Command A+ 공개, 2개 H100으로 돌리는 오픈웨이트 MoE
Cohere Command A+는 Apache 2.0, 218B MoE, 25B active, 128K context, 2개 H100 배포를 앞세운 기업용 오픈웨이트 모델입니다.

- 무슨 일: Cohere가 Command A+를 Apache 2.0 open-weights로 공개했습니다.
- 2026년 5월 20일 발표 기준
218Btotal parameters,25Bactive parameters,128Kcontext를 내세웁니다.
- 2026년 5월 20일 발표 기준
- 배포 계산: Cohere는 1개 B200 또는 2개 H100에서 운영 가능하다고 설명합니다.
- Hugging Face에는
command-a-plus-05-2026-w4a4가 올라왔고, 자체 VPC와 on-premises 배포도 전면에 둡니다.
- Hugging Face에는
- 개발자 영향: agentic QA, data analysis, memory quality, multilingual, tool use를 기업 워크로드 기준으로 묶었습니다.
- 주의점: 성능 그래프는 Cohere 자체 벤치마크입니다. 실제 비용과 latency는 serving stack과 workload로 다시 재야 합니다.
2026년 5월 20일 Cohere가 Command A+를 공개했습니다. 발표문에서 Cohere는 이 모델을 "가장 빠르고 강력한 언어 모델"로 설명합니다. 개발자가 먼저 볼 대목은 그 문구가 아니라 배포 수치입니다. Command A+는 2,180억 total parameters를 가진 mixture-of-experts 모델이고, 요청마다 250억 active parameters를 사용합니다. context length는 128K입니다. Hugging Face에 공개된 model card의 라이선스는 Apache 2.0입니다.
이 글에서 다룰 사건은 "또 하나의 오픈 모델 공개"가 아닙니다. Cohere는 Command A+를 Cohere API, Amazon SageMaker, Azure AI Foundry, Oracle Cloud Infrastructure, Hugging Face에 올렸습니다. private VPC와 on-premises deployment도 같은 배포 선택지에 포함했습니다. 같은 발표에서 Cohere는 Command A+가 1개 NVIDIA B200 또는 2개 NVIDIA H100에서 실행될 수 있다고 적었습니다. 이 숫자는 open-weight LLM 경쟁에서 모델 점수만큼 중요한 구매 단위입니다.
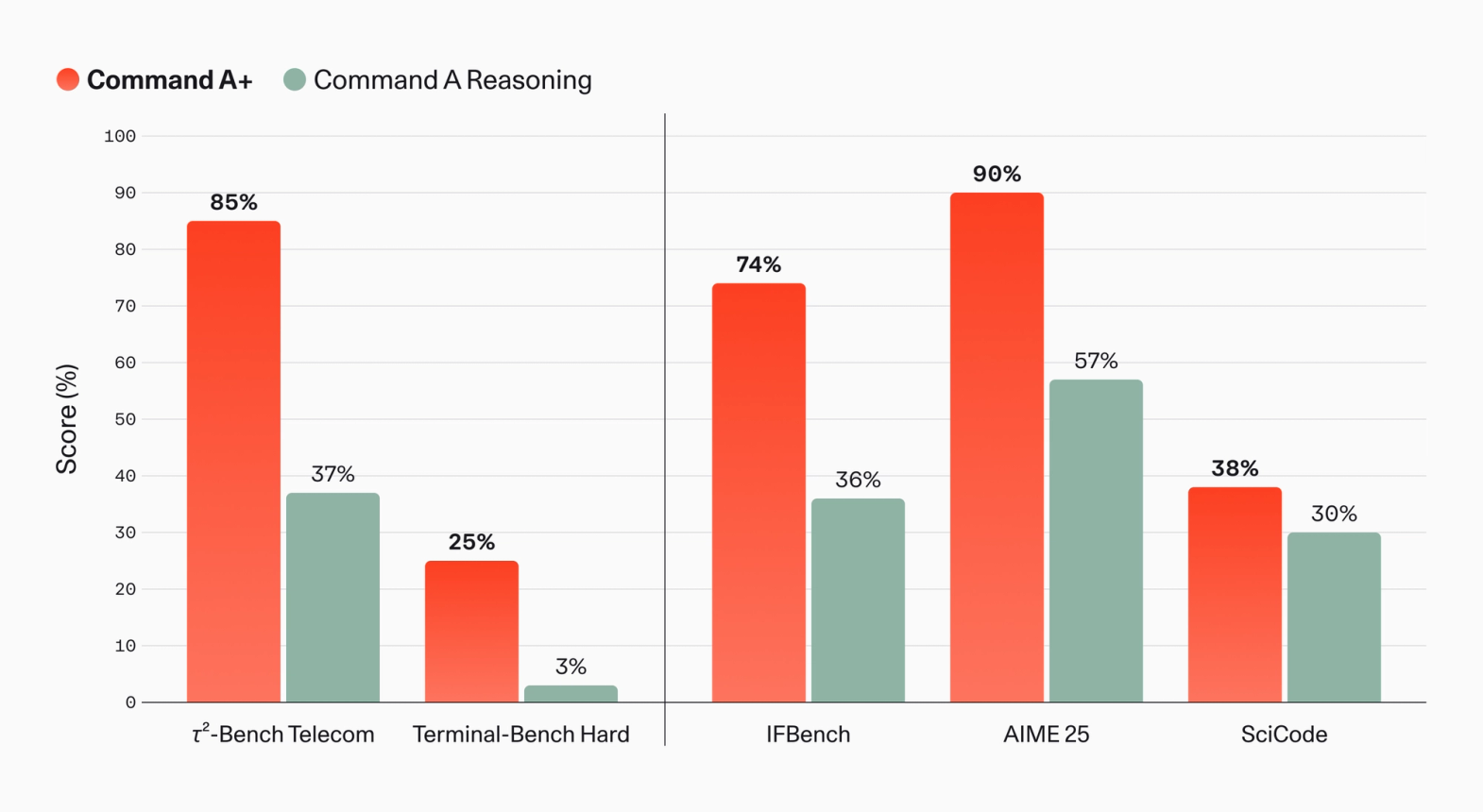
