SQLite에 붙은 에이전트, Datasette가 고른 좁은 길
Datasette Agent는 SQLite 데이터 탐색을 LLM, 플러그인 도구, 권한 모델, sandbox 실행과 결합한 좁지만 실용적인 에이전트 실험입니다.

- 무슨 일: Datasette가 SQLite 데이터용 오픈소스
Datasette Agent를 공개했습니다.- Simon Willison은 2026년 5월 21일 발표에서
llmPython 라이브러리와 Datasette가 본격 결합한 첫 알파라고 설명했습니다.
- Simon Willison은 2026년 5월 21일 발표에서
- 핵심 구조: 자연어 질문을 SQL, 차트, 이미지 생성, sandbox 실행 같은 플러그인 도구로 연결합니다.
- 도구는 Datasette 권한으로 필터링되며, 권한 없는 actor에게는 모델이 해당 tool 자체를 보지 못합니다.
- 의미: 에이전트 경쟁이 범용 비서에서 좁은 데이터 workflow 안으로 내려오는 신호입니다.
- 주의점: 아직
0.1a계열 알파라 운영 기준은 권한, 비용 제한, SQL 검증, sandbox 경계를 따로 봐야 합니다.
Datasette Agent는 거대한 모델 발표가 아닙니다. 새로운 frontier LLM도 아니고, 기업 전체의 에이전트를 관리하는 control plane도 아닙니다. 2026년 5월 21일 Simon Willison과 Datasette 팀이 공개한 것은 훨씬 작은 물건입니다. SQLite 데이터베이스를 탐색하고 게시하는 Datasette 안에 LLM 기반 에이전트를 붙인 오픈소스 플러그인입니다.
그런데 이 작은 발표가 흥미로운 이유가 있습니다. 요즘 AI 에이전트 시장은 “무엇이든 하는 범용 비서”를 향해 계속 커지는 것처럼 보입니다. 코딩 에이전트는 저장소를 수정하고, 브라우저 에이전트는 웹사이트를 조작하고, 기업용 에이전트는 CRM과 메일, 문서, 결제 시스템을 넘나듭니다. 그럴수록 질문은 점점 커집니다. 이 에이전트가 어떤 데이터에 접근했는지, 어떤 도구를 호출했는지, 어느 사용자의 권한으로 행동했는지, 실패했을 때 어디까지 되돌릴 수 있는지 설명할 수 있어야 합니다.
Datasette Agent는 정반대 방향에서 출발합니다. 범위를 SQLite 데이터 탐색으로 좁히고, 에이전트가 쓸 수 있는 도구를 Datasette 플러그인으로 등록하며, 도구 노출을 Datasette 권한 모델로 제한합니다. 사용자는 자연어로 질문하지만, 그 밑에서는 SQL 쿼리, 차트 렌더링, 백그라운드 탐색, sandbox 실행 같은 구체적인 소프트웨어 경로가 움직입니다. 그래서 이 발표의 핵심은 “데이터베이스에 채팅창을 붙였다”가 아닙니다. 에이전트가 좁은 업무 도구 안에 들어올 때 필요한 권한, 플러그인, 비용, 실행 경계를 한꺼번에 보여준다는 점입니다.
Datasette와 LLM이 만나는 지점
Datasette는 SQLite 파일을 웹에서 탐색하고 API로 공개하는 도구입니다. 데이터 저널리스트, 연구자, 박물관, 지방정부, 과학자처럼 “큰 데이터 플랫폼을 운영하고 싶지는 않지만, 구조화된 데이터를 탐색하고 공유해야 하는 사람들”에게 오래 사랑받아 왔습니다. 테이블을 열고, 필터를 걸고, SQL을 실행하고, 결과를 링크로 공유하는 흐름이 핵심입니다.
Simon Willison은 여기에 LLM을 바로 붙이지 않았습니다. 먼저 llm이라는 Python 라이브러리와 CLI를 만들었습니다. 여러 모델 공급자를 플러그인으로 연결하고, 로컬 모델과 클라우드 모델을 같은 명령줄 경험으로 다루는 계층입니다. 그 위에 datasette-llm이 나왔고, 최근에는 모델 사용량 제한과 회계 처리를 위한 datasette-llm-limits, datasette-llm-accountant 같은 주변 플러그인도 등장했습니다.
