Codex 500만 주간 사용자, 보고서·계약서까지 맡은 지식노동
OpenAI가 Codex 지식노동 보고서를 공개했습니다. 500만 주간 사용자, 20% 비개발자, 병렬 작업 50%가 새 관찰 지점입니다.

- 무슨 일: OpenAI가 2026년 6월 2일 Codex 지식노동 보고서를 공개하고 주간 활성 사용자 500만 명 이상을 제시했습니다.
- 2월 데스크톱 앱 출시 이후 6배 이상 성장했고, 지식노동자는 사용자 중 약 20%라고 설명합니다.
- 사용 변화: 보고서, 메모, 계약서, PDF, 스프레드시트 같은 업무 산출물이 Codex 사용의 중심 사례로 올라왔습니다.
- 개발자 영향: 비개발자가 대시보드, 데이터 정리 스크립트, 내부 도구를 직접 만들면서 개발팀의 요청 처리 방식이 바뀝니다.
- OpenAI 자체 데이터이므로 채택 효과와 생산성 효과는 외부 검증 수치처럼 읽으면 안 됩니다.
OpenAI가 2026년 6월 2일 공개한 Codex 지식노동 보고서는 제품 출시 공지보다 사용 통계에 가깝습니다. 회사는 Codex의 주간 활성 사용자가 500만 명을 넘었고, 2026년 2월 데스크톱 앱 출시 이후 6배 이상 늘었다고 밝혔습니다. 지식노동자는 전체 사용자 중 약 20%이며, 개발자보다 3배 이상 빠르게 채택 중이라는 설명도 붙었습니다.
이번 발표를 또 하나의 Codex 기능 업데이트로 읽으면 핵심을 놓칩니다. OpenAI가 강조한 작업은 코드 생성보다 보고서, 스프레드시트, 계약서, 시장 조사, 데이터 분석, 내부 업무 도구입니다. Codex는 개발자가 IDE 안에서 호출하는 도구에서, 비개발자가 자기 업무를 직접 자동화하는 실행 인터페이스로 포지셔닝되고 있습니다.
보고서에서 가장 직접적인 수치는 작업 유형입니다. 지식노동자 중 매주 72%가 텍스트 문서, 보고서, 메모, 계약서, 이미지·오디오·비디오 같은 멀티미디어 산출물, PDF, 스프레드시트를 만든다고 OpenAI는 설명합니다. 같은 집단에서 engineering operations는 47%, code implementation은 46%, research는 41%로 집계됐습니다. 비개발자가 코드를 아예 쓰지 않는다는 구분보다, 업무 목표에 필요한 만큼 코드와 문서를 오간다는 구분이 더 맞아집니다.
OpenAI가 PDF 8쪽에 넣은 빠른 성장 작업 차트도 같은 방향을 가리킵니다. 지식노동자 기준 데이터 분석은 전주 대비 110%, 리서치는 37%, 지식 산출물은 36% 성장한 작업 유형으로 제시됐습니다. 보고서는 데이터 라벨링이 데이터 분석 안에서 큰 비중을 차지하고, 리서치에는 웹 검색과 내부 지식 검색, 회사·산업·경쟁사·시장 규모 조사가 포함된다고 적었습니다.
