1만개 버그 뒤의 병목, Mythos가 당긴 패치 속도전
Anthropic Project Glasswing 초기 결과는 AI 보안 모델이 취약점 발견보다 검증과 패치 처리량을 새 병목으로 만든다는 신호입니다.

- 무슨 일: Anthropic이
Project Glasswing첫 달 결과를 공개하며 Mythos Preview가 1만 개 이상 고위험 취약점 발견에 관여했다고 밝혔습니다.- 오픈소스 스캔에서는 6,202개 high/critical 후보, 검증 표본 기준 90.6% true positive가 제시됐습니다.
- 핵심 병목: 취약점 발견보다 검증, 보고, 패치, 배포가 더 느린 단계로 드러났습니다.
- Anthropic은 high/critical 취약점 하나를 패치하는 평균 시간이 2주라고 설명합니다.
- 개발자 영향: 보안 자동화의 경쟁력은 모델 호출보다 triage queue, maintainer workflow, disclosure policy, 기본 방어 체계로 이동합니다.
- 주의점: Mythos급 모델은 아직 일반 공개되지 않았고, Anthropic도 오용 방지 장치가 충분하지 않다고 말합니다.
Anthropic이 2026년 5월 22일 공개한 Project Glasswing 초기 업데이트는 "AI가 취약점을 잘 찾는다"는 익숙한 문장보다 더 까다로운 질문을 던집니다. 정말 중요한 변화는 발견 성능 하나가 아니라, 발견 속도가 패치 속도를 앞지르기 시작했다는 점입니다. 소프트웨어 보안에서 오랫동안 비용이 컸던 일은 새로운 취약점을 찾아내는 것이었습니다. 그런데 Mythos Preview 같은 사이버 특화 frontier 모델이 그 비용을 급격히 낮추면, 다음 병목은 인간 검증자, maintainer, coordinated disclosure, 릴리스 엔지니어링, 고객 배포로 옮겨갑니다.
공식 숫자는 꽤 공격적입니다. Anthropic은 Project Glasswing 파트너들이 첫 달에 합산 1만 개 이상의 critical 또는 high severity 취약점을 찾았다고 말합니다. Cloudflare는 핵심 경로 시스템에서 2,000개 버그를 찾았고, 그중 400개가 high 또는 critical severity였다고 발표에 인용됐습니다. Mozilla는 Firefox 150에서 Mythos Preview를 활용해 271개 취약점을 찾아 고쳤고, Anthropic은 이 수치가 Firefox 148에서 Claude Opus 4.6으로 찾은 것보다 10배 이상 많았다고 설명합니다.
하지만 이 글의 주인공은 "1만 개"라는 숫자 자체가 아닙니다. 숫자의 뒤쪽에 붙은 처리량입니다. Anthropic은 1,000개 이상의 오픈소스 프로젝트를 스캔해 총 23,019개 취약점 후보를 얻었고, 그중 6,202개를 high 또는 critical로 추정했습니다. 여기서 끝나지 않습니다. 1,752개 high/critical 후보가 독립 보안 연구사 또는 Anthropic의 검증을 거쳤고, 90.6%인 1,587개가 유효한 true positive로 확인됐습니다. 그중 62.4%인 1,094개는 실제로 high 또는 critical severity로 재확인됐습니다.
숫자만 보면 방어자가 마침내 속도를 얻은 듯합니다. 그러나 Anthropic이 이어서 보여준 것은 훨씬 현실적인 병목입니다. 2026년 5월 22일 기준 공개 대시보드에는 281개 오픈소스 프로젝트에 보고한 1,596개 취약점, 패치된 97개, CVE 또는 GHSA가 붙은 88개가 표시됐습니다. oss-sec 메일링 리스트에서도 같은 수치를 인용하며, 여기서 "disclosed"는 공개됐다는 뜻이 아니라 maintainer에게 보고됐다는 뜻이라고 짚었습니다. 발견은 대량으로 쌓이지만, 공개 가능한 상태까지 이동하는 항목은 훨씬 적습니다.
