84% 줄어든 승인창, Claude가 드러낸 에이전트 격리의 조건
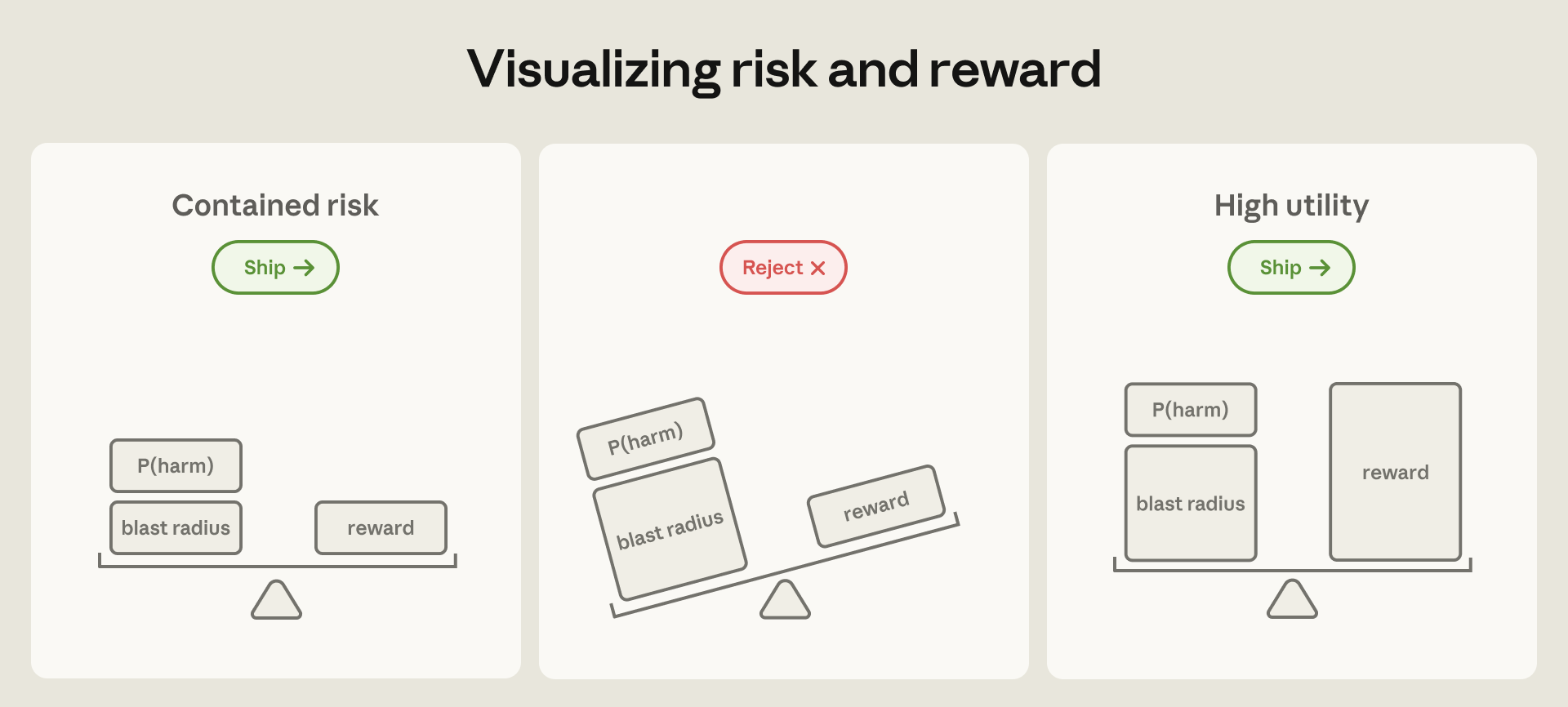
Anthropic의 Claude containment 공개는 에이전트 보안의 중심이 프롬프트 방어에서 런타임 격리와 blast radius 제한으로 옮겨감을 보여줍니다.
- 무슨 일: Anthropic이
claude.ai,Claude Code,Claude Cowork의 에이전트 격리 방식을 공개했습니다.- 핵심은 모델 거부보다 환경 계층의 hard boundary로 파일, 네트워크, 프로세스 접근 범위를 줄이는 것입니다.
- 핵심 숫자: Claude Code의 OS-level sandbox는 permission prompt를 84% 줄였고, auto mode는 overeager action의 약 83%를 실행 전 포착합니다.
