Codex Goals and the New Completion Contract for Coding Agents
OpenAI Codex Goals turns long-running coding work into an evidence-based loop with objectives, verification surfaces, constraints, and budgets.
- What happened: OpenAI described Codex
/goalas a persistent work loop with objectives, verification, and constraints.- The Codex 0.128.0 release added persisted
/goalworkflows, runtime continuation, app-server APIs, model tools, and TUI controls.
- The Codex 0.128.0 release added persisted
- Why it matters: The competitive question for coding agents is moving from "how long can it run?" to "what counts as done?"
- Builder impact: A useful Goal defines the evidence surface first: tests, logs, benchmarks, diffs, deploys, or generated artifacts.
- Watch: Goals are not unlimited autonomy. They are thread-scoped completion contracts with budgets, boundaries, and stop conditions.
The new Goals flow in OpenAI Codex can look small at first. A user writes a target after /goal, and Codex keeps working toward that target across turns. But if you read OpenAI's May 9 Cookbook guide alongside the April 30 openai/codex 0.128.0 release notes, the center of gravity is not "keep going." It is the decision to make completion criteria a product surface.
That distinction matters. Developers using coding agents have been repeating the same operational phrases for months: continue from here, try the next likely fix, run the tests again, inspect the failure, pick another approach, summarize the blocker. Those sentences are already a work contract. They have simply been scattered across prompts. Codex Goals moves that contract into persistent thread state. A goal can bundle the outcome, the verification method, constraints, boundaries, iteration policy, and the point where the agent should stop and report that it is blocked.
