72% 브라우저 성공률, 작은 에이전트가 Operator를 넘은 지점
Microsoft Fara1.5는 작은 computer use 모델과 합성 웹 환경이 브라우저 에이전트 경쟁의 새 병목임을 보여줍니다.

- 무슨 일: Microsoft Research가
Fara1.5,MagenticBrain,MagenticLite를 공개했습니다.- Fara1.5는 브라우저를 조작하는 computer use agent 모델군으로, 4B, 9B, 27B 크기로 제시됐습니다.
- 핵심 수치:
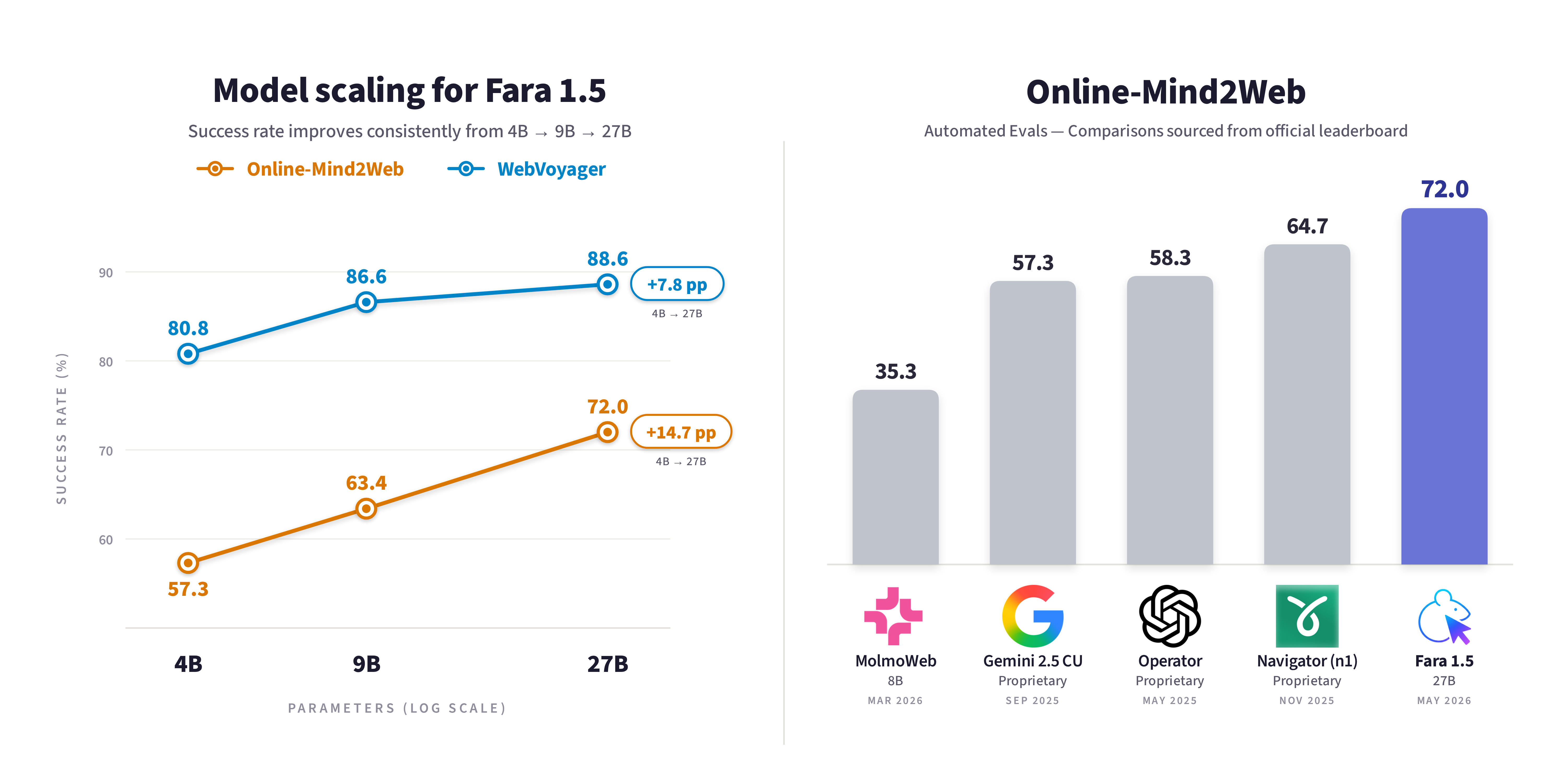
Fara1.5-27B는 Online-Mind2Web 자동 평가에서 72.0%를 기록했습니다.- Microsoft 표 기준으로 Operator 58.3%, Gemini 2.5 Computer Use 57.3%, Yutori Navigator n1 64.7%와 비교됩니다.
