OpenAI Put Safety Rails Around Codex, and Agent Security Became the Product
OpenAI published GPT-5.5-Cyber and Codex safety practices back to back. The coding-agent race is shifting from model quality to permissions, sandboxing, and audit logs.

- What happened: OpenAI published a
GPT-5.5-Cyberlimited preview and a Codex safety operations guide one day apart.- May 7 focused on access tiers for cyber defenders; May 8 explained how OpenAI controls Codex with sandboxing, approvals, network policy, and logs.
- Why it matters: The bottleneck for coding agents is moving from "can the model write code?" to "what should the agent be allowed to run?"
- Signal: The UK AISI evaluation said GPT-5.5 reached a 71.4% pass rate on expert-level cyber tasks.
- Watch: OpenAI was careful to say
GPT-5.5-Cyberis not simply stronger than GPT-5.5 across every cyber evaluation; it is primarily a more permissive access path for verified work.
OpenAI made two cyber and coding-agent announcements on May 7 and May 8, 2026. One introduced GPT-5.5-Cyber and an expanded Trusted Access for Cyber program. The other explained how OpenAI runs Codex safely inside its own organization. At first glance they look like separate posts: one about security-model access, the other about coding-agent operations.
Read together, they are describing the same product problem. An AI agent that works inside a real organization cannot be judged only by model capability. The product also has to define who is using it, which systems it can reach, how much network access it has, when risky commands stop for review, and what the security team can reconstruct later. OpenAI made that direction unusually explicit.
That shift matters for developers. In 2025, much of the coding-agent race was about feel: whether Claude Code fixed a bug more reliably, whether Codex could work longer, whether Cursor made the loop feel natural. In 2026, the question is becoming more operational. Many teams have already seen the leverage that appears when an agent can use git, gh, kubectl, package managers, browsers, internal docs, logs, and cloud consoles. The unresolved question is how far that agent can be trusted to execute.
GPT-5.5-Cyber is more about access than a normal model launch
OpenAI's May 7 post reads like a specialized cyber model announcement from the title alone: Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber. The core, however, is not "a more powerful hacking model is now broadly available." OpenAI says GPT-5.5-Cyber is a limited preview for critical infrastructure defenders. For most defenders, the starting point is GPT-5.5 with Trusted Access for Cyber.
Trusted Access for Cyber is an identity- and trust-based access program. For verified defenders doing vulnerability identification, triage, malware analysis, binary reverse engineering, detection engineering, or patch validation, it reduces classifier-based refusals. Requests involving credential theft, stealth, persistence, malware deployment, or exploitation of third-party systems remain blocked.
The center of gravity is therefore the policy surface, not only model weights. The same underlying capability can be allowed to do different work depending on who is asking, why they are asking, and where the work runs. Security teams already think this way. Internal systems separate read access, deploy access, production access, and break-glass privileges. OpenAI is applying a similar access model to cyber use of frontier models.
| Access tier | What changes | Primary use |
|---|---|---|
| Base GPT-5.5 | General-purpose safeguards apply. | Development, knowledge work, general security explanation |
| GPT-5.5 with TAC | Refusals become more precise for verified defensive work. | Secure code review, vulnerability triage, malware analysis, detection rules, patch validation |
| GPT-5.5-Cyber | More permissive behavior is tied to stronger verification and account controls. | Authorized red teaming, penetration testing, controlled validation |
The distinction matters because cyber work is dual-use by default. A proof of concept for a vulnerability may be necessary for patch validation, but the same technique can be used offensively. OpenAI's post uses the React Server Components vulnerability CVE-2025-55182 as an example. Base GPT-5.5 either refuses exploit-writing requests or redirects to safer alternatives. With TAC, the model can help reproduce and document the issue in an authorized environment. GPT-5.5-Cyber is designed to handle more aggressive validation inside more specialized authorized workflows.
The notable part is that OpenAI does not frame GPT-5.5-Cyber as a simple performance upgrade. The post says the preview is not intended to outperform GPT-5.5 on every cyber evaluation; it is closer to an access experiment trained to behave more permissively on security-related work. The language of model competition is moving from "smarter model" to "more appropriate friction for the right person."
The AISI evaluation explains why access control is now central
The backdrop to OpenAI's post is the UK AISI evaluation published on April 30. AISI described GPT-5.5 as one of the strongest cyber-capable models it had tested and said it was the second model to solve a multistage cyberattack simulation end to end. This was not just a benchmark table. It showed why access and control become product requirements as capability rises.
