The bill behind 73% success, agent evaluation moves beyond models
IBM Research and Hugging Face’s Open Agent Leaderboard evaluates AI agents as systems, including harnesses, costs, and failure modes.
- What happened: IBM Research and Hugging Face launched the
Open Agent Leaderboard.- It compares general agent systems across SWE-Bench Verified, BrowseComp+, AppWorld, and tau2-Bench variants.
- Core shift: The unit of comparison moves from a model alone to an agent harness + model + cost package.
- Builder impact: The same backbone model can show different success rates, costs, and failure patterns depending on the agent architecture.
- The paper reports that architecture choice can move results by up to roughly 12 percentage points within the same model family.
- Watch: This is a live surface. Treat rankings as snapshots and inspect the protocol, cost traces, and reproducibility before drawing conclusions.
The AI agent market has spent a long time talking in model names. Is Claude better? Is GPT cheaper? Is Gemini faster? Coding agents have followed the same habit. Users compare SWE-Bench scores, context windows, tool-use support, and pricing, then map those model-level numbers onto products. But anyone who has tried to deploy an agent quickly runs into a different layer of reality. Even with the same model, the outcome changes depending on which tool the agent picks first, whether it retries after a bad step, where it stops a long task, and how much money it burns before it admits failure.
That is the point IBM Research and Hugging Face are targeting with the Open Agent Leaderboard, announced on May 18, 2026. On the surface, it is another leaderboard. The deeper message is not "which model is number one." The project tries to compare full agent systems, not standalone model outputs. It makes visible the fact that the same backbone model can behave differently once wrapped in a particular agent architecture, tool interface, planning loop, and cost profile.
That makes this more than another benchmark launch. It changes the evaluation unit. A model provider's scorecard usually tells us how well a model answers a given class of problems. A production agent is wider than a model call. It reads files, edits code, opens browsers, follows support policies, calls APIs, keeps intermediate state, and recovers when something goes wrong. Open Agent Leaderboard puts that whole bundle on the evaluation table.
Six benchmarks on one evaluation surface
The official blog describes Open Agent Leaderboard as a combination of six benchmarks. SWE-Bench Verified tests the ability to fix real GitHub repository issues. BrowseComp+ focuses on complex research questions that require web navigation. AppWorld measures task completion in a personal-work environment with hundreds of apps and actions. tau2-Bench Airline & Retail and tau2-Bench Telecom examine whether agents can perform customer-support or technical-support work while following company policies.
That mix matters because agent failure looks different in each domain. In coding, an agent can pass tests while touching the wrong file. In research, it can write a long answer with thin evidence. In customer support, policy compliance is the product. In personal-assistant workflows, a small API call ordering mistake can change the final state. A single benchmark can show whether an agent is tuned for a specific environment, but it does not tell us how well the system generalizes when the rules, tools, and failure modes change.
The paper General Agent Evaluation frames the problem around general-purpose agents performing tasks in unfamiliar environments. In other words, a general agent is not a hand-built workflow for one job. It should retain some capability when moved into environments with different tools, constraints, and policies. That is a product-minded view of agents. Builders do not only want to know whether an agent scores well on a famous coding benchmark. They want to know whether it collapses when placed in a workflow that does not look exactly like the benchmark.
