1,000 Desktop Tasks Turn Computer-Use Agents Into Verifiable Systems
OpenComputer shifts computer-use agent evaluation from LLM judges to reproducible desktop tasks and app-state verifiers.

- What happened:
OpenComputerrethinks computer-use agent evaluation with 33 desktop apps and 1,000 tasks.- The paper appeared on arXiv on May 19, 2026, and the GitHub repository includes the evaluation harness and app-specific verifier structure.
- Key numbers: GPT-5.4 reached a 68.3% success rate, while Claude-Sonnet-4.6 reached 64.4%.
- Why it matters: The new bottleneck is not only whether agents can see screens, but whether environments can verify outcomes.
- On 120 samples, the LLM judge matched human decisions in 95 cases, while hard-coded verifiers matched in 113.
- Watch: The official benchmark excludes 17 tasks that require visual or spatial judgment beyond hard-coded checks.
Computer-use agent demos are getting easier to believe. Watching an agent open a browser, move files, edit a spreadsheet, or change code in an IDE no longer feels exotic. The harder question comes after the demo: who can tell whether the agent actually finished the task, how can that judgment be reproduced, and what part of the software state should count as evidence?
The OpenComputer paper, posted to arXiv on May 19, takes that question head-on. Researchers from Yale NLP Lab, the University of Pennsylvania, and the University of North Carolina at Chapel Hill propose OpenComputer: Verifiable Software Worlds for Computer-Use Agents. The central idea is simple but consequential. Instead of asking an LLM whether the final screen looks right, evaluate the final state of real desktop applications with programmatic verifiers.
That is not a small implementation detail. It is a change in research infrastructure. GUI agent evaluation has leaned heavily on screenshots, action logs, human-authored tasks, and LLM-as-judge scoring. But success in desktop work often lives outside the pixels. It can be hidden in file contents, saved settings, SQLite profile databases, document metadata, browser history, plugin state, terminal logs, project structure, or application-specific configuration. OpenComputer moves that hidden state into the center of evaluation.
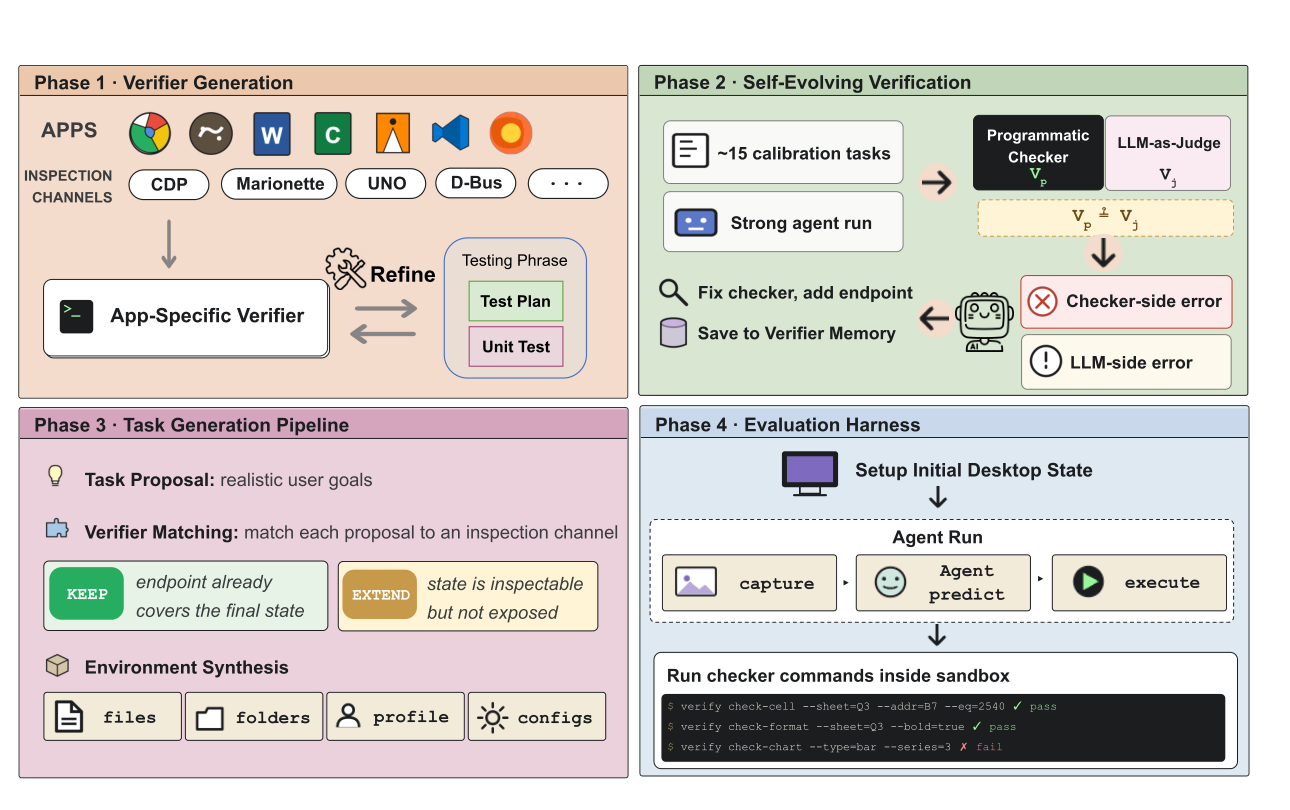