OpenAI's documentation frames Goals as persistent objectives. In more concrete terms, a Goal is a completion condition that tells Codex what result to pursue, how success should be checked, and which constraints must not be violated. The GitHub release notes for openai/codex 0.128.0 put persisted /goal workflows near the top of the release and mention app-server APIs, model tools, runtime continuation, and TUI controls for creating, pausing, resuming, and clearing them. This is not just a prompt-writing tip. It is a change in the runtime and interface model of Codex.
The Work Unit After the Prompt
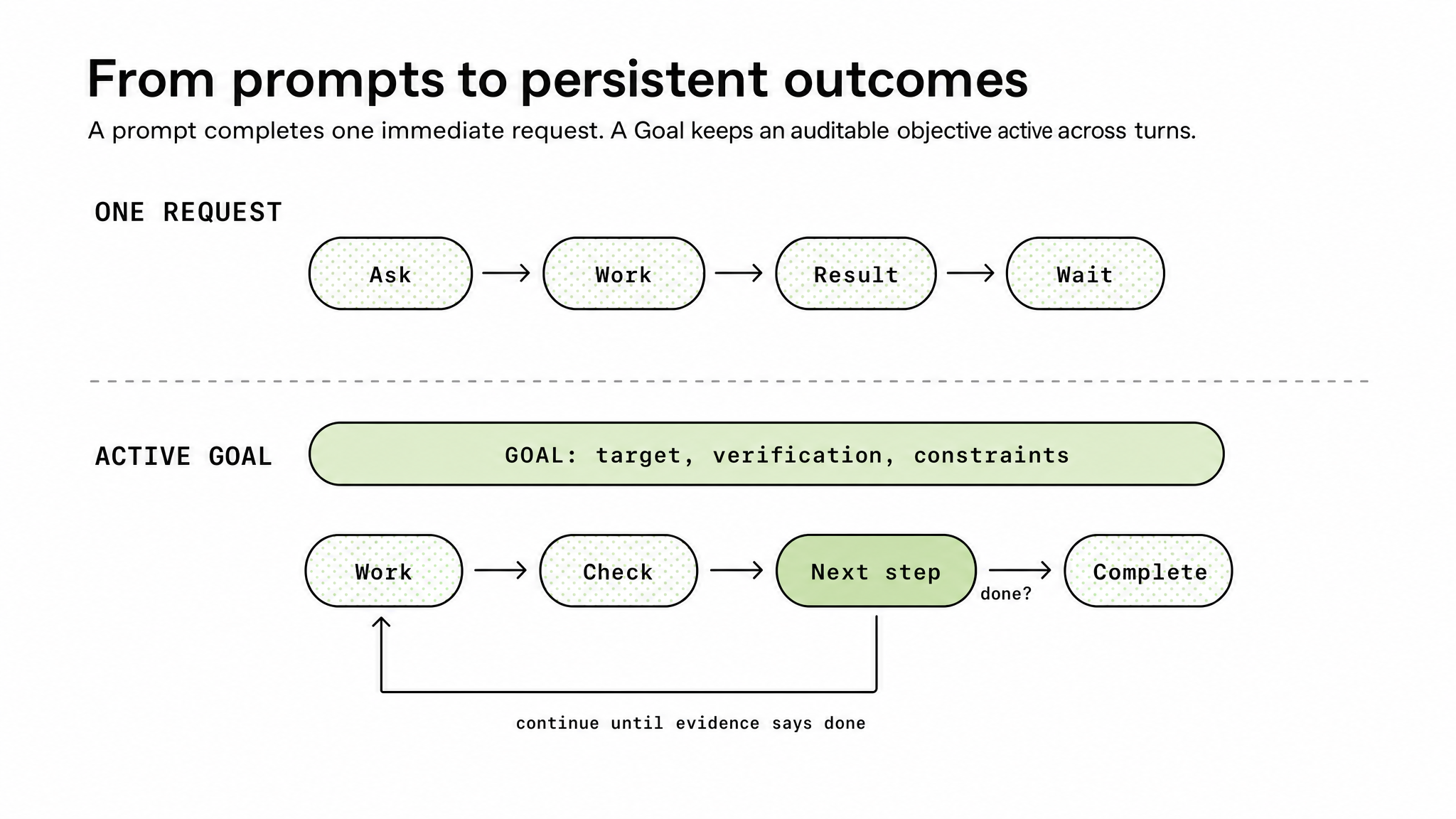
A normal prompt asks for the next piece of work. Codex reads code, edits files, runs commands, reports the result, and then waits. A Goal asks for a state to become true. The important shift is not that the agent never waits. It is that the criteria for continuing or stopping remain attached to the thread.
OpenAI's Cookbook describes the difference as the move from ask -> work -> result -> wait to work -> check -> continue or complete. In a one-off request, the agent produces a result and stops. In a thread with an active Goal, Codex checks the current evidence after each work step. If the goal is not satisfied yet, and the budget and state allow it, the system can choose the next useful action.
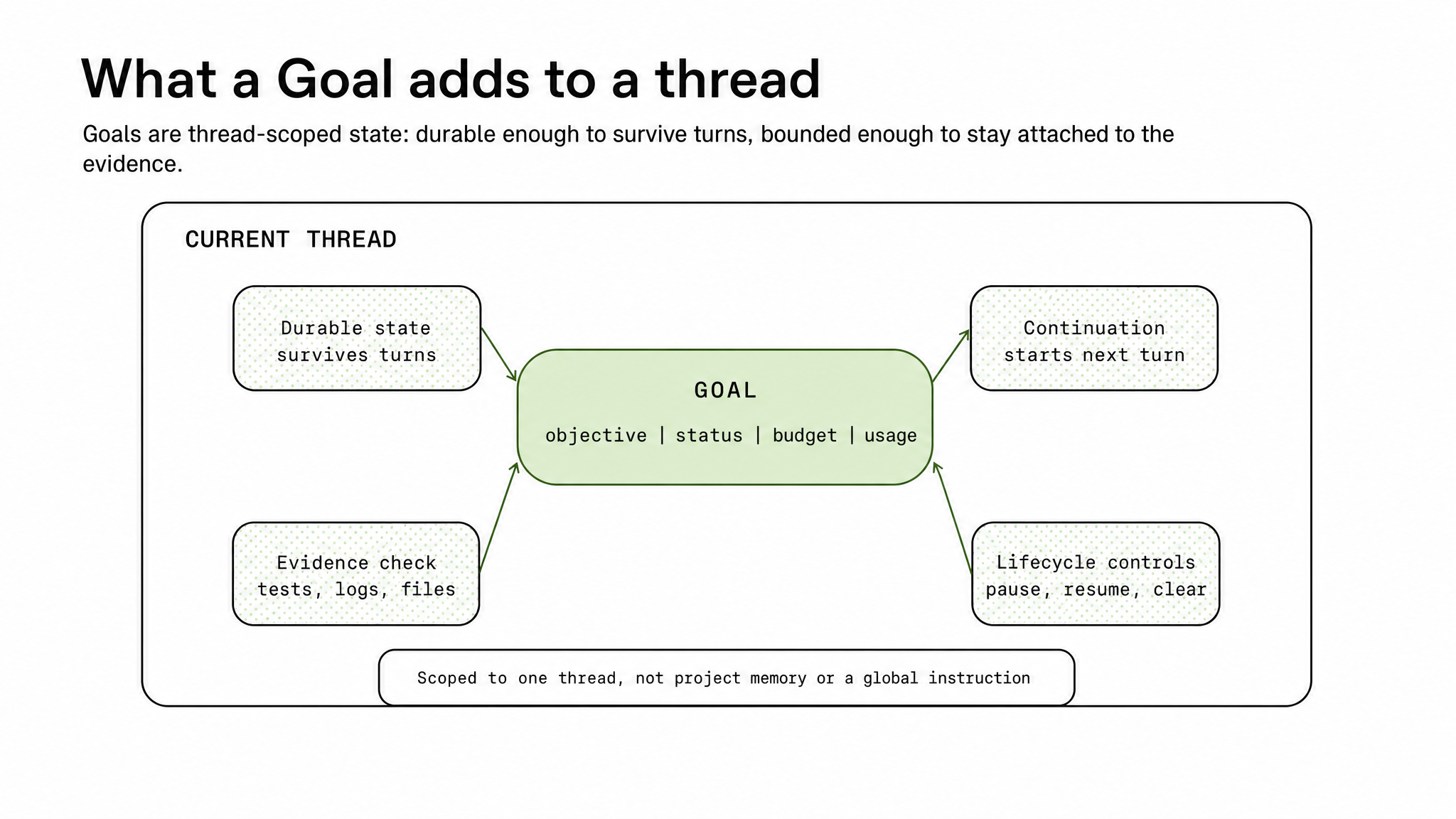
The image captures four pieces Goals add to a thread: durable state, evidence checks, lifecycle controls, and continuation. The most important word here is "thread." OpenAI draws a boundary around Goals. They are not global memory, and they are not project-level instructions. A Goal is attached to the current thread, which already contains the files Codex inspected, the commands it ran, the logs it saw, the diffs it produced, the artifacts it created, and the reasoning path accumulated during that task.