- 의미: 브라우저 에이전트의 병목이 거대 모델 호출에서 작은 모델, 합성 환경, 검증기, 승인 정책으로 이동합니다.
- 주의점: 연구 미리보기이며, 벤치마크 우위가 곧 실제 제품 전체 우위를 뜻하지는 않습니다.
Microsoft Research가 2026년 5월 21일 Fara1.5 모델군을 공개했습니다. 함께 나온 이름은 MagenticLite와 MagenticBrain입니다. 발표를 한 문장으로 줄이면 이렇습니다. 브라우저를 대신 조작하는 에이전트는 반드시 가장 큰 폐쇄형 모델만으로 움직일 필요가 없으며, 작은 모델과 전용 하네스, 합성 웹 환경, 검증기를 잘 묶으면 실용적인 성능에 가까워질 수 있습니다.
이 뉴스가 흥미로운 이유는 단순한 모델 출시가 아니기 때문입니다. 최근 브라우저 에이전트 경쟁은 OpenAI Operator, Google Gemini Computer Use, Yutori Navigator, Playwright 기반 자동화 도구, Browserbase 계열 런타임처럼 "사람이 보는 웹을 AI가 대신 쓰는" 방향으로 몰리고 있습니다. 하지만 실제 서비스에 넣으려는 순간 질문이 바뀝니다. 모델이 화면을 얼마나 잘 이해합니까. 비용은 얼마입니까. 로그인 뒤의 업무 앱은 어떻게 학습합니까. 되돌릴 수 없는 제출 버튼 앞에서 어떻게 멈춥니까. 나중에 어떤 action을 했는지 감사할 수 있습니까.
Fara1.5는 이 질문에 연구 시스템으로 답합니다. Microsoft는 4B, 9B, 27B 세 크기의 computer use agent 모델을 제시했고, Fara1.5-9B가 WebVoyager에서 86.6%, Online-Mind2Web에서 63.4% task success rate를 냈다고 밝혔습니다. 더 큰 Fara1.5-27B는 Online-Mind2Web에서 72.0%를 기록했습니다. Microsoft의 같은 표에서 OpenAI Operator는 58.3%, Google Gemini 2.5 Computer Use는 57.3%, Yutori Navigator n1은 64.7%입니다. 이 숫자만 보면 "작은 모델이 대형 제품을 이겼다"는 제목이 쉽습니다. 그러나 더 중요한 뉴스는 왜 그런 결과가 나왔는지입니다.
작은 모델이 중요한 이유
브라우저 에이전트는 챗봇보다 훨씬 비싼 실패를 만듭니다. 모델이 틀린 답을 쓰는 것과, 사용자를 대신해 잘못된 상품을 결제하거나 회사 문서를 엉뚱한 곳에 제출하는 것은 다릅니다. 그래서 computer use agent의 핵심은 추론 성능만이 아닙니다. 지연시간, 실행 비용, 로컬 또는 사설 배포 가능성, 로그와 재현성, 사용자의 중간 승인, 샌드박스 격리가 모두 함께 필요합니다.
큰 frontier model을 매 step마다 호출하면 성능은 좋을 수 있습니다. 하지만 브라우저 에이전트는 보통 한 번의 답변으로 끝나지 않습니다. 화면을 보고, 클릭하고, 다시 보고, 입력하고, 모달을 닫고, 실패를 복구합니다. Microsoft의 Fara1.5 설명도 observe-think-act loop를 전제로 합니다. 각 단계에서 최근 3개 브라우저 스크린샷과 대화 이력을 보고, 다음 하나의 원자적 action을 예측합니다. 이런 구조에서는 step 비용이 바로 제품 비용이 됩니다. 모델이 작아질수록 온디바이스, 사내 GPU, 더 낮은 지연시간 같은 선택지가 생깁니다.