Datasette Agent는 이 조각들이 실제 데이터 탐색 UX 안에서 만나는 지점입니다. 공식 발표는 “Datasette와 LLM이 드디어 결합했다”는 식으로 설명합니다. 사용자는 /-/agent 경로에서 대화형 assistant를 열고, 데이터베이스에 대해 질문합니다. 에이전트는 테이블 목록을 보고, 스키마를 설명하고, 읽기 전용 SQL을 실행하고, 결과를 표나 차트로 보여줄 수 있습니다. 데이터베이스나 테이블 action menu에서 “Explore with AI agent”를 실행하면 백그라운드 에이전트가 해당 데이터를 탐색하고 보고서를 남기는 흐름도 있습니다.
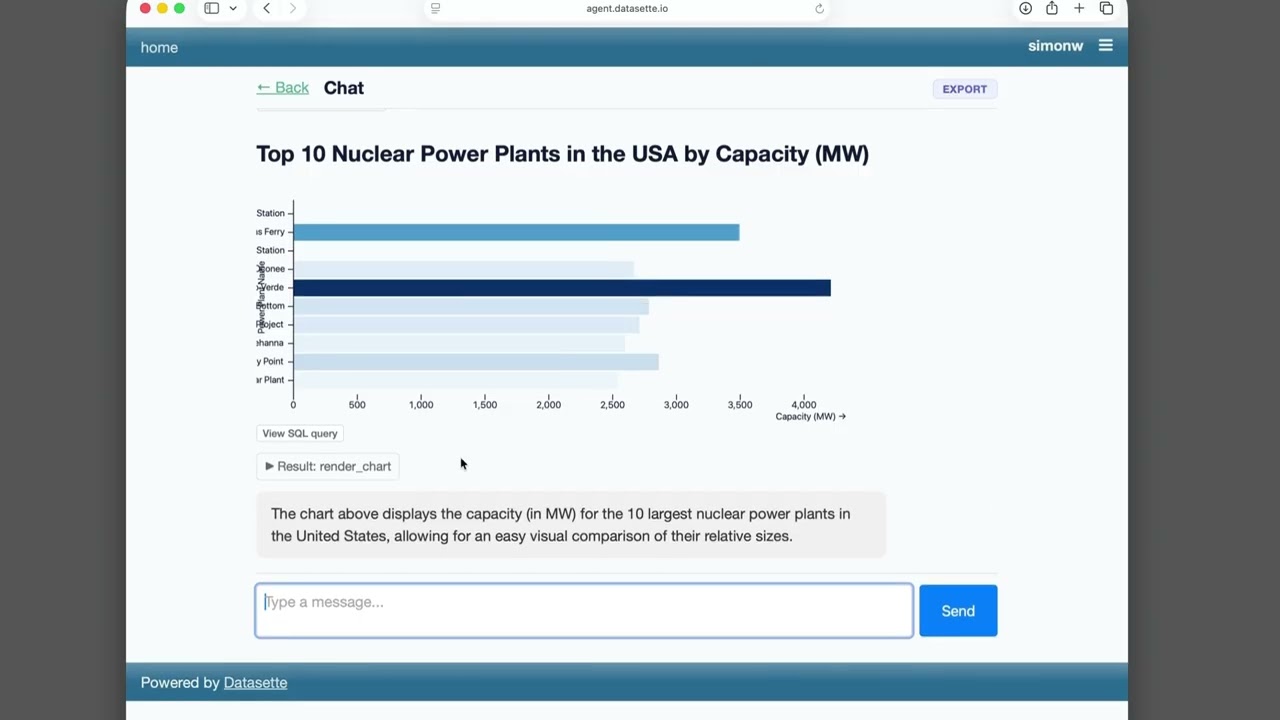
이 구조가 중요한 이유는 SQL을 완전히 숨기려 하지 않는다는 데 있습니다. 블로그 데모에서 사용자는 “Simon이 가장 최근에 펠리컨을 본 때가 언제인가”라고 묻습니다. 에이전트는 blog_beat 테이블에서 beat_type = 'sighting'이고 제목이나 설명에 pelican이 들어간 행을 최신순으로 찾는 SQL을 실행합니다. 답변은 자연어로 나오지만, 쿼리는 확인할 수 있습니다. 차트 플러그인도 “View SQL query” 버튼을 제공하도록 개선됐습니다. 이 작은 버튼이 데이터용 에이전트에서는 매우 큽니다. 답이 마음에 드는가보다 먼저, 어떤 데이터를 어떤 조건으로 읽었는지 검토할 수 있어야 하기 때문입니다.
