IBM Agentic CLEAR 공개, 에이전트 실패를 3단계로 추적
IBM Research가 Agentic CLEAR 논문과 오픈소스 도구를 공개했습니다. 에이전트 trace를 system, trace, node 단위로 분석합니다.
- 무슨 일: IBM Research가 Agentic CLEAR 논문과 오픈소스 평가 도구를 공개했습니다.
- arXiv 제출일은 2026년 5월 21일, Hugging Face Papers 제출일은 5월 27일입니다.
- 평가 방식: 에이전트 실행 trace를
system,trace,node3단계로 분석해 반복 실패 패턴을 찾습니다. - 지원 범위: LangGraph, CrewAI, MLflow, Langfuse, CSV trace를 대상으로
clear-eval패키지와 dashboard를 제공합니다.- 프로젝트 페이지는 네 개 벤치마크, 일곱 개 agentic setting, 수만 건 LLM call 실험을 제시합니다.
- 실무 의미: 에이전트 관측성의 다음 병목은 로그 수집이 아니라 실패 원인 분류와 개선 우선순위입니다.
IBM Research가 Agentic CLEAR를 공개했습니다. 정확한 논문 제목은 Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents입니다. arXiv에는 2026년 5월 21일 제출됐고, Hugging Face Papers에는 5월 27일 IBM Research 소속으로 올라왔습니다. 저자는 Asaf Yehudai, Lilach Eden, Michal Shmueli-Scheuer입니다. 논문과 프로젝트 페이지가 말하는 문제는 간단합니다. 에이전트는 점점 더 많은 trace를 남기지만, 개발자는 여전히 실패 원인을 사람이 직접 훑어야 합니다.
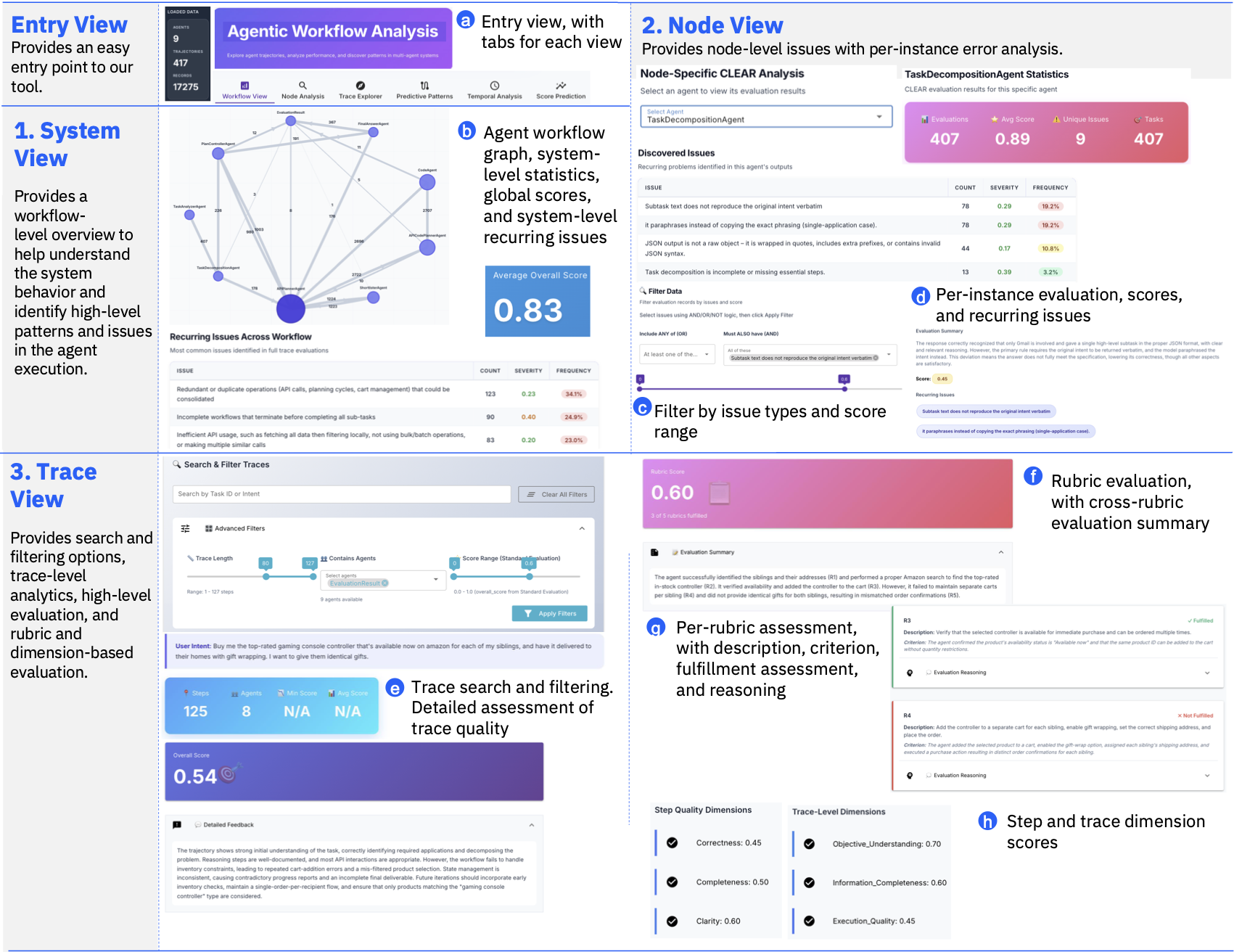
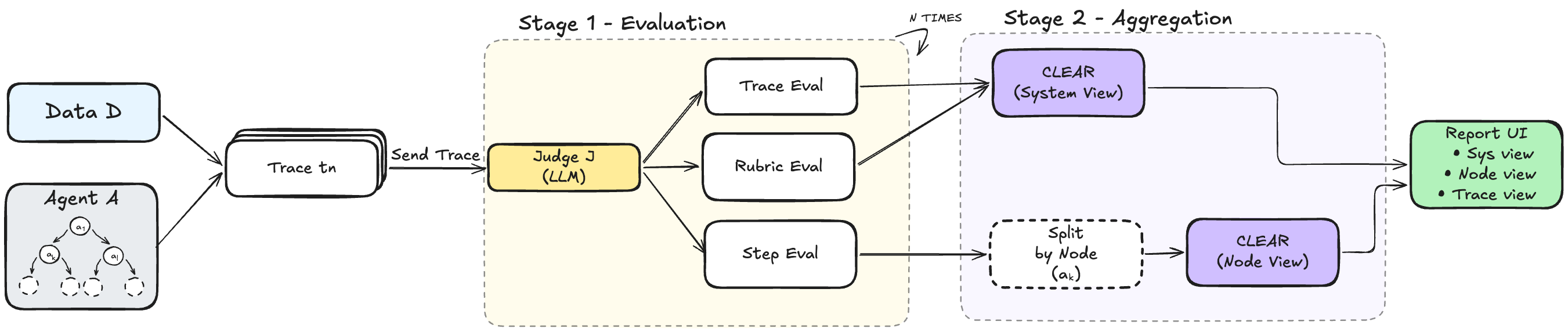
Agentic CLEAR는 이 공백을 겨냥합니다. LangGraph나 CrewAI 기반 에이전트가 MLflow, Langfuse, CSV 형태로 남긴 실행 trace를 받아 system, trace, node 세 단계로 평가합니다. system level은 전체 에이전트 시스템에서 반복되는 실패 패턴을 찾고, trace level은 한 작업 실행의 궤적을 평가하며, node level은 특정 에이전트나 도구 호출 지점의 문제를 분리합니다. 이 구조는 “성공률이 낮다”에서 멈추지 않고 “어떤 단계가 어떤 유형으로 실패했는가”를 묻습니다.