The figure above shows the pipeline described in the paper. OpenComputer combines four pieces. First, it builds app-specific verifier endpoints. Chrome and Brave use CDP, Firefox uses Marionette, LibreOffice-style tools use UNO, Electron apps such as VS Code and Slack use CDP, and other apps can be inspected through channels such as D-Bus, SQLite, file parsing, and AT-SPI. Second, it runs calibration tasks with real agents. Third, it analyzes disagreements between programmatic verifiers and LLM evaluators, then repairs checkers or endpoints. Finally, it synthesizes verifiable tasks and runs checker commands inside the sandbox after each agent attempt to compute reward.
What 33 Apps And 1,000 Tasks Reveal
The public OpenComputer release contains 33 desktop applications and 1,000 final tasks. According to Table 1 in the paper, each app has an average of 17.7 verifier endpoints, each task has an average of 6.9 checks, and each task uses an average of 1.3 seed files. The breadth matters because the suite spans browsers, office tools, creative software, development environments, file managers, and communication apps.
Those numbers do not only mean "more tasks." In desktop agent evaluation, more tasks require more initial state. A spreadsheet needs realistic data. A document needs structure. A browser profile may need history or bookmarks. A file-manager task needs folders and filenames. A development task needs project files and settings. Then every task also needs a scoring function.
OpenComputer is interesting because it reverse-engineers this process around verifiable state. It starts with realistic user goals and filters out tasks that are too trivial or too linear. It then asks whether the goal can be checked with existing verifier endpoints. If it can, the task stays. If the state is checkable but the endpoint is missing, the verifier can be expanded. Finally, the required files, folders, profiles, and settings are packaged into task.json and an environment setup process.
That turns an agent benchmark from a hand-written workbook into an executable environment supply chain. If computer-use agents improve through reinforcement learning or rejection sampling, the most valuable data may not be a natural-language answer key. It may be a software world where success and failure can be mechanically judged.
Even GPT-5.4 Stops At 68.3%
The paper's most striking table compares model performance. On OpenComputer, GPT-5.4 reaches a 68.3% success rate and an 88.4% average reward. Claude-Sonnet-4.6 reaches 64.4%, and Kimi-K2.6 reaches 58.8%. GPT-5.4 leads the group, but it still fails to fully complete roughly one-third of tasks.