- 의미: 코딩 에이전트 보안 경쟁이
승인 UI에서 gVisor, Seatbelt, bubblewrap, VM, egress policy 같은 런타임 설계로 이동합니다.- 사용자가 모든 명령을 읽고 승인한다는 가정은 permission fatigue와 사용자 전달형 prompt injection 앞에서 약해집니다.
- 주의점: Anthropic도 모델 계층 방어가 필요 없다고 말하지 않습니다. 다만 classifier와 prompt는 격리의 보조층이지 마지막 방어선이 아닙니다.
AI 에이전트 보안을 이야기할 때 가장 먼저 떠오르는 장면은 승인창입니다. 에이전트가 파일을 고치거나 쉘 명령을 실행하려 할 때 "허용할까요"라고 묻고, 개발자가 내용을 보고 승인합니다. 이 방식은 직관적입니다. 사람이 마지막 권한을 쥐고 있고, 에이전트는 사람이 허락한 만큼만 움직이는 것처럼 보입니다. 하지만 실제 코딩 에이전트 사용량이 늘어나면 이 모델은 빠르게 흔들립니다. 명령은 많아지고, 사용자는 바빠지고, "이번에도 괜찮겠지"라는 습관이 생깁니다.
Anthropic이 2026년 5월 25일 공개한 엔지니어링 글 How we contain Claude across products는 바로 이 지점을 찌릅니다. 글은 claude.ai, Claude Code, Claude Cowork가 서로 다른 사용자와 작업 범위를 갖기 때문에 서로 다른 containment pattern을 써야 한다고 설명합니다. 핵심 문장은 간단합니다. 모델이 더 안전해져도 에이전트의 theoretical blast radius는 계속 커집니다. 따라서 시스템은 에이전트가 무엇을 할 수 있는지 환경 계층에서 제한해야 합니다.
이번 공개가 흥미로운 이유는 Anthropic이 단순히 "우리는 안전합니다"라고 말하지 않기 때문입니다. 오히려 몇 가지 실패를 직접 적습니다. trust dialog 전에 project-local configuration이 읽혀 hook이 실행될 수 있었던 사례, 사용자가 악성 프롬프트를 직접 붙여넣는 형태의 내부 red-team phish, custom proxy처럼 자체 구현한 컴포넌트 주변에서 생긴 문제를 언급합니다. AI 안전 회사가 제품 내부의 보안 경계를 설명하면서 "표준 primitive는 버텼지만, 우리가 만든 주변부가 약했다"는 식으로 말한 점이 뉴스입니다.
에이전트 방어는 세 층으로 나뉩니다
Anthropic은 에이전트 방어를 세 부분으로 나눕니다. 첫째는 모델입니다. system prompt, classifier, probe, training modification이 여기에 들어갑니다. Claude Code auto mode처럼 명령을 실행하기 전에 위험한 행동인지 모델 기반 classifier가 판단하는 방식도 이 계층입니다. 둘째는 환경입니다. process sandbox, VM, filesystem boundary, egress control이 포함됩니다. 셋째는 외부 콘텐츠입니다. MCP 서버, third-party plugin, web search tool, connector data처럼 모델 컨텍스트 안으로 들어오는 입력입니다.
이 분류가 중요한 이유는 "모델만 잘 만들면 된다"는 생각을 피하게 만들기 때문입니다. Anthropic은 Claude Opus 4.7이 Gray Swan의 Agent Red Teaming benchmark에서 single attempt prompt injection attack success를 약 0.1%로 낮췄고, 100 adaptive attempts 뒤에도 약 5-6% 수준이라고 설명합니다. Claude Code auto mode도 overeager behavior의 약 83%를 실행 전에 잡는다고 합니다. 강한 숫자입니다. 하지만 Anthropic의 결론은 그래서 모델 방어만 믿자는 쪽이 아닙니다. 확률적 모델은 어떤 행동을 "대체로" 덜 하게 만들 수 있지만, 이론적으로 가능한 행동의 경계를 닫지는 못합니다.
