+0.83개 언어, Claude Code가 낮춘 새 기술 진입 장벽
Claude Code 도입 전후 5,838명 GitHub 패널 연구는 AI 코딩 도구가 생산성뿐 아니라 개발자의 언어 경계를 넓힐 수 있음을 보여줍니다.
- 무슨 일: arXiv에
Claude Code도입 전후 개발자 행동을 추적한 5,838명 패널 연구가 공개됐습니다.- 논문은 28개월 GitHub 활동과 7,786,771개 Claude co-authored commit을 분석했습니다.
- 핵심 숫자: adoption month에 commit은 +40.7, 저장소는 +1.5, 사용 언어는 +0.83으로 추정됐습니다.
- 의미: AI 코딩 도구의 효과가 속도 향상을 넘어
낯선 언어로 이동하는 비용을 낮추는 방향일 수 있습니다.- 저자는 이를 AI가 unfamiliar technology에 대한 free signal을 제공하는 Bayesian learning model로 해석합니다.
- 주의점: Claude Code 채택은 자발적이므로, 논문도 strict causal claim보다 동시 발생한 행동 변화로 읽어야 한다고 선을 긋습니다.
AI 코딩 도구를 이야기할 때 가장 자주 묻는 질문은 "얼마나 빨라졌는가"입니다. GitHub Copilot 이후 연구와 마케팅 자료는 작업 완료 시간, pull request 수, 테스트 통과율, SWE-bench 점수 같은 지표를 중심으로 쌓였습니다. 그 질문은 여전히 중요합니다. 하지만 개발자의 실제 커리어와 팀의 기술 선택을 생각하면 다른 질문도 필요합니다. AI 코딩 도구는 개발자가 이미 아는 언어에서 더 빨리 일하게 할 뿐일까요. 아니면 낯선 언어와 낯선 저장소에 들어가는 심리적, 기술적 비용까지 낮출까요.
2026년 5월 25일 arXiv에 올라온 Coding Beyond Your Training: Claude Code and the Technological Frontier of Software Developers는 이 두 번째 질문을 정면으로 다룹니다. Alexander Quispe의 이 예비 논문은 Claude Code 도입을 개발자의 "technological frontier" 확장 문제로 봅니다. 여기서 frontier는 거창한 국가 단위 기술 경계가 아니라, 한 개발자가 실제로 커밋하는 프로그래밍 언어와 저장소의 범위입니다. 즉 "이 사람이 이번 달에 어떤 언어로, 몇 개 저장소에, 얼마나 다양한 기술 조합으로 기여했는가"를 보는 방식입니다.
논문이 흥미로운 이유는 Claude Code 자체의 기능 소개가 아니라 관측 방식에 있습니다. Claude Code는 commit에 Co-Authored-By: Claude 형태의 trailer를 남길 수 있고, 이 metadata는 GitHub public event API에서 대규모로 관측됩니다. 저자는 2025년 1월부터 2026년 1월까지 7,786,771개 Claude co-authored commit을 수집했고, 여기서 185,517명의 distinct author를 확인했습니다. 이어 early adopter와 later adopter를 나눠 5,838명 개발자의 28개월 공개 GitHub 활동 패널을 만들었습니다.
이 숫자만 보면 "Claude Code가 개발자를 두 배 생산적으로 만들었다"는 식의 헤드라인을 뽑기 쉽습니다. 하지만 논문의 더 중요한 부분은 작업량보다 언어 포트폴리오입니다. adoption month에 개발자가 사용한 distinct programming languages는 0.83개 늘었고, 이전에 쓰지 않았던 newly-used languages도 0.31개 늘었습니다. 누적 lifetime languages 효과는 시간이 지나며 커지는 패턴을 보였습니다. 이것이 단순한 자동완성 도구 이야기와 다른 지점입니다. AI가 코드 한 줄을 더 빨리 쓰게 한 것이 아니라, 개발자가 "내가 모르는 언어라서 못 들어가겠다"고 느끼던 문턱을 낮췄을 가능성을 보여주기 때문입니다.