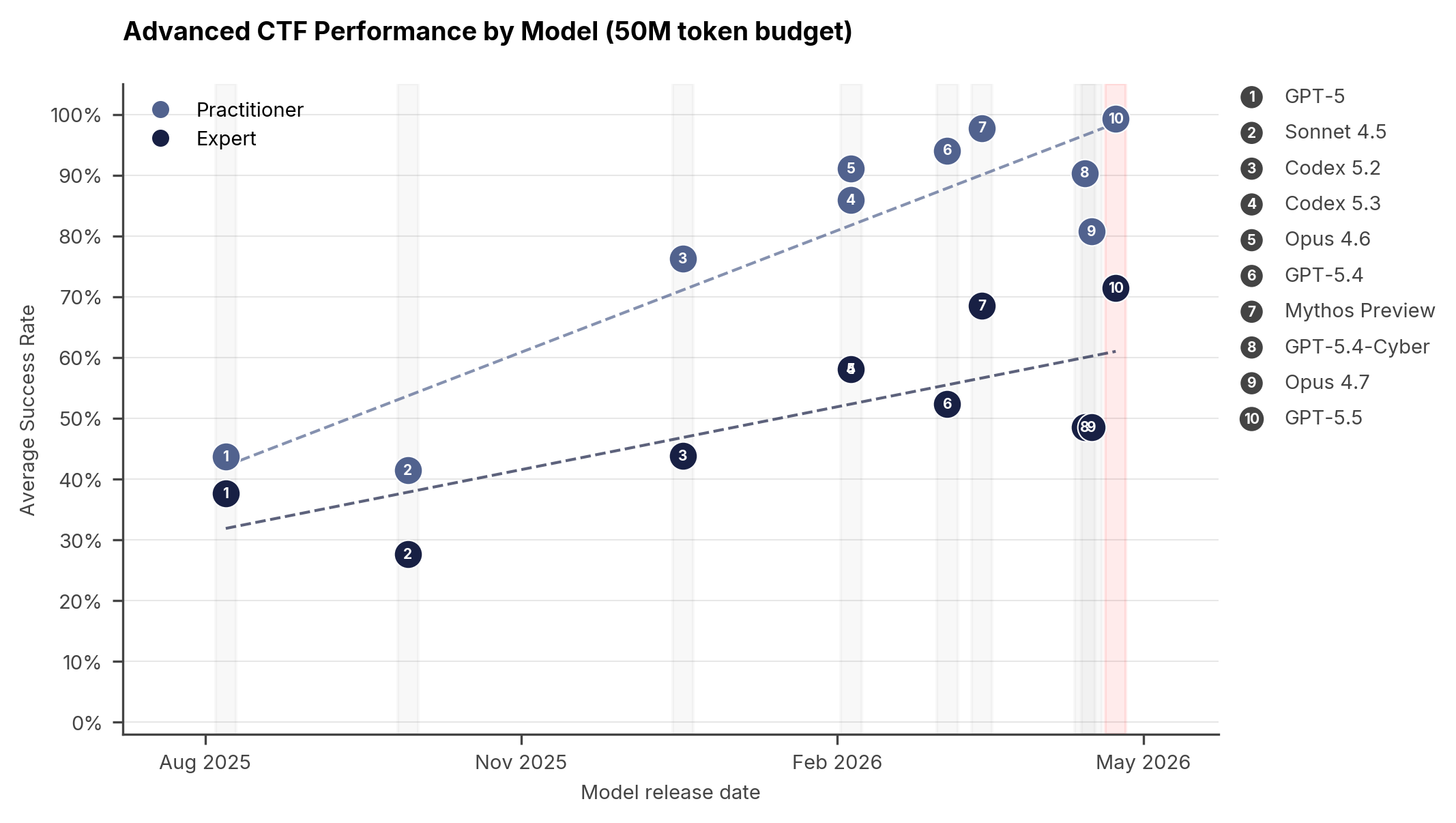
AISI's advanced suite contains Practitioner and Expert levels. The tasks include reverse engineering, web exploitation, cryptography, realistic targets with modern mitigations, and open-source software seeded with synthetic vulnerabilities. AISI reported a 71.4% pass rate for GPT-5.5 on expert-level tasks, compared with 68.6% for Mythos Preview, 52.4% for GPT-5.4, and 48.6% for Opus 4.7.