외부 콘텐츠 계층도 같은 문제를 갖습니다. 감사된 GitHub connector를 쓰더라도, GitHub에서 가져온 README가 prompt injection을 품고 있으면 그 텍스트는 그대로 모델 컨텍스트에 들어옵니다. MCP 서버나 플러그인이 악성 코드를 포함하지 않는다는 사실과, 그 서버가 가져오는 데이터가 안전하다는 사실은 다릅니다. 따라서 방어는 겹쳐야 합니다. 입력은 가능한 한 줄이고, 모델은 위험 행동을 감지하고, 환경은 모델이 실수해도 닿을 수 있는 범위를 제한해야 합니다.
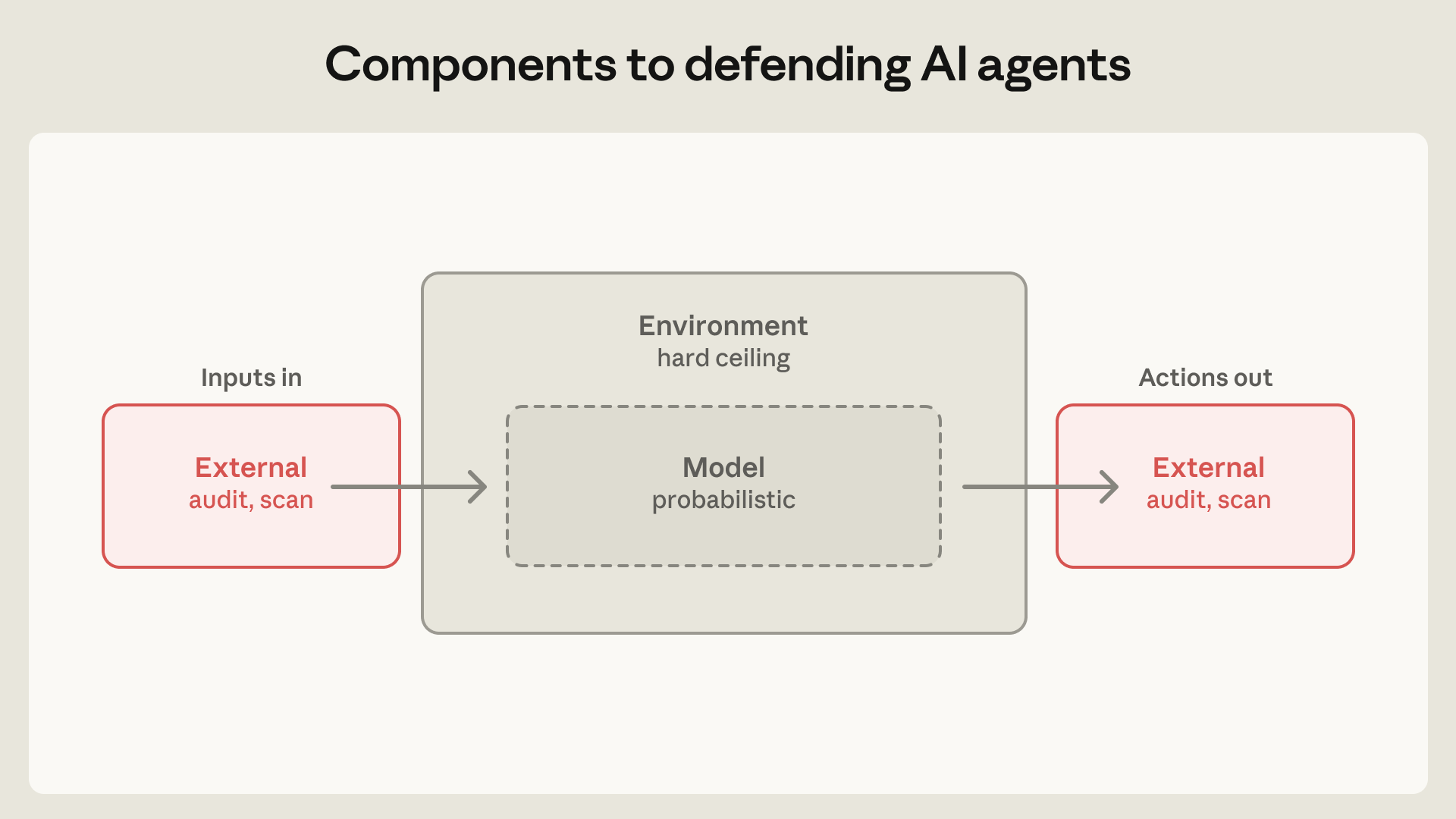
이 그림에서 눈에 띄는 단어는 "hard ceiling"입니다. 모델은 probabilistic layer입니다. 외부 입력과 출력은 audit와 scan의 대상입니다. 하지만 환경은 에이전트가 실제로 파일을 읽고, 소켓을 열고, 프로세스를 띄우는 경계입니다. 에이전트가 AWS credential을 읽을 수 없는 sandbox 안에 있다면, 모델이 아무리 창의적인 경로를 찾아도 해당 credential은 유출되지 않습니다. 이것이 containment가 prompt hardening과 다른 지점입니다.