논문이 실제로 본 데이터
저자는 Claude Code가 2025년 2월 beta로, 2025년 5월 general availability로 나왔다고 설명합니다. 분석의 핵심은 rollout이 한 번에 끝난 사건이 아니라, 2025년 5월부터 2026년 1월까지 GitHub 개발자 사이에 시간차를 두고 확산됐다는 점입니다. 이 시간차 덕분에 먼저 채택한 개발자와 나중에 채택한 개발자를 비교할 수 있습니다.
treated sample은 2025년 2분기와 3분기에 첫 Claude commit을 남긴 early adopter입니다. control sample은 2025년 4분기와 2026년 1분기에 처음 채택한 not-yet-treated developer입니다. 나중에 결국 Claude Code를 쓰는 사람들을 control로 잡았기 때문에, "AI 코딩 도구에 관심 있는 개발자"라는 큰 취향 차이는 일부 줄어듭니다. 논문은 이 접근을 Callaway and Sant'Anna 방식의 staggered adoption 설계와 연결합니다.
최종 main sample은 pre-adoption commit activity가 있는 5,838명입니다. 이 중 3,060명이 treated, 2,778명이 control이고, developer-month observation은 163,464개입니다. 저자는 GitHub GraphQL contributionsCollection endpoint로 2024년 1월부터 2026년 4월까지 매월 공개 기여 기록을 다시 가져왔습니다. 여기에는 commit 수, repository 수, GitHub Linguist 기준 primary language, 언어별 byte distribution, repository metadata가 포함됩니다.
결과 변수는 여섯 개입니다. 첫째는 월별 commit 수입니다. 둘째는 그 달에 기여한 distinct repositories 수입니다. 셋째는 그 달에 사용한 distinct primary languages 수입니다. 넷째는 language entropy입니다. 언어 수뿐 아니라 언어 사용 분포가 얼마나 균형 잡혔는지 보는 Shannon entropy입니다. 다섯째는 newly-used languages입니다. 해당 개발자가 이전 어느 달에도 쓰지 않았던 언어가 그 달에 새로 등장했는지 봅니다. 여섯째는 cumulative languages입니다. 관측 기간 동안 한 개발자가 지금까지 써본 distinct languages의 누적 개수입니다.
