Qoder 1.0 moves the AI IDE fight onto the developer desktop
Qoder 1.0 reframes AI coding from IDE assistance to a task runtime with Quest, team knowledge, reviewable artifacts, and parallel work.

- What happened: Qoder released
Qoder 1.0on May 16, 2026, and repositioned the product from an AI IDE to an Autonomous Development Desktop.- The new Quest window brings task management, status tracking, artifact review, and knowledge invocation into one workspace.
- Why it matters: AI coding competition is shifting from autocomplete and chat quality toward task runtimes, team knowledge, and verifiable chains of work.
- Watch: Qoder's 11%, 40%, and 33% improvement claims are internal metrics. Teams still need to validate reproducibility, permission boundaries, and cost in their own workflows.
Qoder has announced Qoder 1.0. The language is intentionally large. Qoder no longer describes itself as only an AI IDE. It now calls the product an "Autonomous Development Desktop." The release says the new version is designed for AI-powered Experts to execute code generation, verification, and delivery autonomously, and that it is available on Windows, macOS, and Linux.
If this is read as just another AI coding tool launch, it is easy to miss the signal. The interesting part is the product vocabulary. The AI coding market is no longer fighting only over autocomplete latency, chat answers, or a model picker. The center of gravity is moving toward what happens after a developer gives the agent a real requirement: how the agent plans the work, which team knowledge it invokes, where verification happens, and what artifacts humans can review before trusting the result.
GitHub Copilot App, OpenAI Codex, Claude Code, Cursor background agents, and Replit parallel agents have all been moving in this direction. Qoder 1.0 is notable because it packages the shift not as a feature inside an editor, but as a larger "development desktop." An IDE is primarily the place where files are edited and code is written. A development desktop implies something broader: requirements, task status, team knowledge, verification results, artifact review, and parallel progress across several projects. That is the expansion Qoder wants this release to signal.
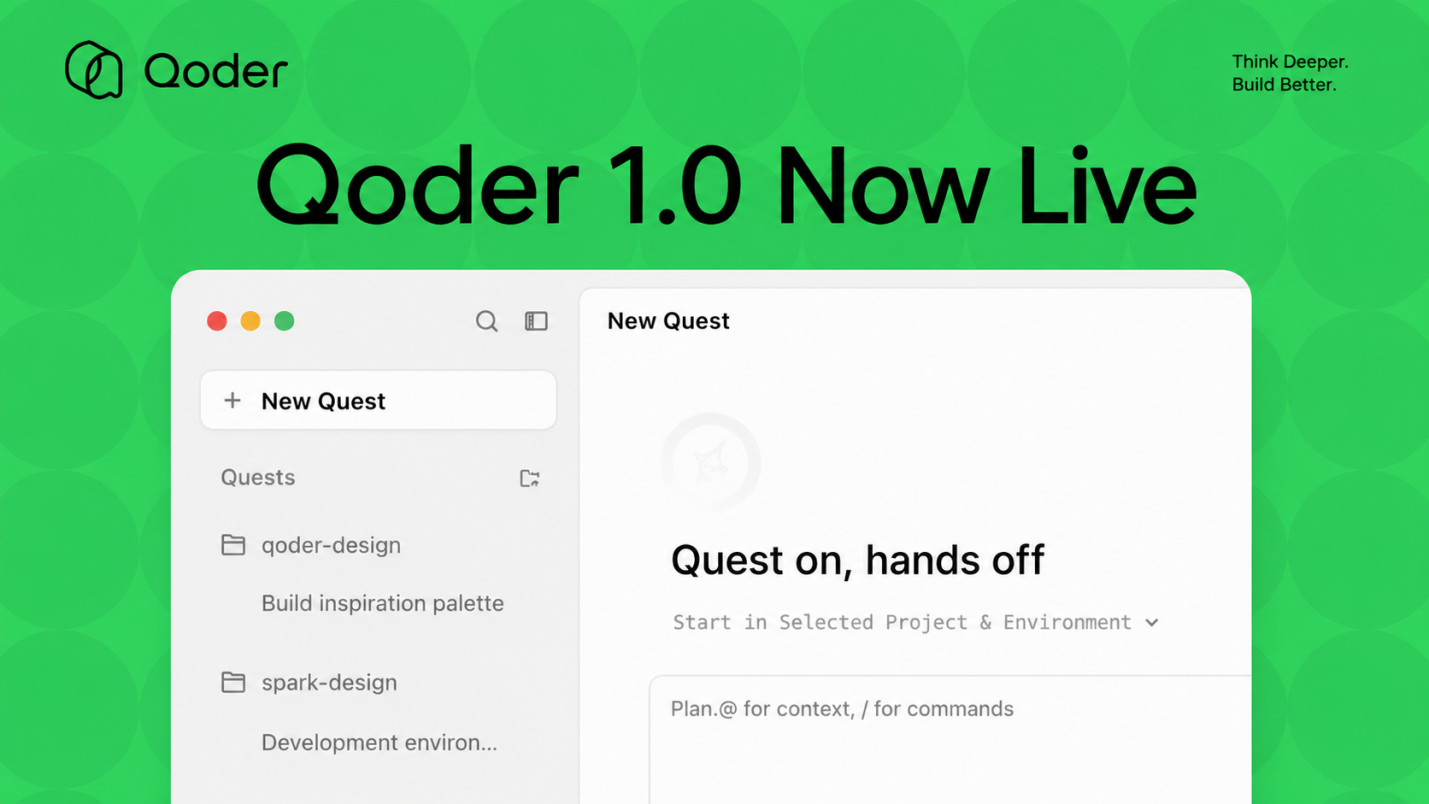
What the Quest window says about the product
The first major feature in Qoder 1.0 is the new Quest window. According to the official announcement, Quest combines task management, status tracking, artifact review, and knowledge invocation. Qoder also says a user can enter a requirement and let an Agent autonomously handle execution, verification, and delivery inside the workspace.