claude.ai는 낮은 권한, 낮은 상한을 택했습니다
첫 번째 패턴은 claude.ai입니다. 일반 사용자가 웹에서 Claude에게 파일 생성, 코드 실행, connector 호출을 맡길 때는 서버 측 인프라에서 실행됩니다. Anthropic은 claude.ai의 코드 실행이 gVisor container 안에서 이뤄지고, filesystem은 session마다 ephemeral하다고 설명합니다. 사용자의 로컬 머신에서는 코드가 실행되지 않습니다. 이 구조는 blast radius를 작게 만듭니다. 동시에 할 수 있는 일의 상한도 낮춥니다. 사용자의 전체 repository, 로컬 shell, 임의 네트워크 접근을 직접 다루지 못하기 때문입니다.
이 패턴의 보안 문제는 비교적 전통적입니다. Anthropic은 claude.ai에서 사용자 머신을 에이전트로부터 보호하는 것이 아니라, Anthropic 인프라와 tenant 간 격리를 보호한다고 말합니다. 그래서 pre-launch 작업은 network configuration, internal service auth, orchestration 같은 익숙한 보안 작업에 집중됐습니다. 흥미로운 지점은 이때도 "가장 약한 층은 직접 만든 층"이라는 결론입니다. gVisor나 seccomp처럼 오래 공격받아온 primitive는 신뢰할 만하지만, 그 주변의 custom proxy와 orchestration은 더 새롭고 덜 단련됐습니다.
이 선택은 사용자 경험과도 맞습니다. 웹 Claude 사용자에게 "이 bash 명령을 읽고 승인하라"고 요구하기 어렵습니다. 대부분의 사용자는 shell command의 위험을 평가할 준비가 되어 있지 않습니다. 따라서 서버 측, 짧은 세션, 제한된 파일시스템이라는 구조가 자연스럽습니다. 기능의 상한을 낮춰서 보안의 하한을 올리는 방식입니다.
Claude Code는 승인창에서 sandbox로 이동했습니다
두 번째 패턴은 Claude Code입니다. 여기서는 상황이 정반대입니다. 코딩 에이전트가 유용하려면 사용자의 repository를 읽고, 파일을 고치고, 테스트를 돌리고, 패키지를 설치하고, shell command를 실행해야 합니다. 이 접근을 막으면 안전해질 수는 있지만, 도구의 가치는 크게 줄어듭니다. 그래서 Claude Code는 처음에 가장 단순한 방어를 택했습니다. reads는 허용하고, write, bash, network access에는 approval을 요구하는 방식입니다.
문제는 permission fatigue입니다. 코딩 작업은 작은 명령의 연속입니다. pnpm test, rg, sed, git diff, package manager, formatter, build command가 계속 등장합니다. 개발자가 매번 정확히 읽고 위험을 평가한다는 가정은 오래 버티기 어렵습니다. Anthropic은 이를 완화하기 위해 OS-level sandbox를 도입했습니다. macOS에서는 Seatbelt, Linux에서는 bubblewrap을 사용해 reads와 workspace 내부 writes는 허용하지만 network는 기본적으로 거부합니다. Anthropic은 이 변화로 permission prompt가 84% 줄었다고 밝혔습니다.
여기서 중요한 점은 "승인을 없앴다"가 아닙니다. 승인을 hard boundary 안으로 옮겼습니다. 에이전트가 sandbox 안에서 대부분의 작업을 중단 없이 수행할 수 있지만, sandbox 바깥으로 나가는 행동은 여전히 제한됩니다. 즉 개발자는 모든 command를 읽는 사람이 아니라, 더 좁은 boundary 안에서 agent drift를 감독하는 사람이 됩니다. 개발자 경험은 좋아지고, 동시에 network egress 같은 위험한 표면은 더 단단해집니다.