Command A+가 겨냥하는 사용자는 consumer chatbot보다 enterprise agent builder에 가깝습니다. Cohere는 발표문에서 tool use, agents, data analysis, memory usage quality, coding, vision, translation을 한 묶음으로 제시했습니다. 특히 agentic question answering, data analysis, memory usage quality 그래프를 별도로 공개했습니다. 자체 그래프에서 Command A+는 Command A Reasoning보다 agentic QA 65% 대 45%, data analysis 45% 대 13%로 앞섭니다. memory usage quality도 54% 대 39%로 높은 점수를 받았습니다.
이 비교는 독립 벤치마크가 아니므로 순위표처럼 읽으면 안 됩니다. 그래도 Cohere가 어떤 구매 질문을 의식하는지는 드러납니다. enterprise agent를 운영하는 팀은 "모델이 reasoning을 잘하는가"만 묻지 않습니다. 내부 문서에서 답을 찾아야 하는지, tool call 이후 memory가 유지되는지, data analysis task 산출물이 일관되는지 함께 봅니다. latency budget 안에 들어오는지, 사내 GPU나 VPC 안에서 돌아가는지도 같은 체크리스트에 들어갑니다. Command A+ 발표 자료는 이 질문을 모델 아키텍처와 serving footprint로 묶어 답하려 합니다.
Command A+의 MoE 구조는 그 답의 중심입니다. 2,180억 total parameters는 headline으로 크지만, 요청마다 쓰는 active parameters는 250억입니다. dense model처럼 모든 parameter를 매번 통과하지 않도록 expert를 나누는 방식입니다. Cohere가 함께 강조한 1개 B200 또는 2개 H100 배포 가능성은 여기에서 나옵니다. 기업 입장에서는 "모델이 몇 B인가"보다 "우리 inference cluster에서 몇 장의 GPU로 SLA를 맞출 수 있는가"가 실제 예산 항목입니다.
Hugging Face에 올라온 이름도 이 방향을 뒷받침합니다. 공개된 model id는 CohereLabs/command-a-plus-05-2026-w4a4입니다. W4A4는 weights와 activations를 4-bit로 다루는 quantization 설정을 가리키는 이름입니다. Cohere가 model card와 blog에서 open-weights, Apache 2.0, on-premises, private deployment를 동시에 적은 이유는 단순한 연구 공개보다 운영 선택지를 강조하려는 쪽에 가깝습니다.