이 설계가 좋은 이유는 "코드를 더 많이 썼다"와 "기술 경계가 넓어졌다"를 분리하려 하기 때문입니다. commit 수만 늘었다면 생산성 또는 자동화 효과일 수 있습니다. repository 수가 늘었다면 더 많은 작업면을 건드린 것입니다. 하지만 새 언어와 누적 언어 수가 늘었다면 이야기가 달라집니다. 개발자가 기존 전문 영역 안에서 더 빨리 움직인 것이 아니라, 이전에 쓰지 않았던 기술로 이동했을 가능성이 생깁니다.
+41 commits보다 +0.83 languages가 더 중요합니다
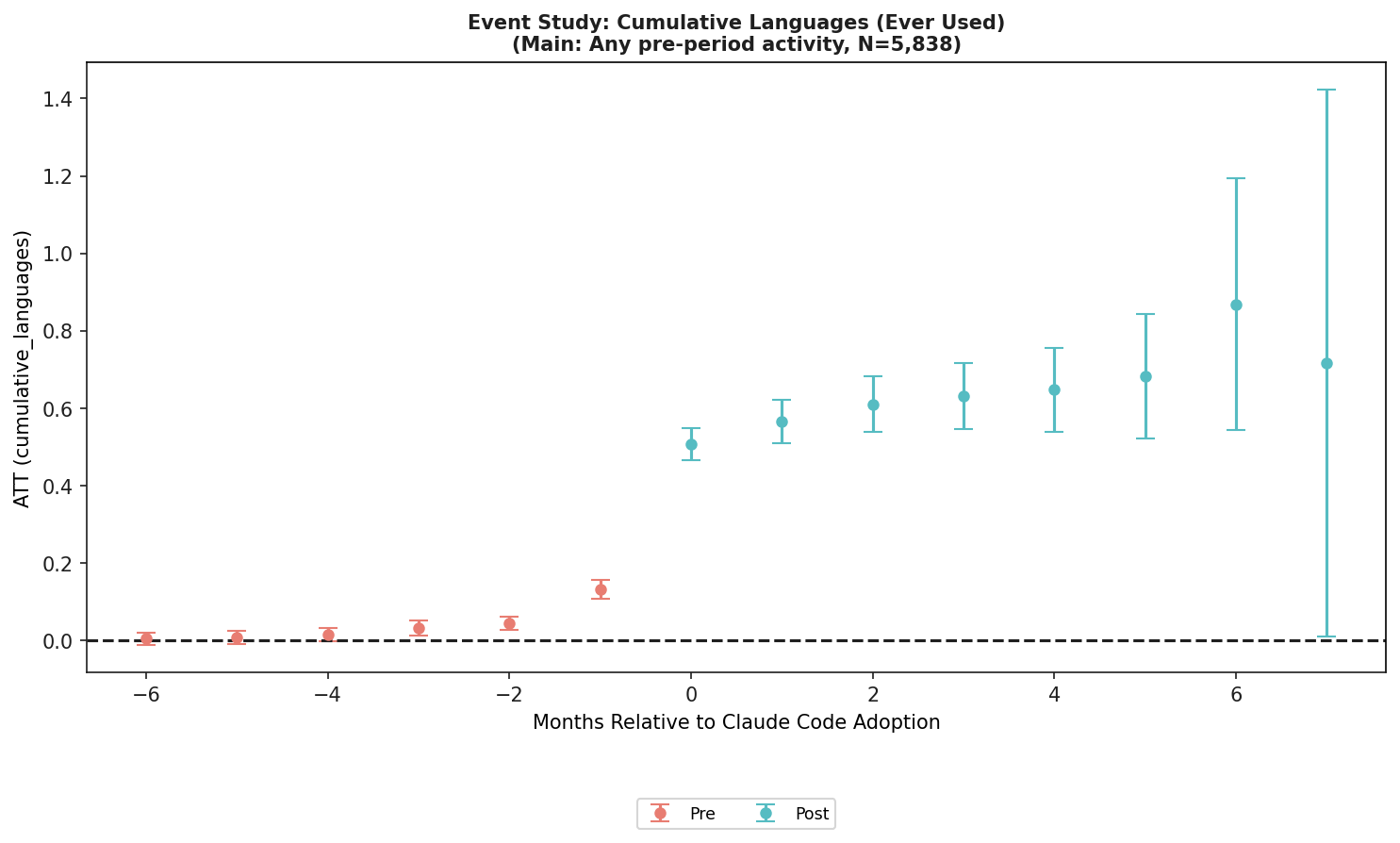
논문의 Table 2에서 adoption month의 ATT는 모두 양수입니다. 월별 commit은 +40.708, repositories는 +1.497, programming languages는 +0.830, language entropy는 +0.138, newly-used languages는 +0.308, cumulative languages는 +0.507입니다. 저자는 bootstrap standard error를 developer 단위로 cluster했고, 모든 adoption month 추정치가 통계적으로 유의하다고 보고합니다.
가장 눈에 띄는 숫자는 commit +40.7입니다. treated developer의 pre-adoption 월별 commit 평균이 21.3이었다는 점을 생각하면 큰 변화입니다. 논문은 simple ATT 기준으로도 +20.8 commits가 남는다고 설명합니다. 즉 adoption month의 급격한 상승은 일부 줄어들지만, post-adoption 평균에서도 activity boost가 사라지지는 않습니다.
하지만 이 글의 중심은 commit 수가 아닙니다. commit 수는 해석이 넓습니다. AI가 boilerplate를 많이 만들었을 수 있고, 작은 commit을 더 자주 쪼갰을 수 있으며, 프로젝트 시작 시점의 활동 증가가 반영됐을 수도 있습니다. 반면 programming languages +0.83은 더 구체적인 신호입니다. treated developer의 pre-adoption distinct language 평균이 0.63이었다는 점을 감안하면, adoption month에 거의 "한 언어"가 추가된 셈입니다.
논문은 newly-used languages도 별도로 봅니다. adoption month ATT는 +0.308입니다. 이 지표는 단순 commit volume 증가만으로 설명하기 어렵습니다. 같은 JavaScript 프로젝트에서 commit이 40개 늘어도 newly-used languages는 늘지 않습니다. 개발자가 이전 관측 기간에 쓰지 않았던 언어로 실제 기여를 해야 숫자가 움직입니다. 저자는 이 지점을 portfolio-expansion mechanism의 경험적 서명으로 봅니다.