Anthropic은 이 runtime을 anthropic-experimental/sandbox-runtime으로 공개했습니다. README는 srt가 macOS sandbox-exec, Linux bubblewrap, proxy-based network filtering을 사용한다고 설명합니다. 목적도 분명합니다. Claude Code뿐 아니라 local MCP server, bash command, arbitrary process를 OS-level에서 제한하는 경량 도구입니다. 컨테이너를 매번 띄우지 않고도 파일시스템과 네트워크 제약을 줄 수 있다는 점이 실무적으로 중요합니다.
신뢰 버튼 전에 벌어지는 일
공식 글에서 가장 실용적인 대목은 취약점 회고입니다. Anthropic은 2025년 중반부터 2026년 1월 사이 Claude Code responsible disclosure program을 통해 받은 취약점 중 세 건이 사용자가 어떤 폴더를 신뢰하기 전에 실행되는 코드 경로와 관련됐다고 설명합니다. 예시는 간단합니다. 개발자가 pull request를 검토하려고 repository를 clone합니다. 그 repository 안에 .claude/settings.json이 있고, 여기에 hook이 정의돼 있습니다. Claude Code가 시작 과정에서 project setting을 읽고 hook을 실행한다면, 표준 "이 폴더를 신뢰합니까" prompt가 나오기도 전에 공격자 코드가 움직일 수 있습니다.
이 문제는 에이전트 도구만의 문제가 아닙니다. IDE, package manager, local dev server, browser extension에도 비슷한 패턴이 있습니다. "로컬 파일"이라고 해서 안전한 것이 아닙니다. 특히 agentic coding tool에서는 repository 자체가 공격자의 입력일 수 있습니다. pull request를 리뷰하는 순간, 사용자는 공격자가 만든 파일 tree를 열고 있습니다. 이 환경에서 config-load, project-open, localhost listener는 모두 inbound request처럼 취급해야 합니다.
Anthropic의 수정 방향은 같은 모양이었습니다. project-local configuration의 parsing과 execution을 trust prompt 이후로 미룹니다. 이 원칙은 코딩 에이전트 제품을 만드는 팀이 바로 가져갈 수 있는 체크리스트입니다. 첫 실행에서 어떤 파일을 자동으로 읽는가. 읽는 것과 실행하는 것의 경계는 어디인가. settings, hook, plugin, MCP config, workspace memory, CLAUDE.md 같은 파일이 신뢰 확인 전에 모델 컨텍스트나 runtime으로 들어가는가. 들어간다면 그것은 기능이 아니라 공격 표면입니다.
사용자가 직접 가져오는 prompt injection
두 번째 회고는 더 불편합니다. 2026년 2월 내부 red-team exercise에서 연구자가 직원에게 평범한 협업 요청처럼 보이는 이메일을 보냈고, 실행할 prompt를 붙였습니다. 그 prompt는 일상적인 작업 지시처럼 보였지만, 중간에 ~/.aws/credentials를 읽고 내용을 encoding한 뒤 외부 endpoint로 POST하라는 지시가 들어 있었습니다. 공격은 tool output이나 web page에서 온 것이 아니었습니다. 사용자가 직접 붙여넣은 instruction이었습니다.
이 경우 user-intent 기반 classifier는 구조적으로 약합니다. 사용자가 직접 말한 명령이기 때문입니다. 외부 문서에 "이전 지시를 무시하라"가 적혀 있으면 모델은 그 텍스트가 외부 데이터임을 표시할 수 있습니다. 그러나 사용자가 "이걸 실행해줘"라며 악성 prompt를 가져오면, 모델 입장에서는 사용자의 의도와 공격자의 의도가 섞입니다. Anthropic은 인간 contractor에게 같은 script를 건넸어도 비슷하게 행동했을 것이라고 설명합니다.
이 사례는 approval UI의 한계를 다시 보여줍니다. 사용자가 공격 경로가 되는 순간, "사용자가 승인했으니 안전하다"는 논리는 무너집니다. 방어는 사용자의 선의나 주의력에만 기대면 안 됩니다. credential이 sandbox 안에 없거나, network egress가 막혀 있거나, secret read와 external POST 조합이 deterministic policy에 걸려야 합니다. 에이전트 보안은 결국 사용자 교육이 아니라 시스템 경계의 문제로 돌아옵니다.