That design is directly connected to trust. If an objective leaked into global memory, it could affect unrelated future work. If the objective existed only as a sentence in a prompt, it could become blurry during a long task. Thread-scoped state is the middle position: durable enough for a sustained coding job, narrow enough not to spread beyond the evidence context of that job.
A Good Goal Is Not a Longer Prompt
The strongest lesson in OpenAI's guide is that a good Goal is not just a bigger prompt. It is closer to a small contract. It should say what outcome is expected, what evidence will prove it, which constraints must hold, which parts of the system may be touched, what should be recorded between iterations, and what Codex should report when there is no defensible path forward.
"Improve performance" is a weak Goal. It has no completion condition. "Reduce checkout benchmark p95 latency below 120 ms while keeping the correctness suite green" is much stronger. It gives Codex a target number, a verification surface, and a constraint that cannot be broken. Codex can run the benchmark, inspect the hot path, make a change, rerun the benchmark, and then verify the correctness suite.
The same pattern applies outside performance work. For a migration, the Goal should preserve contract tests, screen equivalence, and a rollback boundary. For a flaky test investigation, the Goal should ask for reproduction logs, failure frequency, the suspected cause, and repeated passing runs after the fix. For research reproduction, the Goal should distinguish claims that were reproduced exactly, claims that were approximated, and claims that remain blocked because the original data is unavailable.
This is where the practical burden for coding agents becomes visible. "Done" does not become real because a model sounds confident. Done is created by evidence: test output, benchmark results, logs, diffs, deployment state, generated files, screenshots, or a reproduction report. Goals push the user to define that evidence surface before the long-running work begins.
| Area | Weak instruction | Strong Goal |
|---|---|---|
| Performance | Improve performance. | Bring p95 latency below a defined threshold and keep the correctness suite passing. |
| Migration | Move this to the new stack. | Verify screen parity, tests, and rollback boundaries together. |
| Research | Reproduce the paper. | Produce an evidence report that separates confirmed, approximate, blocked, and uncertain findings. |
Continuation, Not an Automatic Loop
It is easy to misread Goals as a "coding agent infinite loop." That misses the point. OpenAI describes continuation as event-driven, not as a blind loop. Codex does not start the next turn whenever it wants. It considers continuation only when the current turn has ended, no other task is pending, no user input is queued, the thread is idle, a Goal is active, and the work is still inside budget.
Another safeguard is subtle but important: if a continuation turn does not produce a tool call, the next automatic continuation is suppressed. That reduces the chance of the model spinning in place with verbal updates that do not advance the task. The user can interrupt the work, and lifecycle commands such as pause, resume, and clear remain visible controls. When the budget is reached, Codex should stop substantive work and summarize progress, blockers, and useful next steps. A budget limit is not completion.
These conditions are a signal for the broader coding-agent market. Last year's product race asked whether an agent could use a terminal, browse a repo, open a remote environment, create a pull request, or keep working outside the IDE. The next question is sharper: how does the agent know when to stop? Goals are OpenAI's answer. Longer runtime is not enough. The right to declare completion has to be tied to evidence and to the contract the user set.
Why This Matters Now
Codex Goals looks modest as a feature, but it sits inside a larger transition. GitHub Copilot has been expanding cloud agents, an Agents tab, desktop surfaces, and remote session control. Anthropic is pushing Claude Code and enterprise Claude deployments into everyday developer and knowledge-work surfaces. Cursor has been emphasizing longer-running work and reinforcement-learning feedback in Composer 2.5. The direction is consistent: agents are being asked to own larger chunks of work.
