SANA-WM 2.6B asks what a one-minute world model really costs
NVIDIA SANA-WM claims 720p, 60-second world modeling from a 2.6B backbone. The real story is not video polish but the cost structure of open models.

- What happened: NVIDIA Research published the
SANA-WMpaper and project page.- The claim is that a 2.6B-parameter model can generate 720p, 60-second video from one image and a 6-DoF camera trajectory.
- Key numbers: Roughly 213K public videos, 64 H100s for 15 days, and 34-second denoising on an RTX 5090 distilled variant.
- Why it matters: Unlike closed AI video services, SANA-WM points toward open infrastructure that researchers can modify, inspect, and benchmark.
- The important question is whether long-horizon consistency can become cheap enough for robotics, simulation, synthetic data, and agent evaluation loops.
- Watch: Read
open-sourcecarefully here. Code, model weights, the refiner, and reproducible evaluation are separate claims.
NVIDIA Research and researchers connected to MIT Han Lab posted SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer to arXiv on May 14, 2026. The project framing is simple: SANA-WM takes a starting image and a camera path, then generates a controllable 720p video up to one minute long. The headline number is 2.6B parameters. That may sound small next to frontier language models, but the comparison is different when the output is a minute of spatially and temporally consistent video.
The interesting part is not just "AI can make longer clips." SANA-WM is presented as a world model, not as a consumer text-to-video product. Instead of asking a prompt to produce a plausible scene, the system starts from a frame and asks whether the same scene can remain coherent as the camera moves through it. The core question shifts from "what should the clip show?" to "does this generated world keep being the same world?"
That distinction matters for AI builders. In a short advertising clip or social video, visual appeal over a few seconds may be enough. In robotics, games, simulation, synthetic data, and embodied AI, the harder question is whether the door remains in the same place when the camera turns back, whether rain continues in a consistent direction, and whether objects that leave the frame still belong to the same underlying scene when they return. SANA-WM is interesting because it pushes open video research toward that standard.
What SANA-WM actually claims
The paper describes SANA-WM as a 2.6B-parameter open-source world model. Its main inputs are a single first-frame image and a metric 6-DoF camera trajectory. Six degrees of freedom means the camera path includes three axes of translation and three axes of rotation. Compared with ordinary prompt-driven video generation, this is narrower control, but it also creates a stricter evaluation target. Generating a plausible forest from a text prompt is one task. Preserving the structure of that forest while a virtual camera follows a real trajectory is another.
The system design has four important pieces. First is Hybrid Linear Attention, which combines frame-wise Gated DeltaNet blocks with periodic softmax attention to handle long contexts without paying the full memory cost of dense attention everywhere. Second is Dual-Branch Camera Control, which uses a coarse global pose branch and a fine pixel-aligned geometric branch to follow the camera path more accurately. Third is a two-stage generation pipeline: a 2.6B long-rollout backbone produces the long video, then a 17B long-video refiner improves texture and later-frame quality. Fourth is a robust annotation pipeline that extracts metric-scale 6-DoF camera poses from public videos and uses those poses as training labels.
The numbers are aggressive. The paper says SANA-WM was trained on about 213K public video clips with camera-pose supervision and completed training in 15 days on 64 H100 GPUs. The authors say a 60-second 720p clip can be generated on a single GPU, while a distilled variant can denoise a 60-second 720p clip in 34 seconds on an RTX 5090 with NVFP4 quantization. They also report stronger action-following accuracy than existing open-source baselines on a one-minute world-model benchmark, while reaching similar visual quality at 36x higher throughput.
