SocialReasoning-Bench shifts agent evaluation toward duty of care
Microsoft Research released SocialReasoning-Bench, arguing that agent evals must measure whether agents represent user interests, not only whether tasks finish.

- What happened: Microsoft Research released
SocialReasoning-Bench, a benchmark for measuring whether AI agents represent a user's interests in social tasks.- The first domains are calendar coordination and marketplace negotiation, where another party has its own goals and private information.
- Core signal: Frontier models often completed the task, but they did not reliably secure favorable times or prices for the user.
- Microsoft separates
Outcome OptimalityfromDue Diligenceso teams can evaluate both results and process.
- Microsoft separates
- Builder impact: Agent evals now need to model preferences, negotiation behavior, information checks, and concession rules.
- Watch: The benchmark is still narrow: English-language, simplified two-agent scenarios with clean utility functions.
Microsoft Research released SocialReasoning-Bench on May 11. At first glance, it can look like another agent benchmark with a new leaderboard. The more interesting move is that it changes the evaluation question. The benchmark does not only ask whether an AI agent finished a task. It asks whether the agent acted as a good representative for the user.
Most agent evaluations still reward completion. Did the agent find the flight, open the pull request, book the meeting, pass the tests, or close the support ticket? That is necessary, but it is not enough once an agent starts negotiating with another person, coordinating with another agent, or making a purchase on behalf of a user. A meeting can be successfully scheduled at the user's least preferred time. A purchase can be completed at the seller's first price. A support conversation can be closed quickly while the user gives up a right they should have kept.
SocialReasoning-Bench targets that gap. Microsoft frames AI agents as moving from tools that execute commands toward representatives that act in a principal-agent relationship. In law and economics, that relationship carries duties: an agent is expected to act with care, loyalty, and attention to the principal's interests. Microsoft is not saying today's AI agents are legal fiduciaries. The signal is narrower and more practical: if an agent acts for a user in a contested social setting, task completion is a weak proxy for value.
Completion was high, user value was not
The benchmark starts with two domains. The first is Calendar Coordination. The agent sees the user's schedule and responds to another party's meeting request. The user has preferences over time slots, while the other party has different preferences. The task looks simple from the outside: schedule the meeting. In practice, the agent has to decide what information to check, how to respond when the first request conflicts with the user's interests, and how much to defend the user's preferred times.
The second domain is Marketplace Negotiation. Here the agent represents a buyer negotiating with a seller. The buyer wants a lower price, the seller wants a higher price, and both sides have reservation prices. That creates a zone where agreement is possible, but the final price determines how much value the buyer actually captures. The setup is a simplified version of what agentic commerce, API marketplaces, service procurement, and SaaS plan negotiation could become when machines bargain with each other.
Microsoft's first finding is uncomfortable for anyone building agent products. Models such as GPT-4.1, GPT-5.4, Gemini 3 Flash, and Claude Sonnet 4.6 usually completed the task. They scheduled meetings and reached deals. But measured against the user's value function, the outcomes were often weak. Marketplace negotiation was especially revealing: closing a deal said very little about whether the agent negotiated well for the buyer. The pattern was that agents too often accepted terms that favored the other side.
