MiniMax M3 100만 토큰 공개, 오픈 모델의 에이전트 비용 시험
MiniMax M3는 100만 토큰 context, agentic coding, 오픈 웨이트 예고를 내세웁니다. API와 검증 과제를 분리해 봅니다.

- 무슨 일: MiniMax가 2026년 6월 1일
M3를 공개하며 100만 토큰 context와 agentic coding을 전면에 뒀습니다.- API와 MiniMax Agent 사용은 열렸고, weights와 technical report는 발표 주 후반 공개를 예고했습니다.
- 의미: 오픈 웨이트 모델 경쟁이 chat 점수에서
Claude Code, Cursor, Cline 같은 에이전트 실행 비용으로 옮겨갑니다. - 확인점: 1M context, MSA architecture, benchmark 이미지는 공식 발표 기준이며 독립 재현은 weights 공개 뒤 봐야 합니다.
- 개발팀은 launch-day 순위보다 API 가격, quota, tool loop 안정성, 실패 비용을 같은 표에서 비교해야 합니다.
MiniMax가 2026년 6월 1일 M3를 공개했습니다. 발표 글의 첫 문장은 모델 이름보다 사용 장면을 먼저 내세웁니다. M3는 100만 토큰 context window, agentic coding, tool use, long-horizon reasoning을 겨냥한 모델이며, MiniMax Agent뿐 아니라 Claude Code, Cursor, Cline 같은 개발자 도구에서 쓸 수 있다고 설명합니다.
이 뉴스에서 개발자가 봐야 할 부분은 "새 LLM 하나가 또 나왔다"가 아닙니다. MiniMax는 M3를 open-weight 모델로 예고했고, 동시에 API와 에이전트 제품 통합을 먼저 열었습니다. weights와 technical report는 발표 주 후반 공개하겠다고 적었습니다. 따라서 6월 1일 기준으로 확정된 사실은 API 사용 경로와 공식 benchmark 주장이고, 아직 검증해야 할 부분은 공개 weights, 학습 세부, 독립 재현입니다.
오픈 모델 경쟁은 지난 1년 동안 모델 크기와 일반 benchmark 점수로 많이 이야기됐습니다. M3 발표는 기준을 조금 다르게 둡니다. 100만 토큰 context를 코딩 에이전트와 장기 실행 작업에 연결하고, closed model API보다 낮은 비용으로 agent loop를 오래 돌릴 수 있는지를 묻습니다. Claude Code, Codex, Gemini CLI, Cursor 같은 도구가 이미 개발자의 작업 단위로 들어온 지금, 오픈 웨이트 모델의 가치는 "채팅 답변이 괜찮다"보다 "긴 repository와 도구 호출을 얼마에 처리하나"에 더 가깝습니다.
100만 토큰은 기능보다 비용 질문입니다
MiniMax는 M3의 context window를 1M tokens로 제시합니다. 이 숫자는 긴 문서나 대형 repository를 한 번에 넣을 수 있다는 식의 마케팅 문장으로 소비되기 쉽습니다. 하지만 에이전트 운영에서는 context 길이가 곧 비용과 실패 표면입니다. 코딩 에이전트가 repository를 읽고, plan을 만들고, 파일을 수정하고, 테스트 로그를 다시 해석하면 한 task 안에서 같은 모델을 여러 번 호출합니다.
1M context가 유용하려면 두 조건이 필요합니다. 첫째, 모델이 긴 입력 안에서 실제로 필요한 정보를 찾아야 합니다. 둘째, API 가격과 latency가 긴 context 사용을 허용해야 합니다. context window가 커도 매 호출 비용이 높거나, 긴 입력에서 retrieval 품질이 흔들리면 개발팀은 결국 자체 chunking, search, summary cache를 붙입니다. MiniMax M3의 실전 평가는 context 길이 자체보다 "큰 입력을 넣었을 때 실패한 agent run이 얼마를 쓰는가"에서 갈립니다.