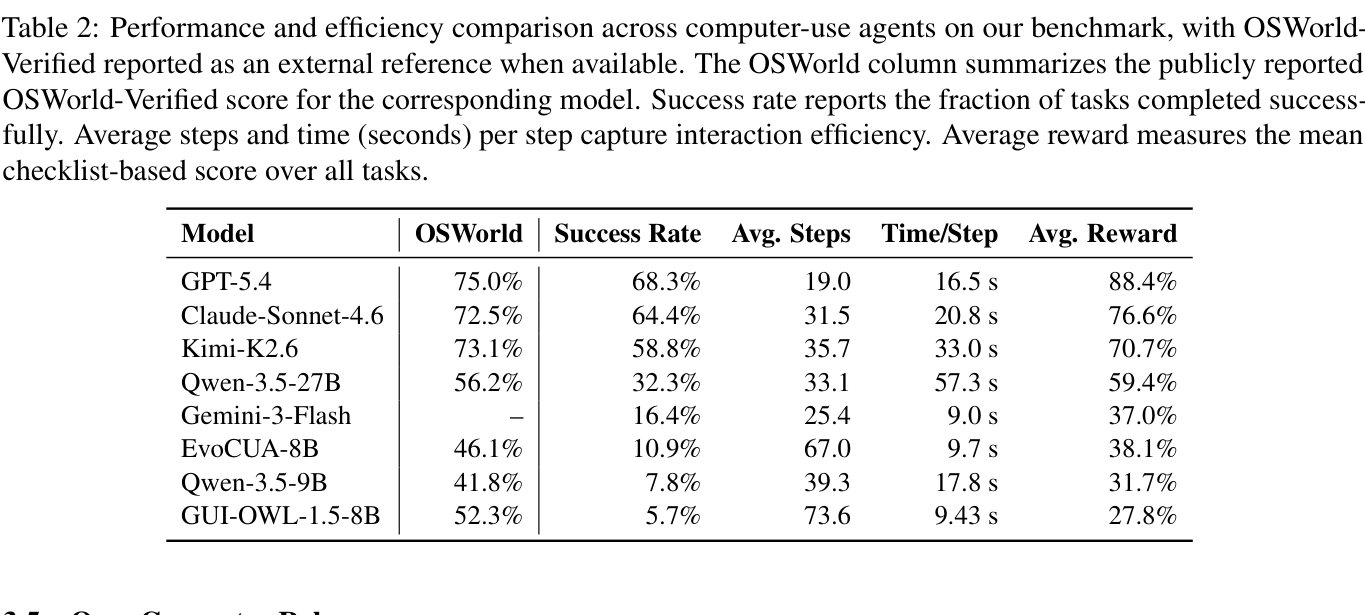
The distinction between average reward and success rate matters. Average reward measures how many checklist items were satisfied. Success rate measures how often all required criteria were met. The gap between GPT-5.4's 88.4% average reward and 68.3% success rate is a useful snapshot of frontier agents today. They often get very close, then fail on a final save operation, a precise cell location, a hidden setting, a wrongly selected object, or a file metadata condition.
The drop for open-source models is much sharper. GUI-OWL-1.5-8B was reported at 52.3% on OSWorld-Verified, but reaches only 5.7% on OpenComputer. EvoCUA-8B falls from 46.1% on OSWorld to 10.9% on OpenComputer. The authors interpret this as evidence that scores on existing desktop benchmarks do not necessarily transfer to broader, more heterogeneous software environments.
For AI product teams, that is an uncomfortable but useful message. A successful computer-use demo is not the same thing as reliable task completion in real work. In particular, there is a gap between a result that looks right on screen and a result that is correct inside the application state. Before automation products enter customer workflows, teams may need to define verifiable completion conditions before they argue about which model to use.
Why LLM Judges Are Not Enough
LLM-as-judge is convenient. You can show the agent's action log and final screenshot to a model and ask whether the task was completed. OpenComputer does not reject that pattern entirely. LLM judges can still help during synthesis diagnostics, and they may be useful for some visual criteria that are hard to express as automatic checks.
But the gap shown in the paper is large. The researchers asked humans to judge 120 completed trajectories, then compared those decisions with an LLM judge and hard-coded verifiers. At task level, the hard-coded verifier agreed with humans on 113 out of 120 samples. The LLM judge agreed on 95. Checklist-level agreement also favored hard-coded verifiers: 97.3% versus 92.2%.
The reason is rooted in the nature of desktop UI. A spreadsheet may look acceptable while two tokens are placed in the wrong cells. A field hidden inside a collapsed panel may be wrong. A Blender scene or development project may contain intermediate artifacts. A file format may store object properties that cannot be inferred from one final screenshot. Programmatic verifiers can read saved documents, databases, settings, logs, and application APIs directly.
OpenComputer's message is not "never use an LLM judge." It is more precise: do not confuse LLM-only judgment with reliable evaluation of computer-use agents. If agents act on screens, evaluators also need to see beyond screens.
A Cautious Version Of Self-Improving Verifiers
OpenComputer's self-evolving verification layer is also worth watching. For each app, the researchers create roughly 15 easy or medium calibration tasks and run a strong agent inside a real sandbox. They then freeze the resulting trajectory and final state, compare criterion-level decisions from an LLM evaluator and the programmatic verifier, and inspect disagreements.