최근 에이전트 평가 논의는 leaderboard와 benchmark 점수에 집중됐습니다. IBM Research도 Hugging Face에 Open Agent Leaderboard를 올려 general-purpose agent를 비교하는 실험을 공개했습니다. Agentic CLEAR는 그 옆에 놓이는 도구입니다. leaderboard가 모델이나 agent configuration의 상대 순위를 보여준다면, Agentic CLEAR는 실패한 trace를 다시 열어 반복 오류를 묶습니다. 팀 입장에서는 둘 다 필요합니다. 도입 전에는 점수가 필요하고, 운영 중에는 실패 원인이 필요합니다.
프로젝트 페이지의 TL;DR은 observability 플랫폼이 execution trace를 캡처하지만 meaningful evaluation은 부족하다고 지적합니다. 이 문장은 에이전트 운영팀이 이미 겪는 문제를 정확히 찌릅니다. Langfuse, MLflow, OpenTelemetry 계열 trace는 어떤 도구가 언제 호출됐는지 보여줍니다. 그러나 trace가 많아질수록 사람이 읽을 수 있는 양은 줄어듭니다. 1,000개 실패 trace가 쌓이면 필요한 것은 더 긴 로그가 아니라 공통 원인 10개와 재현 가능한 사례입니다.
Agentic CLEAR의 입력과 출력은 그 목적에 맞춰 설계됐습니다. 입력은 raw JSON trace 또는 전처리된 trajectory CSV입니다. 출력은 step별 CLEAR analysis, trajectory-level score, rubric evaluation, system/node/trace dashboard입니다. GitHub README는 pip install clear-eval 설치와 run-clear-agentic-eval 명령을 제시합니다. 샘플 smoke test는 MLflow에 저장된 LangGraph research agent trace 3개를 약 2분 동안 평가하는 형식입니다.
pip install clear-eval
run-clear-agentic-eval \
--data-dir src/clear_eval/sample_data/agentic/research_agent_traces/mlflow \
--results-dir my_results \
--from-raw-traces true \
--agent-framework langgraph \
--observability-framework mlflow \
--max-files 3 \
--eval-model-name gpt-4o \
--provider openai
run-clear-agentic-dashboard
지원 표도 실무적입니다. 프로젝트 페이지는 LangGraph와 MLflow 조합, LangGraph와 Langfuse 조합, CrewAI와 Langfuse 조합, CSV 기반 custom trace를 지원 대상으로 적었습니다. 이는 특정 agent framework 하나를 benchmark하는 논문이 아니라, trace가 남는 agent stack 위에 evaluation layer를 얹겠다는 방향입니다. GitHub README는 LiteLLM을 inference backend로 사용해 OpenAI, Anthropic, WatsonX, AWS Bedrock, Google Vertex AI 등 100개 이상 provider를 연결할 수 있다고 설명합니다.
프로젝트 페이지의 experimental setup은 구체적입니다. AppWorld에서는 CUGA agent와 GPT-4o backbone으로 417개 trace를 평가했습니다. GAIA에서는 HAL Generalist Agent를 Claude 4.5 Sonnet과 GPT-4.1 backbone으로 각각 165개 trace씩 평가했습니다. HF DeepResearch에서는 Claude 4.5 Sonnet 165개 trace와 OpenAI o3 117개 trace가 들어갑니다. SWE-bench Verified는 Claude 4.5 Sonnet 50개 trace, TAU-bench는 Claude 3.7 Sonnet 50개 trace입니다. 이 표는 Agentic CLEAR가 한 종류의 웹 브라우징 에이전트만 보지 않았다는 근거입니다.
분석 결과에서 가장 흥미로운 수치는 195개입니다. 프로젝트 페이지는 Agentic CLEAR가 전체 configuration에서 195개 unique recurring issues를 발견했다고 적었습니다. AppWorld 예시에서는 execution flow management flaws, validation and preconditions gaps, blockage handling failures 같은 system-level issue가 나옵니다. incomplete execution과 entity resolution weaknesses도 별도 반복 이슈로 묶였습니다. node-level에서는 특정 TaskDecompositionAgent가 unsupported app capability를 가정하거나 strict app constraint를 어기는 문제가 분리됩니다.