공식 발표는 M3를 MiniMax Agent, API, Claude Code, Cursor, Cline에서 사용할 수 있다고 설명합니다. 이 목록은 중요합니다. 모델은 더 이상 독립적인 chat UI에서만 평가되지 않습니다. 파일 시스템을 읽고, shell을 실행하고, diff를 만들고, test failure를 다시 해석하는 harness 안에서 평가됩니다. 같은 모델도 Cursor의 tool surface, Claude Code의 승인 흐름, Cline의 browser/editor 통합에 따라 다른 비용과 실패 패턴을 냅니다.
MSA architecture가 겨냥하는 병목
MiniMax는 M3의 핵심 구조로 hybrid Mamba-Transformer 기반 MSA architecture를 제시합니다. 공식 도식은 Mamba 계열 sequence modeling과 Transformer attention을 결합해 긴 context와 효율을 동시에 잡으려는 방향을 보여줍니다. 발표 글은 이 구조를 long context, efficient inference, agentic workload와 연결합니다.
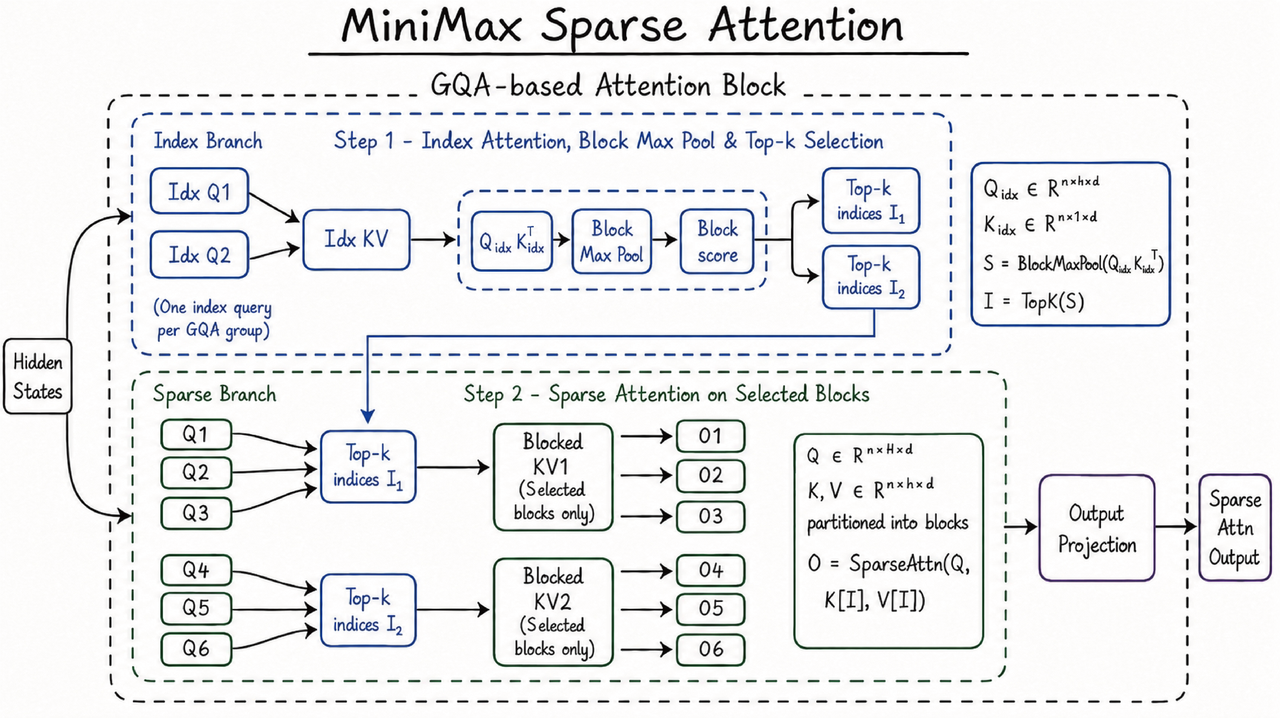
이 구조가 중요한 이유는 agent workload의 병목이 단일 답변 품질만이 아니기 때문입니다. 코딩 에이전트는 동일한 repository 상태를 여러 step에서 다시 봅니다. 문서 분석 에이전트는 긴 source 묶음을 읽고, 중간 결과를 다시 context에 넣습니다. 운영 에이전트는 로그, runbook, ticket, metric snapshot을 함께 읽습니다. 긴 sequence를 매번 full attention으로 처리하는 비용은 빠르게 커집니다.