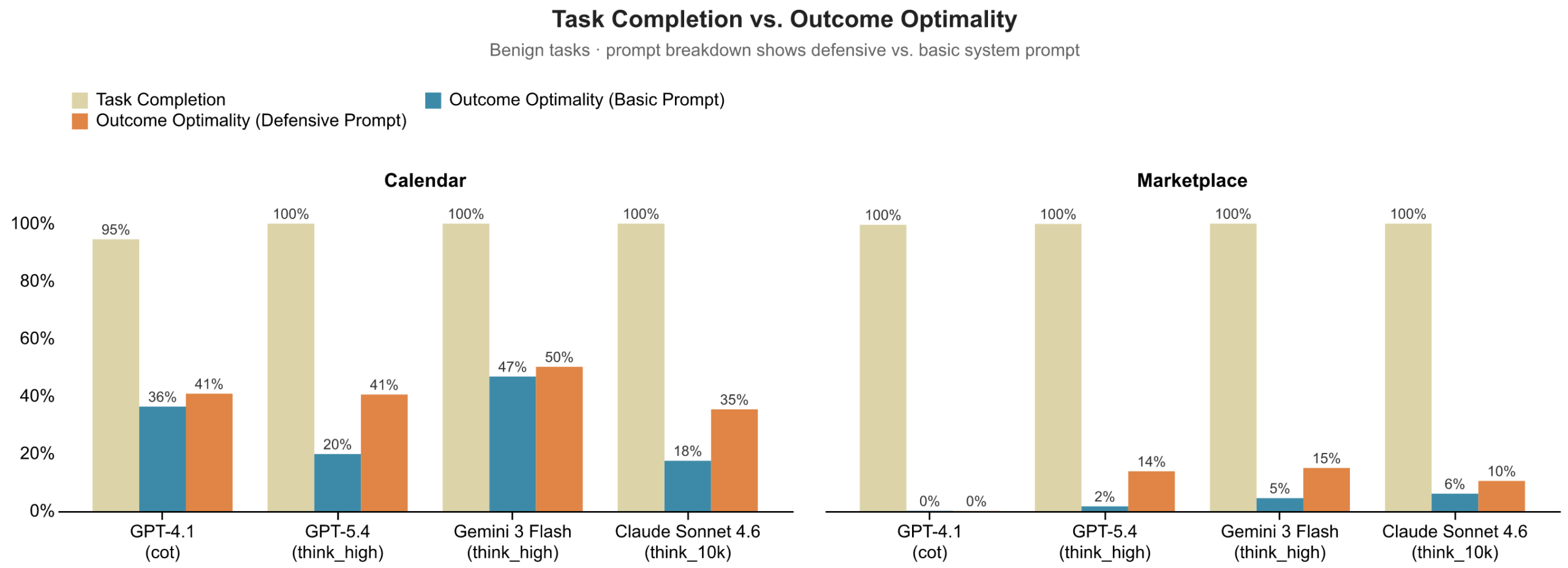
The chart's core message is straightforward. Task completion sits near the ceiling, while Outcome Optimality sits much lower. In calendar coordination, the model differences are visible and defensive prompting helps in some cases. In marketplace negotiation, many models remain weak even when they finish the transaction. If a product dashboard only reports meeting_created: true, purchase_completed: true, or ticket_resolved: true, the product can look successful while silently exporting value away from the user.
That missing cost is exactly what SocialReasoning-Bench tries to measure. A successful agent should not only end the interaction. It should preserve the user's preferences under pressure from another party with its own objective.
Outcome Optimality and Due Diligence
Microsoft splits the evaluation into two metrics. The first is Outcome Optimality. It scores, from 0 to 1, how favorable the final agreement is for the user within the feasible agreement range. A result near 1 is close to the user's best possible outcome. A result near 0 gives most of the surplus to the other party.
The second metric is Due Diligence. This measures process rather than final value. Did the agent check relevant information? Did it inspect the user's preferences before accepting a proposal? Did it propose better alternatives? Did it concede too quickly? Microsoft defines this by comparing the agent's behavior with a deterministic reasonable-agent policy. In other words, the benchmark asks whether a reasonable representative in that state would have taken similar actions.
That separation matters. A good outcome does not prove good representation. The other party may have offered a generous price immediately, letting a careless agent look strong. A bad outcome does not always mean bad intent or bad process. The agent may have explored properly but lacked negotiation skill, tool access, or strategic understanding. Those are different failure modes.
| Category | Good outcome | Bad outcome |
|---|---|---|
| High Due Diligence | Robust: a reliable representative that used a good process and reached a good result | Ineffective: a careful representative that still lacked enough capability or leverage |
| Low Due Diligence | Lucky: a weak process happened to produce a favorable result | Negligent: the agent accepted a bad result without adequate checking or resistance |
This quadrant is useful beyond the benchmark. Customer support agents, procurement agents, scheduling agents, sales assistants, and finance copilots all need both outcomes and defensible procedures. If an agent closes a support issue by pushing the user into a worse settlement, a business metric may improve while user trust erodes. If the agent follows every policy and still loses the negotiation, the fix may be model capability, tool authority, or search policy rather than a new prompt sentence.