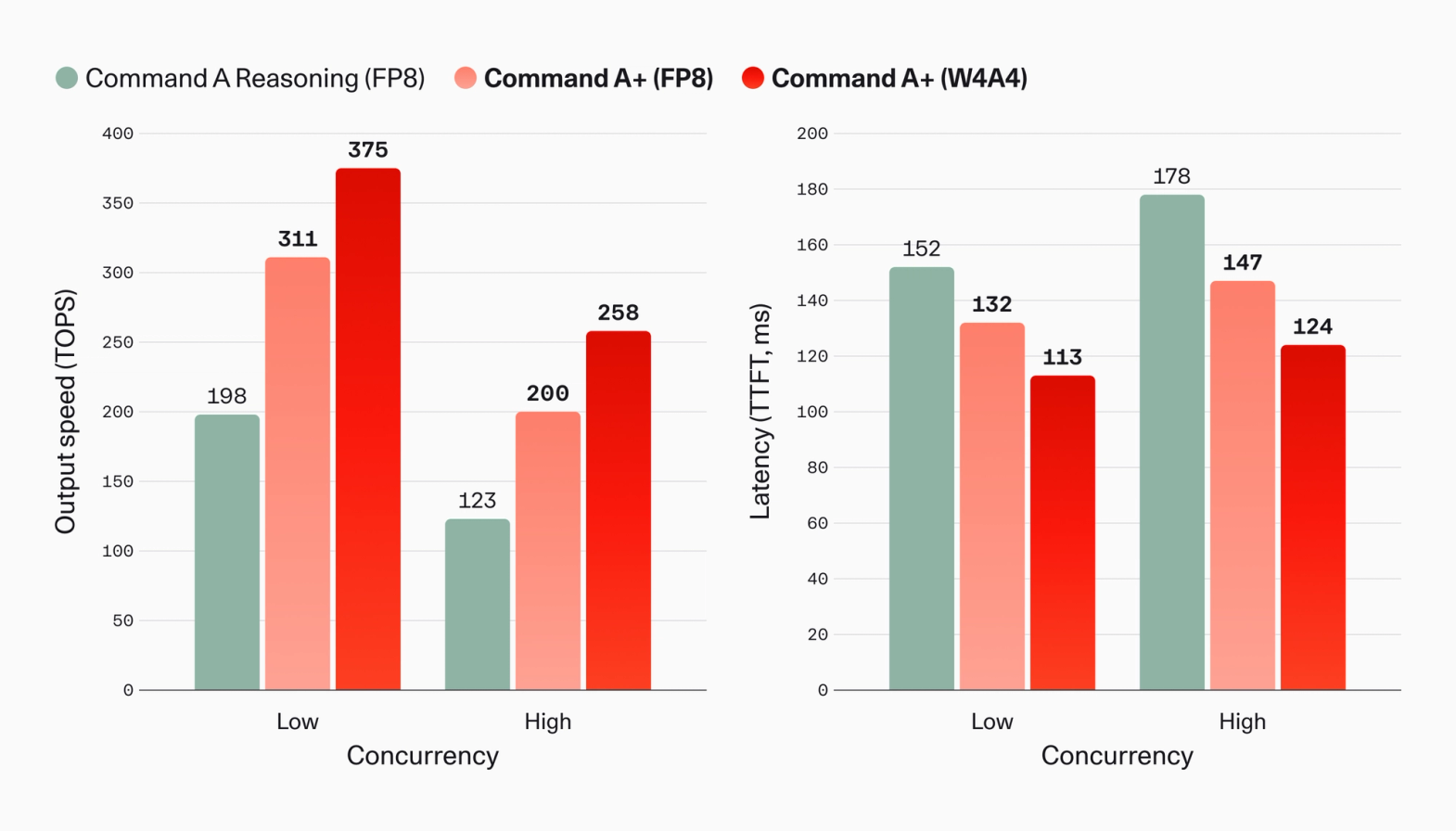
Serving claim은 두 번째 그래프에서 더 구체적입니다. Cohere의 speed and latency chart는 Command A Reasoning FP8, Command A+ FP8, Command A+ W4A4를 나란히 놓습니다. low concurrency output speed에서 Command A Reasoning FP8은 198 TOPS, Command A+ FP8은 311 TOPS, Command A+ W4A4는 375 TOPS로 표시됩니다. high concurrency에서는 각각 123, 200, 258 TOPS입니다. TTFT latency도 low concurrency 152ms, 132ms, 113ms, high concurrency 178ms, 147ms, 124ms 순으로 제시됩니다.