Mamba 계열 구조는 긴 sequence 처리에서 attention 비용을 줄이려는 시도로 알려져 있습니다. MiniMax가 M3에서 이를 Transformer와 섞었다는 설명은 충분히 자연스럽습니다. 다만 발표 글만으로는 어느 layer가 어떤 역할을 하는지, training mix가 어떻게 구성됐는지, long-context benchmark가 어떤 retrieval 조건에서 측정됐는지까지 확인할 수 없습니다. 이 부분은 technical report 공개 뒤 검증해야 합니다.
따라서 MSA는 지금 단계에서 "성능이 입증됐다"보다 "MiniMax가 비용 병목을 어디로 보고 있는지"를 보여주는 단서입니다. 회사가 장기 실행 agent와 1M context를 전면에 둔 만큼, 구조 선택도 긴 입력의 추론비와 latency를 낮추는 방향으로 읽어야 합니다.
API가 먼저 열리고 weights는 뒤따릅니다
M3 발표에서 가장 조심해서 읽어야 할 문장은 open-weight입니다. MiniMax는 M3를 open-weight model로 부르지만, 공식 글 기준으로 API와 제품 사용 경로가 먼저 열렸고 weights와 technical report는 발표 주 후반 공개 예정이라고 적었습니다. 이 순서는 개발팀 평가 방식에 영향을 줍니다.
API로 먼저 써 볼 수 있다는 점은 빠른 실험에 좋습니다. Claude Code나 Cursor 같은 도구에 연결해 기존 workflow에서 모델 반응, 비용, 속도, 실패 로그를 비교할 수 있습니다. 그러나 open-weight 모델의 핵심 약속은 self-hosting, private deployment, fine-tuning 또는 내부 평가 재현입니다. weights가 실제로 공개되고 license, quantization, serving recipe가 확인되어야 그 약속을 판단할 수 있습니다.
개발팀이 launch week에 할 수 있는 일은 명확합니다. API 기반 smoke test로 작은 repository, 큰 repository, test failure 수정, 문서 기반 질의, tool loop 실패 사례를 돌려 봅니다. 동시에 weights 공개 뒤 반복할 eval set을 고정합니다. API에서 잘 된 task가 self-hosted serving에서도 같은 비용과 latency로 유지되는지는 별도 질문입니다.
토큰 계획 이미지는 benchmark보다 운영 지표에 가깝습니다
MiniMax는 공식 글에 token plan 이미지를 포함했습니다. 이 이미지는 M3를 단순 chat model이 아니라 long-context training과 agentic usage를 염두에 둔 모델로 포지셔닝합니다. 개발자에게 이 자료는 "얼마나 긴 입력을 받나"보다 "긴 입력을 어떻게 가격표와 quota에 연결할 것인가"라는 질문을 던집니다.
에이전트 제품에서 토큰 계획은 모델 사양표가 아니라 운영 설계입니다. 예를 들어 코드 리뷰 agent가 pull request 하나를 읽을 때 변경 diff, 주변 파일, test log, style guide, 이전 리뷰 코멘트를 함께 넣으면 입력 토큰은 쉽게 커집니다. 실패한 patch를 다시 고치면 같은 작업이 두세 번 반복됩니다. long-context 모델은 이 반복을 줄일 수도 있지만, 반대로 더 많은 자료를 무심코 넣게 만들어 비용을 키울 수도 있습니다.
그래서 M3의 가격 경쟁력은 단일 1M 입력 가격으로 끝나지 않습니다. 평균 task 비용, 실패 task 비용, p95 latency, tool call 횟수, context cache 유무, rate limit이 함께 필요합니다. MiniMax가 제시한 공식 가격은 시작점이지만, 실제 선택은 각 팀의 workload trace 위에서만 나옵니다. 특히 코딩 agent는 성공한 task보다 실패한 task가 더 비쌀 수 있습니다. 실패한 agent는 같은 로그를 반복해서 읽고, 비슷한 patch를 다시 만들고, 테스트를 계속 돌립니다.