물론 작은 모델이 자동으로 안전하다는 뜻은 아닙니다. 오히려 작은 모델은 도구와 하네스에 더 강하게 의존합니다. Fara1.5가 의미 있는 지점도 여기에 있습니다. Microsoft는 "더 작은 모델도 가능하다"는 주장만 한 것이 아니라, 작은 모델을 훈련시키기 위한 합성 데이터 파이프라인과 검증 조건을 함께 보여줬습니다. 브라우저 에이전트의 경쟁축이 모델 파라미터 수에서 데이터 생성, 평가, 실행 하네스로 내려오는 장면입니다.
Fara1.5가 보는 웹은 사람의 웹과 조금 다릅니다
Fara1.5는 브라우저 화면을 보고 action을 내는 computer use model입니다. Microsoft는 모델이 표준 마우스와 키보드 입력, 웹 검색 같은 web-specific action, 그리고 정보를 기억하거나 사용자에게 질문하는 context management action을 낸다고 설명합니다. 여기서 중요한 것은 "질문하는 action"입니다. 실제 웹 작업은 사용자의 선호와 개인 정보가 없으면 진행할 수 없는 순간이 많습니다. 배송지를 알아야 하고, 결제 승인을 받아야 하고, 날짜가 애매하면 확인해야 합니다.
Microsoft가 critical point로 든 것도 이 지점입니다. 작업에 필요한 사용자 정보가 빠졌을 때, 지시가 애매할 때, 되돌릴 수 없는 행동을 승인 없이 하려 할 때 모델이 멈추고 물어야 합니다. 이는 브라우저 에이전트 제품에서 가장 중요한 UX입니다. 좋은 에이전트는 많은 것을 자동으로 처리하지만, 무엇을 자동으로 처리하지 않을지도 알아야 합니다.
이런 관점에서 Fara1.5의 점수는 단순한 benchmark bragging이 아닙니다. 브라우저 에이전트를 실제 업무에 넣으려면 "클릭을 잘한다"와 "멈출 때 멈춘다"를 동시에 만족해야 합니다. 웹 자동화의 오래된 도구들은 selector와 DOM을 잘 다루지만 의미와 승인 경계가 약합니다. 일반 LLM 에이전트는 의미를 잘 추론하지만 화면, 상태, 반복 action에서 비용과 불확실성이 큽니다. Fara1.5는 그 사이를 small model과 전용 action space로 좁히려는 시도입니다.
진짜 무기는 FaraGen1.5입니다
Fara1.5 발표에서 가장 실무적인 부분은 모델 이름보다 FaraGen1.5입니다. Microsoft는 FaraGen1.5를 computer use data를 만들기 위한 end-to-end synthetic data generation pipeline으로 설명합니다. 구조는 environments, solvers, verifiers 세 단계입니다. 환경을 만들고, 강한 solver agent가 task trajectory를 만들고, 검증기가 correctness, efficiency, user interaction 기준으로 걸러냅니다.
