Command A+ 공개, 두 H100으로 여는 오픈 에이전트 모델
Cohere가 Apache 2.0 Command A+를 공개했습니다. 218B MoE, 25B active, 2 x H100 배포 조건과 에이전트 성능을 짚습니다.

- 무슨 일: Cohere가 2026년 5월 20일
Command A+를 Apache 2.0으로 공개했습니다.- 모델은 218B total, 25B active sparse MoE이며 text, image, reasoning, tool use를 한 모델에 묶습니다.
- 배포 조건: Cohere는 W4A4 quantization 기준 1 x B200 또는 2 x H100 실행을 제시했습니다.
- Hugging Face 모델 카드는 BF16, FP8, W4A4 quantization과 vLLM, SGLang, Transformers 예시를 함께 제공합니다.
- 실무 의미: 경쟁 지점은 챗봇 점수보다 private deployment, Korean tokenizer, tool-use eval, inference cost입니다.
- 주의점: 공식 벤치마크는 주로 이전 Command A 모델과 비교되며, 커뮤니티는 Qwen·Gemma 대비 검증을 요구합니다.
Cohere가 2026년 5월 20일 Command A+를 공개했습니다. 공식 발표에서 Command A+는 218B total parameters, 25B active parameters의 sparse Mixture-of-Experts 모델입니다. Cohere는 이 모델을 complex reasoning, multimodal document processing, multilingual RAG, tool use, agentic workflow를 한 번에 처리하는 enterprise workhorse로 설명했습니다.
이번 공개에서 눈에 띄는 숫자는 모델 크기보다 배포 조건입니다. Cohere는 Command A+가 W4A4 quantization 기준으로 1 x NVIDIA B200 또는 2 x NVIDIA H100에서 실행될 수 있다고 제시했습니다. Hugging Face 모델 카드에는 BF16, FP8, W4A4 변형이 따로 올라왔고, W4A4 카드에는 vLLM >=0.21.0과 Cohere의 cohere_melody>=0.9.0 설치 조건이 적혀 있습니다. API로만 쓰는 모델이 아니라, 기업이 직접 내려받아 private deployment로 운영할 수 있는 모델이라는 점을 전면에 둔 발표입니다.
Command A+는 Cohere의 기존 Command A 계열을 합치는 모델입니다. Cohere docs의 changelog는 Command A+를 "last model in the Command A family"라고 부르며, vision inputs, reasoning, translation, agentic tasks를 같은 모델에 결합했다고 설명합니다. 이전에는 Command A, Command A Reasoning, Command A Vision, Command A Translate처럼 기능별 모델이 나뉘어 있었습니다. Command A+는 이 분리를 줄이고, enterprise application이 모델 라우팅을 덜 복잡하게 만들 수 있다는 메시지를 냅니다.
Apache 2.0이 바꾼 배포 언어
Cohere가 이번 발표에서 반복한 단어는 sovereign AI입니다. 공식 블로그는 Command A+를 Apache 2.0 license로 자유롭게 사용할 수 있다고 설명하고, government와 regulated industry가 transparency, control, security, data sovereignty를 요구한다고 적었습니다. 같은 날 올라온 별도 발표문은 "sovereign critical infrastructure"라는 표현을 제목에 넣었습니다.
이 포지션은 OpenAI, Anthropic, Google의 hosted frontier API와 다른 시장을 겨냥합니다. 은행, 공공기관, 제조, 국방, 의료 조직은 모델 품질만으로 계약을 결정하지 않습니다. 데이터가 어느 region에 남는지, inference log가 외부 vendor에 저장되는지, fine-tuned derivative를 누가 소유하는지, 장애 시 fallback endpoint가 어디인지가 조달 문서에 들어갑니다. Apache 2.0 모델을 직접 배포할 수 있다는 점은 이런 팀에게 법무·보안 검토의 출발선을 바꿉니다.
Hugging Face의 W4A4 모델 카드는 라이선스를 apache-2.0으로 표시합니다. 같은 카드의 model summary는 Command A+가 25B active, 218B total parameters이며 agentic, multilingual, reasoning-heavy tasks에 최적화됐고 vision input도 지원한다고 적었습니다. BF16 카드도 같은 license와 model size를 제시합니다. 이 점은 Liquid AI LFM2.5처럼 open-weight지만 별도 상업 제한이 붙는 모델과 다른 차이를 만듭니다.