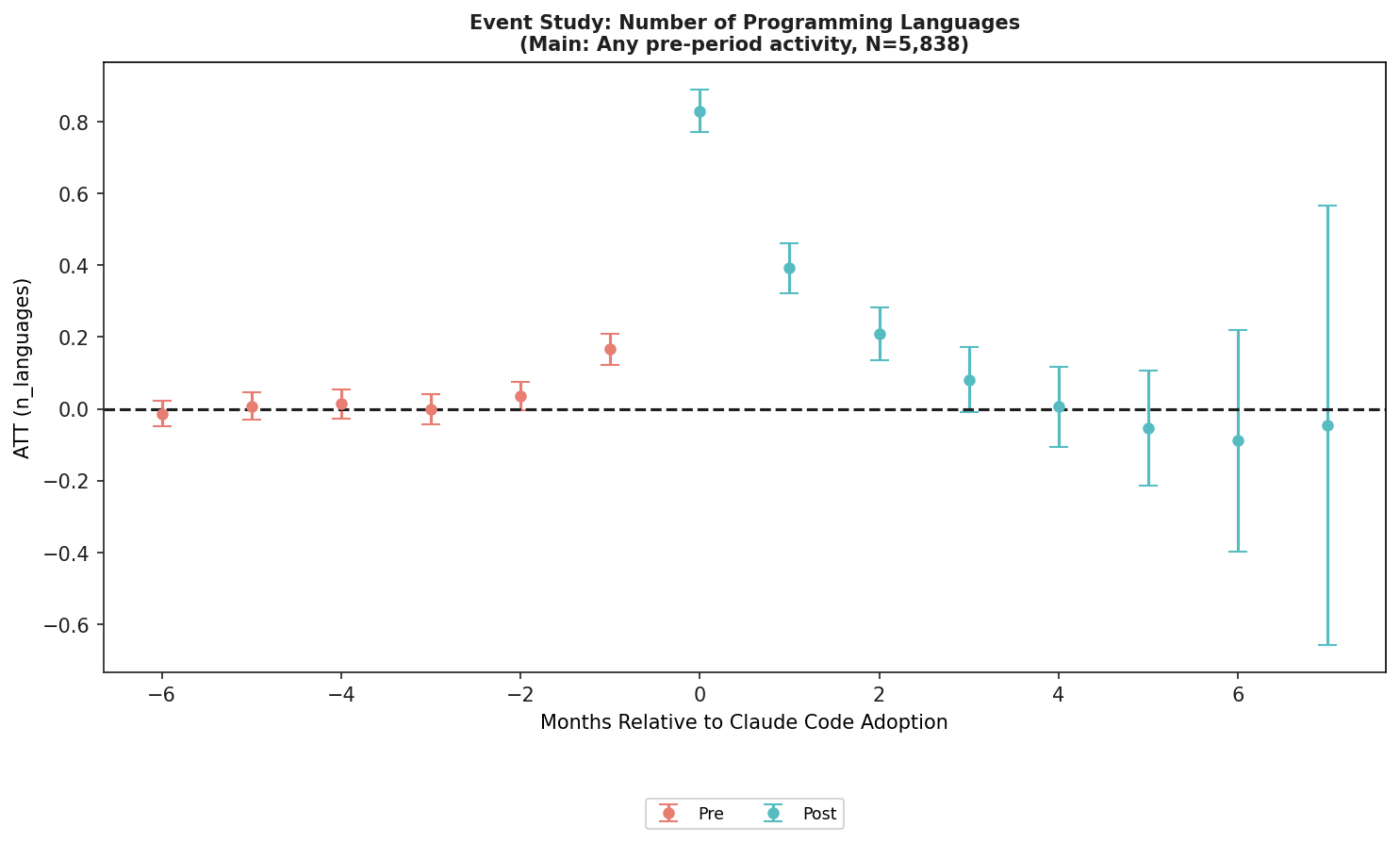
본문 그림은 논문 공식 HTML의 programming languages event-study입니다. 저작권 표기는 arXiv HTML의 CC BY 4.0 라이선스를 따릅니다. 그래프의 메시지는 adoption month의 jump와 이후 일부 되돌림입니다. 즉 "Claude Code를 켠 순간 모든 달에 계속 같은 크기로 언어 수가 늘었다"기보다는, 새 프로젝트나 새 작업에 들어가는 adoption month에 변화가 가장 크고 이후에는 안정화되는 모양입니다.
AI를 free signal channel로 보는 모델
논문은 결과를 설명하기 위해 Bayesian learning model을 둡니다. 개발자는 각 프로그래밍 언어에서 자신의 생산성에 대한 믿음을 갖고 있습니다. 이미 써본 언어에 대해서는 precision이 높고, 써보지 않은 언어에 대해서는 precision이 낮습니다. 위험 회피적인 개발자는 낯선 언어로 전환하기를 꺼립니다. 새 언어에서 얼마나 잘할지 모르기 때문입니다. 이 uncertainty가 switching barrier가 됩니다.