The important word here is not "window." It is "task." When an AI coding tool lives mostly in a chat panel, the user has to keep prompting, pasting results, explaining failures, and asking for follow-up changes. That can be fast for small edits, but it becomes fragile during longer work. For an agent to participate in real product development, the work needs state. It needs to show what the requirement was, which files changed, which tests ran, which artifacts were produced, and where human approval is required.
That is why Qoder emphasizes a structured Task Runtime. The press release says the traditional chat dialogue has evolved into a Task Runtime with a reviewable artifact chain. That phrase sounds like product marketing, but it points at one of the most practical bottlenecks in AI coding. Enterprise teams do not only want to hear that "AI generated the code." They need to know that the AI interpreted the requirement in a specific way, changed these files, ran these checks, produced these artifacts, and left enough evidence for review.
The difference is not cosmetic. In a chat-oriented tool, failures are scattered through a conversation. In a runtime-oriented tool, failures attach to stages. A planning failure, knowledge retrieval failure, code generation failure, test failure, and delivery failure require different responses. If Qoder 1.0 implements the Task Runtime well, the user should be able to find where the agent went wrong faster. That is the real value proposition for the next generation of AI IDEs.

Team knowledge is another name for the context race
The second axis is Qoder's Team Knowledge Engine. The announcement says Qoder has unified previously separate Memory, Repo Wiki, and Knowledge Cards. It frames that as a team-level sharing mechanism that can turn individual know-how into organizational capability. During work, the agent can automatically invoke team conventions, historical decisions, module relationships, coding standards, and tech-stack knowledge.
This lands directly in the current AI coding competition. Even when frontier models are strong, coding agents still fail in production repositories because they do not understand local context. Repository structure, older architecture decisions, module boundaries, deployment rules, test conventions, security exceptions, and review preferences usually are not on the public internet. Developers carry that context in their heads. Agents keep trying to infer it within a token budget.
Every serious coding-agent product is trying to productize context. Cursor emphasizes rules, docs, and background-agent environments. Claude Code is building around Skills, MCP, project memory, and command-based workflows. GitHub Copilot is moving closer to repositories, pull requests, issues, and sessions. OpenAI Codex is packaging task execution, remote environments, and approval loops. Qoder's Team Knowledge Engine is another attempt to solve the same problem with a different interface.
The internal numbers Qoder published are aggressive. The company says the Knowledge Engine improved code retention by 11%, reduced input token consumption by 40%, and reduced conversation turns by 33%. These are not external benchmark results, so they should not be read as absolute performance comparisons. They are still useful as a product signal. Qoder is not trying to stuff more context into every prompt. It is trying to selectively invoke the knowledge that matches the current task, reducing noise and token cost during execution.
For that strategy to work, operational quality matters more than retrieval alone. Team knowledge ages. Rules change. Bad exceptions become folklore. A historical decision for one module may be wrong for a new architecture. If an agent automatically invokes stale practice under the label of "team knowledge," productivity can go down instead of up. The value of a Team Knowledge Engine therefore depends on governance: who writes knowledge, who approves it, when it expires, how conflicts are resolved, and whether the agent shows which knowledge it used.
Parallel work is attractive, but it creates a control problem
Qoder 1.0 also highlights cross-project parallel multitasking. The announcement says users can monitor progress across multiple projects in one screen without constantly switching windows. This follows a broader market pattern. AI coding tools are moving from one agent slowly handling one task to multiple agents working on separate branches, repositories, or projects at the same time.
Parallelism is an easy productivity story to tell. In practice, it creates a new operating burden. If several agents open pull requests at once, human review becomes the bottleneck. If they touch shared modules, merge conflicts rise. If they all run tests, CI and local compute can become scarce. If one agent changes a dependency or migration, the team has to know which authority it used and why. As agent-generated code volume increases, the human role shifts from typing to control.
That means the important question is not how many jobs can run at once. The important questions are how well the tool isolates work, how clearly it displays change scope, how quickly a failing job can be stopped, how token and compute budgets are controlled, and how completed artifacts enter a review queue. Qoder's emphasis on task management and status tracking in Quest is a response to this problem.