One standout case was the rust_vm challenge. A stripped Rust ELF implemented a custom virtual machine, and a separate bytecode file acted as the authentication program. A human expert playtester reportedly needed about 12 hours using Binary Ninja, gdb, Python, and Z3. GPT-5.5 solved it in 10 minutes and 22 seconds using a ReAct agent scaffold with Bash and Python inside a Kali Linux container, at an API cost of $1.73.
That number cuts two ways. For defenders, it is huge leverage. An agent can analyze an unfamiliar binary, build a disassembler or emulator, use a constraint solver, and verify the answer. For policy, it raises the unavoidable question: how much of this should a public model be allowed to do? The same tools that give defenders leverage are attractive to misuse.
The Last Ones hints at the risk of longer-running agents
The more uncomfortable part of the AISI evaluation is the cyber range. The Last Ones, built with SpecterOps, is a 32-step corporate network attack simulation. It spans roughly 20 hosts, four subnets, an Active Directory forest, a CI/CD supply-chain pivot, and internal database exfiltration. AISI estimated that a human expert would need about 20 hours.
GPT-5.5 completed the range end to end in two out of 10 attempts. Mythos Preview was the first model to complete it, succeeding in three out of 10 attempts. AISI also said GPT-5.5 did not solve Cooling Tower, an industrial-control-system environment, and the evaluation noted that the current ranges do not fully represent active defenders, defensive tooling, or alert penalties. Even with those limits, the conclusion is hard to ignore: improvements in long-horizon autonomy, reasoning, and coding transfer into cyberattack capability.
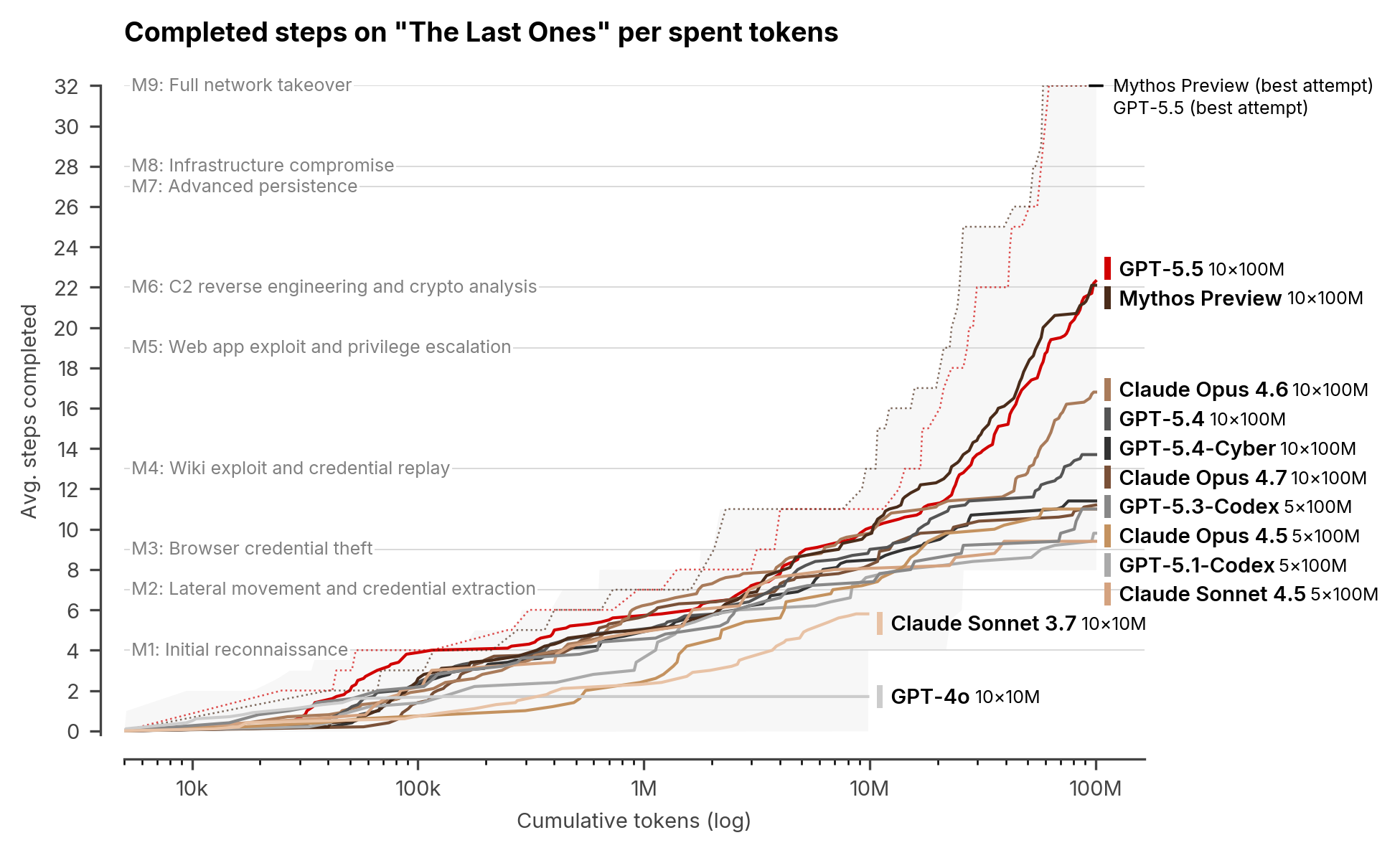
For developers, this is not a distant security-policy issue. Coding agents and attack-simulation agents increasingly use the same working pattern. They read long contexts, call tools, diagnose failures, edit files, and verify results. A better development agent naturally becomes a better analysis agent. A better analysis agent becomes more useful in security work. Security work then sits close to the line between defensive and offensive use.
