88-Core Vera Shows Agent Bottlenecks Moving To The CPU
NVIDIA Vera CPU deliveries show that AI agent competition is shifting beyond GPU inference toward CPU-bound sandboxes, tool calls, and RL evaluation.

- What happened: NVIDIA delivered its first Vera CPU systems to Anthropic, OpenAI, SpaceXAI, and OCI.
- Vera is NVIDIA's first custom data center CPU, aimed at agent runtimes, reinforcement learning, and CPU-bound control work.
- Why it matters: Agent quality now depends on
tool calls, sandboxes, orchestration, memory bandwidth, and failure recovery, not only model tokens. - Numbers to watch: NVIDIA claims 88 Olympus cores, 1.2 TB/s memory bandwidth, and 50% faster per-core performance.
- The Vera CPU Rack pitch goes further: up to 256 CPUs and more than 22,500 concurrent CPU environments.
NVIDIA said on May 18, 2026 that it had delivered the first Vera CPU systems to Anthropic, OpenAI, SpaceXAI, and Oracle Cloud Infrastructure. The scene looked like a hardware marketing tour: an NVIDIA executive carrying servers into AI labs and cloud offices, explaining a new CPU to compute leaders. The more important story is not the photo opportunity. It is the signal that the AI agent race can no longer be explained by GPU inference alone.
Vera is NVIDIA's first custom data center CPU, announced at GTC in March 2026. NVIDIA describes it as a CPU built for agentic AI and reinforcement learning. That sentence can sound promotional until you map it onto how modern AI systems actually run. A coding agent writes code, compiles it, runs tests, opens a browser, reads logs, patches files again, and tries the loop one more time. A research agent writes Python, pulls data, executes simulations, retries failed runs, and stores artifacts. The model may generate tokens on GPUs, but the moment those tokens turn into action, CPUs start doing constant work.
That makes this event larger than "NVIDIA now sells CPUs too." After GPUs became the throne of AI infrastructure, agents are making the rest of the system expensive again. Tool calling, sandbox execution, data loading, KV cache management, code execution, file search, orchestration, and observability create bottlenecks that do not look like dense matrix multiplication. Vera is aimed at that gray area between model inference and real-world action.
What The First Customer List Says
According to NVIDIA's blog, the first Vera CPUs were delivered on Friday to Anthropic's San Francisco office, OpenAI's Mission Bay headquarters, and SpaceXAI's Palo Alto office, followed by Oracle's AI Customer Excellence Center in Santa Clara the next Monday. The list is more interesting than a normal early-customer roll call. Anthropic and OpenAI sit at the center of frontier model and coding-agent competition. SpaceXAI is presented in the context of reinforcement learning and simulation pipelines. OCI is a hyperscale cloud provider.
That mix tells us where NVIDIA expects Vera to matter. Anthropic and OpenAI need faster, denser agent runtimes. When a user asks an agent to fix a failing test, the model does not only answer in text. It needs to understand the repository, run the test suite, install dependencies, read failures, and produce another patch. If thousands of users ask for this at once, CPU environments stop being background infrastructure. How quickly the platform creates agent sandboxes, keeps them dense, recovers failed runs, and preserves logs becomes part of the product.
OCI's role is even more direct. NVIDIA said OCI plans to deploy hundreds of thousands of Vera CPUs beginning in 2026. OCI's product leadership framed agentic AI as a workload that requires sustained performance at large scale. That matters from the cloud customer's perspective. AI agents do not only create sharp peak load. They can hold many small environments open for a long time. One customer's agent may produce dozens of tool calls, while another customer's RL workflow spins up thousands of evaluation environments. In that world, the cloud CPU fleet is not just the layer that feeds GPUs. It becomes a visible driver of price, latency, and reliability.
Agents Do Not Run On GPUs Alone
NVIDIA's Vera material repeatedly makes the same point in different language: AI agents do not run on GPUs alone. For developers, this is a familiar reality translated into a hardware company's vocabulary. An LLM API call is only part of an agent workflow. Once you build an agent product, the practical questions arrive quickly. Where does code execute? How is the file system isolated? Who approves external network access? What happens when a test process hangs? Where do logs, screenshots, and artifacts from thousands of parallel runs live?
Those questions do not shrink as models improve. Weak models are hard to trust with many actions. Strong models can take more actions, which means they require more execution environments. When a coding agent edits multiple files, verifies the result in a browser, reads a CI failure, and writes a pull request summary, success is not decided by reasoning alone. Compile time, package install time, file-system latency, sandbox startup, CPU scheduling, and cancellation behavior become part of the user experience.

The CPU sandbox diagram in NVIDIA's technical blog captures this structure well. Even if GPUs scale candidate generation, compilation and runtime checks happen in CPU sandboxes. The real loop for agentic AI is closer to "the model proposes actions, the environment executes them, and the result trains or corrects the model" than to "the model answers." If CPUs are slow, GPUs wait. If there are not enough sandboxes, agents queue. If memory bandwidth is constrained, state movement becomes the bottleneck.