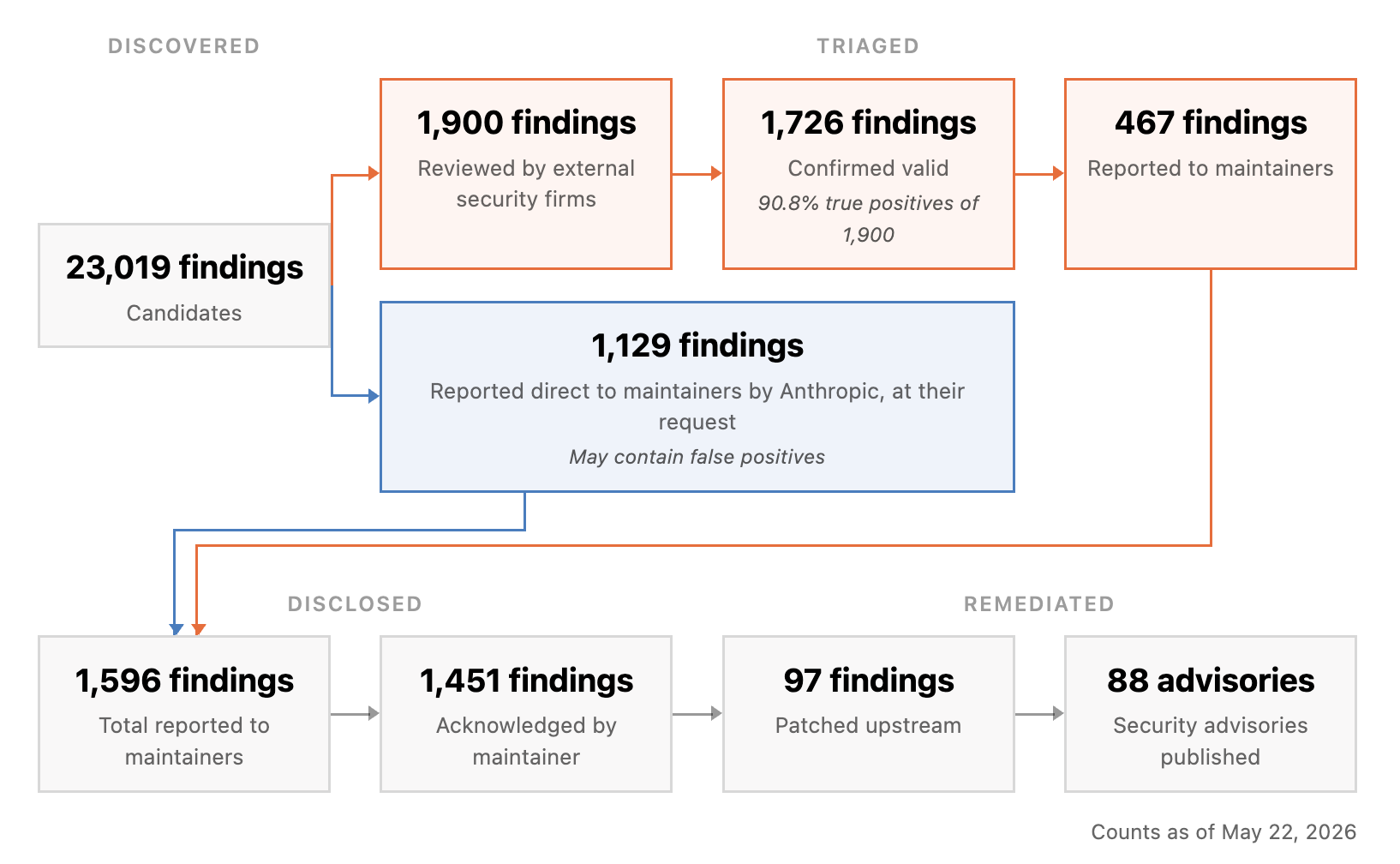
이 차이는 보안팀에게 익숙한 장면입니다. 스캐너는 이미 오래전부터 많은 경고를 만들어 왔습니다. 문제는 그 경고가 진짜인지 재현하고, severity를 다시 평가하고, 중복을 묶고, 어느 팀이 고쳐야 하는지 나누고, 회귀 테스트를 통과시키고, 릴리스를 배포하는 과정입니다. Mythos Preview가 흥미로운 이유는 false positive 쓰나미만 만든 것이 아니라, Anthropic이 공개한 표본에서 꽤 높은 true positive 비율을 냈다는 점입니다. 그렇더라도 true positive가 많아질수록 보안 운영의 나머지 단계는 더 빨리 막힙니다.
여기서 보안 자동화의 기준이 바뀝니다. 기존 취약점 관리 도구는 "무엇을 찾았는가"를 중심으로 평가됐습니다. 다음 단계의 질문은 "찾은 것을 어느 속도로 신뢰 가능한 패치로 바꾸는가"입니다. Anthropic은 Mythos Preview가 찾은 high 또는 critical 취약점 하나를 패치하는 데 평균 2주가 걸린다고 설명합니다. 이 숫자는 모델 성능보다 조직 성능을 더 많이 말해줍니다. maintainer가 자원 부족에 시달리는 오픈소스 프로젝트라면 2주도 낙관적일 수 있습니다. 반대로 기업 내부 코드처럼 소유권이 명확하고 배포 파이프라인이 정비돼 있으면 더 빠를 수 있습니다.