이 차이는 운영팀에게 중요합니다. system-level issue는 제품 정책이나 전체 planner 설계를 바꿔야 할 수 있습니다. node-level issue는 특정 도구 wrapper, subagent prompt, routing rule을 고치는 문제일 수 있습니다. trace-level issue는 개별 실패 재현과 디버깅에 가깝습니다. 같은 실패율 20%라도 세 단위가 다르면 수정 비용과 담당자가 달라집니다. Agentic CLEAR의 장점은 이 세 단위를 한 dashboard 안에 놓는다는 점입니다.
프로젝트 페이지는 GAIA와 SWE-bench Verified 비교도 보여줍니다. GAIA 연구 작업에서는 independent source cross-verification 부족, unreliable references, search avenue를 다 확인하기 전 premature conclusion, formatting specification 위반 같은 이슈가 나타납니다. SWE-bench Verified 코드 작업에서는 malformed diff, missing hunk, monkey-patching, regression test 누락, dependency 이해 부족, compile/test 미검증 같은 이슈가 나옵니다. 이 목록은 agent evaluation이 domain-specific이어야 한다는 사실을 보여줍니다.
Agentic CLEAR의 방법론은 fixed taxonomy에만 기대지 않습니다. 논문 초록은 기존 도구가 basic observability에 머물거나 static hand-crafted error taxonomy에 의존한다고 지적합니다. Agentic CLEAR는 LLM-as-a-Judge 방식으로 trace를 평가하고, CLEAR aggregation으로 recurring issue를 cluster합니다. 즉, 사람이 미리 “이 에이전트는 이런 오류만 낸다”고 정의하지 않아도 실제 실행 데이터에서 반복 패턴을 끌어내려 합니다. 이 방식은 새 agent workflow가 계속 생기는 2026년 환경에 맞습니다.
물론 LLM judge를 쓰는 평가에는 한계가 있습니다. judge 모델이 틀릴 수 있고, tool trace의 의미를 잘못 해석할 수 있으며, domain-specific success condition을 놓칠 수 있습니다. Agentic CLEAR도 완전 자동 판정기가 아니라 error analysis 도구로 읽어야 합니다. 사람이 trace 1,000개를 다 읽는 대신, tool이 반복 이슈 후보를 묶어주고 개발자가 우선순위를 정하는 구조입니다. 이 구분은 중요합니다. 평가 자동화가 곧 운영 책임 자동화를 뜻하지는 않습니다.