AI 코딩 도구는 여기서 "free signal channel"로 들어옵니다. 개발자가 Rust를 깊이 알지 못해도, Claude Code가 syntax를 설명하고, compiler error를 해석하고, idiomatic pattern을 제안하고, 작은 실행 가능한 코드를 만들어주면 Rust에 대한 실질적 신호를 얻습니다. 직접 months-long learning-by-doing을 하지 않아도, 낯선 언어의 생산성 분포에 대한 불확실성이 줄어듭니다. 그러면 entry threshold를 넘는 언어가 늘어납니다.
이 관점은 AI 코딩 도구를 autocomplete보다 넓게 보게 만듭니다. 자동완성은 "내가 쓰던 코드의 다음 줄"에 가깝습니다. coding agent는 "내가 잘 모르는 생태계에서 첫 발을 떼는 비용"에 더 가깝습니다. 문법, build tool, package manager, test runner, error message, framework convention을 한꺼번에 물어볼 수 있기 때문입니다. 개발자가 새 언어를 시도할 때 가장 큰 마찰은 공식 문서가 없는 것이 아니라, 작고 낯선 실패를 계속 해석해야 한다는 점입니다. AI는 이 실패 해석 비용을 낮춥니다.
누적 언어 수 결과가 중요한 이유도 여기에 있습니다. 논문의 cumulative languages simple ATT는 +0.586으로 adoption month ATT +0.507보다 큽니다. event-study profile도 시간이 지나며 증가하는 형태라고 설명됩니다. 월별 commit이나 월별 language count는 adoption 이후 일부 되돌아가지만, 한 번 새 언어를 써본 기록은 누적됩니다. 만약 AI가 새 언어에 대한 낮은 비용의 신호를 계속 제공한다면, 개발자는 시간이 지나며 더 많은 threshold crossing을 경험할 수 있습니다.
이것은 기업 교육과 채용에도 다른 질문을 던집니다. 지금까지 "Python 개발자를 Go 개발자로 전환할 수 있는가"는 교육, 멘토링, 코드 리뷰, 프로젝트 배치 문제였습니다. AI 코딩 도구가 실제로 switching barrier를 낮춘다면, 팀은 기술 전환 계획을 다르게 설계할 수 있습니다. 단순히 "AI로 더 빨리 구현하자"가 아니라, "AI와 함께 새로운 언어와 시스템을 탐색하는 onboarding 경로를 만들자"가 됩니다.
생산성 연구와 다른 지점
기존 AI 코딩 연구에는 GitHub Copilot의 task completion time, 기업 field experiment, code generation benchmark가 많이 있습니다. 이런 연구들은 중요한 질문을 다룹니다. 같은 과제를 더 빨리 끝내는가. 코드 품질은 유지되는가. 경험 많은 개발자와 초보 개발자에게 효과가 다른가. 하지만 대부분은 과제가 이미 주어져 있고, 작업 범위도 비교적 고정되어 있습니다.
이번 논문은 범위를 바꿉니다. 개발자가 어떤 일을 선택하는지, 어떤 언어로 들어가는지, 몇 개 저장소를 건드리는지를 봅니다. 생산 함수의 속도만이 아니라 생산 함수의 domain 자체를 봅니다. 그래서 "AI가 개발자를 대체하는가"보다 "AI가 개발자의 기술 선택 집합을 넓히는가"에 가깝습니다.
이 차이는 실무에서 큽니다. 예를 들어 한 백엔드 개발자가 기존 Node.js 서비스만 고치는 상황과, 같은 개발자가 Rust 기반 CLI, Python 데이터 파이프라인, Terraform 모듈까지 손대는 상황은 조직의 운영 방식이 다릅니다. 두 경우 모두 commit 수는 늘 수 있지만, 후자는 팀 구조와 코드 소유권, 리뷰 정책, incident response까지 영향을 줍니다. AI가 경계를 넓힌다면 좋은 점만 있는 것은 아닙니다. 더 많은 영역을 건드릴 수 있다는 것은 더 많은 잘못된 확신과 더 넓은 blast radius도 의미합니다.
따라서 이 논문은 AI 코딩 도구 도입 지표를 다시 생각하게 합니다. 도입률, seat 수, token 사용량, PR 수만 보면 놓치는 부분이 있습니다. 팀은 AI 도구 사용 후 개발자가 어떤 언어와 저장소로 이동하는지, review load가 어디로 쏠리는지, 신규 언어에서 defect rate가 늘지 않는지, domain expert가 없는 코드가 늘어나는지 봐야 합니다. frontier expansion은 기회이면서 governance 문제입니다.