다만 Apache 2.0이 운영 비용을 없애지는 않습니다. BF16 quantization은 Hugging Face 카드 기준 4 x B200 또는 8 x H100이 필요합니다. FP8은 2 x B200 또는 4 x H100, W4A4는 1 x B200 또는 2 x H100입니다. 두 장의 H100으로 "실행 가능"하다는 말과, latency SLO·batch concurrency·observability·failover를 맞춘 production serving은 다른 문제입니다. Command A+는 license barrier를 낮추지만, GPU 운영 장벽은 그대로 남깁니다.
| Quantization | Blackwell 최소 예시 | Hopper 최소 예시 | 실무 해석 |
|---|---|---|---|
| BF16 | 4 x B200 | 8 x H100 | 품질 보존을 우선하는 고비용 배포 |
| FP8 | 2 x B200 | 4 x H100 | 메모리와 속도를 줄인 중간 선택지 |
| W4A4 | 1 x B200 | 2 x H100 | Cohere가 권장한 작은 하드웨어 footprint |
벤치마크는 에이전트 업무 쪽으로 읽어야 합니다
Command A+ 발표의 성능 표는 일반 챗봇 리더보드보다 enterprise agent workload에 가깝습니다. Cohere는 Command A Reasoning 대비 τ²-Bench Telecom 점수가 37%에서 85%로 올랐고, Terminal-Bench Hard는 3%에서 25%로 올랐다고 설명했습니다. IFBench는 36%에서 74%, AIME 25는 57%에서 90%, SciCode는 30%에서 38%로 제시됐습니다.
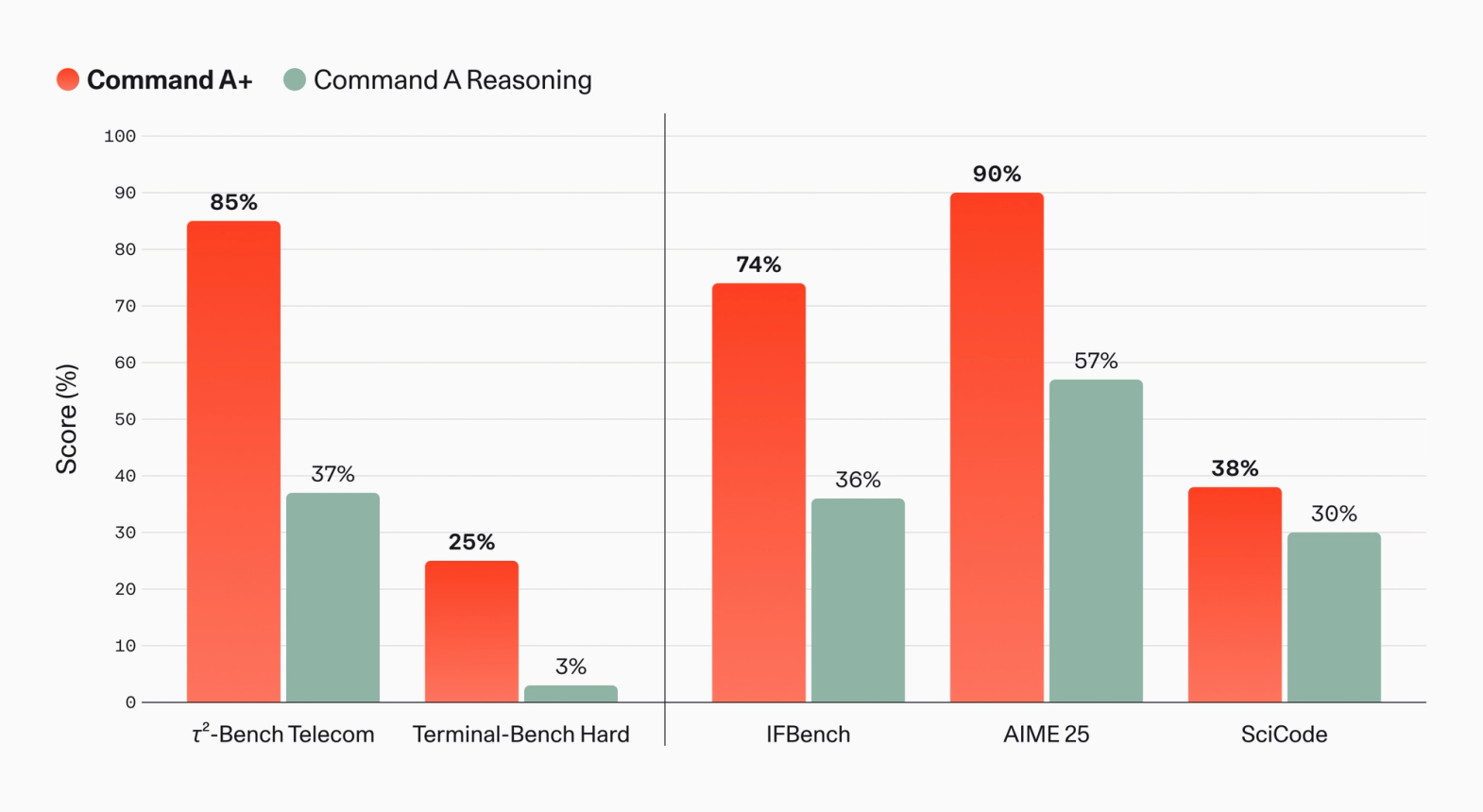
τ²-Bench Telecom은 telecom customer service 같은 다단계 업무를 측정하는 agentic benchmark입니다. Terminal-Bench Hard는 shell과 터미널 환경에서 모델이 작업을 수행하는 능력에 가깝습니다. 이 두 지표가 발표의 앞쪽에 배치된 것은 Command A+가 "질문 답변 모델"보다 "도구를 써서 업무를 끝내는 모델"로 팔리고 있다는 뜻입니다.