코딩 에이전트 통합이 만드는 비교 기준
MiniMax가 Claude Code, Cursor, Cline을 직접 언급한 점은 이번 발표의 실무적 후크입니다. 모델 제공자가 "우리 모델은 API에서 쓸 수 있다"를 넘어 "기존 agent toolchain에 꽂아 쓰라"고 말한 셈입니다. 이는 open-weight 모델 공급자가 closed coding agent 시장을 우회하지 않고 정면으로 들어가겠다는 신호입니다.
하지만 통합 목록이 곧 품질을 보장하지는 않습니다. 코딩 에이전트에서 모델은 여러 제약 안에서 움직입니다. 어느 파일을 먼저 읽을지, shell command 실행을 언제 요청할지, 실패 로그를 어떻게 요약할지, 사용자 승인 전에 얼마나 큰 diff를 만들지 같은 결정이 모두 결과에 영향을 줍니다. 모델이 강해도 tool schema와 system prompt가 맞지 않으면 반복 실행이 늘어납니다.
반대로 모델이 closed frontier보다 약간 낮아도 가격이 충분히 낮고 context가 길다면 특정 내부 업무에서는 유리할 수 있습니다. 예를 들어 사내 문서 기반 리팩터링, 반복적인 test migration, 큰 monorepo 탐색, 보안 민감 코드의 private deployment는 open-weight 모델에 맞는 후보입니다. 이때 평가 기준은 benchmark score가 아니라 "사람 리뷰 전에 clean diff를 몇 번이나 만들었나"와 "실패한 run이 얼마를 썼나"입니다.
benchmark 이미지는 출발점이지 결론이 아닙니다
MiniMax 공식 글은 agentic coding과 post-training benchmark 이미지를 제시합니다. launch page의 benchmark는 제품 발표에서 필요한 자료입니다. 그러나 독자는 두 층을 나눠야 합니다. 하나는 MiniMax가 어떤 평가를 중요하게 보는지입니다. 다른 하나는 그 수치가 독립적으로 재현되는지입니다.
첫 번째 층은 이미 유용합니다. MiniMax는 M3를 일반 chat assistant보다 agentic coding, tool use, long-context workload로 비교하려 합니다. 이는 시장의 관심이 어디에 있는지 보여줍니다. 모델 경쟁은 MMLU류 일반 지식 점수에서 SWE-bench, terminal task, tool-use, long-context recall, cost-per-task 쪽으로 옮겨가고 있습니다.
두 번째 층은 기다려야 합니다. weights, technical report, evaluation harness, prompt, sampling 설정, tool 제한이 공개되어야 외부 팀이 같은 조건에서 재현할 수 있습니다. 특히 코딩 benchmark는 작은 설정 차이에도 결과가 달라집니다. repository snapshot, test command, retry 횟수, patch validation 방식, timeout이 모두 점수에 영향을 줍니다.
따라서 M3를 지금 평가하는 가장 좋은 문장은 "공식 benchmark가 강하다"가 아니라 "MiniMax가 1M context와 agentic coding을 공개 비교 표면으로 올렸다"입니다. 이는 충분히 뉴스 가치가 있습니다. 다만 구매나 마이그레이션 판단은 독립 재현 뒤로 미뤄야 합니다.
커뮤니티 반응은 조용하지만 질문은 선명합니다
Hacker News와 GeekNews에서 M3만을 두고 큰 단독 토론은 확인하지 못했습니다. Reddit과 AI 커뮤니티 검색 결과에서도 관심은 있었지만, launch-day 대형 모델 발표처럼 폭발적인 반응은 아니었습니다. 반응의 공통분모는 100만 토큰과 open-weight promise에 대한 기대, 그리고 weights와 technical report가 실제로 올라온 뒤 보자는 유보입니다.
이 조용함은 이상하지 않습니다. M3는 일반 소비자용 챗봇 출시보다 개발자 infrastructure에 가까운 발표입니다. 이런 발표는 headline보다 며칠 뒤의 repository, license, serving example, API latency report에서 더 오래 평가됩니다. 특히 오픈 웨이트 모델은 다운로드 가능한 순간부터 커뮤니티 검증이 시작됩니다. quantization, vLLM 지원, long-context memory 사용량, multi-GPU serving 비용 같은 글이 뒤따라야 실전성이 보입니다.