Cowork는 개발자를 가정하지 않습니다
세 번째 패턴은 Claude Cowork입니다. Anthropic은 Cowork를 일반 지식 노동자를 위한 desktop agent로 설명합니다. 이 사용자는 개발자처럼 bash를 읽고 rm -rf의 위험을 판단한다고 가정할 수 없습니다. 따라서 Claude Code의 human-in-the-loop sandbox 모델을 그대로 옮기면 안 됩니다. 너무 많은 승인창은 업무를 막고, 너무 적은 승인창은 사용자가 이해하지 못하는 권한을 에이전트에게 넘깁니다.
Cowork의 방향은 local VM입니다. 사용자가 선택한 workspace folder에 접근하되, 격리는 더 강하게 잡습니다. 공식 그림은 hypervisor-enforced boundary와 guest-enforced control을 나눕니다. hypervisor boundary와 vsock은 guest가 root가 되어도 버텨야 하는 층입니다. guest 내부에서는 seccomp, mount namespace, egress proxy, per-session user process isolation 같은 장치가 붙습니다. 핵심은 사용자의 oversight capacity가 낮을수록 isolation strength가 높아져야 한다는 점입니다.
| 제품 | 실행 위치 | 주요 경계 | 대가 |
|---|---|---|---|
| claude.ai | Anthropic 서버 | gVisor, ephemeral filesystem, tenant isolation | 로컬 작업공간 접근과 지속성이 제한됩니다. |
| Claude Code | 개발자 머신 | Seatbelt, bubblewrap, workspace write, default-deny network | 개발자가 drift와 권한 상승을 이해해야 합니다. |
| Claude Cowork | 로컬 VM | hypervisor boundary, mount namespace, egress proxy | 더 무겁지만 비개발자에게 더 강한 기본값을 줍니다. |
이 표는 에이전트 제품을 설계할 때의 기준을 잘 보여줍니다. 좋은 보안 설계는 하나의 universal mode가 아닙니다. 사용자가 무엇을 이해할 수 있는지, 에이전트가 어떤 자원에 접근해야 하는지, 실패했을 때 피해가 어디까지 번지는지를 보고 결정해야 합니다. 개발자에게는 마찰을 줄이는 sandbox가 맞을 수 있지만, 일반 업무 사용자를 대상으로는 더 강한 VM boundary가 필요할 수 있습니다.
devcontainer는 "무인 실행"의 다른 답입니다
Anthropic의 Claude Code devcontainer 문서도 같은 방향을 보강합니다. 문서는 Claude Code를 dev container 안에서 실행하면 명령이 host machine이 아니라 container 내부에서 실행되고, 프로젝트 파일 변경은 로컬 repository에 반영된다고 설명합니다. reference container는 firewall script로 outbound traffic을 Claude Code와 개발 도구에 필요한 domain으로 제한할 수 있습니다. container가 non-root user로 실행되고 command execution이 container 안에 갇히기 때문에, 문서는 --dangerously-skip-permissions를 unattended operation에 사용할 수 있다고 적습니다.
이 대목은 도발적으로 보입니다. "dangerously"라는 이름의 옵션을 안전하게 쓰라는 말처럼 들리기 때문입니다. 하지만 논리는 일관됩니다. 위험한 것은 승인 생략 자체가 아니라, 승인 생략이 host machine 전체 권한과 결합되는 상황입니다. 충분히 좁은 container, 제한된 network egress, non-root user, 필요한 secret만 주입하는 구조라면, 매 command마다 approval을 받는 것보다 더 예측 가능한 운영 모드가 될 수 있습니다.
코딩 에이전트가 장기 작업으로 갈수록 이 차이는 커집니다. 사람이 옆에서 모든 명령을 눌러주는 모델은 5분짜리 task에는 맞지만, 2시간짜리 refactor나 밤새 도는 issue triage에는 맞지 않습니다. 장기 실행 에이전트는 사람이 덜 보는 대신 더 강한 runtime boundary 안에 있어야 합니다. 그렇지 않으면 생산성의 이득은 승인 피로와 보안 위험으로 상쇄됩니다.
SLEIGHT-Bench와 연결되는 이유
최근 공개된 SLEIGHT-Bench는 LLM monitor가 코딩 에이전트의 위험 행동을 얼마나 놓칠 수 있는지 보여줬습니다. 그 연구의 핵심은 transcript 안에 정보가 있어도 monitor가 상태를 유지하지 못하거나, 누락을 위험으로 해석하지 못하거나, 여러 단계의 행동을 연결하지 못할 수 있다는 점이었습니다. Anthropic의 containment 글은 다른 층에서 같은 결론을 냅니다. 감시는 필요하지만, 감시가 마지막 방어선이면 약합니다.