Project Glasswing이 방어 프로젝트라는 점도 중요합니다. Anthropic은 Mythos급 모델을 아직 일반 공개하지 않았습니다. 이유는 명확합니다. 회사는 현재 어떤 회사도, Anthropic 자신도, 이런 모델이 오용돼 심각한 피해를 일으키는 것을 막을 만큼 강한 safeguard를 만들지 못했다고 적었습니다. 그래서 Glasswing은 제한된 파트너에게 먼저 접근권을 주고, 핵심 인프라의 취약점을 선제적으로 찾고, 패치가 충분히 배포된 뒤 세부 내용을 공개하는 쪽을 택했습니다.
이 방식은 보안 공개 관행과 충돌하지 않으려는 설계입니다. Anthropic은 일반적으로 새 취약점은 발견 후 90일, 또는 패치가 먼저 만들어지면 패치 가능 시점 이후 약 45일 안팎에 공개된다고 설명합니다. 이번 업데이트가 세부 exploit을 자세히 설명하지 않는 이유도 여기에 있습니다. 취약점을 찾았다는 사실을 빠르게 자랑할수록 공격자에게 힌트를 줄 위험이 커집니다. 따라서 이번 발표는 "모델이 무엇을 할 수 있는가"와 "어디까지 말할 수 있는가" 사이에서 균형을 잡은 문서에 가깝습니다.
Mozilla 사례는 이 균형을 가장 구체적으로 보여줍니다. Mozilla Hacks 글은 Firefox 팀이 Mythos Preview를 단순 챗봇처럼 쓴 것이 아니라, 코드베이스 분석과 검증 흐름을 갖춘 pipeline 안에 넣었다고 설명합니다. Firefox 150의 271개 취약점은 모델 단독 성과라기보다, 모델과 harness, 두 번째 검증 모델, 인간 리뷰, 릴리스 프로세스가 결합한 결과입니다. 이 차이를 빼면 이야기가 과장됩니다. AI가 마법처럼 브라우저를 고친 것이 아니라, 보안팀이 AI를 반복 가능한 워크플로 안에 넣었을 때 발견량이 크게 늘어난 것입니다.
Cloudflare 반응도 비슷한 방향입니다. Cloudflare는 Mythos Preview가 단일 low severity 문제를 보는 데 그치지 않고 여러 약한 신호를 묶어 더 심각한 exploit 가능성을 구성할 수 있었다고 설명했습니다. 보안 연구에서 이 능력은 큽니다. 많은 취약점은 한 줄의 치명적 실수로만 생기지 않습니다. 경계 조건, 권한 가정, 입력 검증 누락, 오래된 코드 경로가 연결되면서 실제 위험이 됩니다. 모델이 이 연결을 잘하면 기존 backlog에서 낮게 평가된 항목도 다시 봐야 합니다.
다만 이 지점에서 조심해야 합니다. "AI가 모든 보안 연구자를 대체한다"는 결론은 너무 빠릅니다. 이번 발표에서 계속 반복되는 단어는 partner, tester, maintainer, security research firm입니다. Mythos Preview의 결과도 독립 보안 연구사와 인간 검증 과정을 거쳤습니다. Anthropic은 몇몇 maintainer가 disclosure 속도를 늦춰 달라고 요청했다고도 밝혔습니다. 이미 오픈소스 maintainer들은 저품질 AI bug report에 시달리고 있습니다. 좋은 모델이 더 많은 진짜 취약점을 찾기 시작하면, 나쁜 보고서와 좋은 보고서를 가르는 triage 능력은 더 중요해집니다.
커뮤니티 반응도 이 지점을 정확히 건드립니다. Reddit r/technology 스레드에서는 "ship it and fix it later" 문화가 누적한 부채가 드러난다는 반응이 있었고, 실제 현장에서 300개 스캔 결과를 검증하고 공통 코드 수정과 개별 서비스 수정으로 나누는 일이 얼마나 오래 걸리는지 설명한 댓글도 있었습니다. 또 다른 반응은 앞으로 vulnerability management가 사전 테스트 중심에서 더 빠른 탐지와 패치 중심으로 이동할 수 있다고 봤습니다. 이런 반응은 과장된 공포보다 실무에 가깝습니다. 모델이 버그를 많이 찾으면, 조직은 더 많은 진실을 감당해야 합니다.
개발자와 AI 팀 입장에서 첫 번째 실무 변화는 보안 backlog의 의미가 바뀐다는 점입니다. 과거에는 "아직 아무도 찾지 못했다"는 사실이 암묵적 완충지대처럼 작동했습니다. 이제는 공개 모델이나 제한형 모델이 더 많은 코드를 더 싸게 훑을 수 있습니다. 특히 인기 있는 오픈소스, 인터넷 경로의 핵심 라이브러리, 브라우저, 클라우드 인프라, 인증·암호화 관련 코드는 먼저 대상이 됩니다. 의존성 업데이트를 미루는 비용은 더 커집니다.