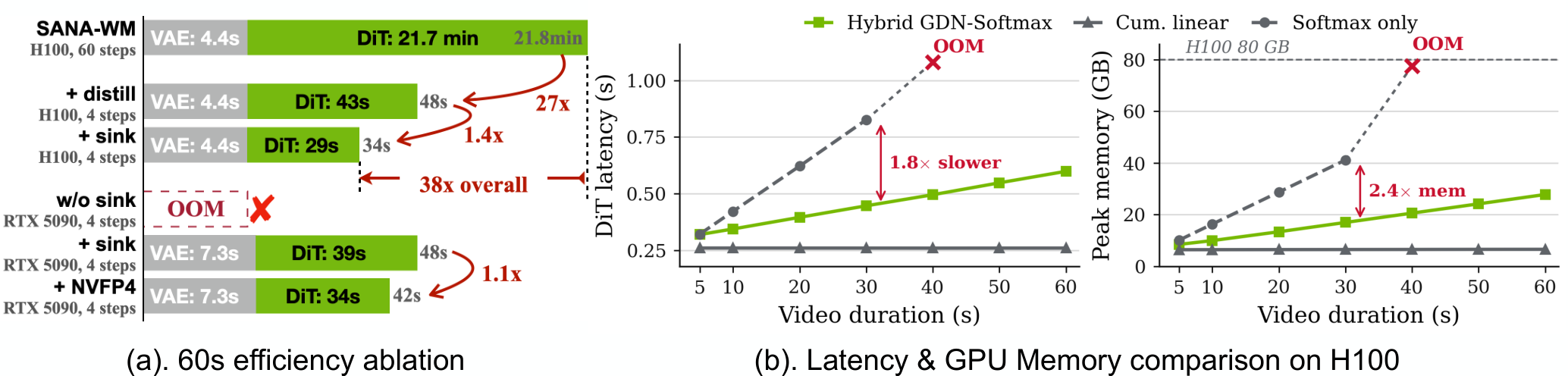
This chart matters because SANA-WM's claim is about cost as much as quality. Closed AI video systems mostly compete through polished samples and product packaging. SANA-WM puts another question in the foreground: can researchers repeatedly experiment with this length and resolution at a cost they can bear? If world models are going to be useful for robotics or simulation, one beautiful sample is less important than thousands of generations and evaluations. That makes latency, memory, training compute, and reproducibility part of the news.
Why call it a world model?
"World model" is now an overloaded term. In reinforcement learning and robotics, a world model traditionally predicts the next state from a current state and an action, letting a system simulate outcomes before acting in the real environment. In recent video generation, the term is often used more narrowly: a model earns the label when it can keep an on-screen world coherent while responding to camera movement or user control.
SANA-WM is closer to the second meaning. It is not evidence, by itself, that the model contains a hidden physics engine or a causal simulator. The output is still video. What makes it different from a short clip generator is that it is trained to preserve scene structure over a one-minute horizon under camera control. That is a meaningful step, but it is also a reason to avoid overreading the term.
The community reaction reflected that split. Some Hacker News commenters saw the result as promising for robotics planning. Others were skeptical that a "video world model" is the right foundation for real planning stacks. There was also a game-development objection: a good game world is not just a stable visual space. It contains intentional objects, authored constraints, and meaningful choices. A generative world can be coherent without being designed.
That criticism is useful. A model can keep a corridor continuous without making that corridor interesting. It can preserve a building across camera motion without making the space meaningful for a player or a robot. Still, SANA-WM gives builders a practical technical reference point. It makes the long-video labeling problem explicit, uses hybrid linear attention rather than full attention to reach a one-minute horizon, and accepts a camera trajectory rather than text alone. Those are ingredients future browser agents, robot-learning systems, digital twins, and game-prototyping tools can share.
What is different in the open-model race
The biggest differentiator is the word "open." Sora, Veo, Runway, Kling, and similar systems are mostly experienced through products or APIs. Users can create outputs, but they cannot fully inspect the training pipeline, architecture, weights, benchmark setup, or failure modes. The SANA repository, by contrast, is a public Apache-2.0 codebase, and its README places SANA, SANA-1.5, SANA-Sprint, SANA-Video, SANA-WM, and Sol-RL into one efficiency-oriented generative-model family.
That does not mean every part of the SANA-WM stack was immediately open in the strongest possible sense. At the time of the Korean source article, the project page's Models button was still marked as coming soon. Hacker News discussion also showed skepticism about whether usable weights were actually available. That distinction matters. Open code, announced model weights, demo videos, and reproducible checkpoints are not the same thing.
There is another important qualifier. SANA-WM's best demos are not simply "a 2.6B model did everything." The official page states that the displayed videos use a bidirectional variant of SANA-WM followed by a second-stage long-video refiner. The paper and feature cards also describe a dedicated 17B long-video refiner. If someone compresses the story to "2.6B generates all this quality alone," they are losing a key part of the pipeline.
The first frame also matters. The project page says gallery first-frame images were generated with OpenAI GPT Image 2 and Google Nano Banana Pro, while SANA-WM animates those images into one-minute videos. That is not necessarily a weakness. It clarifies the system boundary. SANA-WM is not claiming to replace the entire image-to-video creative pipeline from scratch. It is positioned as the model that rolls out a world over time once a strong starting image and camera path exist.
That boundary changes how teams should evaluate it. If you want an end-user product where a text prompt becomes a finished commercial video, SANA-WM is a lower-level research tool. If you are building robotics, simulation, or evaluation systems, that lower level may be exactly the interesting layer. Starting state, camera or action trajectory, refiner, and benchmark loop can be separated and studied.
Efficiency is not only speed
SANA-WM's efficiency story has three layers. The first is data efficiency. The paper reports about 213K public video clips, which is small compared with the tens of millions of video hours often discussed around large physical-AI and world-foundation-model efforts. Smaller is not automatically better. The real question is whether the annotation pipeline and pose supervision extract enough signal for long-horizon learning.