범용 모델보다 도구 경계가 먼저입니다
Datasette Agent는 특정 모델에 묶이지 않습니다. 공식 발표는 OpenAI, Anthropic, Google Gemini 같은 frontier vendor부터 사용자가 직접 실행하는 open weight 모델까지 tool-calling 모델을 폭넓게 지원한다고 설명합니다. 블로그의 실행 예시는 gpt-5.5, Codex를 통한 openai-codex/gpt-5.5, LM Studio에서 제공하는 qwen3.5-9b를 보여줍니다. README의 설정 예시는 datasette-llm.default_model에 모델 이름을 넣는 방식입니다.
하지만 이 발표의 초점은 모델 선택보다 도구 경계입니다. README를 보면 Datasette Agent가 등록하는 권한은 세 개로 나뉩니다. datasette-agent는 대화형 assistant 사용 권한입니다. datasette-agent-explore는 데이터베이스와 테이블 탐색 메뉴 및 탐색 보고서 경로에 대한 권한입니다. datasette-agent-background는 채팅에서 백그라운드 에이전트를 생성하거나 확인하는 도구와 관련 API에 필요한 권한입니다. 루트 사용자는 모두 가질 수 있지만, 일반 actor는 일부만 가질 수 있습니다.
더 중요한 부분은 플러그인 도구 권한입니다. 다른 Datasette 플러그인은 register_agent_tools 훅으로 AgentTool을 등록할 수 있습니다. 이때 required_permission을 지정하면, Datasette Agent harness는 현재 actor가 그 권한을 갖고 있는지 확인한 뒤 도구 목록을 구성합니다. 권한이 없으면 모델에게 해당 도구가 아예 전달되지 않습니다. “호출했더니 permission denied를 반환한다”가 아니라, 모델이 처음부터 그 도구의 존재를 보지 못하게 하는 방식입니다.
이것은 에이전트 보안에서 꽤 실용적인 선택입니다. LLM에게 위험한 도구 설명을 보여준 뒤 “사용하지 마”라고 말하는 것보다, 사용자 권한에 맞춰 tool surface 자체를 줄이는 편이 안전합니다. 특히 Datasette처럼 데이터와 권한이 이미 핵심인 애플리케이션에서는 이 방식이 자연스럽습니다. 모델이 똑똑한가보다 먼저, 모델이 볼 수 있는 데이터와 누를 수 있는 버튼이 무엇인지 관리해야 합니다.
| 계층 | Datasette Agent의 선택 | 개발자가 확인할 점 |
|---|---|---|
| 모델 | datasette-llm을 통한 다중 provider와 로컬 모델 | 도구 호출 품질, 비용, 추론 지연 |
| 데이터 접근 | 테이블 설명과 읽기 전용 SQL 중심 | SQL 검토 가능성, row-level 권한, 민감 컬럼 처리 |
| 도구 확장 | register_agent_tools 훅과 AgentTool | 도구 설명, 입력 schema, side effect 범위 |
| 권한 | 권한 없는 도구는 모델에게 전달하지 않음 | actor별 tool 목록과 감사 로그 |
| 실행 | Fly Sprites sandbox 플러그인으로 명령 실행 확장 | sandbox 격리, 네트워크, 파일, 비용 제한 |
플러그인 생태계가 에이전트의 몸이 됩니다
Datasette는 원래 플러그인 생태계가 강한 도구입니다. Datasette Agent도 같은 길을 갑니다. 첫 공개 발표에서 함께 언급된 플러그인은 세 가지입니다. datasette-agent-charts는 SQL 결과를 Observable Plot 기반 차트로 렌더링합니다. datasette-agent-openai-imagegen은 ChatGPT Images 2.0을 써서 이미지를 생성합니다. datasette-agent-sprites는 Fly Sprites persistent sandbox에서 명령을 실행하는 도구를 제공합니다.
