Gemma 4 12B 공개, 16GB 노트북의 로컬 에이전트
Google Gemma 4 12B는 16GB급 노트북에서 이미지·음성·텍스트를 처리하는 로컬 멀티모달 에이전트를 겨냥합니다.

- 무슨 일: Google이 2026년 6월 3일
Gemma 4 12B를 공개했습니다.- 12B dense multimodal model이며, Google은 16GB VRAM 또는 unified memory 노트북 실행을 전면에 세웠습니다.
- weights는 Hugging Face와 Kaggle에 올라왔고, 라이선스는 Apache 2.0입니다.
- 기술 변화: vision·audio 입력을 별도 encoder model이 아니라 LLM backbone으로 직접 넣는
encoder-free구조를 내세웁니다. - 개발자 영향:
LiteRT-LM,llama.cpp,MLX,gemma-skills가 로컬 에이전트 harness로 이어집니다. - 주의점: HN 테스트는 4-bit GGUF와 12GB VRAM에서 가능성을 보였지만, syntax error와 낮은 tokens/s도 함께 보고했습니다.
Google이 2026년 6월 3일 Gemma 4 12B를 공개했습니다. 발표문 한 줄만 보면 "고성능 멀티모달 지능을 노트북으로 가져온다"는 제품 문구처럼 읽힙니다. 개발자가 확인할 사건은 더 구체적입니다. Google은 12B dense model에 image, audio, text 입력을 묶고, 16GB VRAM 또는 unified memory 장비에서 로컬로 돌리는 agent workflow를 공식 사용 사례로 제시했습니다.

Gemma 4 12B는 Google의 edge-friendly E4B와 26B MoE 사이에 놓입니다. Google 개발자 가이드는 이 모델을 dense multimodal model로 설명했습니다. 같은 문서에는 네 가지 출시 포인트가 적혀 있습니다. 무거운 vision/audio encoder를 우회하는 구조, Gemma 계열 첫 medium-sized native audio input, 16GB급 로컬 실행, MacOS desktop app 경험입니다.
모델 발표가 많은 2026년 기준으로 12B라는 숫자는 크지 않습니다. MiniMax M3처럼 100만 토큰 context를 말하거나, Microsoft MAI-Thinking-1처럼 35B active MoE를 내세우는 발표와 비교하면 더 작아 보입니다. 그런데 Gemma 4 12B의 기사는 parameter race가 아니라 실행 위치의 기사입니다. 대형 cloud model이 할 수 있는 일을 더 싼 모델이 얼마나 따라잡는지가 아니라, image와 audio가 붙은 agent loop를 로컬 노트북에서 어느 정도까지 끌어내릴 수 있는지가 이번 발표의 검증 지점입니다.
Google은 launch blog에서 Gemma 4 model family가 1억5000만 다운로드를 넘었다고 적었습니다. 이 수치는 모델 품질만이 아니라 distribution을 보여줍니다. Hugging Face, Kaggle, Ollama, LM Studio, llama.cpp, MLX, vLLM, SGLang 같은 경로가 동시에 열리면 개발자는 Google Cloud에 endpoint를 만들기 전에도 로컬 harness에서 실험할 수 있습니다. Google이 같은 글에서 Cloud Run, GKE, Gemini Enterprise Agent Platform Model Garden까지 언급한 점은 로컬 실험과 cloud 배포를 같은 제품 경로에 놓습니다.
구조에서 Google이 가장 크게 표시한 단어는 encoder-free입니다. 전통적인 multimodal model은 vision encoder나 audio encoder가 입력을 먼저 feature representation으로 바꾸고, 그 결과를 language model에 넘깁니다. Gemma 4 12B는 이 단계를 줄였다고 설명합니다. 개발자 가이드는 기존 Gemma 4 medium-sized model의 27개 vision transformer layer를 35M parameter vision embedder가 대체한다고 적었습니다. raw 48x48 pixel patch가 single matrix multiplication으로 LLM hidden dimension에 투영되고, X/Y factorized coordinate lookup이 공간 위치 정보를 붙입니다.