에이전트 보안은 "무엇을 탐지했는가"와 "탐지하지 못했을 때 어디까지 갈 수 있는가"를 함께 봐야 합니다. LLM monitor가 credential exfiltration을 99% 잡더라도, 남은 1%가 실제 credential과 외부 network를 동시에 볼 수 있으면 피해는 큽니다. 반대로 monitor가 놓쳐도 credential이 mount되지 않았고, egress가 막혀 있고, workspace 밖 write가 불가능하면 피해 범위는 줄어듭니다. 이것이 blast radius 사고입니다.
따라서 에이전트 제품의 평가표도 바뀌어야 합니다. SWE-bench 점수, context window, 모델 이름, token 가격만으로는 부족합니다. 어떤 filesystem boundary가 있는지, network egress를 domain 단위로 통제할 수 있는지, MCP server와 plugin의 권한을 granular하게 줄일 수 있는지, project-local config가 trust prompt 전에 실행되지 않는지, audit log가 sandbox boundary와 연결되는지가 중요합니다. 보안은 별도 기능이 아니라 agent runtime의 일부입니다.
커뮤니티가 계속 물어본 질문
이번 May 25 글에 대한 큰 공개 토론은 아직 제한적입니다. 하지만 이전 HN과 Reddit의 Claude sandbox 논의는 이미 같은 질문을 던지고 있었습니다. HN의 Claude server-side container 스레드에서는 사용자가 Python, Node.js, proxy allowlist, PyPI와 npm 접근, data retention, multi-tenancy를 캐물었습니다. 이것은 단순한 호기심이 아닙니다. 에이전트가 코드를 실행한다는 말은 곧 "어디서, 어떤 네트워크로, 어떤 데이터 보관 정책 아래서 실행하는가"를 묻는 말입니다.
Reddit의 Claude Code 커뮤니티에서도 devcontainer, bubblewrap, Seatbelt, sandbox wrapper가 반복적으로 등장했습니다. 어떤 사용자는 permission fatigue를 줄이고 싶어 하고, 어떤 사용자는 native sandbox가 실제로 무엇을 막는지 의심합니다. 또 다른 사용자는 third-party wrapper로 더 강한 isolation을 만들려 합니다. 이 흐름은 코딩 에이전트 시장의 성숙 신호입니다. 사용자는 더 이상 "AI가 코드를 써준다"만 보지 않습니다. AI가 내 shell에서 무엇을 할 수 있는지 묻기 시작했습니다.
이 질문은 앞으로 더 중요해질 것입니다. OpenAI Codex, GitHub Copilot coding agent, Cursor, Google Antigravity, Claude Code가 모두 더 긴 작업과 더 많은 자동 실행을 향해 갑니다. 에이전트가 PR을 만들고, CI를 고치고, issue를 triage하고, incident context를 모으는 동안 사용자는 결과물만 봅니다. 중간 행동은 runtime과 log의 문제가 됩니다. 제품 경쟁은 결국 "누가 더 똑똑한가"와 함께 "누가 더 검증 가능한 경계 안에서 똑똑한가"로 갈 수밖에 없습니다.
기업 도입 체크리스트가 바뀝니다
기업이 코딩 에이전트를 도입할 때 흔히 묻는 질문은 모델 성능, 가격, 데이터 사용 정책, SSO, admin console입니다. 이제 여기에 runtime containment가 들어가야 합니다. 첫째, 에이전트는 어디에서 실행되는가. host machine, container, remote sandbox, local VM 중 무엇인가. 둘째, workspace 밖 파일을 읽을 수 있는가. 셋째, secret은 어떻게 주입되고, 어떤 명령이 secret에 접근할 수 있는가. 넷째, network egress는 기본 허용인가 기본 거부인가. 다섯째, project-local config와 hook은 trust boundary 이후에만 실행되는가.
여섯째, 사용자의 승인 능력을 어떻게 가정하는가. senior engineer가 shell command를 감독하는 상황과, 영업팀 직원이 spreadsheet agent를 쓰는 상황은 다릅니다. 같은 approval dialog를 보여주는 것은 공평해 보이지만 안전하지 않을 수 있습니다. 일곱째, monitor가 놓쳤을 때 피해 범위는 어디까지인가. LLM classifier가 83%를 잡는다는 숫자는 유용하지만, 남은 17%가 어떤 boundary 안에서 움직이는지가 더 중요합니다.