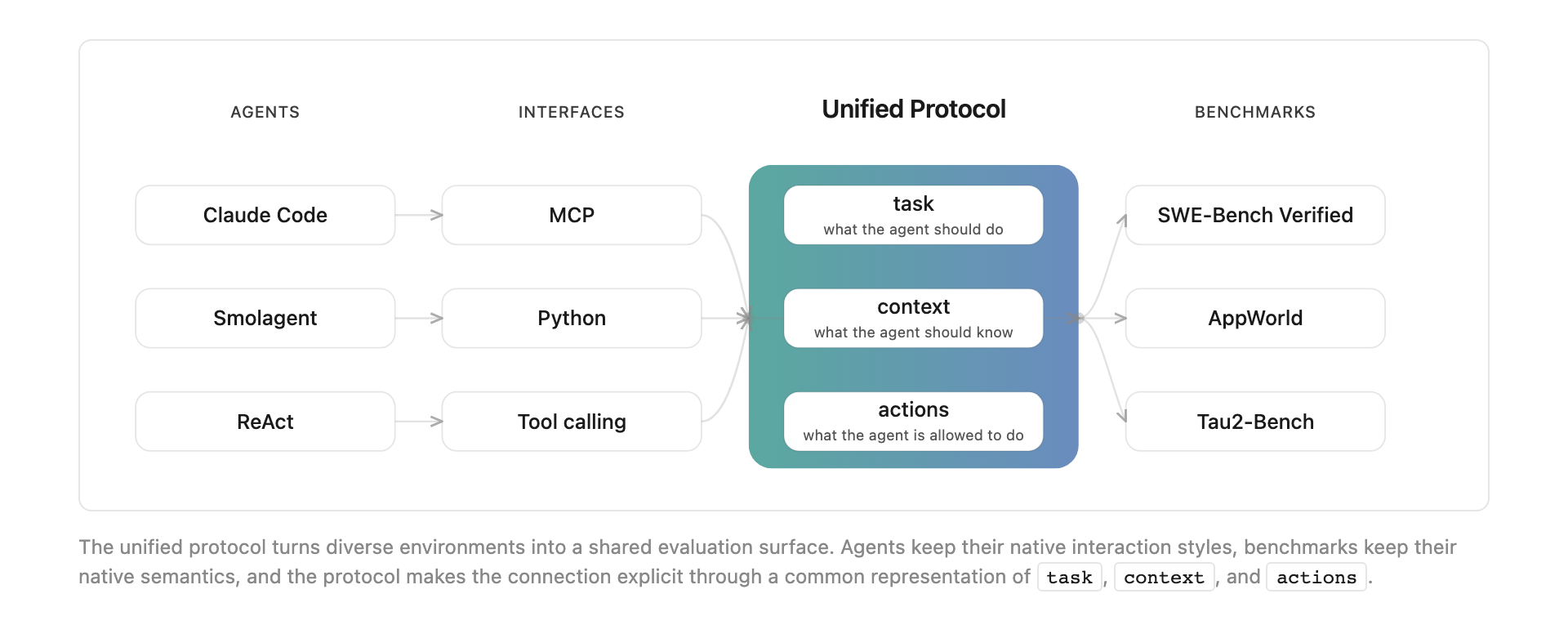
To support that comparison, the researchers propose a unified protocol. Each benchmark and agent can keep its own internal implementation, but tasks, context, and actions are mapped into a shared representation. Without that layer, every benchmark speaks a slightly different language and every agent has to be wired in again. The protocol reduces that wiring cost and lets different agent architectures sit on the same evaluation surface.
The leaderboard is about combinations, not models
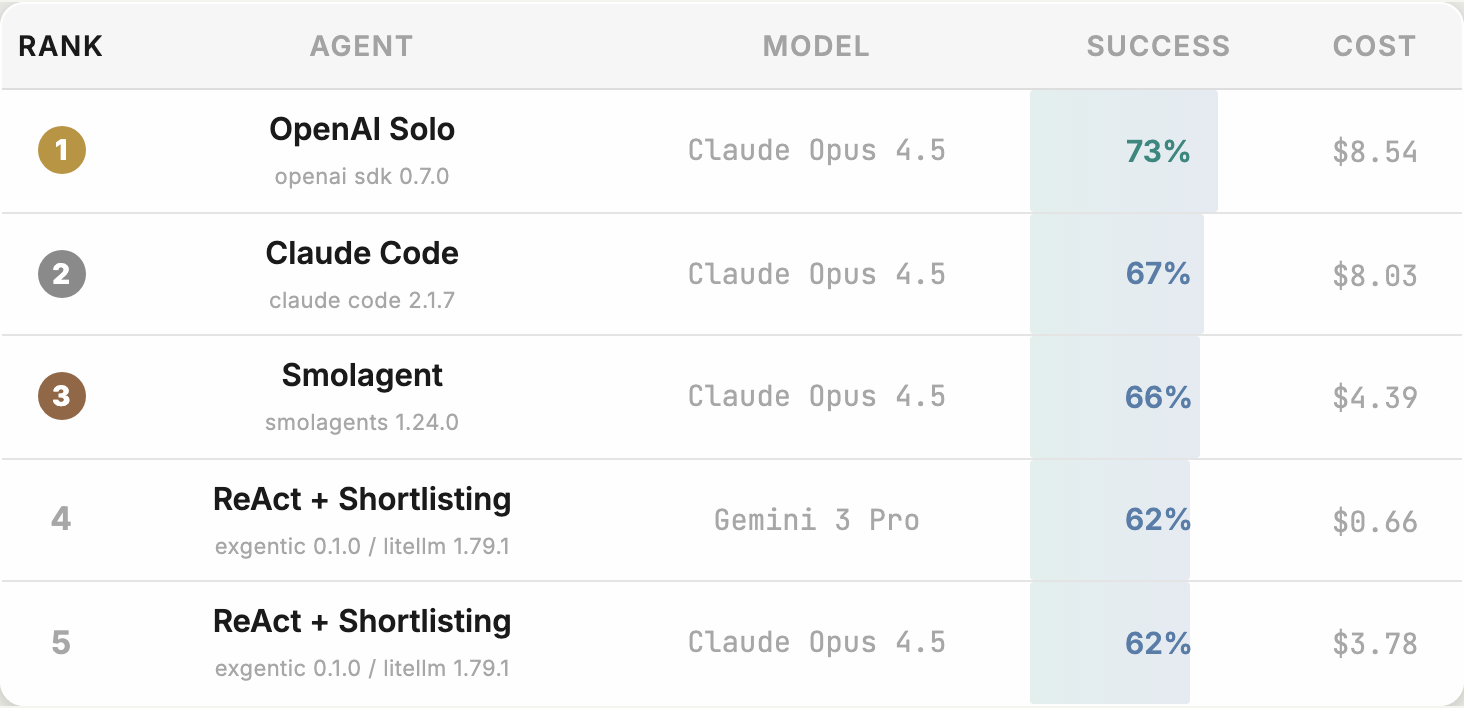
Each row on Open Agent Leaderboard is not just a model. It is a particular agent system paired with a particular model. The examples shown in the launch material include agent configurations such as OpenAI Solo, Claude Code, Smolagent, and ReAct + Shortlisting, attached to models such as Claude Opus 4.5 and Gemini 3 Pro. That structure is the point. An agent is an execution system around a model, and the score belongs to the combination.
The official blog notes that the top three configurations can use the same model while producing different success rates and costs. The harness changes which tools are exposed, how the system plans, how it decides a task is finished, and how it handles mistakes. Coding-agent users have already felt this directly. The same underlying model does not behave identically inside Claude Code, Codex CLI, Gemini CLI, Cursor, or an internal LangGraph harness. File discovery, shell usage, stopping criteria, and logs all differ.
The paper's abstract makes the gap more concrete. The researchers compare a full factorial setup across five agent architectures, five backbone LLMs, and six benchmarks. They report that, within the same model, the choice of agent architecture can move performance by up to roughly 12 percentage points. At the same time, the choice of backbone model remains the dominant performance factor overall. The careful reading is not "models no longer matter." It is "model-only evaluation is incomplete."
That balance matters because the agent market often swings between two exaggerated claims. One claim says model capability decides everything. The other says orchestration can make almost any model good enough. Open Agent Leaderboard does not really support either extreme. Model choice remains powerful. But once an agent starts doing real work, tool shortlisting, context management, memory, error recovery, and interface design become separate variables.
Why cost is on the leaderboard
One of the most useful details in this leaderboard is that cost is not treated as a footnote. The official blog says it shows average success rate together with average task cost. For teams operating agents, that is not a secondary metric. An agent's cost structure is much messier than a chatbot's single response. It can plan, call tools several times, retry after failure, summarize intermediate state, and run a final verification step.