인과라고 말하기 어려운 이유
논문은 자신의 약점을 비교적 정직하게 씁니다. Claude Code adoption은 자발적입니다. 어떤 개발자가 낯선 Rust 프로젝트를 시작하기로 마음먹고, 바로 그 이유 때문에 Claude Code를 설치했을 수 있습니다. 이 경우 첫 Claude commit과 첫 Rust commit은 같은 달에 나타납니다. 데이터에서는 Claude adoption과 language diversification이 동시에 보이지만, 실제 원인은 "새 프로젝트 시작"일 수 있습니다.
저자는 이를 reverse-causal selection이라고 부릅니다. staggered DiD 설계는 cohort heterogeneity와 일반적인 TWFE negative weighting 문제를 줄일 수 있지만, treatment timing이 새 프로젝트 시작과 함께 결정되는 문제를 완전히 해결하지 못합니다. 논문은 따라서 "strict causal claim"을 하지 않습니다. 가장 방어적인 해석은 Claude adoption과 동시에 sharp하고 persistent한 developer behavior shift가 관측됐고, 그 패턴이 AI-as-signal mechanism과 정량적으로 맞는다는 것입니다.
이 주의점은 기사에서도 중요합니다. "Claude Code가 개발자에게 새 언어를 가르쳤다"라고 단정하면 과장입니다. 더 정확한 문장은 "Claude Code 도입과 같은 시점에 개발자가 더 많은 언어와 저장소에 기여하는 패턴이 나타났고, 일부 누적 지표는 이후에도 커졌다"입니다. 이 차이는 작아 보이지만 큽니다. 전자는 제품 효과 주장이고, 후자는 관측 연구의 결과입니다.
논문은 더 강한 인과 추론을 위한 경로도 제안합니다. 예를 들어 free tier의 지역별 rollout, 가격 변화, 기관 구독 eligibility cutoff 같은 외생적 variation이 있으면 instrumental variables나 regression discontinuity 설계를 만들 수 있습니다. 또는 풍부한 pre-period covariate로 conditional parallel trends를 더 설득력 있게 검증할 수 있습니다. fake adoption date를 이용한 placebo treatment도 방법입니다. 즉 이번 논문은 최종 판결이라기보다 다음 연구가 붙을 수 있는 첫 큰 관측 프레임에 가깝습니다.
그래도 왜 뉴스인가
인과가 제한적이라면 왜 이 논문을 뉴스로 다룰 만할까요. 이유는 두 가지입니다. 첫째, 공개 GitHub metadata를 이용해 AI 코딩 도구의 대규모 행동 변화를 측정하려 했다는 점입니다. AI coding adoption은 빠르게 커졌지만, 실제 사용이 어떤 developer-month 변화로 이어지는지 보는 데이터는 제한적입니다. vendor가 제공하는 내부 수치나 설문보다, 공개 commit metadata와 contribution history를 결합한 접근은 독립적 검증의 출발점이 됩니다.
둘째, 질문의 방향이 좋습니다. AI 코딩 도구가 업무 시간을 줄이는지 묻는 것만으로는 2026년의 에이전트 현실을 설명하기 어렵습니다. Codex, Claude Code, Cursor, GitHub Copilot, Google Antigravity 같은 도구는 점점 "한 파일 보조"에서 "저장소 전체 작업"으로 이동하고 있습니다. 이때 개발자는 더 많은 코드를 쓰는 사람이 아니라, 더 많은 기술 경계에 들어가는 사람이 될 수 있습니다. 그 변화는 생산성 통계보다 조직 설계에 더 큰 영향을 줍니다.