audio 쪽 변화는 더 급진적으로 설명됩니다. Google은 Gemma 4 E2B와 E4B에서 쓰던 12개 conformer layer audio encoder를 제거했다고 적었습니다. raw 16kHz audio signal을 40ms frame, 즉 640 floats 단위로 자른 뒤 LLM input space로 linear projection합니다. 이 설계가 실제 환경에서 얼마나 robust한지는 별도 평가가 필요하지만, 제품 메시지는 분명합니다. audio와 vision을 별도 tower로 취급하지 않고, text token loop와 같은 weight가 업데이트되는 multimodal path로 묶겠다는 것입니다.
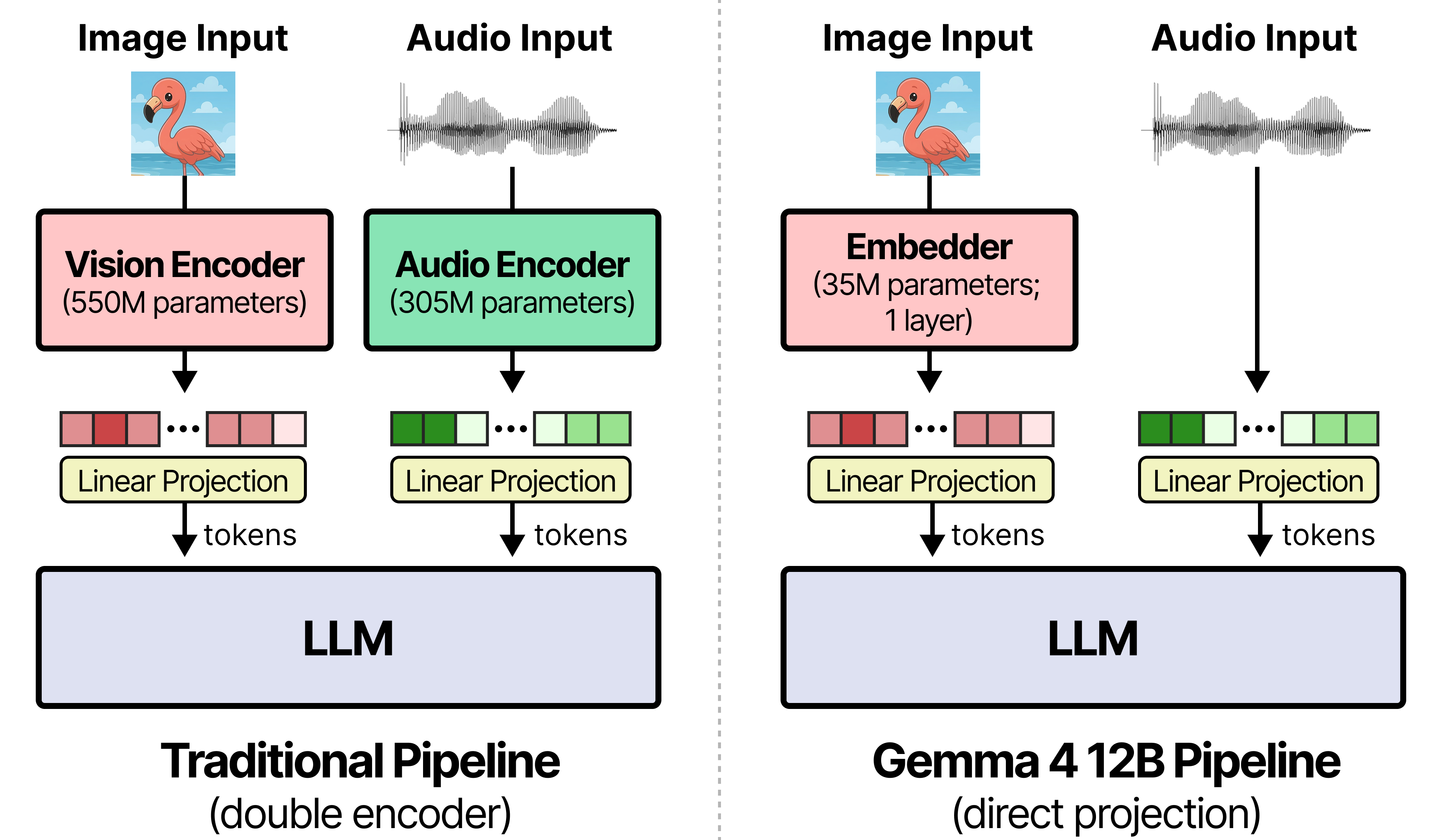
이 설계는 fine-tuning에도 영향을 줍니다. Google은 vision, audio, text input이 같은 weight를 공유하기 때문에 downstream adapter나 full tuning이 multimodal token loop 전체를 한 번에 업데이트할 수 있다고 설명했습니다. 별도 frozen encoder를 같이 맞추는 작업이 줄어든다는 뜻입니다. LoRA나 Unsloth 기반 미세조정을 하는 팀에게는 작은 차이가 아닙니다. 로컬 agent가 특정 업무 화면, 사내 이미지 양식, 음성 메모를 같이 읽어야 한다면 encoder별 튜닝 경로보다 단일 loop가 운영하기 쉽습니다.
발표문은 성능도 언급합니다. Google은 Gemma 4 12B가 standard benchmark에서 더 큰 26B MoE model에 가까운 성능을 내며, total memory footprint는 절반 미만이라고 적었습니다. benchmark 이미지는 공식 페이지에 따로 제공됩니다. 다만 이 대목은 기사에서 조심해서 읽어야 합니다. "26B에 가까움"은 benchmark 집합과 inference 설정에 따라 달라지는 주장이고, 로컬 agent가 실제로 마주치는 문제는 긴 context 유지, tool call 실패 복구, linter/test feedback loop, multimodal input 전처리까지 포함합니다.