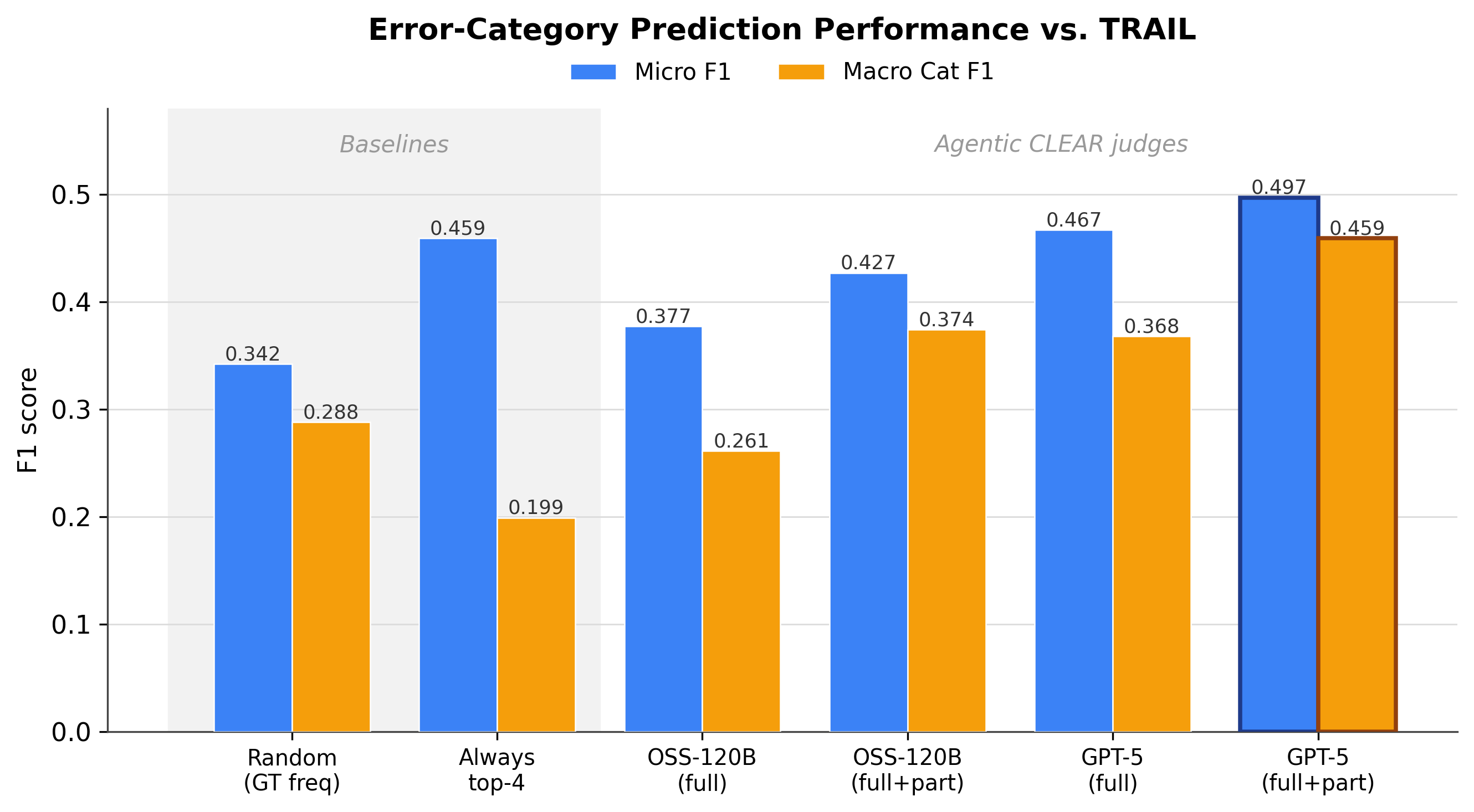
Score prediction 결과도 참고할 만합니다. 프로젝트 페이지의 AUC 표는 trajectory success를 예측하기 위해 step-wise 평균 점수, trace-level holistic judgment, rubric-based criteria 비율을 비교합니다. 설명에 따르면 trace-level evaluation이 대체로 강하고 AppWorld에서는 0.890까지 올라갑니다. 다만 benchmark와 agent에 따라 가장 좋은 방식이 달라졌다고 적혀 있습니다. 이 문장은 한 가지 평가 신호만으로 모든 에이전트를 관리하기 어렵다는 뜻입니다.
Agentic CLEAR가 제시하는 dashboard는 workflow view, node analysis, trajectory explorer, path analysis, temporal analysis, score prediction을 포함합니다. workflow view는 agent와 transition graph를 보여주고 call count를 표시합니다. node analysis는 component별 CLEAR issue와 score distribution을 봅니다. trajectory explorer는 길이, agent, score로 실행 궤적을 필터링합니다. path analysis는 성공과 실패의 공통 경로를 비교합니다. temporal analysis는 step 위치와 score 변화를 따라갑니다.
이 기능 묶음은 APM이나 observability 제품의 AI 버전처럼 보일 수 있습니다. 그러나 중요한 차이는 “원인 언어화”입니다. 일반 trace UI는 latency, error rate, span, token count를 보여줍니다. Agentic CLEAR는 source verification gaps, broken patch output, fails to isolate the minimal reproducible case 같은 개선 가능한 문장으로 묶습니다. 개발팀은 이 문장을 backlog item으로 바꿀 수 있습니다. 예를 들어 SWE-bench agent에서 regression test 누락이 반복되면 agent prompt보다 merge gate를 먼저 바꿔야 할 수 있습니다.