The Specs Put CPU Back In The Foreground
The headline Vera spec is 88 NVIDIA-designed Olympus cores and 1.2 TB/s of memory bandwidth. NVIDIA claims 50% faster per-core performance at full load than existing CPUs. Its product page points to LPDDR5X memory bandwidth, a low-latency Scalable Coherency Fabric, NVLink-C2C, confidential computing, and Arm compatibility. These are not ordinary web-server selling points. They are aimed at control-heavy workloads inside an AI factory.
The rack-level claim is more revealing. NVIDIA says a Vera CPU Rack can integrate up to 256 liquid-cooled Vera CPUs and run more than 22,500 concurrent CPU environments. That "22,500 environments" number is infrastructure language for the agent era. In the previous phase of AI deployment, the core metrics were inference QPS, token throughput, and GPU utilization. Now teams also need to ask how many sandboxes can run concurrently, whether each environment can sustain full performance, and how quickly a failed environment can be discarded and rebuilt.
The same shift appears in reinforcement learning. RL post-training is not a single training job that cleanly ends. It generates many candidate actions, evaluates them in environments, scores the results, and updates a policy. For coding agents, evaluation may mean test runs, lint checks, benchmarks, and actual tool execution. For robotics or simulation agents, it may mean environment rollouts. In both cases, GPUs handle model computation while CPUs support the environment and validation loop.
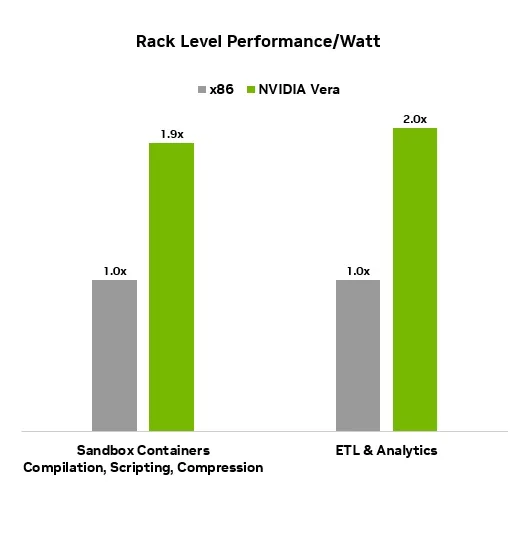
NVIDIA's rack-level efficiency chart pushes that message more directly. The company claims the Vera LC CPU Rack provides a 2x performance-efficiency benefit over traditional air-cooled x86 racks for workloads such as RL sandbox evaluation, ETL, and analytics. Vendor benchmarks still need independent validation. But the direction of the claim is clear: the cost competition around agents and RL will not be fought only on GPU token throughput. CPU rack efficiency is now part of the bill.
Why CPU, And Why Now
For AI developers, saying that CPUs matter is not new. Data preprocessing, feature pipelines, embedding indexes, vector search, API servers, and queue workers have always used CPUs. The agent-era CPU problem is different because the CPU is no longer just handling generic backend traffic. It runs the environment in which model-generated actions become real.
That runtime is latency-sensitive, highly concurrent, isolated, and failure-prone by design. A coding agent may use more CPU when it fails than when it succeeds. A failed test triggers log reading, another edit, another run. A dependency conflict repeats package installation. A browser automation failure collects screenshots and console logs. This is not one long GPU inference call. It is a bundle of many small CPU operations: shell processes, compilers, test runners, file systems, network namespaces, and artifact stores.
Enterprise agents have the same pattern. A spreadsheet agent calls parsers and calculation engines. A contract agent uses OCR, PDF parsing, policy lookup, and approval workflows. A support agent moves across CRM, billing, knowledge bases, and ticketing systems. Between model calls, CPUs fetch data, transform it, check permissions, and record outcomes. As agentic AI moves from answering to acting, CPUs become part of the control plane.
NVIDIA's Strategic Calculation
This is also why NVIDIA is putting a custom CPU on stage. A company that can sell as many GPUs as the market can absorb still has reasons to care about the CPU layer. First, reducing CPU bottlenecks improves GPU utilization. Fast GPUs do not help if data movement, orchestration, or environment execution keeps them waiting. Second, rack-scale systems are easier to sell when CPU, GPU, DPU, networking, and switching are designed as one stack. Systems such as Vera Rubin NVL72 treat the data center, not the chip, as the unit of compute.
Third, agent workloads extend NVIDIA's "AI factory" story into a wider market. Training clusters can feel like the domain of frontier labs and hyperscalers. Agent sandboxes, coding assistants, enterprise workflows, and RL evaluation spread across a broader set of customers. That is why NVIDIA describes Vera as relevant to coding assistants, consumer agents, and enterprise agents. A company that never trains its own foundation model may still need a serious execution layer for agents.