개발자 입장에서 더 바로 쓰이는 발표는 LiteRT-LM입니다. Google은 litert-lm serve로 Gemma 4 12B를 OpenAI-compatible local API server처럼 띄울 수 있다고 설명했습니다. 예시는 Hugging Face repo에서 LiteRT-LM artifact를 import한 뒤 local server를 실행합니다.
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
litert-lm serve
OpenAI-compatible local server라는 표현은 agent tool 생태계에서 강합니다. Continue, Aider, OpenCode, OpenClaw, Hermes 같은 도구는 이미 chat completions 형태의 endpoint를 바꿔 끼우는 방식에 익숙합니다. Google이 이를 공식 문서에 넣었다는 것은 Gemma 4 12B를 "다운로드 가능한 모델"로만 팔지 않겠다는 뜻입니다. 로컬 endpoint, prefix caching, desktop app, agent harness가 한 묶음입니다.
Google은 google-gemma/gemma-skills 저장소도 공개했습니다. 저장소는 Apache-2.0이고, README에는 gemma-dev skill이 표시됩니다. 개발자 가이드는 llama.cpp로 로컬 served Gemma 4 12B를 쓰고, OpenCode와 gemma-skills를 결합해 Gradio image processing app을 만들었다는 예시를 들었습니다. 이 부분은 Google이 Codex나 Claude Code 같은 범용 coding agent와 정면충돌하기보다, Gemma를 agent가 쓸 수 있는 specialist local model로 배치하는 장면입니다.
Mac 쪽 제품도 같은 메시지를 냅니다. Google AI Edge Gallery desktop은 Apple Silicon GPU에서 Gemma 4 12B를 offline으로 돌리고, chat bubble 안에서 secure sandboxed Python execution loop를 제공한다고 적었습니다. Eloquent app은 Gemma 12B로 Voice Edit conversational input을 지원합니다. 로컬 모델이 단순 chat UI에 머무르지 않고, 파일·이미지·음성·Python 실행을 묶은 작은 작업 환경으로 이동한다는 뜻입니다.