그럼에도 비교 대상을 조심해야 합니다. Cohere 공식 차트는 주로 Command A Reasoning과의 내부 계열 비교입니다. Reddit r/LocalLLaMA 토론에서는 직접 경쟁 모델과의 비교가 부족하다는 지적이 나왔습니다. 한 사용자는 Terminal-Bench Hard 25%를 언급하며 Qwen 계열의 별도 점수와 비교해야 한다고 적었습니다. 다른 사용자는 128K context가 현재 open model 경쟁에서 특별히 길지 않다고 봤습니다.
이 비판은 모델 공개의 의미를 줄이기보다, 검증 순서를 알려줍니다. Command A+를 도입하려는 팀은 먼저 Cohere의 이전 모델 대비 개선을 인정하되, Qwen, Gemma, Llama, DeepSeek, hosted frontier API와 같은 사내 업무셋에서 비교해야 합니다. 특히 agent workload는 benchmark 이름이 같아도 도구 스키마, permission model, retry policy, external API latency가 달라지면 결과가 크게 흔들립니다.
North에서 온 모델이라는 단서
Cohere는 Command A+가 지난 1년 동안 North를 고객에게 배포하며 얻은 경험에서 나왔다고 설명했습니다. North는 Cohere의 enterprise workspace이며, cloud file systems를 MCP로 연결하고, spreadsheet analysis와 memory를 다루는 agentic product입니다. 공식 블로그는 Command A+가 North 내부 application 평가에서도 개선됐다고 밝혔습니다.
수치도 구체적입니다. Cohere는 Agentic Question Answering accuracy가 Command A Reasoning 대비 20% 올랐고, spreadsheet analysis quality가 32% 올랐다고 적었습니다. Memory performance는 이전 세션의 stored data를 활용해 후속 질문에 답하는 능력을 측정하며, Command A Reasoning 39%에서 Command A+ 54%로 올랐다고 설명했습니다. 이 평가는 LLM-as-a-judge 방식입니다.