이 조합은 다소 이상해 보일 수 있습니다. SQLite 데이터 assistant가 왜 이미지 생성과 sandbox 실행을 가져야 할까요. 하지만 에이전트 제품 관점에서는 자연스럽습니다. 데이터 탐색은 단순히 SELECT 결과를 읽는 일에서 끝나지 않습니다. 결과를 시각화하고, 보고서로 정리하고, 작은 변환 코드를 실행하고, 필요하면 외부 산출물을 만들어야 합니다. 지금까지는 사용자가 SQL, Python, 차트 라이브러리, 호스팅 환경을 직접 오갔습니다. Datasette Agent는 그 일부를 대화형 도구 호출로 묶으려 합니다.
물론 여기서 위험도 같이 커집니다. 읽기 전용 SQL만 실행하는 에이전트와 sandbox 명령까지 실행하는 에이전트는 전혀 다른 보안 표면을 가집니다. 이미지 생성 도구는 비용과 콘텐츠 정책 문제를 만들 수 있습니다. 백그라운드 에이전트는 사용자가 대화창을 닫은 뒤에도 작업을 이어갈 수 있으므로 중지 버튼, 상태 확인, 권한 분리, 사용량 제한이 필요합니다. 그래서 Datasette Agent가 이미 권한을 세분화하고, 도구별 권한 gate를 README의 핵심 예시로 둔 점은 중요합니다.
에이전트 도구의 좋은 설계는 단순히 “많은 일을 할 수 있다”가 아닙니다. 어떤 actor에게 어떤 도구를 보여줄지, 그 도구가 어떤 입력 schema를 받는지, LLM에게 보이는 결과와 사용자에게 렌더링되는 HTML을 어떻게 분리할지, side effect가 있는 도구를 어디에서 막을지 정해야 합니다. Datasette Agent의 _html 처리도 이 맥락에서 볼 수 있습니다. 플러그인 도구는 채팅 UI에 rich HTML을 렌더링할 수 있지만, _로 시작하는 top-level key는 모델에게 다시 전달되는 결과에서 제거됩니다. 사용자에게 보여줄 UI와 모델 컨텍스트를 구분하려는 작은 장치입니다.
왜 SQLite인가
AI 에이전트와 데이터베이스를 말하면 보통 Snowflake, BigQuery, Databricks, Postgres, enterprise semantic layer 같은 큰 이름이 먼저 나옵니다. Datasette Agent가 SQLite를 택한 것은 작아 보입니다. 하지만 이 작은 선택은 에이전트 UX를 실험하기에 유리합니다.
SQLite 데이터셋은 파일입니다. 복사하기 쉽고, 로컬에서 돌리기 쉽고, 실패해도 blast radius가 상대적으로 작습니다. Datasette는 이미 공개 데이터셋을 웹으로 보여주고 링크 가능한 SQL 결과를 제공하는 도구입니다. 여기에 에이전트를 붙이면 “데이터베이스를 읽는 AI”의 핵심 문제가 잘 드러납니다. 스키마를 어떻게 설명할 것인가. 자연어 질문을 어떤 SQL로 바꿀 것인가. 사용자가 결과를 어떻게 검증할 것인가. 차트나 보고서가 쿼리 근거를 잃지 않게 하려면 무엇을 보여줘야 하는가.
대형 BI 도구도 같은 문제를 풀고 있습니다. 차이는 Datasette Agent가 훨씬 개발자 친화적이고 파일 친화적인 표면에서 시작한다는 점입니다. uvx --with datasette-agent datasette ...로 실행하고, datasette install datasette-agent로 설치하며, 플러그인 훅으로 도구를 추가합니다. 데이터 분석가와 개발자가 작은 데이터 앱을 만들 때 필요한 경량성이 남아 있습니다.
이 점은 최근 AI 개발 흐름과도 맞습니다. 모델이 강해질수록 모든 것을 거대한 SaaS 안에 넣는 방식만 남는 것은 아닙니다. 오히려 작고 명확한 도구가 더 좋은 에이전트 표면이 될 수 있습니다. SQLite는 범용 데이터 웨어하우스가 아니지만, 재현 가능한 데이터 파일과 로컬 실험에는 강합니다. Datasette는 엔터프라이즈 대시보드가 아니지만, 데이터를 빠르게 열고 공유하는 데 강합니다. Datasette Agent는 이 장점 위에서 “작은 에이전트가 어디까지 쓸모 있어질 수 있는가”를 묻습니다.