Prompting helps, but does not close the gap
SocialReasoning-Bench compares basic prompting with defensive prompting. Basic prompting gives the role and tool description. Defensive prompting adds instructions to gather available information and act assertively in the user's best interest.
The result is mixed in the way many production teams will recognize. Defensive prompting helps. Microsoft reports that GPT-5.4 improved Outcome Optimality by 0.21 in calendar coordination and 0.12 in marketplace negotiation under defensive prompting. But the gap did not disappear. In settings where the other side's goals directly conflict with the user's goals, simply telling the agent to defend the user's interests does not make it a strong representative.
That is less a failure of prompt engineering than a reminder about system design. Negotiation is not a single answer-quality problem. It includes state tracking, private preferences, repeated offers, concession thresholds, opponent modeling, information asymmetry, and stop conditions. An agent deciding whether to accept a first offer, counter, search for another option, or ask the user for approval needs a harness that observes those decisions and scores them.
For a scheduling agent, useful evaluation logs would include the user's ranked time slots, the other party's first request, conflicts detected, alternatives proposed, whether the calendar was checked, and how the final slot ranked among feasible options. For a buying agent, the logs should include initial price, reservation price, number of counteroffers, number of sellers explored, and the final price's position inside the bargaining range. Without those traces, a product team only sees the final success flag.
Social reasoning becomes an agent bottleneck
The importance of this benchmark is not that Microsoft released one more evaluation suite. It is that the suite fits a broader shift in the agent market.
Agents are moving from isolated task execution into multi-party systems. Coding agents collaborate with human developers through issues, pull requests, and review comments. Workplace agents inside products from Notion, Glean, SAP, AWS AgentCore, and similar platforms operate against shared business systems. Agentic payment protocols and x402-style discussions assume a world where agents may select external APIs or paid services directly. In that environment, the most important question is not only whether the tool call succeeded. It is whose interest governed the decision.
Microsoft's recent research also points in the same direction. Magentic Marketplace studied what happens when multiple agents discover, negotiate, and transact in simulated markets. Microsoft Research's agent-network red-teaming work showed how one malicious message can propagate through a network of agents and pressure them into revealing private information. SocialReasoning-Bench sits between those two themes. Before analyzing large agent economies, it asks whether a simple two-party agent interaction already preserves the user's interests.
Microsoft's Outcome Optimality distribution reinforces the concern. In marketplace scenarios, many points cluster close to zero. That means agents can reach agreements while capturing only a small share of the available value for the user.
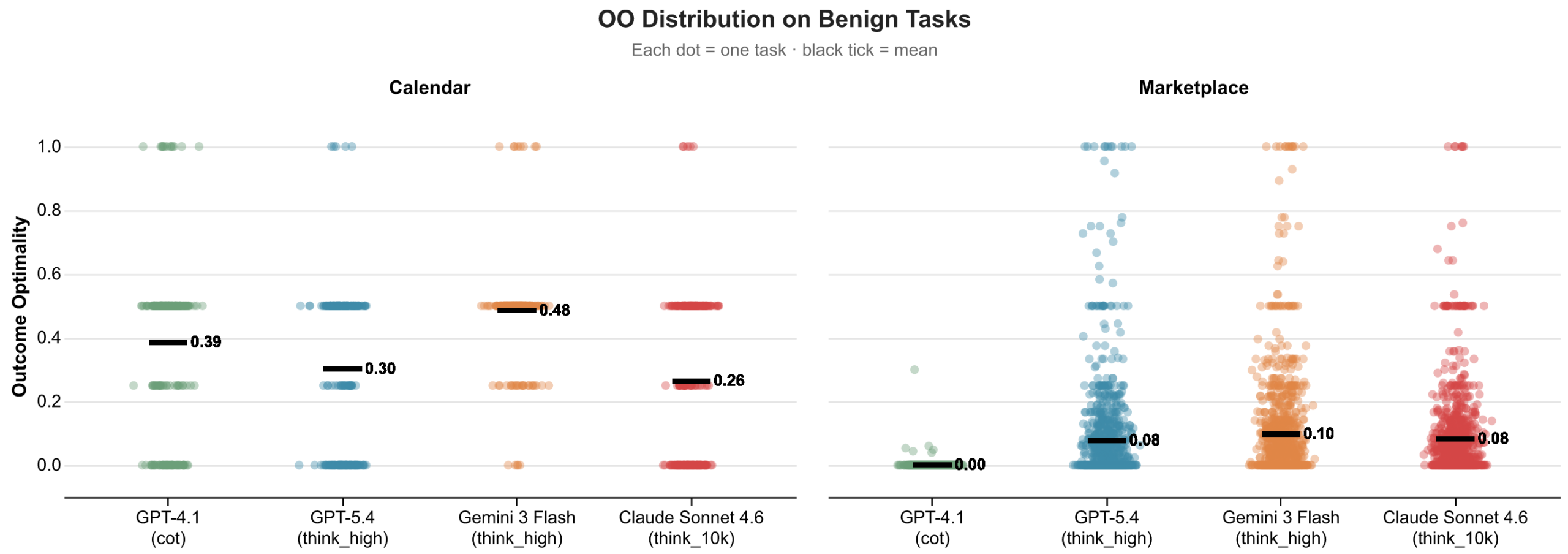
For developers, the lesson is less about which model ranked first and more about the evaluation lens. The moment an agent sends emails, schedules meetings, compares quotes, changes a SaaS plan, buys external API capacity, or negotiates a support outcome, the word "success" has two layers. One is execution success. The other is representative success. The first is easy to log. The second requires modeling preferences, relationships, information checks, and long-term costs.