여기서 cloud model과 로컬 model의 역할은 선명하게 나뉩니다. frontier model은 복잡한 planning, long horizon reasoning, enterprise integration에서 계속 필요합니다. 로컬 12B multimodal model은 privacy, latency, offline, 반복 비용이 더 큰 제약인 곳에 들어갑니다. 예를 들어 현장 장비 사진 분류, 회의 중 음성 메모 요약, 개인 문서의 초벌 분류, UI screenshot 기반 bug triage, test failure screenshot 해석 같은 작업은 매번 cloud로 보내기 애매합니다. 로컬 model이 충분히 빠르고 싸다면, cloud call 전의 filter나 draft agent로 쓰일 수 있습니다.
Hacker News 반응은 이 기대와 한계를 같이 보여줬습니다. 2026년 6월 4일 KST 기준 HN 토론은 약 4시간 만에 500포인트 이상과 180개가 넘는 댓글을 기록했습니다. 상단 댓글 중 하나는 4-bit GGUF quant를 llama.cpp로 돌려 minesweeper vibe-coding benchmark를 시험했다고 적었습니다. 이 사용자는 12GB VRAM 소비자 GPU에서 output 5 tokens/s를 얻었고, 결과는 괜찮았지만 trivial syntax error를 몇 번 수동으로 고쳤다고 보고했습니다.
이 댓글은 좋은 균형추입니다. Google의 "16GB급 로컬 실행" 주장은 접근성을 말하지만, 개발자는 quantization, context length, tokens/s, syntax reliability를 따로 확인해야 합니다. 5 tokens/s는 실험으로는 의미가 있어도 빠른 interactive coding assistant에는 답답할 수 있습니다. syntax error가 linter feedback으로 고쳐지는 harness라면 받아들일 수 있지만, agent가 tool call과 file edit을 반복하는 환경에서는 작은 문법 오류도 비용으로 돌아옵니다.
HN의 두 번째 논점은 encoder-free 표현이었습니다. 한 사용자는 vision embedder가 35M parameter layer라면 "encoding이 전혀 없다"는 뜻은 아니라고 지적했습니다. 다른 사용자는 dedicated encoder neural network가 없다는 뜻으로 읽어야 한다고 정리했습니다. 기사에서도 이 구분이 필요합니다. Gemma 4 12B는 image와 audio를 아무 처리 없이 LLM에 넣는 모델이 아닙니다. 별도 ViT나 conformer tower를 줄이고, projection과 coordinate lookup 같은 가벼운 경로로 LLM backbone에 밀어 넣는 모델입니다.
audio 쪽 댓글도 따로 볼 만합니다. 한 HN 사용자는 raw audio signal을 text token과 같은 dimensional space로 linear transform하는 부분이 더 흥미롭다고 적었습니다. 이 반응은 기술 독자가 실제로 보는 지점을 드러냅니다. image encoder 축소는 이미 여러 연구가 있었지만, medium-sized open-weight model에서 native audio input을 같이 넣고 로컬 agent 사례까지 연결한 조합은 제품화 관점에서 새롭습니다.
GeekNews 첫 화면에서는 아직 Gemma 4 12B launch 자체가 크게 올라오지 않았습니다. 대신 Claude Code dynamic workflows, OpenAI Codex Sites, MAI-Code-1-Flash, local Gemma 실행 글이 나란히 보였습니다. 한국 개발자 커뮤니티가 보는 질문도 비슷합니다. "어떤 모델이 가장 똑똑한가"보다 "어떤 도구가 내 파일, 브라우저, 터미널, 이미지, 음성을 다루면서 비용과 권한을 감당할 수 있는가"가 제품 선택의 기준으로 이동하고 있습니다.
Gemma 4 12B는 이 기준에서 Google의 포지션을 넓힙니다. Gemini API와 AI Studio는 cloud-first 개발 표면입니다. Android AppFunctions와 ML Kit은 OS와 앱 함수 호출 쪽입니다. Gemma 4 12B와 AI Edge Gallery, LiteRT-LM은 로컬 실행 쪽입니다. Google은 이 세 층을 모두 갖고 있지만, 개발자가 실제로 체감하는 품질은 각 층이 얼마나 끊기지 않고 이어지는지에 달려 있습니다. 로컬 prototype에서 Cloud Run endpoint로 옮길 때 prompt, tool schema, safety policy, model behavior가 크게 바뀌면 생산성은 떨어집니다.