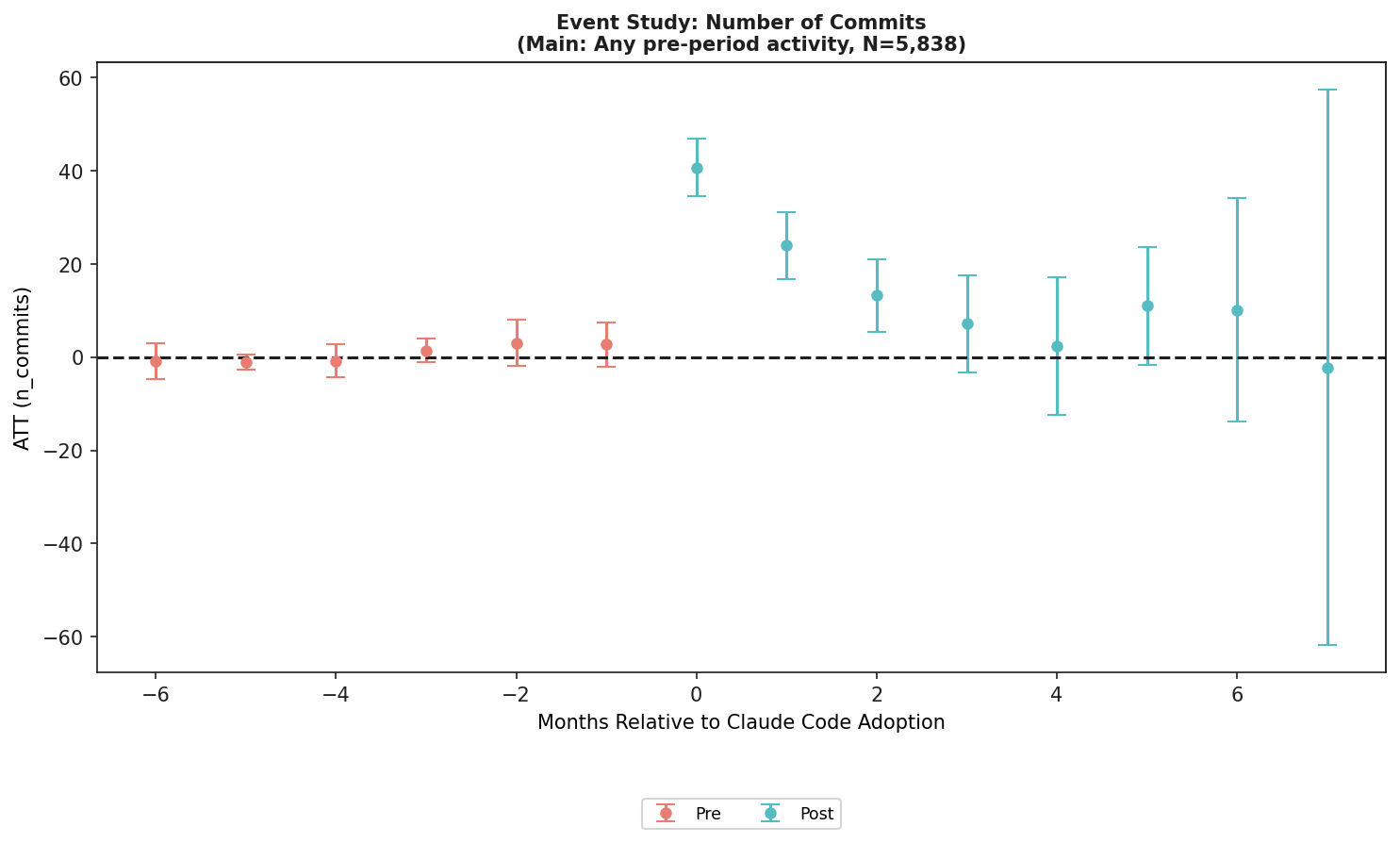
commit event-study는 생산성 헤드라인을 설명하는 데 유용합니다. adoption month의 상승이 크고, 이후에도 일부 효과가 남습니다. 하지만 이 그림만 보면 AI 코딩 도구 논의가 다시 "얼마나 많이 만들었나"로 돌아갑니다. 그래서 언어 수 그림과 함께 읽어야 합니다. 작업량이 늘어난 동시에 작업 범위가 넓어졌는지가 이 논문의 핵심이기 때문입니다.
개발팀이 가져갈 실무 질문
이 논문을 읽고 바로 "Claude Code를 도입하면 우리 팀도 언어 범위가 넓어진다"고 결론내릴 필요는 없습니다. 대신 다음 질문을 실무 지표로 바꿔볼 수 있습니다.
첫째, AI 도구 사용자가 새 언어와 새 저장소에 더 자주 들어가는가. 사내 GitHub나 GitLab에서도 비슷한 패널을 만들 수 있습니다. AI 도구 사용 전후로 repository count, language count, first-time language contribution을 보면 됩니다. 둘째, 그 확장이 품질 저하 없이 일어나는가. 새 언어 contribution의 review cycle time, rollback, incident, test failure, security finding을 함께 봐야 합니다. 셋째, 누가 확장의 혜택을 받는가. 논문은 specialist와 generalist 차이를 이론적으로 언급하지만, 실무에서는 junior, senior, platform team, product team, contractor 사이의 차이가 더 중요할 수 있습니다.