이 부분은 개발팀에게 더 직접적입니다. 에이전트 제품에서 실패는 대개 "답변이 어색하다"가 아니라 파일을 잘못 고르거나, 표 계산을 놓치거나, 이전 대화의 제약을 잊거나, tool call arguments를 틀리는 식으로 나타납니다. North 내부 평가는 이런 업무형 실패를 줄였다는 Cohere의 주장입니다. 다만 LLM-as-a-judge 수치이므로, 조직별 회계 문서, CRM export, Jira backlog, 한국어 보고서에서는 별도 eval이 필요합니다.
한국어 토큰 16% 개선의 실제 의미
Command A+는 48개 언어를 지원합니다. Cohere docs changelog에는 Korean, Japanese, Chinese, Arabic, Hindi, Vietnamese, Thai, Turkish, Ukrainian, Urdu가 포함됩니다. English와 주요 EU 언어도 목록에 들어갑니다.
Cohere는 tokenizer도 새로 도입했다고 설명했습니다. 공식 발표는 Command A+가 최신 tokenizer를 쓰며, 같은 응답을 생성하는 데 필요한 token 수가 줄었다고 말합니다. 언어별 수치로 Arabic 20%, Korean 16%, Japanese 18% tokenization efficiency improvement를 제시했습니다. 한국어를 쓰는 개발팀에게 이 숫자는 번역 품질 홍보보다 inference cost와 context packing 문제에 가깝습니다.
한국어 업무 문서는 조사, 띄어쓰기, 한자어, 영어 제품명, 사내 약어가 섞입니다. 고객지원 로그, 법무 문서, 회의록, 금융 보고서, 제품 요구사항 문서를 RAG나 agent memory에 넣으면 tokenizer 효율이 곧 context budget으로 바뀝니다. 16% 개선이 모든 업무 문서에서 그대로 재현된다는 보장은 없습니다. 그래도 같은 한국어 문단이 더 적은 token으로 들어간다면, retrieval chunk 수, tool result 요약, audit log 보존량, memory recall 비용이 줄어듭니다.
Command A+의 context length는 128K input, 64K max generation입니다. 이 숫자는 일부 장문 모델보다 짧습니다. 그래서 tokenizer 효율은 더 중요해집니다. 128K 안에 여러 tool descriptions, retrieved documents, previous decisions, user constraints를 넣어야 하는 agent product에서는 token 하나가 곧 latency와 GPU memory pressure입니다. 한국어 서비스가 Command A+를 검토한다면, 영어 benchmark보다 먼저 자체 한국어 corpus에서 token count와 answer quality를 같이 재야 합니다.
추론 속도 주장은 비용 모델로 이어집니다
Cohere는 Command A+가 Command A Reasoning의 111B dense architecture와 달리 218B total, 25B active MoE 구조를 쓴다고 설명합니다. 같은 quantization과 concurrency 조건에서 output tokens per second가 최대 63% 높고, time to first token이 최대 17% 낮다고 발표했습니다. W4A4 quantization은 추가로 47% speed increase와 13% latency reduction을 제공한다고 적었습니다.
Speculative decoding도 들어갔습니다. Cohere는 MoE 구조에 맞춘 speculative decoding으로 text와 multimodal input 모두에서 1.5-1.6x inference speedup을 얻었다고 주장했습니다. 이 주장은 agentic workflow에서 비용 의미가 큽니다. 에이전트는 한 번의 긴 답변보다 짧은 reasoning, tool call, tool result 읽기, 다음 tool call을 반복합니다. Time to first token과 small batch throughput이 나쁘면 사용자는 한 단계마다 멈춤을 느낍니다.
다만 속도 수치를 제품 비용으로 바꾸려면 조건을 다시 맞춰야 합니다. Cohere가 말한 TOPS는 첫 chunk 이후 generation 중 수신되는 tokens per second입니다. 실제 서비스 비용에는 image input preprocessing, tool execution time, vector search, permission check, network hop, logging, retry가 붙습니다. W4A4가 모델 latency를 줄여도, agent loop의 병목이 외부 SaaS API나 사내 DB라면 전체 체감 속도는 덜 바뀝니다.