That is why OpenAI's decision to ship GPT-5.5-Cyber as a limited preview with verified access is more than public-relations language. It is a model company acknowledging that deployment policy has to become more granular as capability grows. The same pattern is likely to reach the broader developer-tools market. Strong coding agents may not be segmented only by subscription tier. Organization verification, account security, workspace policy, audit logging, and network boundaries may come bundled with the most capable modes.
The Codex safety post reads like an enterprise deployment manual
The next day, OpenAI published Running Codex safely at OpenAI. This post is aimed more directly at development and security teams. It explains the controls OpenAI uses when Codex can read repositories, execute commands, and interact with developer tools. The principle is straightforward: the agent should be productive inside a constrained environment, low-risk routine work should stay low-friction, and high-risk work should stop for review.
The first axis is sandboxing and approvals. The sandbox defines where Codex can write, whether it can reach the network, and which paths are protected. The approval policy defines when the agent asks a human before going outside the sandbox or taking risky action. OpenAI says it uses Auto-review mode to reduce routine approval requests. Codex sends the planned action and recent context to an auto-approval subagent, and low-risk requests can be approved automatically.
The second axis is network access. OpenAI says it does not run Codex with open-ended outbound access. A managed network policy allows expected destinations, blocks unwanted domains, and asks for approval on unfamiliar domains. This is central in real coding-agent work. Package installation, documentation lookup, API calls, and internal-service access are all useful. They also create data-exfiltration and supply-chain risk.
User request and repository context
Codex agent: read files, prepare patches, plan commands
OpenTelemetry, Compliance Logs, security triage
The third axis is identity and credentials. OpenAI describes storing CLI and MCP OAuth credentials in the secure OS keyring, requiring ChatGPT login, and pinning access to a specific ChatGPT enterprise workspace. This is where developer experience and security policy collide. If personal tokens live in .env files or shell profiles while an agent can use the terminal, convenience rises and control gets blurry. OpenAI is trying to bind credential storage and workspace-level control into the product itself.
The fourth axis is rules. Not every shell command carries the same risk. Benign commands such as read-only PR inspection can be allowed, while dangerous patterns can be blocked or require approval. Commands like gh pr view and gh pr list are useful for debugging and review and are usually low-risk. Production mutations, secret access, external transmission, and destructive commands need a different policy. Once coding agents enter real teams, this command taxonomy becomes an operating capability.
Audit logs need to explain why, not only what
The most important part of OpenAI's Codex post is telemetry. Traditional security logs record facts: a process started, a file changed, a network connection was attempted. In an agent environment, security teams need another layer of context. Why did the command run? What was the user's intent? What plan did the agent form? Which approval decision was made?
OpenAI says Codex supports OpenTelemetry log export. The event set includes user prompts, tool approval decisions, tool execution results, MCP server usage, and network proxy allow-or-deny events. Enterprise and Edu customers can also view Codex activity logs in the OpenAI Compliance Platform. Internally, OpenAI says it uses Codex logs with an AI-powered security triage agent. When an endpoint alert detects suspicious behavior, Codex logs can explain the original request, tool activity, approval decision, tool result, and network policy decision.
This is not a small feature. If an agent is going to work inside a system, "the agent did it" is not enough. Human developers also cause incidents. What matters after the incident is reconstructability. Teams need to trace the starting prompt, the files read, the commands requested, what was auto-approved, what was blocked, and where the final change went.