Fourth, the CPU market itself is shifting. AMD EPYC and Intel Xeon remain central to data centers. Hyperscaler Arm CPUs such as AWS Graviton and Google Axion are already strong. NVIDIA enters that market with GPUs, networking, and software around the CPU. That is a direct move into general data center CPUs, but it is also an attempt to bind AI-specific racks more tightly.
| Layer | GPU-era question | Agent-era question |
|---|---|---|
| Inference | How quickly can we generate tokens? | Can we reduce waiting and state movement between tool calls? |
| Sandbox | Execution environments live in a separate system. | Can we create and isolate thousands of environments quickly? |
| RL evaluation | Measure model training throughput. | Measure environment execution and evaluation-loop throughput together. |
| Operations | Watch GPU utilization and QPS. | Watch CPU density, memory bandwidth, and failure recovery. |
What Development Teams Should Measure
This news does not mean every AI team should buy Vera. Supplier performance claims must be validated against real workloads. Agent-system bottlenecks also vary widely. One team may be dominated by LLM latency. Another may wait on a vector database. Another may spend most of its time inside browser automation and test runners. To understand whether Vera's target problem applies, teams first need traces from their own systems.
The first question is time breakdown per agent step. How much of total runtime goes to model inference, tool execution, sandbox startup, dependency installation, file IO, network IO, and post-processing? The second question is concurrency. At peak load, how many environments does the agent create at once, and how long does each one live? The third question is the failure path. Agents fail often. If you do not know how long failed runs hold CPU or how often retries happen, you cannot estimate cost.
The fourth question is isolation and permissions. Running many CPU environments is not useful if they are unsafe. A coding agent that executes arbitrary code needs limits on file systems, network access, secrets, package installation, and artifact uploads. An enterprise agent that calls internal systems needs a clear separation between user permissions and agent permissions. As CPU infrastructure becomes more powerful, the security model must move with it.
The fifth question is lock-in. Vera's strongest story appears when it is tied to NVIDIA GPUs, NVLink-C2C, DPUs, networking, and MGX rack architecture. That may be the right trade for some workloads, but it is still a trade. Teams need to compare it with hyperscaler custom CPUs, AMD or Intel racks, independent GPU clouds, and serverless sandbox platforms, then decide what they gain and what they hand over to a vendor stack.
The Signal For AI Teams
Many AI startups and internal platform teams still budget around model API cost first. Once agents enter the product, that cost sheet changes. A single user request can produce three model calls, ten tool calls, five test runs, and dozens of file parses. Looking only at model token price misses the actual unit economics.
Teams building AI coding tools or workflow automation should design the CPU layer early. At first, a single container and a queue worker may feel sufficient. As usage grows, sandbox density, warm environments, package caches, observability, quotas, cancellation, and artifact retention all become product features. At that stage, CPU capacity, memory bandwidth, file-system behavior, and network isolation are not internal details. They are part of the user experience.
There is also an on-prem and private-cloud angle. Enterprise customers may not be willing to send source code or sensitive workflows to an external agent runtime. In those deals, the location of the execution environment can matter more than the model itself. OpenAI and Dell's on-prem Codex collaboration, Anthropic's enterprise-agent direction, and isolated execution products such as Vercel Sandbox all answer the same question in different ways. Vera is the hardware-foundation version of that answer.
Skepticism Still Matters
In the r/hardware discussion around Vera, commenters mixed optimism about NVIDIA's CPU opportunity with skepticism about real competition against Intel and AMD. That reaction is useful. NVIDIA's announcement provides a strong narrative. A developer making a buying decision needs reproducible metrics from their own workload.
For example, 50% faster per-core performance may not mean the same thing for a codebase compile, a Python sandbox, a data pipeline, and an RL environment. The value of 1.2 TB/s memory bandwidth depends on whether memory movement is actually the bottleneck. The 22,500 concurrent CPU environments claim also depends on environment size, isolation level, storage IO, and network policy. The numbers show direction, but traces and benchmarks should make the final judgment.
The Point Is Not That CPUs Are Back
It would be too flat to summarize this as "CPUs are important again." CPUs were always important. What changed is that their work has moved into the core action loop of AI products. In systems where a model plans, calls tools, executes code, reads failures, and plans again, the CPU becomes the invisible agent runtime.
That is why Vera's first delivery is symbolic. What Anthropic and OpenAI received was not merely a new server. It was a clue about where agent competition is moving. Stronger models demand more actions. More actions demand more sandboxes, orchestration, memory movement, and CPU scheduling. The next AI infrastructure cost sheet may put CPU environment price next to GPU token price.
The developer question is straightforward: is the bottleneck in the model or in execution? If the model answers well but the product feels slow, the issue may be the sandbox rather than the prompt. If GPU utilization is low while the bill is high, the issue may be CPU work and state movement. Vera is not just a new CPU. It is evidence that the performance debate around agents is expanding beyond the model.