Tool use와 reasoning 출력의 통합 문제
Hugging Face 모델 카드는 Command A+를 Image-Text-to-Text, Transformers, Safetensors, cohere2_vision, conversational, chat 태그와 함께 보여줍니다. 사용 예시에는 Transformers pipeline, vLLM server, SGLang server, Docker Model Runner가 포함됩니다. vLLM과 SGLang 예시는 OpenAI-compatible /v1/chat/completions 호출 형태를 사용합니다.
이 호환성은 개발자가 빠르게 붙이기 좋습니다. 기존 OpenAI-compatible client를 쓰는 서비스는 endpoint와 model id를 바꾸는 방식으로 실험할 수 있습니다. 이미지 입력도 예시에 들어가 있어, 문서 캡처, 표, 슬라이드, 제품 UI를 읽는 enterprise workflow에 바로 연결됩니다. 모델 카드의 예시는 <|START_THINKING|>와 <|END_THINKING|> 사이에 thinking이 생성되는 형태도 보여줍니다.
제품 통합에서는 이 thinking 출력이 별도 설계 대상입니다. 내부 reasoning을 사용자에게 그대로 노출할지, 저장하지 않을지, eval log에만 남길지, PII scrubber를 통과시킬지 결정해야 합니다. Tool call과 final answer, reasoning trace, audit event를 같은 로그 테이블에 넣으면 보안 검토에서 문제가 됩니다. Command A+가 reasoning과 tool use를 한 모델에 묶을수록, application layer는 출력 channel과 retention policy를 더 엄격히 나눠야 합니다.
커뮤니티의 반응은 "좋다"보다 "검증하자"에 가깝습니다
r/LocalLLaMA의 Hugging Face 모델 카드 토론은 공개 자체에는 긍정적이지만, 성능에는 유보적입니다. 한 댓글은 "large and sparse MoE로 전환하는 일은 쉽지 않다"며 open-weight 모델이 늘어나는 점을 좋게 봤습니다. 다른 댓글은 "이전 license와 달리 드디어 open"이라는 점을 평가했습니다. multilingual 모델로서 218B A25B 크기가 흥미롭다는 반응도 있었습니다.
반대편에서는 128K context, 경쟁 모델 대비 benchmark, 직접 비교 부족을 지적했습니다. "Cohere 블로그에서 competitor model과의 direct bench가 보이지 않는다"는 댓글이 있었고, Terminal-Bench Hard 25%를 Qwen 계열과 비교하는 댓글도 나왔습니다. 이 반응은 Command A+가 무의미하다는 뜻이 아닙니다. open model 사용자층은 이미 "공식 발표 점수"보다 "내 GPU에서 어느 quantization이 얼마나 빠르고, tool call이 얼마나 안정적인가"를 묻는 단계에 있습니다.
개발팀 입장에서는 이 유보가 건강합니다. Command A+는 private deployment가 가능한 Apache 2.0 모델이라는 강한 장점이 있습니다. 동시에 218B MoE라는 크기는 운영 실험 비용을 요구합니다. 제품에 넣기 전에는 세 가지를 따로 재야 합니다. 첫째, W4A4와 FP8에서 업무 품질 차이가 정말 무시 가능한지. 둘째, 한국어 문서와 이미지가 섞인 workflow에서 hallucination과 citation 품질이 어떤지. 셋째, tool call schema가 많아질수록 argument omission과 unsafe action이 얼마나 늘어나는지입니다.
왜 이 발표가 AI 인프라 뉴스인가
Command A+는 모델 release이지만, 기사로 다룰 핵심은 인프라입니다. Open-source license, quantization, vLLM/SGLang support, private deployment, tokenizer efficiency, speculative decoding이 모두 배포 의사결정의 항목입니다. 모델 이름이 아니라 "어디서, 어떤 GPU로, 어떤 데이터 경계 안에서, 얼마의 latency로 돌릴 수 있는가"가 발표의 중심입니다.
이 질문은 에이전트 제품에서 더 날카롭습니다. 고객지원 agent가 CRM과 결제 시스템을 읽는다면, 법무팀은 hosted API보다 private endpoint를 선호할 수 있습니다. 개발 agent가 내부 repository와 ticket을 열어본다면, 보안팀은 code snippet과 secret scan 결과가 외부 로그로 나가는지 묻습니다. 공공기관 RAG agent가 민감 문서를 읽는다면, 지역·계약·감사 요건이 모델 선택을 제한합니다. Command A+는 이런 팀에게 "frontier API를 쓰지 않는 대안"을 추가합니다.