A disagreement can mean two things. The agent may have failed, or the verifier may be checking the wrong condition. OpenComputer only modifies the verification layer when the issue is classified as a verifier-side error. The recorded trajectory, sandbox state, task objective, and expected outcome are not changed. Only checker code, endpoint implementation, or verifier documentation is repaired.
In the experiment, 159 disagreements appeared across 450 calibration runs. Of those, 76 were classified as checker-side errors. The self-evolution process repaired 68 of those 76 cases, an 89.4% repair rate. Forty-seven repairs took one iteration, 15 took two, and six took three. Human-checker agreement rose from 85.2% to 94.1%.
This is another example of AI systems being used to improve the surrounding infrastructure, but the scope is important. The paper does not present unlimited automatic mutation of the benchmark. It frames the process as a bounded debugging loop over the verification layer, anchored to fixed executions and final states. The automation target is not the model output. It is the evaluation tool.
GUI And CLI Hit Different Bottlenecks
The paper also compares GUI and CLI agents. Because OpenComputer verifies final application state, it can evaluate the same goal whether it was achieved through GUI clicks, shell commands, or scripts. The researchers selected 343 tasks across 14 apps that could also be solved from the command line.
The result is nuanced. GUI GPT-5.4 reaches a 75.2% success rate, and GUI Claude Sonnet 4.6 reaches 73.0%. A CLI agent using Claude Code v2.1.129 reaches 67.2%. Time moves in the opposite direction. The CLI agent averages 141 seconds per task, compared with 288 seconds for GUI GPT-5.4 and 622 seconds for GUI Claude.
The CLI is fast and direct. It can manipulate files, run scripts, and call app-specific tools. But for desktop work that depends on visual grounding, GUI agents still achieve higher success in this subset. The practical design lesson is not to choose between screen agents and terminal agents as separate worlds. A stronger architecture may share final-state verifiers while allowing multiple action spaces.
Why Builders Should Care
OpenComputer is closer to research infrastructure than a product you would immediately plug into a customer workflow. The GitHub repository is still early, and the research note records only about 15 stars at the time of checking. Even so, the direction matters. Competition in computer-use agents will not be settled by model API quality alone. Teams also need environments agents can manipulate, setup procedures for initial state, endpoints that verify outcomes, and harnesses that collect failed trajectories.
For developers and AI teams, three practical implications stand out.
First, workflow automation tasks should not stop at natural-language success criteria. "Clean up this report" is too vague as an evaluation target. A deployable automation needs checks such as whether a value was written to a specific sheet, whether an email draft has the expected fields and attachment, or whether a flag in a settings database has the right value.
Second, agent evaluation should move beyond final screenshot review. Human-visible output and persisted system state can diverge. In real work, the saved state is often what matters. The inspection channels OpenComputer highlights, including CDP, D-Bus, UNO, SQLite, and file parsing, map directly onto product QA and enterprise automation testing.
Third, reward quality may become one of the biggest constraints on reinforcement learning and SFT data collection for computer-use agents. OpenComputer says successful and partially successful trajectories can be used for SFT, RL, and rejection sampling. That implies training data for computer-use agents should not be just screen-action logs. It should be paired with verified state changes.
The Remaining Limits
The paper is clear about its limits. Not every desktop task can be represented by a hard-coded verifier. In Draw.io, it can be difficult to prove through a file format or API alone that an arrow visually and semantically connects two boxes in the intended way. In design tools, exact alignment and visual quality may require perceptual judgment. The researchers excluded 17 generated tasks from the official benchmark because their success criteria could not be fully checked with hard-coded logic.
That decision makes the benchmark more credible, not less. OpenComputer does not claim that everything can be scored by code. The likely next step is hybrid verification that combines executable state checks with visual judgment. Even then, the system should record which criteria were checked programmatically and which relied on visual or model-based judgment.
The real signal from OpenComputer is straightforward: the next bottleneck for computer-use agents is not another impressive click-through demo. It is reproducible environments and verifiable completion conditions. Models will keep getting better at doing things. But teams that want to deploy real automation need a mechanical language for asking "was it done?" OpenComputer is an early blueprint for bringing that language into the world of desktop apps.