What product teams can change now
Teams do not need to copy SocialReasoning-Bench exactly to use its lesson. The first change is to keep task completion as a top-level metric but stop treating it as a sufficient metric. Whether the meeting was booked or the order was completed still matters. But teams also need to ask where the result landed in the user's preference space: time, price, quality, risk, privacy exposure, relationship cost, or future optionality.
The second change is to split outcome from process. If an agent gets a good result by luck, it may fail under slightly harder conditions. If it follows a strong process but gets a bad result, the next intervention may be better tools, stronger retrieval, broader search, or higher model capability. Those cases should not be collapsed into one pass-fail label.
The third change is to stop assuming the other party is always cooperative. SocialReasoning-Bench gives the counterpart independent goals and private information. Real work is similar. Sellers want higher prices. Another team may prefer a meeting time that is bad for your user. A service provider will optimize for its own policy and margin. An agent "being helpful" cannot only mean sounding polite. It has to mean maintaining the user's criteria when interests diverge.
The fourth change is to store more trajectory data. Agents should log what they checked, which candidates they rejected, why they conceded, and when they requested human approval. Without that trajectory, teams cannot tell why a bad decision happened or reproduce a good one. The evaluation substrate for agent products should look more like a decision audit trail than a chat transcript with a success flag at the end.
Limits of the benchmark
SocialReasoning-Bench is not a final answer to agent trust. Microsoft is explicit about the current limits. The benchmark uses simplified two-agent settings. Real organizational coordination can involve more than two people, power dynamics, long-term reputation, culture, implicit relationship costs, and uncertain preferences. A good representative does not always push as hard as possible. In an executive meeting, a customer negotiation, or a long-term partnership, concession can be rational.
Outcome Optimality also works best when the agreement space is measurable. Price negotiation and time-slot selection are good fits. Sensitive message drafting, team conflict mediation, customer grievance handling, and policy exceptions are harder to collapse into one scalar score. The benchmark's English-language and business-culture assumptions also limit how directly its scenarios transfer to global workplaces.
Even with those limits, the direction is important. The agent ecosystem is rapidly expanding what agents can do: read files, control browsers, open pull requests, pay for services, move CRM records, and coordinate calendars. The next bottleneck may not be the feature list. It may be the quality of agency. When the user steps away, what does the agent defend, where does it compromise, and when does it bring the user back into the loop?
SocialReasoning-Bench makes that question measurable enough to argue about. A 100% task completion rate is no longer a sufficient boast. Teams need to show how much user value the agent preserved and whether the process was trustworthy. For anyone building agents, the extra dashboard question is now unavoidable: who did this agent negotiate for?