비용과 남용 방지도 제품의 일부입니다
공식 데모는 agent.datasette.io에서 직접 시도할 수 있지만 GitHub 로그인이 필요합니다. 발표는 남용 방지를 이유로 듭니다. 이 역시 사소한 운영 세부사항처럼 보이지만, AI 기능에서는 제품의 본질에 가깝습니다. LLM 호출은 비용이 들고, tool calling은 시스템 자원을 쓰며, sandbox 실행은 남용 가능성이 있습니다. 공개 데모 하나에도 인증과 제한이 필요합니다.
Datasette 생태계의 최근 플러그인 흐름은 이 문제를 정면으로 다룹니다. datasette-llm-limits는 주기별 사용량 제한을 설정하는 플러그인이고, datasette-llm-accountant는 LLM 토큰 사용량 회계를 다룹니다. Datasette Agent 자체가 이 모든 것을 완성했다는 뜻은 아닙니다. 다만 에이전트를 데이터 앱에 붙일 때 “모델이 답을 잘하나”와 같은 수준으로 “누가 얼마나 썼나”, “누가 어떤 도구를 호출할 수 있나”, “장시간 백그라운드 작업을 어떻게 멈추나”가 중요하다는 방향을 보여줍니다.
특히 데이터 탐색은 프롬프트 한 번으로 끝나지 않습니다. 사용자는 질문을 바꾸고, 정렬을 바꾸고, 그룹 기준을 바꾸고, 차트를 요청합니다. 에이전트는 여러 번 SQL을 실행할 수 있고, 결과가 길면 요약하거나 일부만 모델에 전달합니다. 이 과정에서 비용과 정확성은 서로 얽힙니다. 너무 많은 rows를 모델에 넘기면 비싸고 위험합니다. 너무 적게 넘기면 답이 틀릴 수 있습니다. SQL 결과는 사용자에게 보여주되 모델에는 요약만 전달하는 식의 설계가 필요합니다.
Datasette Agent가 알파 단계라는 점은 그래서 중요합니다. 지금 버전은 완성된 답이라기보다 실험 가능한 기반입니다. PyPI 확인 기준 datasette-agent는 0.1a4, datasette-agent-charts는 0.1a2, datasette-agent-sprites는 0.1a0입니다. GitHub 저장소도 아직 작습니다. 확인 시점 기준 datasette/datasette-agent는 48 stars, 3 forks 수준입니다. 숫자로 보면 작은 프로젝트지만, 이 작은 규모가 오히려 빠른 설계 실험을 가능하게 합니다.
커뮤니티 반응은 작지만 신호는 선명합니다
Hacker News에는 Show HN: Datasette Agent가 올라왔지만, 확인 시점 기준 5 points와 댓글 1개에 그쳤습니다. 댓글도 Simon Willison이 라이브 데모와 코드 링크를 안내하는 내용입니다. 이것만 보면 시장 반응이 뜨겁다고 말하기는 어렵습니다. 하지만 Datasette Agent는 대중형 AI 앱이 아니라, Datasette 사용자와 데이터 도구 개발자를 겨냥한 알파 플러그인입니다. HN의 작은 반응이 곧 의미가 작다는 뜻은 아닙니다.
오히려 볼 것은 발표의 방향입니다. 많은 AI 에이전트 제품은 “우리가 모든 업무를 대신한다”는 식으로 말합니다. Datasette Agent는 “이 데이터베이스 안에서, 이 도구 목록으로, 이 권한을 가진 actor가, 이 SQL을 실행했다”는 식의 더 좁은 언어를 씁니다. 개발자에게는 이쪽이 더 다루기 쉽습니다. 제품을 만들 때도 마찬가지입니다. 에이전트가 할 수 있는 일이 많을수록 데모는 화려하지만, 운영 중 설명 책임은 커집니다. 에이전트가 할 수 있는 일을 좁힐수록 UX는 덜 마법처럼 보일 수 있지만, 검증과 권한 관리는 쉬워집니다.