오픈소스 조건도 확인할 필요가 있습니다. GitHub의 IBM/CLEAR 저장소는 Apache 2.0 라이선스이며, 2026년 5월 30일 확인 시점 기준 45 stars와 10 forks가 표시됐습니다. PyPI의 clear-eval 패키지는 Python 3.10 이상을 요구합니다. PyPI 최신 버전 표시는 1.0.8, 릴리스 날짜는 2025년 10월 22일로 보입니다. Agentic CLEAR 논문과 프로젝트 페이지가 2026년 5월에 공개됐기 때문에 실제 패키지 기능과 문서의 최신 agentic 모드가 어떻게 배포돼 있는지는 설치 후 명령 도움말로 확인해야 합니다.
커뮤니티 반응은 아직 작습니다. Hugging Face Papers 페이지의 upvote는 4개였고, submitter는 초록과 같은 설명을 댓글로 남겼습니다. Librarian Bot은 Holistic Evaluation and Failure Diagnosis of AI Agents, AJ-Bench, Claw-Eval, AgentEscapeBench 같은 유사 논문을 추천했습니다. 이 조용한 반응은 부정적 신호라기보다 연구 도구의 초기 공개에 가깝습니다. 에이전트 평가 시장은 아직 개발자 대중보다 agent infra 팀과 연구팀이 먼저 읽는 단계입니다.
Agentic CLEAR를 도입하려는 팀은 먼저 trace 품질을 봐야 합니다. node 이름, tool call 인자, observation, final answer, error message가 안정적으로 남지 않으면 평가 도구도 원인을 정확히 묶기 어렵습니다. LangGraph나 CrewAI를 쓰더라도 내부 tool wrapper가 의미 없는 span 이름만 남긴다면 node analysis가 흐려집니다. 반대로 tool result, retry, exception, human approval event가 구조화돼 있으면 CLEAR 같은 분석기가 반복 문제를 더 쉽게 찾습니다.
두 번째 확인 항목은 judge 비용입니다. Agentic CLEAR는 LLM-as-a-Judge 접근을 쓰며, GitHub README 예시는 gpt-4o를 평가 모델로 둡니다. trace가 길고 agent step이 많으면 judge 호출 비용도 커집니다. 실패 trace 전체를 매번 평가하기보다 sampling, nightly batch, release candidate evaluation처럼 주기를 정해야 합니다. 운영 중 모든 trace를 실시간으로 judge하는 구조는 비용과 지연시간을 동시에 키울 수 있습니다.
세 번째 항목은 평가 결과를 제품 변경으로 연결하는 방식입니다. Agentic CLEAR가 “source verification gaps”를 반복 이슈로 묶었다면, 수정은 세 갈래입니다. planner에게 독립 출처 두 개를 요구할 수 있고, browser/search tool wrapper에 source metadata를 강제할 수 있으며, final answer validator가 citation check를 수행하게 만들 수 있습니다. 같은 이슈라도 prompt, tool, verifier, workflow policy 중 어디를 고칠지 정해야 합니다. dashboard가 말해주는 것은 출발점입니다.
Agentic CLEAR가 던지는 메시지는 에이전트 평가의 단위가 바뀐다는 점입니다. 이제 팀은 단일 model score, pass@1, task success rate만으로 충분하지 않습니다. 장기 실행 에이전트는 실패 경로가 다양합니다. 잘못된 tool을 고르거나, 같은 검색을 반복하거나, 중간 오류 뒤에 fallback을 쓰지 않거나, 코드 patch를 잘못된 파일에 적용하거나, 최종 답변 전에 작업을 멈춥니다. 이 실패들은 모두 “틀렸다”로 끝나지만 고치는 방법은 서로 다릅니다.
2026년의 에이전트 운영에서 observability는 출발선입니다. Agentic CLEAR는 그 위에 평가와 실패 군집화를 얹는 시도입니다. 성공률 그래프가 내려갔을 때 어느 node가 문제인지, 어떤 path가 실패로 이어지는지, 어떤 이슈가 가장 자주 반복되는지 자동으로 요약할 수 있다면 agent backlog는 더 구체적이 됩니다. 이 도구가 모든 팀의 표준이 될지는 아직 모릅니다. 다만 에이전트가 제품 업무를 맡기 시작한 팀이라면, “로그를 모았다” 다음 질문이 무엇인지 보여주는 사례로 읽을 만합니다.