The blog reports that failed executions were 20-54% more expensive than successful ones. That number exposes a cost many teams miss. Failure is not just a score of zero. A failing agent often loops longer, calls more tools, spends more tokens, and still fails to produce a useful result. Even if the failure rate is moderate, expensive failures can dominate the operating bill.
From a builder's perspective, this is a more realistic metric. If one agent gets two percentage points more success but costs several times more per task, it is not always the better choice. A cheaper system that fails fast can be useful for batch evaluation or draft generation, but it may be unacceptable in a customer-facing workflow. Agent evaluation needs to consider success rate, cost, failure duration, retry policy, and tool-call count together.
Putting cost on the public surface also changes how agent products are purchased. It becomes harder for an enterprise to accept "this model is smarter" as the entire argument. The real questions are more concrete. What is the average cost to complete this workflow? How long do failed tasks run? How many wrong tool calls happen before the system stops? Is there an intermediate artifact for a human to review? Can the team explain why the agent stopped?
Exgentic turns evaluation into executable infrastructure
If the announcement were only a web leaderboard, its impact would be limited. The more important piece is Exgentic. The GitHub repository describes Exgentic as a universal evaluation framework for standardizing AI-agent evaluation across benchmarks and domains. It exposes a CLI for listing benchmarks and agents, running specific combinations, and comparing results.
The README lists available agents including LiteLLM Tool Calling, SmolAgents, OpenAI MCP, Claude Code, Codex CLI, and Gemini CLI. Available benchmarks include tau2, AppWorld, BrowseCompPlus, SWE-bench, HotpotQA, GSM8K, and BFCL. That means the leaderboard is not just a static page. It can become a runnable evaluation layer.
The output structure matters as much as the benchmark list. Exgentic stores each run under outputs/<run_id>/ and records overall score and cost, benchmark-level results, runtime context, per-session trajectories, and OpenTelemetry span logs. In agent evaluation, those logs are not just debugging extras. They are evidence for why a task failed, where tool selection went wrong, which context was missing, and which step drove up cost.
This is also why agent observability products have been multiplying. Honeycomb wants to replay agent timelines as traces. LangSmith and Langfuse trace LLM calls and tool calls. Open Agent Leaderboard and Exgentic bring a similar idea into evaluation. Observing agents in production matters, but breaking them in standardized environments before launch is becoming just as important.
The trap in the phrase general-purpose agent
Open Agent Leaderboard says it evaluates general-purpose agents. That phrase is attractive, but it can be misleading. "General" can sound like "good at everything." The paper and blog are more careful. Generality is not a binary property. It is a spectrum, and it only matters when the cost is tolerable.
That framing is useful in practice. Many teams start with a prompt and tool chain tuned for one workflow. That can work well for that workflow. But if every new workflow requires a new prompt, a new tool wrapper, and a new evaluator, the approach does not scale. The opposite extreme is also risky: handing everything to a single general agent can make cost and failure modes hard to control.
Most product designs will land in the middle. They will keep a shared agent harness, then attach domain-specific tool sets, policies, and evaluators. Open Agent Leaderboard is useful because it tries to measure that middle ground. It does not merely ask whether an agent is good at coding. It asks how the same style of agent holds up across coding, research, customer support, and personal-assistant environments.
The official blog says general agents are already competitive with specialized systems on some benchmarks. That sentence should be read carefully. It does not mean specialized systems are obsolete everywhere. It more likely means that when the evaluation surface widens, general agents are strong in some areas, specialized systems still matter in others, and some failures remain invisible if you only look at a headline score.
Open-weight models need a different question
The blog also discusses results for open-weight models such as DeepSeek V3.2 and Kimi K2.5. The summary is that some combinations are competitive, but on average they trail frontier closed-source models by 18-29 percentage points. Again, the conclusion should not be flattened into "open models lose." The better reading is that agent workloads need their own generalization tests.
Open models have real advantages in cost control, data boundaries, on-premises deployment, and customization. But agent work is harder than a single prompt-response interaction. The model must maintain long context, follow tool-call formats reliably, recover after mistakes, ask clarifying questions when instructions are ambiguous, and preserve state over multiple steps. A model that looks strong on chat or coding snippets may not behave the same way in an agent benchmark.