이 그래프는 Command A+를 "더 큰 모델"이 아니라 "더 빨리 서빙할 수 있는 기업 모델"로 포지셔닝합니다. 공개 모델을 검토하는 팀은 보통 weight 다운로드 여부 다음에 serving stack을 봅니다. vLLM, TensorRT-LLM, SGLang, TGI, cloud managed endpoint 중 무엇을 쓸지 먼저 정해야 합니다. FP8과 W4A4 중 어떤 quantization을 허용할지, tool call traffic이 burst로 들어올 때 TTFT가 얼마나 밀릴지도 확인해야 합니다. Cohere는 발표문에서 이 계산을 모델 소개의 앞쪽으로 끌어올렸습니다.
Command A+의 또 다른 축은 언어입니다. Cohere는 이 모델이 48개 언어를 지원한다고 설명합니다. 영어 중심 coding benchmark만 앞세운 release가 아니라 MT-AIME 2025와 WMT24++ chart를 포함했습니다. 공개 그래프에서 Command A+는 MT-AIME 2025에서 86%, Command A Reasoning은 53%로 표시됩니다. WMT24++에서는 Command A+ 81%, Command A Reasoning 73%입니다. 다국어 문서, 고객 지원, 계약서, 내부 정책 검색을 다루는 회사라면 이 항목이 coding 점수보다 먼저 들어올 수 있습니다.
다만 48개 언어 지원이 곧 한국어 production 품질을 보장하지는 않습니다. model card와 발표문은 한국어 단독 벤치마크를 자세히 풀어놓지 않았습니다. 한국어 RAG, 법무 문서 요약, 고객상담 routing, 내부 위키 agent를 붙이려면 자체 eval set을 만들어야 합니다. 특히 tool use가 섞인 workflow에서는 언어 능력과 function argument 생성 정확도가 따로 움직일 수 있습니다. "한국어 답변이 자연스럽다"와 "한국어 요청에서 올바른 tool schema를 채운다"는 별도 지표입니다.
Vision도 발표에 포함됐습니다. Cohere는 Command A+를 multimodal model로 설명하고 MMMU, MathVista, CharXiv reasoning, CharXiv descriptive chart를 공개했습니다. 그래프상 Command A+는 Command A Vision보다 MMMU 75% 대 65%, MathVista 81% 대 74%, CharXiv reasoning 53% 대 47%, CharXiv descriptive 88% 대 82%로 앞섭니다. 기업 agent에서 vision은 문서 이미지, 스크린샷, 표, 제품 카탈로그, invoice workflow와 연결됩니다. 이 항목은 단순 이미지 caption보다 back-office automation에서 더 큰 비용 차이를 만들 수 있습니다.
개발 도구 관점에서는 tool use와 memory quality가 더 직접적입니다. Cohere가 공개한 agentic benchmark chart에는 "Memory Usage Quality"가 들어갑니다. agent를 production에 넣는 팀은 모델 응답의 문장 품질보다 실행 상태 관리에서 더 많이 실패합니다. 이전 tool result를 잘못 참조하거나, retrieval 문서와 user instruction을 섞으면 사람이 검토해야 할 diff가 늘어납니다. 오래된 context를 authoritative하게 취급하는 경우도 같은 문제를 만듭니다. Cohere가 memory quality를 별도 축으로 제시한 점은 enterprise agent buyer가 실제로 묻는 질문과 맞닿아 있습니다.
이 발표는 API 사업자와 open-weight 배포 사이의 경계를 다시 건드립니다. OpenAI, Anthropic, Google은 강한 managed API와 product surface를 앞세웁니다. Meta, Mistral, Qwen, DeepSeek, MiniMax 같은 진영은 open-weight 배포와 self-hosting 선택지를 넓힙니다. Cohere는 두 축을 한꺼번에 잡으려 합니다. API와 partner cloud에서 바로 쓰게 하면서도, private VPC와 on-premises에서 돌릴 수 있는 모델을 제공합니다. regulated industry 고객에게 이 조합은 procurement에서 의미가 있습니다.