하지만 이 대안은 자동 해답이 아닙니다. 직접 배포는 patching, model weight provenance, GPU quota, serving runtime CVE, prompt log retention, abuse monitoring, eval regression을 모두 가져옵니다. Cohere의 Model Vault 같은 managed private deployment는 이 부담을 줄이는 선택지입니다. 완전 self-hosting과 managed private inference 사이에서 어떤 책임을 가져갈지 정해야 합니다.
개발팀이 지금 확인할 체크리스트
첫 번째는 license와 procurement입니다. Apache 2.0이라도 기업 내부 정책은 open-source model weight 사용을 별도로 다룰 수 있습니다. 모델 weight의 출처, training data disclosure 수준, acceptable use policy, export control, 고객 데이터 처리 방식이 조달 문서에 들어갑니다. Cohere의 공식 발표와 Hugging Face 카드, Apache 2.0 문서를 함께 법무 검토에 넘겨야 합니다.
두 번째는 serving runtime입니다. W4A4는 vLLM >=0.21.0과 cohere_melody>=0.9.0 조건이 붙습니다. 기존 inference stack이 older vLLM, TensorRT-LLM, Ollama, llama.cpp 중심이라면 지원 상태를 확인해야 합니다. 모델이 실행된다는 사실과 production rollout이 가능한 observability, autoscaling, graceful shutdown, request cancellation이 갖춰졌다는 사실은 다릅니다.
세 번째는 eval입니다. Command A+의 공식 benchmark에는 agentic QA, spreadsheet analysis, memory, Terminal-Bench Hard, τ²-Bench Telecom이 들어갑니다. 사내 eval도 이 축을 따라 쪼개는 편이 낫습니다. RAG answer accuracy, spreadsheet calculation, Korean document summarization, image-table extraction을 따로 봐야 합니다. Function calling argument accuracy, unsafe tool refusal, memory recall도 별도 항목으로 측정해야 합니다.
네 번째는 hybrid routing입니다. 모든 요청을 Command A+로 보내기보다, private data가 들어가는 workflow와 generic internet knowledge workflow를 나누는 설계가 현실적입니다. 사내 문서, 고객 로그, 금융·의료 문서처럼 데이터 경계가 강한 요청은 private Command A+ endpoint로 보내고, public coding question이나 낮은 위험의 아이디어 생성은 hosted frontier API와 비교할 수 있습니다. 모델 라우터는 품질뿐 아니라 데이터 분류와 비용을 같이 봐야 합니다.
결론: 오픈 모델 경쟁은 이제 GPU와 권한의 문제입니다
Command A+ 공개는 "Cohere가 또 모델을 냈다"로 끝내기 어렵습니다. Apache 2.0, 218B total/25B active MoE, W4A4 기준 2 x H100, 48개 언어, Korean tokenizer 16% 개선, tool-use benchmark 개선이 한 묶음으로 나왔습니다. Cohere가 노리는 시장은 개인 챗봇보다 private deployment가 필요한 enterprise agent입니다.
동시에 채택 판단은 신중해야 합니다. 공식 벤치마크는 주로 이전 Command A 모델과 비교됩니다. 커뮤니티는 Qwen, Gemma, DeepSeek 같은 경쟁 모델 대비 직접 검증을 요구합니다. W4A4가 하드웨어 footprint를 낮춰도, 두 장의 H100은 여전히 작은 팀에게 큰 비용입니다. Thinking output과 tool call log는 제품 보안 설계의 일부가 됩니다.
AI 개발팀에게 이번 발표가 던지는 질문은 명확합니다. 모델 품질만 볼 것인가, 아니면 license, GPU, tokenizer, tool reliability, private deployment까지 포함해 볼 것인가. Command A+는 후자의 질문을 전면에 올린 모델입니다. 에이전트가 내부 도구와 문서를 더 깊게 만질수록, 모델 경쟁은 leaderboard보다 배포 위치와 권한 경계에서 결정됩니다.