MiniMax가 노리는 독자는 "새 chat model을 써 볼 사용자"보다 "closed agent API 비용을 줄일 방법을 찾는 팀"에 가깝습니다. 그 독자층은 발표 문구보다 재현 가능한 notebook, Docker image, benchmark trace, license 조항을 봅니다. M3의 실제 평판도 그 자료들이 공개된 뒤 더 분명해질 가능성이 높습니다.
개발팀이 바로 점검할 목록
M3를 검토하는 팀은 먼저 기존 agent workload를 세 가지로 나누는 편이 좋습니다. 짧은 코딩 질의, 긴 repository 탐색, 도구 실행을 포함한 patch 생성입니다. 세 작업은 같은 모델에서도 비용과 실패 이유가 다릅니다. 짧은 질의에서 좋은 모델이 긴 repository에서는 irrelevant file을 오래 읽을 수 있고, 긴 context에서 강한 모델이 shell failure 복구에서는 약할 수 있습니다.
두 번째는 가격표를 task 단위로 바꾸는 일입니다. input 100만 tokens 가격, output 100만 tokens 가격을 그대로 비교하면 부족합니다. 실제로는 한 PR 수정에 평균 몇 번 호출하는지, failed run에서 몇 번 재시도하는지, cache가 적용되는지, tool output을 얼마나 다시 넣는지가 비용을 만듭니다. M3의 1M context는 이 계산을 더 크게 만들 수도, 더 단순하게 만들 수도 있습니다.
세 번째는 weights 공개 뒤 배포 옵션을 따로 평가하는 일입니다. API에서 MiniMax가 제공하는 serving과 직접 운영하는 serving은 다른 제품입니다. self-hosting은 데이터 통제와 비용 예측에는 장점이 있지만, long-context memory, batching, KV cache, GPU allocation, rate limiting을 직접 책임져야 합니다. 오픈 웨이트가 곧 무료 agent runtime을 뜻하지는 않습니다.
네 번째는 실패 로그를 남기는 것입니다. 모델 비교에서 성공률만 보면 개선 지점이 흐려집니다. M3가 실패한 task가 retrieval failure인지, tool selection failure인지, patch validation failure인지, hallucinated API인지 나눠야 합니다. closed model과 open model의 차이는 평균 점수보다 실패 유형에서 더 크게 드러나는 경우가 많습니다.
오픈 모델의 다음 경쟁은 실행 비용입니다
MiniMax M3는 아직 완결된 사건이 아닙니다. 6월 1일 발표는 API와 제품 통합, 공식 benchmark, 100만 토큰 context, open-weight 예고를 묶은 launch입니다. weights와 technical report가 뒤따라야 오픈 모델로서의 약속이 검증됩니다. 그래서 이 글의 결론도 확정적인 추천보다 평가 기준에 가깝습니다.
그래도 방향은 분명합니다. 오픈 웨이트 모델 경쟁은 일반 chat leaderboard에서 코딩 에이전트의 실행 비용으로 이동하고 있습니다. 모델이 긴 context를 처리하고, tool loop를 버티고, 실패를 줄이고, self-hosting으로 데이터 경계를 맞출 수 있다면 closed frontier API의 일부 사용처를 압박할 수 있습니다. 반대로 긴 context가 비싸고, agent harness에서 실패가 늘고, weights 공개 뒤 serving 비용이 크다면 launch page의 숫자는 빠르게 힘을 잃습니다.
개발자에게 MiniMax M3는 지금 당장 "갈아탈 모델"이라기보다 "agent 비용표를 다시 열게 만드는 모델"입니다. Claude Code, Cursor, Cline, 내부 agent platform을 운영하는 팀이라면 같은 task set으로 M3 API를 시험하고, weights 공개 뒤 self-hosting 비용까지 이어서 봐야 합니다. 100만 토큰이라는 숫자는 눈에 잘 띄지만, 실제 경쟁력은 성공한 diff 하나를 만들기까지 든 토큰, 시간, 승인 횟수, 실패 로그 안에 있습니다.