최근 open-weight release와 비교하면 Command A+의 차이는 context length가 아닙니다. MiniMax M3는 1M context와 coding agent benchmark를 강하게 내세웠습니다. Command A+는 128K context입니다. 대신 Cohere는 2개 H100, W4A4, 48개 언어, enterprise deployment channel을 전면에 둡니다. 긴 context로 repository 전체를 넣는 시나리오보다 내부 문서 검색과 tool 호출이 섞인 traffic에 가깝습니다. 다국어 agent traffic을 일정 latency로 처리하는 쪽에 더 맞춘 발표입니다.
Apache 2.0 라이선스도 실무 검토 항목입니다. Hugging Face model card의 license field가 Apache 2.0이므로, 연구용 공개보다 상업적 활용 장벽이 낮습니다. 그래도 기업 배포에서는 license field만 보고 끝낼 수 없습니다. model card, acceptable use policy, weights provenance, dataset disclosure, export control, cloud marketplace terms를 함께 확인해야 합니다. 특히 사내 VPC 또는 on-premises 배포를 검토한다면 보안 심사 문서가 더 필요합니다. weight storage, access logging, artifact signing, model update process가 그 문서의 체크 항목입니다.
커뮤니티 반응은 아직 얕습니다. Hacker News와 GeekNews에서 "Command A+" 단독 토론은 기사 작성 시점에 눈에 띄게 형성되지 않았습니다. Hugging Face model page는 공개되어 있지만, 이 글에서는 다운로드 수나 좋아요 수를 영향력 지표로 쓰지 않았습니다. 초기 open-weight release는 benchmark image가 먼저 돌고, 실제 평가는 며칠 뒤 정리됩니다. serving recipe, quantization issue, tool-call regression report, cost comparison이 그 뒤에 쌓입니다. Command A+도 그 순서를 밟을 가능성이 높습니다.
개발자가 지금 확인할 수 있는 실험은 세 가지입니다. 첫째, Cohere API나 partner cloud endpoint로 실제 agent trace를 돌려 response quality와 tool schema accuracy를 봅니다. 둘째, Hugging Face의 W4A4 weights를 내부 serving stack에서 올릴 수 있는지 확인합니다. 셋째, 같은 prompt와 retrieval corpus를 Claude, Gemini, GPT, Qwen, Mistral, 기존 Cohere model에 걸어 비교합니다. latency, cost, refusal, hallucination, function call error를 따로 기록해야 합니다. 발표문 숫자는 출발점이고, production 선택은 이 trace에서 갈립니다.
팀이 agent product를 운영한다면 Command A+를 "더 좋은 모델인지"보다 "권한과 비용을 어디로 옮기는 모델인지"로 봐야 합니다. managed API는 운영 부담을 줄이는 대신 데이터 경로와 모델 업데이트를 provider에게 맡깁니다. open-weight self-hosting은 데이터 경로와 배포 주기를 더 많이 통제하지만, serving engineer와 GPU budget이 필요합니다. Cohere가 제시한 1개 B200 또는 2개 H100 수치는 이 tradeoff를 회의실 언어로 바꿉니다. 모델 card 하나가 아니라 GPU 구매, cloud reserved instance, 보안 심사, eval harness의 안건이 됩니다.
Command A+ 발표에서 가장 구체적인 신호는 benchmark 순위가 아니라 packaging입니다. Apache 2.0 open-weights, W4A4 model card, 128K context, 48 languages, agentic benchmark를 한 번에 묶었습니다. 1개 B200 또는 2개 H100 claim, cloud와 on-premises channel도 같은 묶음 안에 있습니다. AI agent를 내부 업무로 밀어 넣는 기업에게 이 묶음은 한 가지 선택지를 다시 열어줍니다. "API만 호출할 것인가, 우리 경계 안에서 모델을 운영할 것인가"라는 선택입니다. 다음 검증은 Cohere 그래프가 아니라 각 팀의 trace, latency budget, GPU invoice에서 나와야 합니다.