Datasette Agent의 경쟁 상대는 단순히 다른 Text-to-SQL 도구가 아닙니다. Hex, Observable, Streamlit 기반 데이터 앱, BI assistant, warehouse semantic layer, MCP 서버, LangChain과 LlamaIndex 기반 내부 데이터 agent가 모두 비슷한 영역을 건드립니다. 그러나 Datasette Agent의 차별점은 Datasette라는 기존 오픈소스 데이터 도구 안에서 작동한다는 점입니다. 데이터 게시, SQL 링크, 플러그인 훅, 권한 모델이 이미 있고, 에이전트는 그 위에 올라갑니다.
개발자가 가져갈 질문
Datasette Agent를 당장 도입하지 않더라도, AI 팀이 가져갈 질문은 명확합니다. 첫째, 우리 제품의 에이전트는 어떤 도메인에 충분히 좁혀져 있습니까. “모든 데이터를 분석한다”보다 “이 테이블과 이 도구로 이 보고서를 만든다”가 더 안전하고 유용할 때가 많습니다.
둘째, 도구 권한은 모델 호출 전 단계에서 줄어듭니까. 권한 없는 도구를 모델에게 보여주고 나중에 거부하는 방식은 prompt injection과 모델 착각의 표면을 키웁니다. Datasette Agent처럼 actor 권한에 따라 tool list를 구성하면 모델이 고민해야 할 공간 자체가 줄어듭니다.
셋째, 결과의 근거를 사용자에게 보여줍니까. 데이터 에이전트의 답변은 자연어로 끝나면 안 됩니다. 어떤 SQL이 실행됐는지, 어떤 rows가 쓰였는지, 차트가 어떤 쿼리에서 왔는지 확인할 수 있어야 합니다. “View SQL query” 버튼은 멋진 기능이라기보다 데이터 AI의 최소 조건입니다.
넷째, 확장 플러그인은 비용과 side effect를 별도로 다룹니까. 차트 렌더링은 읽기 작업에 가깝지만, 이미지 생성은 비용과 콘텐츠 정책을 만들고, sandbox 명령 실행은 보안 경계를 만듭니다. 같은 agent UI 안에 있어도 권한과 감사는 다르게 설계해야 합니다.
다섯째, 로컬과 클라우드 모델을 바꿀 수 있습니까. Datasette Agent는 datasette-llm을 통해 여러 모델을 연결합니다. 실제 팀에서는 데이터 민감도, 비용, latency, tool-calling 품질에 따라 모델을 바꿔야 합니다. 모델 선택이 코드와 정책에 너무 깊게 박히면 장기 운영이 어려워집니다.
좁은 에이전트가 더 오래 갑니다
Datasette Agent는 2026년 에이전트 시장의 가장 큰 발표는 아닐 것입니다. 대형 벤더의 keynote도 아니고, 수십억 사용자에게 바로 배포되는 기능도 아닙니다. 하지만 이 발표는 좋은 대조군입니다. 에이전트가 실용적인 소프트웨어가 되려면 꼭 더 넓어져야 하는 것은 아닙니다. 때로는 더 좁아져야 합니다.
SQLite 데이터셋을 탐색하는 일은 충분히 작습니다. 하지만 그 안에도 모델 선택, SQL 생성, 결과 검증, 차트 렌더링, 백그라운드 작업, sandbox 실행, 사용자 권한, 비용 제한, 남용 방지가 모두 들어갑니다. 범용 에이전트가 맞닥뜨리는 문제의 축소판입니다. Datasette Agent는 이 축소판을 오픈소스 플러그인 생태계 안에서 다뤄 보겠다는 실험입니다.
AI 개발자에게 이 실험이 주는 메시지는 단순합니다. 에이전트의 가치는 모델의 범용성만으로 결정되지 않습니다. 어떤 도구 안에 들어가느냐, 어떤 권한 모델을 따르느냐, 어떤 근거를 사용자에게 보여주느냐, 어떤 플러그인 경계로 확장되느냐가 더 중요해지고 있습니다. Datasette가 고른 길은 좁지만, 그 좁음 때문에 배울 것이 많습니다. 에이전트가 제품이 되려면 마법 같은 답변보다 먼저 좋은 도구 표면이 필요합니다.
출처: Datasette 공식 발표, Simon Willison 글, Datasette Agent GitHub, PyPI datasette-agent, HN Show HN 항목.