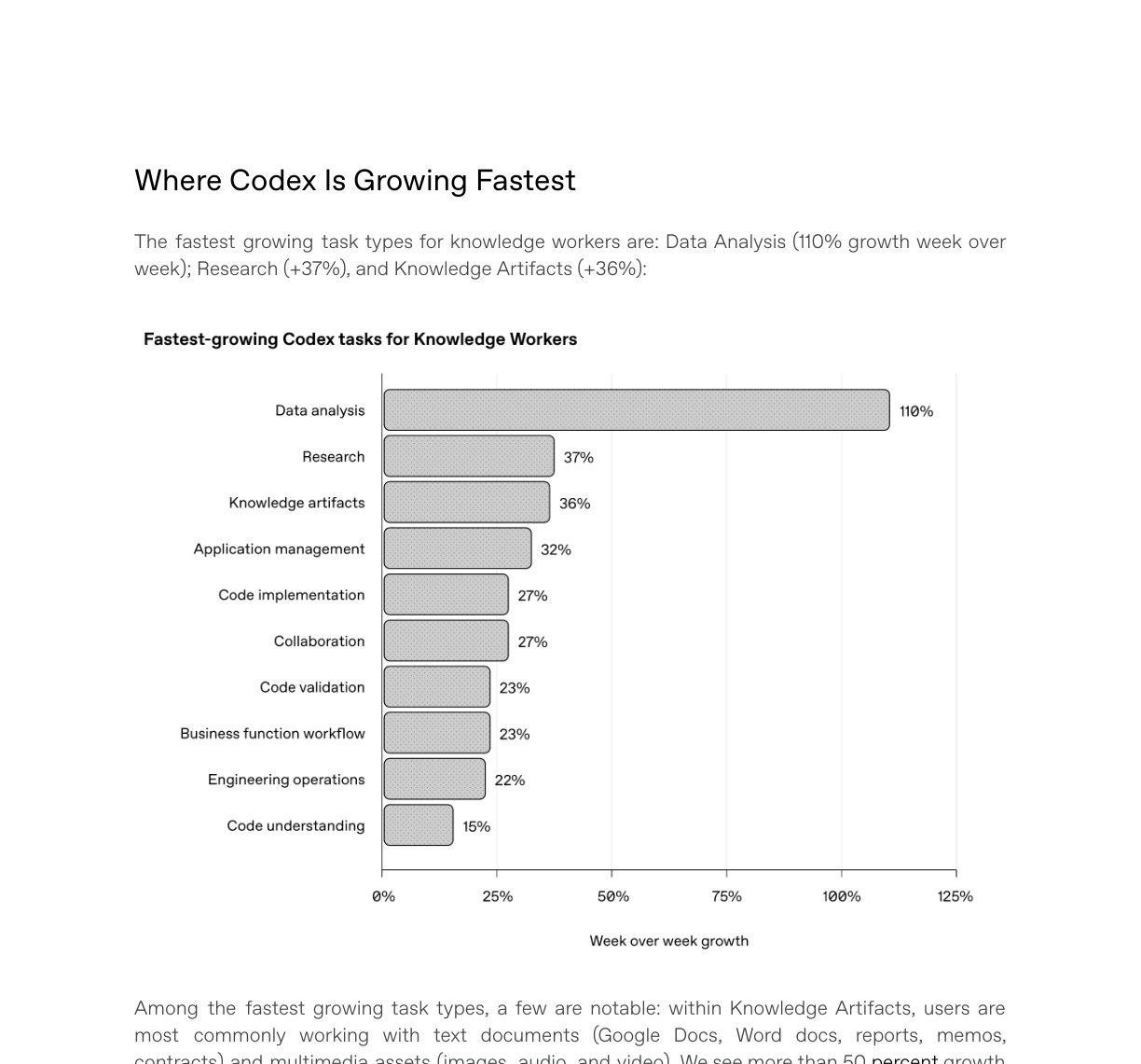
이 숫자는 개발팀 입장에서 불편한 질문을 만듭니다. 제품 매니저가 대시보드를 만들고, 연구자가 데이터 정리 스크립트를 작성하고, 임원이 파일을 대조해 주간 보고서를 만드는 도구를 직접 구성한다면, 개발팀의 업무는 요청 구현에서 권한, 데이터 경계, 품질 검증, 재사용 가능한 플랫폼 설계로 이동합니다. OpenAI는 이 변화를 “정식 소프트웨어 로드맵을 기다리지 않고 작업에 가장 가까운 사람이 필요한 도구를 만든다”는 식으로 설명합니다.
사례도 개발자 전용 도구의 언어에서 벗어나 있습니다. GroundVue는 약 9만 개 정부 기관의 공개 회의 정보를 검색 가능하고 비교 가능한 형태로 만들기 위해 Codex를 사용한다고 보고서는 설명합니다. 흩어진 비디오, 웹사이트, 지역 플랫폼에서 자료를 찾고 지속적으로 수집·정리하는 작업이 핵심입니다. 이 사례에서 Codex는 앱 하나를 만드는 코딩 보조자보다, 공개 정보 수집과 분류 파이프라인을 유지하는 업무 보조자에 가깝습니다.
Proaction 사례는 영업과 제품 개발의 경계를 보여줍니다. 이 5명 규모 스타트업은 차량과 장비 데이터를 다루는 고객을 만나면서, Codex로 맞춤 제안서와 워크플로 프로토타입, 실제 동작하는 데모를 만든다고 소개됐습니다. 제안서가 정적인 문서로 끝나지 않고, 고객 운영 방식에 맞춘 작은 시스템 시연으로 이어지는 구조입니다. 이 경우 Codex는 세일즈 자료 제작, 고객 발견, 제품 검증 사이의 대기 시간을 줄이는 도구가 됩니다.