넷째, AI가 낮춘 것은 학습 비용인가, 검증 비용인가. 새 언어로 첫 PR을 만드는 비용이 줄어도, 그 PR을 안전하게 리뷰하는 비용은 줄지 않을 수 있습니다. 오히려 reviewer는 "이 사람이 원래 모르는 언어를 AI로 작성했다"는 점 때문에 더 세심하게 봐야 합니다. frontier expansion이 조직에 이익이 되려면, code owner와 reviewer, 테스트 인프라, style guide, dependency policy가 같이 따라와야 합니다.
다섯째, AI 도구는 reskilling 프로그램과 어떻게 결합되는가. 개발자가 낯선 언어로 들어갈 수 있다면, 교육은 문법 강의보다 검증 루프 중심으로 바뀔 수 있습니다. 예를 들어 Rust를 처음 쓰는 팀원에게 AI를 금지할 것이 아니라, AI가 만든 코드를 cargo clippy, property test, unsafe policy, ownership review와 함께 통과시키게 할 수 있습니다. 도구가 학습을 대체한다기보다, 낮은 비용의 시도와 빠른 피드백을 제공하는 방식입니다.
개인 개발자의 경계가 넓어질 때 생기는 위험
긍정적 해석만 하면 부족합니다. 개발자가 더 많은 언어를 건드릴 수 있다는 것은 권한과 책임의 경계도 흐려진다는 뜻입니다. 예전에는 "이 저장소는 Go 팀만 만진다"는 암묵적 규칙이 있었습니다. AI 코딩 도구가 있으면 TypeScript 개발자도 Go 코드를 수정해 PR을 만들 수 있습니다. 때로는 이것이 병목을 없앱니다. 하지만 ownership이 흐려지고, 깊은 runtime 지식 없이 표면적 수정이 늘어날 수도 있습니다.
또 다른 위험은 "언어를 썼다"와 "언어를 이해했다"의 차이입니다. GitHub contribution history에서 새 언어가 등장했다는 것은 해당 언어로 commit이 있었다는 뜻이지, 개발자가 그 생태계의 운영 관행을 습득했다는 뜻은 아닙니다. AI가 syntax와 오류 메시지를 처리해주면 초입 장벽은 낮아지지만, performance trap, security footgun, concurrency model, deployment convention까지 자동으로 이해하게 되는 것은 아닙니다.
그래서 팀의 목표는 AI로 경계를 무한히 넓히는 것이 아니라, 넓어진 경계를 검증 가능하게 만드는 것입니다. 새 언어 PR에는 더 강한 CI와 template이 필요합니다. AI-generated contribution에는 설명 가능한 design note가 필요합니다. code owner는 "AI가 돌아가게 만든 코드"와 "팀이 장기 유지보수할 수 있는 코드"를 구분해야 합니다. 논문의 숫자가 맞다면, 이런 governance는 선택 사항이 아니라 필수입니다.
이번 논문을 어떻게 읽어야 하나
가장 균형 잡힌 읽기는 이렇습니다. Claude Code adoption은 개발자의 공개 GitHub 활동에서 큰 변화와 함께 나타났습니다. commit과 repository는 늘었고, 사용 언어와 새 언어도 늘었습니다. 누적 언어 수 효과는 시간이 지나며 커졌습니다. 이 패턴은 AI가 낯선 기술에 대한 신호를 제공해 switching barrier를 낮춘다는 모델과 잘 맞습니다. 그러나 adoption이 자발적이기 때문에, 새 프로젝트를 시작한 개발자가 Claude를 채택했을 가능성을 배제할 수 없습니다.
그럼에도 이 연구는 AI 코딩 도구 논의를 한 단계 옮깁니다. 이제 "AI가 코드를 더 빨리 쓰는가"만 묻기에는 부족합니다. 더 중요한 질문은 "AI가 개발자가 시도하는 기술의 범위를 바꾸는가"입니다. 만약 답이 그렇다면, AI 코딩 도구는 생산성 도구이면서 동시에 학습 인프라, reskilling 장치, 조직 경계 재편 도구가 됩니다.
개발자에게 이것은 기회입니다. 낯선 언어를 처음 시도하는 비용이 낮아질 수 있습니다. 팀에게는 숙제입니다. 더 넓어진 contribution surface를 검증하고, 리뷰하고, 유지보수할 구조를 만들어야 합니다. AI 코딩 에이전트의 다음 평가지표는 단순히 "몇 줄을 썼는가"가 아니라 "어떤 기술 경계를 넘었고, 그 경계를 안전하게 운영할 수 있는가"가 될 가능성이 큽니다.