The second layer is training efficiency. Sixty-four H100s for 15 days is not a casual academic budget. But compared with the industrial training costs behind large video foundation models, it moves the discussion closer to something research labs and company research teams can reason about. For AI infrastructure, the gradient of cost matters as much as the absolute number. If memory and time explode whenever the video gets longer, the research loop collapses. SANA-WM is trying to flatten that curve with hybrid linear attention.
The third layer is inference efficiency. The single-GPU generation claim connects directly to whether world models can become repeatable components inside products or research loops. A robot that imagines several candidate actions needs to compare outcomes quickly. A game team exploring camera paths cannot wait impractically long for every rollout. That is why the 34-second denoising figure on an RTX 5090 gets attention. It suggests a task unit that might be repeated, not just a demo that can be admired once.
Those numbers still need independent confirmation. They are claims from the paper and project page, not yet a broad third-party benchmark. Reproducibility will depend on how quickly weights, code, evaluation scripts, and exact refiner conditions become usable outside the authors' environment. Open-model trust is earned through reruns, not through launch copy.
A different path after Sora
Closed AI video services are usually packaged as creative tools. Their center of gravity is prompt UX, style control, shot generation, editing, safety filters, copyright posture, and distribution. SANA-WM points more directly at robotics and embodied AI, which is a very NVIDIA direction. NVIDIA sells the compute layer, but it is also pushing physical-AI platforms such as Cosmos. A world model is not just a video-app feature. It can become infrastructure for learning and testing behavior in simulated worlds.
That means SANA-WM is not necessarily trying to beat closed video products at their own game. A good consumer video product needs user experience, licensing, editing workflows, and publishing channels. A good world-model research base needs camera control, long-term consistency, repeatable evaluation, lower inference cost, and access to code and weights. SANA-WM is more meaningful in the second category.
For developers, that creates different choices. If the goal is a polished marketing clip today, closed services may still be easier. If the goal is to predict visual changes while an agent manipulates a browser or desktop, imagine a robot's view under a candidate motion, or explore fast synthetic environments outside a full game engine, the ability to decompose the model and pipeline matters more than end-user polish.
The limitations are real. The first frame may come from another model. A 17B refiner changes the total system cost. Visually plausible video may still fall short of the causal model required for planning. The phrase "world model" can pull expectations ahead of the evidence. Those caveats do not erase the technical signal, but they do define how carefully it should be read.
A checklist for reading the announcement
The first split is openness. The NVlabs/Sana repository is public and lists an Apache-2.0 license. But code availability, SANA-WM weights, documentation, and reproducible benchmark scripts are separate boxes to check. Since the project page still showed model availability as forthcoming at the time of the Korean article, that status should remain part of the story.
The second split is pipeline composition. The 2.6B long-rollout backbone, bidirectional variant, 17B refiner, and NVFP4 distilled path should not be collapsed into one number. The 2.6B figure is important because it suggests a compact backbone for long-horizon rollout. It does not mean every displayed sample came from that component alone.
The third split is use case. If SANA-WM is judged as a generic video generator, it may disappoint. If it is judged as a camera-controlled long-video model, its meaning becomes clearer. Maintaining a scene for 60 seconds while following a trajectory requires a different benchmark from a short text-to-video clip. That is why the paper talks about action-following accuracy and throughput alongside visual quality.
The fourth split is data. The annotation pipeline for extracting metric 6-DoF pose from public videos may be the quiet center of the work. Video-model quality is not only a function of model size. It depends on what behavior labels are extracted, how accurately they describe camera motion, and whether those labels transfer to useful control. If that pipeline becomes public and verifiable, SANA-WM's value extends beyond a single checkpoint.
The current takeaway
SANA-WM is not a simple "open source beats Sora" story. That framing would flatten the more useful signal. The better read is that open video research is moving from short-clip quality demos toward one-minute controllable worlds and the cost structure required to evaluate them. A 2.6B number looks small in isolation, but it carries different weight when attached to 720p, 60 seconds, and camera control.
At the same time, SANA-WM should be read with brackets around it: model-weight availability, the 17B refiner, first frames from external image models, and benchmark numbers before broad independent reproduction. Open models do not become credible because a project page says so. They become credible when researchers outside the original team can rerun, break, modify, and compare them.
Still, the direction is clear. AI video is no longer only a video-app problem. It is becoming part of the infrastructure for agents, robots, synthetic environments, simulation, and long-horizon evaluation. SANA-WM is a signal that this infrastructure may be built outside closed APIs as well. The real cost it exposes is not only GPU time. It is the verification standard we are willing to demand when someone calls a generated video system a world model.