California State University의 수학 교수 Taiyo Inoue 사례는 교육 행정 자동화입니다. 보고서에 따르면 그는 Canvas의 과제, 일정, 수업 자료, 공지를 갱신하는 스크립트를 Codex로 만들고, 주당 4-5시간을 절약한다고 추정했습니다. OpenAI는 그 시간이 수업을 협력 문제 풀이 중심으로 바꾸는 데 쓰였다고 설명합니다. 여기서 중요한 사실은 모델이 수학 수업을 대신했다는 주장이 아니라, 학습관리시스템 관리처럼 작고 반복적인 관리 업무가 개인 자동화 대상으로 바뀌었다는 점입니다.
Luke Xing 사례는 더 개인적입니다. 그는 왼쪽 귀의 큰 청력 손실을 보정하기 위해 주파수별 청력 테스트와 장치별 출력 조정을 돕는 데스크톱 앱을 Codex로 만들었다고 보고서는 적었습니다. OpenAI는 이 앱이 의료기기는 아니라고 선을 그었습니다. 이 제한 문구는 기사에서 그대로 중요합니다. Codex가 개인 문제를 해결하는 소프트웨어 제작 문턱을 낮출 수 있지만, 의료·법률·금융처럼 규제와 책임이 붙는 영역에서는 결과물의 용도와 검증 범위를 분리해야 합니다.
OpenAI가 강조한 또 다른 지표는 병렬 실행입니다. 보고서는 하루 중 한 번 이상 두 개 이상의 Codex 작업을 동시에 실행한 사용자가 약 50%라고 설명합니다. 4월 중순에는 이 비율이 3분의 1 미만이었다는 비교도 나옵니다. 한 사용자가 데이터셋 점검, 스크립트 초안, 보고서 구성, 앱 검토를 각각 다른 작업으로 동시에 맡긴다는 설명입니다.
병렬 실행은 제품 사용량 그래프보다 조직 운영에 더 큰 영향을 줍니다. 사람이 한 번에 하나의 문서를 쓰는 방식에서는 업무 병목이 개인의 시간에 묶입니다. 여러 Codex 작업을 동시에 돌리는 방식에서는 병목이 프롬프트 작성, 중간 검토, 데이터 접근 권한, 최종 승인으로 옮겨갑니다. 개발팀과 보안팀은 “누가 코드를 작성했는가”보다 “어떤 데이터에 접근했고, 어떤 산출물이 어느 승인 과정을 통과했는가”를 기록해야 합니다.
OpenAI는 보고서 후반부에서 정책 제언까지 덧붙였습니다. 공공기관은 행정 백로그, 소프트웨어 시스템 개선, 기록 검색과 대조, 과학 연구, 공공서비스 전달에 에이전트를 써야 하며, 성공 지표는 대기 시간 단축, 양식 감소, 빠른 인허가, 더 나은 혜택 전달, 낮은 행정 비용처럼 시민이 이해할 수 있는 결과여야 한다고 적었습니다. 이 부분은 제품 마케팅을 넘어 조달과 교육 예산을 겨냥한 문장입니다.
AI fluency를 핵심 노동 역량으로 다뤄야 한다는 주장도 같은 맥락입니다. OpenAI는 학교, 커뮤니티 칼리지, 공공기관, 도서관, 고용주 파트너십을 통한 실습형 AI 교육을 제안했습니다. 기업에는 직원이 실제 워크플로에서 도구를 배울 유급 시간을 확보하도록 보조금, 세제 혜택, 조달, 파트너십으로 유도할 수 있다고 설명했습니다. Codex가 개발자 도구라면 이런 제언은 과합니다. Codex가 사무·연구·교육·공공 행정의 자동화 인터페이스라면, 이 제언은 제품 확장 전략의 일부가 됩니다.
개발자에게 남는 실무 과제는 세 가지입니다. 첫째, 비개발자가 만드는 작은 도구가 조직 시스템과 연결될 때 인증, 로그, 비밀값, 데이터 반출 경계를 어떻게 둘지 정해야 합니다. 둘째, 일회성 자동화와 운영 시스템을 구분해야 합니다. 고객 파일을 한 번 정리하는 스크립트와 매주 재무 보고서를 만드는 내부 앱은 장애와 감사 요구가 다릅니다. 셋째, 개발팀은 요청을 모두 구현하는 팀에서, 안전하게 위임 가능한 템플릿과 검증 루프를 제공하는 팀으로 바뀔 수 있습니다.