Development teams should adopt parallel agents with a small baseline first. Documentation fixes, test additions, type-error cleanup, and narrow refactors are reasonable candidates for multiple concurrent agent tasks. Authentication, payments, data migrations, and security policy are different. In those areas, a single wrong change can have a high blast radius. Qoder's announcement alone does not prove how well the product handles those boundaries yet.
QoderWork and the CLI point outside the editor
Qoder's official documentation makes the desktop message feel less sudden. The Qoder documentation index includes not only IDE plugins, but also CLI, Mobile, QoderWork, IM Channels, Scheduled Tasks, MCP, Hooks, Skills, Qoder Action, and Remote Control. QoderWork in particular covers communication channels outside the workspace, scheduled tasks, connectors, and expert kits.
This mirrors a larger shift also visible in GitHub Copilot App and Codex mobile control flows. Coding agents are not useful only while the IDE is open. They can pick up work when an issue is created, report status from a messaging channel, run from a CLI, wait for mobile approval, and validate changes in CI. Qoder describes a six-part product family: Qoder IDE, Qoder CLI, Qoder JetBrains Plugin, Qoder Mobile, QoderWork, and QoderWake. The same release says Qoder serves more than 5 million users globally.
A broad product family does not automatically mean a strong ecosystem. For AI coding tools, the breaks between surfaces matter more than the feature list. Can a task started in the IDE be continued from the CLI? Does a mobile approval leave an audit trail? Does team knowledge behave consistently across plugins and command-line use? Can MCP and Hooks pass an organization's security policy? If Qoder wants the Autonomous Development Desktop label to hold up, those connections have to show up in day-to-day product experience.
The competition is about harnesses, not just IDEs
Qoder 1.0 is also meaningful inside the Chinese AI coding market. Alibaba's ecosystem has often been discussed alongside Qwen Code and Qoder. ByteDance's Trae, Baidu Comate, Tencent CodeBuddy and QClaw, and Zhipu CodeGeex are also competing for developers. They overlap with global products such as Cursor, GitHub Copilot, OpenAI Codex, Anthropic Claude Code, Replit, and JetBrains AI.
Model quality alone does not explain this competition. The words Qoder repeats are not only model names. They are Agent, Experts, Quest, Knowledge Engine, Harness Engineering, and Task Runtime. The fight is moving from "which model is attached?" to "what harness does the model work inside?"
A harness includes how the agent uses tools, which files it can read and write, how tests run, how failures are recovered, whether logs are reviewable, how context is supplied, how tasks are queued, and how cost is controlled. A strong model inside a weak harness can become a dangerous autocomplete machine. A slightly weaker model inside a better harness can create more dependable value in repeated team workflows. The real news in Qoder 1.0 is not just that another AI IDE has shipped. It is that Qoder is describing itself as a runtime and harness company.
What still needs verification
There are several unresolved questions in the announcement. The first is the definition of the internal metrics. The public release does not explain the period, language mix, task type, or baseline behind the 11% code-retention improvement. The same applies to the 40% reduction in input tokens and 33% reduction in conversation turns. Those are useful product metrics, but they are not the same as software quality. Fewer turns do not automatically mean safer code.
The second question is agent permission boundaries. "Autonomous Development Desktop" is a powerful message, but once autonomous execution, verification, and delivery enter the product, the tool needs deeper access to repositories and systems. Organizations must decide which tasks may run automatically, which commands require approval, and which external connectors are allowed. Qoder's docs expose extension points such as Hooks, MCP, Skills, and Remote Control. That extensibility is a strength, and also a security review surface.
The third question is trust in team knowledge. It is attractive to say that agents can automatically call team conventions. But if the convention is wrong or outdated, the agent can move faster in the wrong direction. A knowledge engine is not just search infrastructure. It is a maintenance system. Who approves knowledge? When does it expire? Which code changes or decisions is it connected to? Does the agent cite the knowledge it used in the artifact chain? Those details determine whether the feature improves engineering work or quietly automates old mistakes.
The fourth question is the review economy of parallel work. As agents generate more code, the bottleneck moves from writing to reviewing. Qoder is right to put artifact review into Quest, but real teams still have to manage reviewer time, CI cost, conflicts, and accountability. Parallelism becomes productivity only when humans can reject, approve, or redirect agent output quickly.
The signal for development teams
Qoder 1.0 is not a signal that every team should immediately adopt Qoder. It is a signal about the next product standard for AI coding tools. Asking only "which model does it use?" is no longer enough. Better questions are emerging: Does the work have durable state? Does the agent invoke team knowledge with sources? Are artifacts reviewable? Are verification results tracked? Can multiple tasks run in parallel with controlled cost and permissions?
Tools that answer those questions well are more likely to shape the next generation of AI development environments. Qoder's answer in 1.0 is Quest, Team Knowledge Engine, structured Task Runtime, and cross-project parallel multitasking. For now, these are mostly claims from an official announcement and documentation. The direction is still clear. The next battlefield after the AI IDE is not the editor surface. It is whether the agent can operate a team's real development loop in a way that is visible, governable, and verifiable.