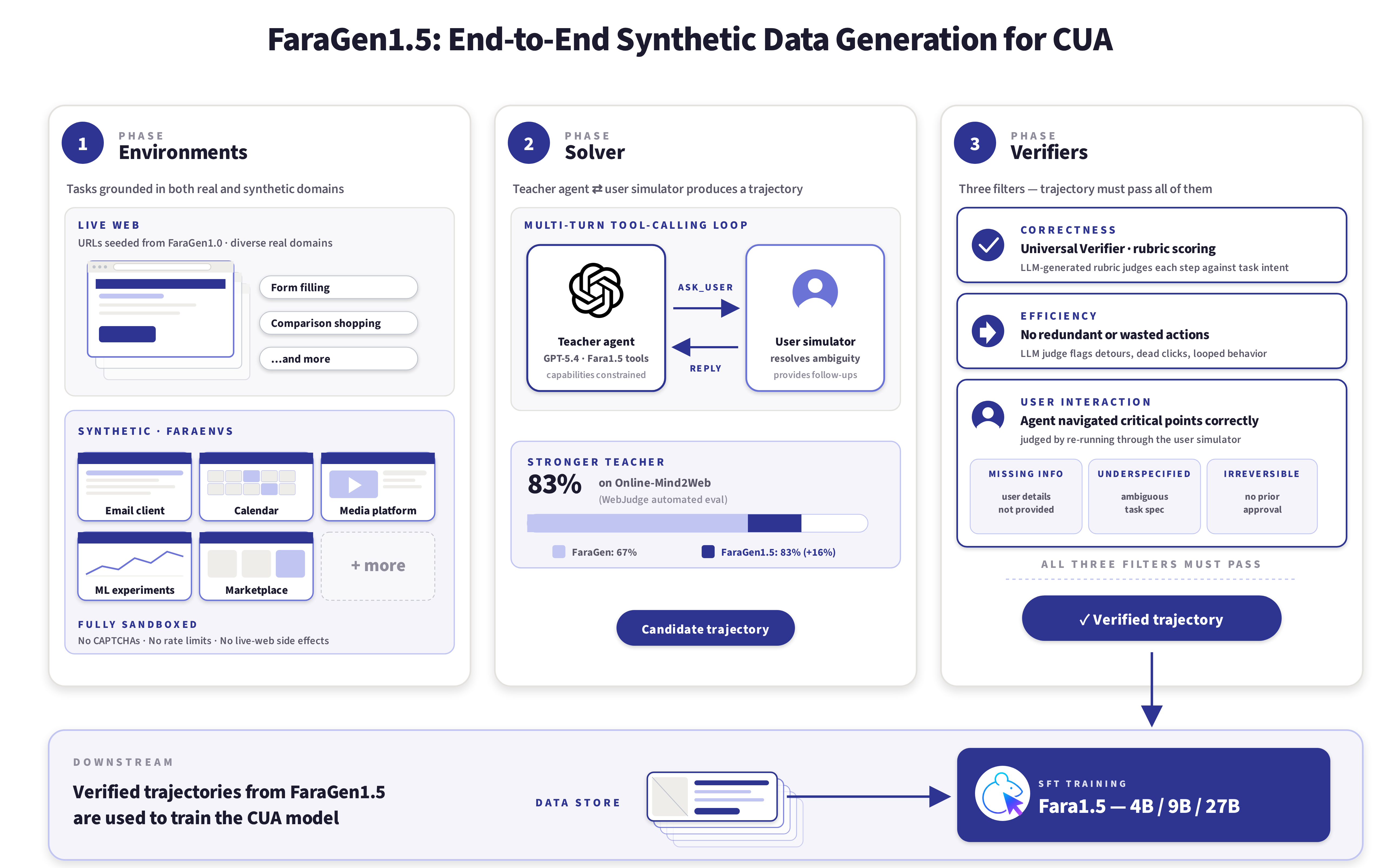
왜 합성 환경이 필요할까요. 브라우저 에이전트를 live web에서만 학습시키면 할 수 없는 일이 많습니다. 로그인해야 하는 사이트, 실제 이메일 전송, 예약 확정, 결제, 사내 도구의 데이터 변경처럼 안전 문제와 계정 문제가 있는 작업은 공개 웹에서 마음대로 수행할 수 없습니다. 하지만 바로 그런 작업이 에이전트의 핵심 사용 사례입니다. "항공권을 찾아줘"보다 어려운 것은 "내 조건에 맞으면 예약을 진행하고 승인 전에 멈춰줘"입니다.
Microsoft는 이를 위해 synthetic domain을 만듭니다. 이메일 클라이언트, 캘린더, 미디어 플랫폼, ML experiment manager, marketplace 같은 환경을 모사하고, UI와 database와 task를 통제합니다. 특히 흥미로운 대목은 Microsoft가 synthetic environment 제작에 GitHub Copilot CLI를 사용했다고 밝힌 부분입니다. 실제 도메인의 interaction trajectory를 모으고, coding agent가 기능적인 sandbox clone의 spec을 만들고, 사람이 반복 검증합니다. 말하자면 코딩 에이전트가 브라우저 에이전트를 훈련시키는 연습장을 만드는 셈입니다.