경쟁사는 각자 다른 압력을 만듭니다. OpenAI Codex와 ChatGPT Sites는 workspace 안에서 code와 web app 생성 경험을 밀고 있습니다. Anthropic Claude Code는 dynamic workflows와 subagent harness로 장시간 coding task를 강조합니다. GitHub Copilot app은 worktree, PR, review, Agent Merge를 GitHub-native 경험으로 묶습니다. Meta, Mistral, Qwen, MiniMax 같은 open-weight 진영은 로컬 실행과 서버 비용을 밀어붙입니다. Gemma 4 12B는 Google이 open-weight multimodal model을 이 경쟁에 다시 연결한 카드입니다.
실무 팀이 바로 확인할 항목은 네 가지입니다. 첫째, 실제 대상 하드웨어입니다. 16GB unified memory Mac과 16GB VRAM GPU laptop은 memory bandwidth, quantization, thermal throttling이 다릅니다. 둘째, 사용하려는 modality입니다. image caption 정도인지, UI screenshot reasoning인지, audio diarization인지, video frame plus audio 분석인지에 따라 전처리 비용이 달라집니다. 셋째, agent harness입니다. OpenCode, Aider, Continue, 자체 MCP 도구 중 무엇과 붙이는지에 따라 실패 복구 방식이 달라집니다. 넷째, cloud fallback입니다. 로컬 model이 모르는 문제를 Gemini, Claude, GPT 같은 cloud model로 넘기는 기준을 먼저 정해야 합니다.
보안 면에서는 로컬 실행이 만능 답은 아닙니다. 데이터가 cloud로 나가지 않는 장점은 큽니다. 그러나 agent가 local filesystem, shell, browser, Python sandbox를 갖는 순간 권한 경계는 더 가까워집니다. Google AI Edge Gallery의 secure sandboxed Python execution loop, LiteRT-LM의 local server, gemma-skills의 agent instruction은 모두 같은 질문을 만듭니다. 모델이 어디에서 돌든, agent가 읽고 쓰고 실행할 수 있는 범위를 사람이 검토할 수 있어야 합니다.
비용 계산도 바뀝니다. cloud API는 token 가격과 latency가 바로 보입니다. 로컬 model은 무료처럼 보이지만 GPU memory, 배터리, fan noise, quantization 품질, support 부담이 비용입니다. 팀 단위에서는 device heterogeneity도 비용입니다. 어떤 개발자는 M-series Mac에서 충분히 빠르고, 다른 개발자는 integrated GPU Windows laptop에서 느리다면 "로컬 우선" 정책은 곧 지원 정책이 됩니다.
이번 발표의 실질적 의미는 Google이 로컬 AI를 데모가 아니라 agent 개발 경로로 문서화했다는 점입니다. Hugging Face collection, Kaggle checkpoints, LiteRT-LM server, desktop app, gemma-skills, Cloud Run/GKE 배포가 같은 발표 묶음에 들어왔습니다. Gemma 4 12B가 frontier model을 대체한다는 이야기는 아닙니다. 대신 로컬 multimodal agent가 cloud agent의 보조 worker, privacy filter, offline assistant, cheap first pass가 될 수 있는지를 테스트할 기준선이 생겼습니다.
앞으로 확인할 수치는 benchmark 표보다 운영 수치입니다. 4-bit, 8-bit, full precision에서 image/audio task 품질이 얼마나 떨어지는지 먼저 봐야 합니다. 16GB 장비의 sustained tokens/s, OpenAI-compatible local endpoint와 기존 coding agent의 안정성, gemma-skills의 실제 repo 작업 성과도 따로 검증해야 합니다. Google이 2026년 6월 3일 공개한 것은 답이 아니라 검증 가능한 로컬 에이전트 실험 환경에 가깝습니다.