두 번째 변화는 보안 자동화가 IDE나 CI의 단순 경고가 아니라 운영 시스템이 된다는 점입니다. Anthropic은 Claude Security 공개 베타를 Claude Enterprise 고객에게 열었고, Claude Opus 4.7이 3주 동안 2,100개 이상의 취약점 패치에 사용됐다고 밝혔습니다. 또한 Mythos 작업에 쓴 skills, harness, threat model builder를 자격 있는 보안팀에 제공하겠다고 했습니다. 이 구성은 "모델 하나"가 아니라 threat model, code mapping, scanning subagent, triage report, patch proposal이 이어지는 agentic security workflow입니다.
세 번째 변화는 평가 체계입니다. Cisco가 공개한 Foundry Security Spec은 Project CodeGuard와 함께 agentic AI 보안 평가를 구조화하려는 시도입니다. 보안 모델이 취약점을 찾는 시대에는 결과가 재현 가능하고 감사 가능해야 합니다. 단순히 "모델이 위험하다고 말했다"로는 패치를 merge하기 어렵습니다. 어떤 threat model에서 어떤 code path가 위험하고, 어떤 증거로 재현됐고, 어떤 test가 회귀를 막는지까지 기록돼야 합니다.
이 흐름은 AI coding agent와도 직접 연결됩니다. 최근 코딩 에이전트 논의는 생산성, PR 생성, 장기 작업, 브라우저 제어에 집중돼 있었습니다. Glasswing은 그 반대편입니다. 에이전트가 코드를 더 빨리 쓰면, 보안 에이전트도 코드를 더 빨리 의심해야 합니다. 결국 개발 파이프라인에는 두 종류의 에이전트가 들어옵니다. 하나는 기능을 만드는 에이전트이고, 다른 하나는 그 기능과 의존성이 공격 가능한지 검증하는 에이전트입니다. 둘 사이의 균형이 맞지 않으면 생산성 증가는 취약점 처리 부채로 돌아올 수 있습니다.
그렇다면 지금 팀이 할 수 있는 일은 무엇일까요. 첫째, 고위험 의존성과 인터넷 노출 경로를 명확히 나눠야 합니다. 모든 경고를 같은 큐에 넣으면 AI가 만든 발견량을 감당하지 못합니다. 둘째, 취약점 보고서를 코드 소유권, 테스트, 릴리스 권한과 연결해야 합니다. 모델이 보고서를 잘 써도 owner가 불명확하면 대기열만 길어집니다. 셋째, coordinated disclosure와 public advisory 흐름을 제품 운영의 일부로 봐야 합니다. Anthropic 대시보드가 보여준 것처럼 "maintainer에게 보고됨", "패치됨", "CVE/GHSA 배정됨"은 서로 다른 상태입니다.
넷째, 기본 방어를 과소평가하면 안 됩니다. Anthropic은 Mythos급 모델의 확산에 대비해 기본 네트워크 설정 강화, MFA, 포괄적 로그 유지 같은 방어를 언급했습니다. 이는 평범해 보이지만, 대량 취약점 발견 시대에는 더 중요해집니다. 모든 버그를 즉시 고칠 수 없다면, 공격자가 그 사이를 이용했는지 감지하고, 계정 탈취와 lateral movement를 줄이는 능력이 필요합니다.
마지막으로, 이번 발표를 "방어자가 이겼다" 또는 "공격자가 끝났다"로 읽으면 안 됩니다. 더 정확한 결론은 취약점 발견의 경제가 바뀌고 있다는 것입니다. 발견 비용이 낮아지면 공격자도 이득을 봅니다. 그래서 Anthropic은 Mythos급 모델을 봉인하고, 제한된 방어 파트너에게 먼저 제공하는 전략을 택했습니다. 그러나 회사 자신도 비슷한 성능의 모델이 여러 AI 회사에서 곧 나올 수 있다고 인정합니다. 이 말은 방어자가 준비할 시간이 무한하지 않다는 뜻입니다.
Project Glasswing의 진짜 뉴스 가치는 모델이 얼마나 똑똑한지보다, 소프트웨어 산업의 병목을 어디에 비추었는지에 있습니다. 지금까지 보안팀은 발견 부족과 false positive에 시달렸습니다. 앞으로는 더 많은 true positive, 더 많은 disclosure 상태, 더 많은 패치 요청, 더 많은 maintainer 피로를 다뤄야 할 수 있습니다. AI 보안의 다음 경쟁력은 취약점을 찾는 능력만이 아닙니다. 그 취약점을 신뢰 가능한 패치와 배포된 업데이트로 바꾸는 처리량입니다.