건이 복잡하거나 별도 계약을 요구합니다. Apache 2.0은 기업 법무와 보안 검토에서 상대적으로 다루기 쉬운 라이선스입니다. 물론 모델 사용 정책, 데이터셋 출처, 배포 환경의 규제 요건은 여전히 따로 봐야 합니다. 그러나 라이선스가 명확하다는 것만으로도 사내 실험의 마찰은 줄어듭니다. 개발팀은 먼저 모델을 받아서 PoC를 만들고, 법무와 보안팀은 더 구체적인 배포 조건을 검토할 수 있습니다.
한국어와 다국어 비용의 작은 신호
Command A+ 발표에서 작지만 흥미로운 부분은 토크나이저입니다. Cohere는 최신 토크나이저를 적용해 같은 응답을 생성하는 데 필요한 토큰 수를 줄였고, Arabic은 20%, Korean은 16%, Japanese는 18% 효율이 개선됐다고 주장합니다. 이 숫자는 모델 점수보다 덜 화려하지만, 글로벌 제품팀에게는 중요합니다. LLM 비용은 모델 호출 수만으로 결정되지 않습니다. 같은 문장을 몇 개 토큰으로 표현하는지도 비용과 지연시간을 바꿉니다.
한국어 서비스에서 영어 모델을 붙여 본 팀은 이 문제를 압니다. 같은 의미의 문장이라도 토큰 분절이 비효율적이면 입력과 출력 비용이 커집니다. 검색 증강을 붙이면 문서 조각이 길어지고, 에이전트를 붙이면 중간 상태와 도구 결과가 계속 컨텍스트에 쌓입니다. 여기서 16% 개선은 단일 답변에서는 작아 보일 수 있지만, 대량 업무 자동화에서는 누적됩니다. 특히 한국어, 일본어, 아랍어처럼 영어 중심 토크나이저에서 손해를 보기 쉬운 언어에서는 배포 비용 계산에 직접 들어갑니다.
다만 이 역시 실제 사용 데이터로 확인해야 합니다. 토크나이저 효율은 문서 종류에 따라 달라집니다. 고객지원 대화, 법률 문서, 개발 문서, 표 데이터, 로그, 코드 주석은 모두 다르게 토큰화됩니다. 따라서 Command A+를 검토하는 팀은 공개 벤치마크보다 먼저 자기 데이터 1천~1만 샘플로 토큰 수와 지연시간을 재는 것이 더 실용적입니다. 모델 선택은 성능표가 아니라 비용표와 장애표에서 확정됩니다.
커뮤니티는 실용성을 먼저 봅니다
LocalLLaMA 커뮤니티 반응도 이 방향과 맞닿아 있습니다. Cohere 공동창업자 Nick Frosst는 Reddit 스레드에서 Command A+를 소개하며, 최고 성능만이 아니라 빠르고 반응성 있는 모델을 만들었고 1~2개 GPU에서도 잘 돌도록 양자화에 공을 들였다고 설명했습니다. 이 메시지는 오픈 모델 커뮤니티가 실제로 묻는 질문과 가깝습니다. "얼마나 똑똑한가"보다 "내 장비에서 돌아가는가", "라이선스가 괜찮은가", "툴 호출과 긴 컨텍스트가 안정적인가"가 먼저입니다.
반응은 낙관만은 아닙니다. 별도 MLX 포팅 글에서는 W4A4 모델을 Apple Silicon에서 돌리려는 시도가 공유됐지만, 약 132GB 메모리 요구 때문에 128GB M3 Max에서는 직접 검증하지 못했다는 경험담이 있었습니다. 이것이 Command A+의 현실입니다. Cohere가 "2개 H100"이라고 말하는 순간 모델은 기업과 고급 연구자에게 가까워지지만, 일반 로컬 LLM 사용자에게는 여전히 큰 모델입니다. 오픈 가중치가 곧 로컬 접근성을 뜻하지는 않습니다.
그래도 커뮤니티 검증의 시작점은 의미가 있습니다. 오픈 모델은 발표 직후부터 vLLM, SGLang, Transformers, MLX 같은 실행 경로에서 검증됩니다. 누군가는 메모리 사용량을 재고, 누군가는 tool calling을 테스트하고, 누군가는 양자화 품질을 비교합니다. 기업 입장에서는 이 공개 검증이 중요합니다. 폐쇄형 API 모델은 공급자가 제공하는 품질과 SLA를 믿어야 하지만, 오픈 가중치 모델은 커뮤니티가 느리게라도 실패 사례를 축적합니다. 그 축적이 사내 도입 리스크를 줄입니다.