이 흐름은 앞으로 AI 개발팀에게 익숙해질 가능성이 큽니다. 에이전트를 잘 만들려면 제품의 축소판, 실패 가능한 sandbox, 정답을 아는 database snapshot, action log, verifier가 필요합니다. 일반적인 "테스트 데이터"보다 훨씬 제품에 가깝고, 일반적인 "운영 환경"보다 훨씬 통제 가능합니다. Fara1.5가 보여준 것은 모델 출시보다 에이전트 학습 인프라의 모양입니다.
숫자는 강하지만, 읽는 법이 더 중요합니다
Microsoft의 표는 인상적입니다. Fara1.5-27B는 Online-Mind2Web에서 72.0%를 기록했고, 같은 표의 Operator, Gemini 2.5 Computer Use, Yutori Navigator n1보다 높습니다. Fara1.5-9B도 63.4%로 작은 모델 중 강한 결과를 보였습니다. WebVoyager에서는 Fara1.5-27B가 88.6%, Fara1.5-9B가 86.6%입니다. Microsoft는 Fara1.5 수치가 세 번의 독립 실행 평균이라고 덧붙였습니다.
하지만 이 숫자를 제품 순위표로만 읽으면 위험합니다. 브라우저 에이전트 benchmark는 세션 안정성, 사이트 변경, block rate, task 분포, judge 품질, 도구 action space에 민감합니다. Microsoft도 Browserbase를 사용해 브라우저 세션을 안정화하고 session-level blocking을 줄였다고 설명합니다. 다른 제품의 public benchmark 숫자와 같은 표에 놓여 있어도, 사용자가 실제로 느끼는 성능은 업무 도메인, 로그인 상태, action 제한, 사용 중인 브라우저 런타임에 따라 달라집니다.
그래서 이번 발표의 결론은 "Microsoft가 OpenAI와 Google을 완전히 이겼다"가 아닙니다. 더 정확한 결론은 "작은 전용 모델도 잘 설계된 synthetic training과 verifier, browser harness를 만나면 폐쇄형 범용 에이전트와 경쟁할 수 있는 구간이 생겼다"입니다. 이 차이가 중요합니다. 전자는 과장이고, 후자는 AI 제품팀이 당장 설계에 반영할 수 있는 신호입니다.
| 항목 | Fara1.5가 강조한 답 | 실무에서 남는 질문 |
|---|---|---|
| 모델 크기 | 4B, 9B, 27B computer use 모델군 | 로컬, 사내 GPU, hosted API 중 어디에 둘 것인가 |
| 학습 환경 | live web와 synthetic gated domain 병행 | 우리 제품의 sandbox replica를 만들 수 있는가 |
| 검증 | correctness, efficiency, user interaction 필터 | 실제 업무 성공과 judge 점수의 간격을 어떻게 줄일 것인가 |
| 안전 | 부족한 정보, 애매한 지시, 승인 없는 irreversible action에서 중단 | 조직별 승인 정책과 감사 로그를 어디에 둘 것인가 |
MagenticLite는 제품보다 실험장의 성격이 강합니다
함께 공개된 MagenticLite는 브라우저와 파일 시스템을 다루는 agentic experience입니다. Microsoft Research의 설명대로라면 Fara1.5는 브라우저 조작 모델이고, MagenticBrain은 orchestration을 맡는 작은 모델이며, MagenticLite는 사용자가 이를 실행해 볼 수 있는 인터페이스와 하네스에 가깝습니다. Fara1.5-9B는 Microsoft Foundry에서 사용 가능하고 MagenticLite에 통합됐으며, 4B와 27B는 곧 제공될 예정이라고 안내됐습니다.
GitHub의 microsoft/fara 저장소도 이 흐름을 보완합니다. README에는 2026년 5월 21일 "Fara1.5 agent harness coming soon" 업데이트가 올라와 있고, 이전 Fara-7B의 실행 방식과 WebTailBench, CUAVerifierBench 같은 평가 자산이 정리돼 있습니다. 아직 모든 것이 완성된 제품처럼 열린 것은 아닙니다. 그래서 이번 발표를 도입 가이드로 읽기보다, Microsoft가 어디에 투자하는지 보여주는 연구 방향으로 읽는 편이 낫습니다.