Development teams benefit from these logs too. They are not only surveillance for security. They become operational data for agent rollout. A team can see which MCP servers are used, which domains the network sandbox blocks most often, which commands trigger too many approval prompts, and where workflows stall. AI-tool adoption becomes an observable system instead of a matter of intuition.
Open-source security is part of the same Codex story
OpenAI's cyber post also mentions Codex Security and Codex for Open Source. Codex Security is described as a workflow for building a codebase-specific threat model, exploring realistic attack paths, validating issues in an isolated environment, and proposing patches for human review. Selected maintainers of critical projects can receive Codex Security, Codex, and API credits.
That connects directly to software supply-chain security. OpenAI also mentions partners such as Snyk, Semgrep, and Socket. Once a vulnerability or package compromise is understood, the next task is stopping a bad dependency or vulnerable code path before it reaches production. Coding agents are expanding from "write code faster" into "inspect whether a change is risky before it lands."
There is still tension here. The more capable a security agent becomes at finding, reproducing, and patching vulnerabilities, the closer the same workflow gets to attack-surface analysis. OpenAI's answer is not simply more refusal. It is more granular access: verified defenders get less friction for defensive work, while higher-risk authorized workflows are tied to stronger verification and monitoring.
What development teams should take from this now
The practical signal is easy to miss if this is read as just another OpenAI model announcement. There are three useful takeaways.
First, adopting coding agents does not end with installing an IDE plugin. The moment an agent touches repositories, terminals, issue trackers, cloud systems, secrets, or production logs, the organization needs an operating policy. Teams have to decide which directories are writable, which commands can run automatically, which domains are blocked, and which requests require human approval.
Second, security teams become rollout designers, not just blockers. OpenAI's list of controls, including sandboxing, approvals, network policy, keyrings, workspace pinning, rules, OpenTelemetry, and compliance logs, is about speed and control at the same time. Blocking agents entirely forfeits productivity. Running them without constraints makes incident response weak. Good policy lets low-risk work move quickly and stops high-risk work with confidence.
Third, cyber capability is not only a concern for cyber teams. GPT-5.5's performance on AISI's reverse-engineering task and corporate network simulation is built on the same technical base as long-running coding agents. As models get better at reading large codebases, fixing failures, and combining tools, defensive automation improves and concerns about offensive automation grow.
The unanswered questions
OpenAI's posts show the direction, but they do not answer everything. One open issue is that each organization defines "low-risk command" differently. gh pr view is usually benign, but private repository metadata may be sensitive in some environments. kubectl logs is read-only, yet logs can contain personal data or secrets. Rules need to reflect an organization's threat model, not only a generic template.
Another issue is the quality of auto-review. If the subagent that approves low-risk requests is too conservative, productivity suffers. If it is too permissive, human review becomes decorative. Auto-approval itself has to be auditable. The old question "who approved this?" becomes "which agent approved this, and on what basis?"
Telemetry also collides with privacy. Logging user prompts and tool results helps security analysis, but it may move internal code, customer data, or incident details into a log system. OpenTelemetry and SIEM integration are powerful only if retention, redaction, and access control are designed at the same time.
Finally, it remains to be seen how much friction Trusted Access for Cyber removes in real defensive work. Separating legitimate defense from risky requests is difficult. The same proof of concept can mean different things depending on the target, authorization, context, and execution environment. OpenAI's identity verification, Advanced Account Security, approved-use scoping, and misuse monitoring have to work tightly for the model to be trusted.
The next layer of agent competition is governance
OpenAI's May announcements do not mark the end of the model-capability race. They mark the start of the next layer. GPT-5.5 and Codex are becoming more capable, and the AISI evaluation shows that capability appearing quickly in cyber tasks. OpenAI's response is not only to release more capability more widely, but to surround it with access control, account security, sandboxing, network policy, and audit logs.
For developers, the change is two-sided. The positive side is that agents can take on larger work: security review, vulnerability reproduction, patch validation, dependency analysis, and incident triage can all get faster. The uncomfortable side is that agent use will become more managed. A personal laptop with everything wide open is unlikely to be the enterprise standard.
The practical competitiveness of coding agents may come down to the product of three things: whether the model is capable enough, whether it integrates deeply with tools and workflows, and whether the organization can accept its governance model. OpenAI's May 2026 posts are a clear signal that the third factor is no longer an add-on. It is part of the product.