That matters for teams handling sensitive code, customer data, or operational logs. A private deployment can be the right choice, but changing the model means rechecking the agent harness. Tool-calling schemas, JSON stability, function selection, multi-step recovery, and latency tails all become evaluation targets again.
How to read this leaderboard
Leaderboards are easy to misuse. A ranked table travels quickly, and the top name becomes the headline. That is the least interesting way to read Open Agent Leaderboard. Its real value is the attempt to make results reproducible through cost reporting, traces, and a shared protocol.
First, treat it as a live leaderboard. Hugging Face datasets and Spaces update. Model versions change. Agent implementations change. More submissions may arrive. A top-five screenshot or a specific score is a snapshot, not a permanent fact.
Second, inspect benchmark adaptation. The official FAQ says the project does not modify benchmark contents, but it does adapt interfaces to the unified protocol. That can mean externalizing prompts that were embedded in a benchmark or making task instructions explicit for a setup such as SWE-Bench Verified. These changes may be necessary for fair comparison, but they also explain why results can differ from each benchmark's original leaderboard.
Third, note that prompt optimization is intentionally avoided. Many model and agent reports optimize prompts and environments heavily to maximize a specific benchmark score. Exgentic tries to keep comparison more neutral. That has a tradeoff. It makes cross-system comparison cleaner, but it may differ from the performance a team gets after tuning an agent deeply for its own workflow.
A checklist for development teams
Open Agent Leaderboard will not replace every internal evaluation suite. It does, however, change the checklist. Teams putting agents into products can no longer rely on model scorecards alone.
The first question is: what is our benchmark surface? A coding agent should be tested on more than issue resolution. Repository-specific migrations, test repair, dependency updates, security fixes, and rollback tasks may matter more. A customer-support agent needs policy compliance, escalation, refund handling, and identity verification tasks. A research agent needs source tracking and counterexample search, not just fluent summaries.
The second question is: how do we record failure? If only the final answer remains, the team cannot diagnose the system. It needs the tool calls, observations, missing context, retries, and cost-driving steps. That is why Exgentic records per-session trajectory.jsonl and OpenTelemetry spans.
The third question is: how do we balance success rate and cost? Not every task needs the most capable model. At the same time, a cheap model that fails quickly can be dangerous in sensitive workflows. Teams need per-task thresholds for acceptable failure rate, average cost, maximum steps, and human review.
The fourth question is: do we version the agent harness? Model versions are not the only moving part. Tool descriptions, system prompts, memory policies, tool shortlisting, MCP server permissions, and CLI wrappers all change performance. The leaderboard treats agent configuration as part of the evaluated unit because all of those pieces influence the result.
Agent evaluation needs more public infrastructure
The strongest idea in Open Agent Leaderboard is that agent evaluation should not be limited to closed vendor reports. The official blog argues that general agents are too important to evaluate behind closed doors. The wording is declarative, but the direction is right. Once agents enter work systems, their failures affect time, money, security, and compliance. Evaluation methods need more transparency.
Public leaderboards have limits. They cannot represent every real workflow, they cannot include sensitive enterprise data, and live services introduce nondeterminism. But the comparison gets worse without public evaluation. Vendors show benchmarks favorable to their products, and users compare numbers produced under incompatible conditions. Open Agent Leaderboard does not solve that entire problem, but it pushes the comparison unit in a more accurate direction.
That is why this announcement can be read as a new baseline for the agent market. Model leaderboards still matter. They are just not enough for the agent era. The same model becomes a different product when the harness changes. The same success rate implies a different operating contract when cost and failure modes differ. The same tool set exposes a different risk surface when permissions and logs change.
The question Open Agent Leaderboard asks is simple: not only which model does your agent use, but what system does it use to act, fail, and spend money? Once agents do real work, evaluation begins outside the model. The public comparison of harnesses, tools, protocols, logs, costs, and failure modes is becoming part of AI development infrastructure.