개발자에게 실질적으로 남는 것은 두 가지입니다. 첫째, 브라우저 에이전트를 만들 때 모델만 교체하는 것으로는 충분하지 않습니다. action space, sandbox, verifier, user approval, telemetry가 함께 설계돼야 합니다. 둘째, 작은 모델을 진지하게 검토할 이유가 생겼습니다. 모든 브라우저 task를 가장 비싼 frontier model에 맡기지 않고, 반복적이고 구조가 분명한 task는 전용 모델로 낮추는 routing이 가능해질 수 있습니다.
브라우저 에이전트의 다음 경쟁축
최근 devlery에서 다룬 WebMCP나 Chrome DevTools for agents 흐름과 비교하면 그림이 더 선명합니다. WebMCP는 웹사이트가 브라우저 에이전트에게 구조화된 도구를 노출하는 방향입니다. DevTools for agents는 코딩 에이전트가 실제 브라우저 런타임을 더 잘 관찰하게 하는 방향입니다. Fara1.5는 브라우저를 직접 조작하는 모델과 그 모델을 키우는 합성 환경의 방향입니다. 세 흐름 모두 같은 질문으로 모입니다. 에이전트가 웹을 쓰게 하려면 사람용 UI 바깥에 어떤 계층을 새로 만들어야 합니까.
그 계층은 하나가 아닙니다. 웹앱은 에이전트용 도구 표면을 제공해야 할 수 있습니다. 에이전트 런타임은 browser session과 sandbox를 관리해야 합니다. 모델 팀은 synthetic environment와 verifier를 만들어야 합니다. 보안팀은 승인 없는 irreversible action을 막고, 감사 로그와 데이터 경계를 정책화해야 합니다. 제품팀은 사용자가 어디서 개입하고 어디서 자동화를 믿을지 UX로 풀어야 합니다.
Fara1.5의 72.0%라는 숫자는 그래서 좋은 headline hook입니다. 하지만 이 숫자가 가리키는 진짜 변화는 더 넓습니다. 브라우저 에이전트 시장은 "누가 가장 똑똑한 모델을 가졌는가"에서 "누가 웹 task를 훈련, 실행, 검증, 승인할 수 있는 시스템을 가졌는가"로 이동하고 있습니다. Microsoft가 작은 모델과 MagenticLite를 함께 꺼낸 것은 이 경쟁이 모델 API 하나로 끝나지 않는다는 신호입니다.
지금 팀이 봐야 할 체크포인트
AI 제품팀이나 플랫폼팀이 이번 발표에서 바로 가져갈 질문은 명확합니다. 우리 서비스의 브라우저 에이전트 task는 live web에서 평가할 수 있습니까. 로그인 뒤에 숨어 있는 핵심 업무를 synthetic environment로 복제할 수 있습니까. 사용자가 승인해야 하는 irreversible action은 무엇입니까. task success를 사람이 아니라 시스템이 판단하려면 어떤 database snapshot, log, rubric이 필요합니까. 작은 모델로 처리해도 되는 반복 task와 frontier model이 필요한 예외 task를 나눌 수 있습니까.
이 질문들은 연구 논문을 읽는 재미를 넘어 배포 비용과 안전성으로 이어집니다. 브라우저 에이전트가 제품 기능이 되면 실패는 데모 실패가 아니라 고객 지원 이슈와 보안 사고가 됩니다. 반대로 제대로 설계되면 반복적인 웹 업무, 내부 운영 도구, QA, 데이터 입력, 비교 조사, 고객 대응에서 큰 자동화 효과가 납니다. Fara1.5는 그 중간 지대를 보여줍니다. 아직 연구 미리보기지만, 작은 모델도 제대로 된 환경과 검증을 만나면 브라우저 작업의 일부를 맡을 수 있다는 실험입니다.
결국 이번 뉴스의 핵심은 "Microsoft가 새 에이전트를 냈다"가 아닙니다. 브라우저 에이전트의 경쟁력이 모델 크기만으로 결정되지 않는다는 점입니다. Fara1.5는 모델, 하네스, 합성 웹사이트, verifier, 승인 정책을 한 묶음으로 보여줬습니다. 개발자와 AI 팀이 지금 주목해야 할 곳도 바로 그 묶음입니다. 에이전트가 웹을 쓰는 시대에는, 웹을 보는 모델보다 웹을 안전하게 연습시키고 검증하는 인프라가 더 큰 차이를 만들 수 있습니다.