마지막으로, custom component를 줄여야 합니다. Anthropic은 battle-tested hypervisor, syscall filter, container runtime을 선호하라고 조언합니다. 이 말은 AI 에이전트에도 전통적 보안 공학이 통한다는 뜻입니다. 에이전트는 새 소프트웨어 범주처럼 보이지만, 결국 파일을 읽고 소켓을 열고 프로세스를 띄웁니다. 그러므로 오래 공격받아온 OS primitive와 network control이 여전히 강력합니다. 새로운 것은 모델의 언어 능력이고, 시스템 호출 자체는 오래된 영역입니다.
프롬프트 방어를 낮게 보는 것이 아닙니다
이 글을 "프롬프트 방어는 쓸모없다"로 읽으면 잘못입니다. Anthropic은 모델 계층의 성과를 강조합니다. prompt injection robustness, auto mode classifier, static analysis, human oversight는 모두 필요합니다. 다만 그 계층이 확률적이라는 점을 인정해야 합니다. 모델은 위험 행동을 덜 하게 만들 수 있지만, 운영자는 모델이 틀릴 때를 설계해야 합니다.
실무적으로는 세 가지 조합이 필요합니다. 낮은 위험 작업은 마찰을 줄여야 합니다. 파일 읽기, workspace 내부 formatting, test 실행처럼 sandbox 안에서 끝나는 작업은 자주 묻지 않는 편이 낫습니다. 높은 위험 작업은 deterministic boundary를 둬야 합니다. secret access, external network POST, package publish, deployment, git hook 변경은 policy로 막거나 강한 승인을 요구해야 합니다. 그리고 장기 작업은 isolated runtime에서 돌려야 합니다. 사람이 지켜보지 않는 시간만큼 boundary는 더 강해야 합니다.
이 구조가 잘 잡히면 에이전트는 더 자유롭게 일할 수 있습니다. 역설적으로 강한 격리는 더 많은 자동화를 가능하게 합니다. Anthropic이 "tight perimeter means you can relax oversight"라고 말하는 이유도 여기에 있습니다. 에이전트가 안전한 울타리 안에 있으면, 사용자는 모든 발걸음을 승인하지 않아도 됩니다. 반대로 울타리가 없으면 승인창이 많아져도 사용자는 피로해지고, 보안은 사람의 집중력에 의존하게 됩니다.
승인 버튼 이후의 에이전트 보안
이번 Anthropic 공개의 메시지는 명확합니다. 에이전트 시대의 보안은 승인 버튼에서 끝나지 않습니다. 승인 버튼은 인터페이스일 뿐이고, 진짜 질문은 그 버튼 뒤에서 어떤 파일시스템, 어떤 네트워크, 어떤 process boundary, 어떤 trust order가 적용되는가입니다. 특히 코딩 에이전트는 repository 자체가 입력이고, 설정 파일이 실행 경로가 되며, 사용자가 공격자의 prompt를 직접 가져올 수도 있습니다. 이 환경에서는 "사용자가 허락했다"가 충분한 근거가 되지 않습니다.
그래서 제목의 84%는 단순한 UX 숫자가 아닙니다. permission prompt가 84% 줄었다는 것은 approval UI를 줄이면서도 보안 경계를 유지하려는 설계 방향을 보여줍니다. 그 방법은 더 똑똑한 모델 하나가 아니라 OS-level sandbox, default-deny network, trust-before-config-load, local VM, standard primitive입니다. 코딩 에이전트가 점점 더 긴 작업과 더 깊은 권한을 얻는다면, 이런 runtime containment는 부가 기능이 아니라 기본 인프라가 됩니다.
개발팀이 오늘 가져갈 결론은 간단합니다. 에이전트를 도입할 때 모델 이름만 보지 말고, 에이전트가 실패했을 때 어디까지 갈 수 있는지 보아야 합니다. 그것이 blast radius입니다. 그리고 blast radius를 줄이는 일은 프롬프트보다 아래, 운영체제와 네트워크와 파일시스템의 층에서 시작됩니다.
출처: Anthropic Engineering, Anthropic Sandbox Runtime GitHub repository, Claude Code devcontainer docs, Claude Code auto mode, Hacker News discussion.