개발팀에게 남는 체크리스트
Command A+가 개발팀에게 던지는 질문은 모델 교체가 아닙니다. 더 정확히는 에이전트 배포 전략의 선택지입니다. 첫째, 데이터 경계가 강한 업무에서 API 모델을 계속 쓸 것인지, 사설 배포 모델을 평가할 것인지 결정해야 합니다. 둘째, 에이전트 루프의 호출 수와 평균 컨텍스트 길이를 먼저 측정해야 합니다. 셋째, 벤치마크 점수보다 실패 복구, tool use, citation, structured output, 지연시간 분포를 테스트해야 합니다. 넷째, H100 두 장 또는 B200 한 장을 모델 하나에 묶을 때의 기회비용을 계산해야 합니다.
특히 사내 에이전트는 "모델 하나"가 아닙니다. 검색 인덱스, 권한 필터, 파일 커넥터, 큐, 작업 로그, 승인 UI, 평가셋, human review, 모니터링이 함께 필요합니다. 모델이 Apache 2.0이라고 해서 이 운영 계층이 공짜가 되지는 않습니다. 하지만 모델을 사설로 돌릴 수 있으면 운영 계층의 설계 자유도가 커집니다. 프롬프트와 로그를 외부 API에 보내지 않아도 되고, 민감 문서를 내부 네트워크에서 처리할 수 있으며, 특정 워크로드에 맞춰 추론 서버와 캐시 정책을 조정할 수 있습니다.
이 지점에서 Command A+는 Cohere의 최근 전략과 이어집니다. Cohere는 Reliant AI 인수로 규제 산업의 문서 업무를 겨냥했고, North로 엔터프라이즈 에이전트 표면을 만들고 있으며, Transcribe와 Embed, Rerank 같은 모델 제품군도 업무 자동화에 붙이고 있습니다. Command A+는 이 제품군의 중심 모델 역할을 노립니다. 그래서 이번 뉴스는 "Cohere가 더 큰 모델을 냈다"보다 "Cohere가 사설 에이전트 배포의 최소 조건을 제품화하려 한다"에 가깝습니다.
결론은 아직 배포 현장에 있습니다
Command A+의 가장 강한 주장은 모델 카드가 아니라 운영 문장입니다. 218B MoE 모델을 Apache 2.0으로 열고, W4A4 기준 2개 H100에서 실행 가능하다고 말하는 것은 오픈 모델 경쟁의 기준선을 바꾸려는 시도입니다. 모델이 정말로 기업 에이전트 워크로드에서 충분히 빠르고 안정적이라면, 사설 배포 모델은 더 이상 "보안 때문에 어쩔 수 없이 성능을 포기하는 선택"이 아니라 "비용과 통제를 위해 검토할 만한 선택"이 됩니다.
하지만 결론은 아직 발표문에 있지 않습니다. 외부 벤치마크, 커뮤니티 실행 로그, 실제 사내 PoC, 장기 에이전트 실패율이 필요합니다. H100 두 장의 약속은 매력적이지만, 그 위에 올라가는 운영체계는 여전히 무겁습니다. 에이전트가 파일을 잘 읽는지, 도구를 잘 고르는지, 긴 작업에서 상태를 잃지 않는지, 한국어 문서에서 비용이 실제로 줄어드는지는 각 팀이 확인해야 합니다.
그래서 Command A+는 당장 모든 팀이 갈아탈 모델이라기보다, 오픈 모델 경쟁이 어디로 가는지 보여주는 표식입니다. 더 큰 모델, 더 높은 점수, 더 긴 컨텍스트만으로는 부족합니다. AI 에이전트가 기업 내부로 들어갈수록 중요한 것은 배포권, 비용, 지연시간, 감사 가능성, 그리고 실패를 관찰할 수 있는 운영 표면입니다. Cohere가 이번에 내놓은 숫자는 그 방향을 분명히 가리킵니다. 사설 에이전트의 다음 경쟁은 모델 크기보다, 그 모델을 어디까지 조직 안으로 들여올 수 있느냐에 달려 있습니다.