As the work gets longer, failures also change shape. A single bad code generation can be caught in review. A five-hour automated migration with the wrong definition of "done" is more expensive. Tests may pass while the product requirement is missed. Benchmarks may improve while a regression appears elsewhere. A research report may sound plausible while mixing verified source material with unmarked inference.
Goals do not remove those failures. They give teams a better language for handling them. A team can say the goal was inaccurate, the verification surface was weak, a constraint was missing, there was no blocked stop condition, or the budget limit was mistaken for completion. That vocabulary matters in agent operations. It helps teams improve the quality of work contracts instead of treating every failure as a mysterious model defect.
OpenAI's May 8 post, "Running Codex safely at OpenAI," points in the same direction. The post discusses access boundaries, approval conditions, telemetry, and audit when Codex is used in real workflows. Goals can be read as the task-unit version of that safety logic. It is not enough to decide which systems an agent may access. Teams also need to decide what evidence the agent must see before it can say the task is complete.
What Development Teams Should Change
The immediate lesson for builders is simple: write "done" before delegating a long task to an agent. But "done" should not be a checkbox label. It should be an observable state. Four questions are a useful minimum.
First, what is the result? The answer should be observable, not generic. "Refactor the checkout flow" is weaker than "preserve the public API while the checkout test suite passes." Second, how will it be verified? The Goal needs tests, benchmarks, Playwright screenshots, log queries, generated documents, deployment URLs, or some other concrete surface. Third, what must not be touched? Public APIs, data migration paths, security policy, design-system rules, and existing user changes are all examples of constraints that need to be explicit. Fourth, what should happen when the agent is blocked? The final report should separate failure logs, attempted paths, remaining hypotheses, and the human decision or input needed next.
This is not only a Codex issue. The same discipline applies to Claude Code, Copilot agents, Cursor Composer, internal agent runtimes, and CI-based automation. The stronger agents become, the more important work specification becomes. For long-running tasks, a good objective is a safety mechanism.
What the Community Reaction Shows
As of May 20, GeekNews had surfaced a post about using Codex Goals and summarized Goals as a feature that persists across turns toward a defined outcome. Hacker News was also showing active discussion around Cursor Composer 2.5 and Anthropic's Stainless acquisition. Those are different stories, but they point to the same shift. Developer attention is moving from model intelligence in isolation toward the work surfaces around agents: execution environments, SDK supply chains, workflow control, and verification.
Reddit reactions are more operational. Some users have reported running /goal for a long stretch. Others have asked why Codex stopped while many checklist items remained unfinished. That contrast explains the feature well. Goals are not a magic "finish my project" button. If the objective is vague, if the verification surface is thin, or if budget and stop conditions do not match the size of the job, the experience can still disappoint. When the objective is well defined, Codex has a better basis for choosing the next action.
So the success of this feature will not be determined by OpenAI's implementation alone. It also depends on how users decompose work, what tests and logs teams make available, and how clearly the product exposes budget and state. A coding agent does not become practical simply by being clever. It becomes practical when it is coupled to the surrounding verification infrastructure.
When Completion Becomes a Product Surface
The most interesting thing about Codex Goals is that "the goal" has moved from prompt content into product state. A goal is no longer just a sentence that disappears after it is submitted. It becomes an object with states such as active, paused, complete, and budget-limited. That object can permit or block continuation, force a progress summary when budget is reached, and tie completion claims back to evidence.
This hints at where coding-agent interfaces are going. A chat box is not enough. Agent products need to show the goal list, verification surface, current evidence, remaining blockers, budget usage, risky actions that require human approval, and the basis for completion. GitHub's Agents tab, Cursor's session interfaces, Claude Code's permission flow, and Codex Goals are different versions of the same operating layer.
For development teams, the right stance is neither blind optimism nor reflexive skepticism. The optimistic case is real: a well-defined Goal can reduce the repeated "continue" prompts that developers spend on long and tedious work, especially performance tuning, flaky test investigations, migrations, and research reproduction. The skeptical case is also real: if the completion condition is wrong, the agent can faithfully optimize toward the wrong target. If the evidence surface is weak, a plausible report can masquerade as completion.
The bigger question Codex Goals raises is what it means to delegate software work to an AI coding agent. The answer is drifting away from "write a better prompt." A more accurate answer is "write a work contract whose completion can be proven." OpenAI's /goal is one of the clearer examples of that contract becoming a command and a thread state.
The next coding-agent race will still care about how well models write code. But the more important product question may be this: what does the agent look at before it says it is done? Codex Goals brings that question directly into the developer workflow.