이 글에서 OpenAI 수치를 외부 검증된 생산성 효과로 읽지 않는 것도 중요합니다. 500만 주간 활성 사용자, 20% 지식노동자 비중, 72% 산출물 생성, 50% 병렬 작업은 모두 OpenAI가 공개한 자체 데이터입니다. 보고서는 작업의 품질, 실패율, 보안 사고, 실제 비용, 사람이 다시 고친 비율을 같은 수준의 표로 공개하지 않았습니다. 그래서 이 발표는 “Codex가 사무직 생산성을 입증했다”보다 “OpenAI가 Codex의 시장을 개발자 밖으로 공식 확장하고, 그 사용 패턴을 일부 공개했다”로 읽는 편이 정확합니다.
커뮤니티 반응도 아직 제한적입니다. 2026년 6월 2일 기준 Hacker News와 GeekNews에서 이 보고서 자체를 다루는 큰 토론은 확인하지 못했습니다. Axios와 Techmeme 계열 요약이 먼저 OpenAI의 500만 주간 사용자, 6배 성장, 지식노동자 20% 수치를 전달했고, Axios 검색 결과에는 성장률을 6배로 정정했다는 편집자 주가 붙었습니다. 초반 보도는 OpenAI의 프레이밍을 받아 적는 단계에 가깝기 때문에, 후속 검증은 기업 고객 사례와 실제 비용 데이터에서 나와야 합니다.
경쟁 구도에서는 Microsoft 365 Copilot과 GitHub Copilot, Anthropic Claude/Claude Code가 함께 보입니다. Microsoft는 Word, Excel, PowerPoint, Outlook 안의 업무 산출물과 Agent 365 같은 거버넌스 제품을 앞세웁니다. Anthropic은 Claude Code와 장시간 작업, 기업용 Claude 배포를 강조해 왔습니다. OpenAI의 이번 보고서는 Codex라는 코딩 에이전트 브랜드를 그대로 유지하면서, 사용 대상은 개발자 밖으로 넓히는 방식입니다. 이름은 코드지만, 판매되는 가치는 업무 산출물과 병렬 실행입니다.
보고서가 미국 노동시장 배경을 길게 다룬 점도 눈에 띕니다. OpenAI는 미국 노동의 40% 이상, 약 7200만 명이 정보 분석, 코드, 문서, 디자인, 시스템, 의사결정, 커뮤니케이션을 주로 다루는 지식노동에 종사한다고 적었습니다. 1850년 농업 고용 약 60%, 1960년 제조업 고용 정점 약 26%, 1970년 농업 고용 약 4% 같은 숫자를 함께 배치한 뒤, 다음 생산성 병목은 물리 장비보다 검색, 조정, 승인, 검증 비용이라고 설명합니다. Codex를 개발자 도구가 아니라 노동시장 도구로 설명하려는 문맥입니다.
이 방향이 성공하면 소프트웨어 요청의 일부는 티켓 큐를 거치지 않습니다. 한 부서가 작은 데이터 변환 도구, 내부 대시보드, 계약서 검토 보조, 교육 관리 자동화를 직접 만들 수 있기 때문입니다. 반대로 실패하면 검증되지 않은 작은 자동화가 조직 곳곳에 흩어집니다. OpenAI 보고서가 말하는 “작업에 가장 가까운 사람의 agency”는 개발팀에는 더 적은 티켓을 뜻할 수도 있고, 더 많은 감사·지원·표준화 업무를 뜻할 수도 있습니다.
따라서 이번 발표에서 개발자가 봐야 할 지점은 Codex가 문서를 잘 쓴다는 주장보다 작업 경계의 이동입니다. 비개발자가 코드를 조금 쓰고, 개발자가 보고서와 데이터 분석을 맡기며, 둘 다 여러 에이전트 작업을 동시에 굴립니다. 그 다음 병목은 모델 이름이 아니라 접근 권한, 검토 단위, 실패 로그, 비용 한도, 산출물 소유권입니다. OpenAI가 공개한 500만 사용자 보고서는 Codex를 코딩 도구 시장에서만 비교하기 어려워졌다는 신호입니다.