Hermes Agent turns the local PC into a learning agent runtime
NVIDIA is positioning Nous Research Hermes Agent on RTX and DGX Spark as a local, always-on self-improving agent runtime.
- What happened: NVIDIA highlighted Nous Research's
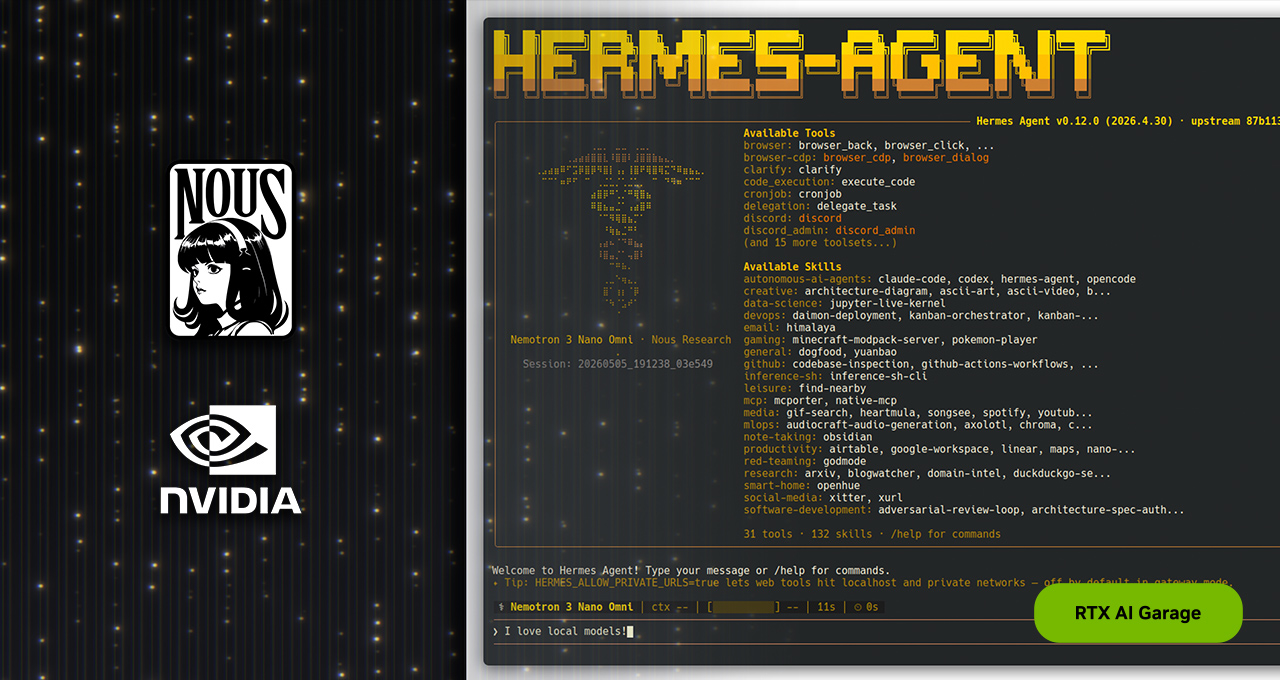
Hermes Agentas a local agent that can run continuously on RTX PCs and DGX Spark.- Hermes aims to create skills from experience, keep memory, and stay reachable through messaging gateways and scheduled jobs.
- Why it matters: The agent race is expanding from cloud model calls into local runtimes and long-term memory.
- Watch: "Self-improving" does not automatically mean model-weight training. The claim is mostly about better skills, memory, and orchestration.
- Without regression tests, deterministic checkers, and pruning, accumulated agent memory can become prompt pollution rather than improvement.
NVIDIA put Nous Research's open-source Hermes Agent in the spotlight on May 13, 2026, as a local agent that can run on RTX PCs, RTX PRO workstations, and DGX Spark. At first glance, this looks like a familiar ecosystem post from a hardware company: take a popular open-source project, optimize it for the company's GPUs, and show developers another reason to keep local acceleration close. The more useful signal is bigger than that. Hermes shows where the agent market is widening next.
Most of the 2025 and 2026 agent race has played out in the cloud. Codex, Claude Code, GitHub Copilot coding agent, xAI Grok Build, Coder Agents, and UiPath for Coding Agents all ask where an agent should run, what permissions it should receive, and how it should interact with code and business systems. Hermes and NVIDIA ask a different question. What changes if the agent is not a short cloud session that wakes up, completes a task, and disappears, but a local runtime that keeps living on a user's own hardware?
The official Hermes framing is direct. Nous Research describes Hermes as a self-improving AI agent with a built-in learning loop. The project says the agent can create skills from experience, improve those skills while being used, search previous conversations, and build a user model across sessions. NVIDIA connects that idea to RTX PCs and DGX Spark. If the model and agent runtime both run locally, conversations and files can stay on the device, API bills do not rise with every long-running loop, and the agent can remain reachable throughout the day through channels such as Telegram or Discord.
The important distinction is that Hermes is not being positioned as another chat UI. NVIDIA highlights self-evolving skills, contained sub-agents, curated skills, tools, and plugins, and an orchestration layer that can produce better outcomes even with the same underlying model. That "same model" phrase matters. Agent quality is no longer explained only by benchmark scores. The product difference increasingly comes from tool order, recovery behavior, memory retrieval, reusable procedures, and when a task should be split into smaller sub-agents.
| Dimension | Cloud agent | Local self-improving agent |
|---|---|---|
| Runtime location | Vendor cloud, remote sandbox, hosted workspace | RTX PC, workstation, DGX Spark, personal server |
| Improvement path | Vendor updates the model and product loop | User environment accumulates memory, skills, and tool configuration |
| Strength | Strong models, managed infrastructure, fast feature rollout | Data control, always-on access, lower marginal cost, personalization |
| Risk | Vendor dependence, data movement, usage-based cost | Weak evaluation, local operations burden, skill pollution and permission drift |
NVIDIA's interest in this direction is easy to understand. An always-on agent turns inference from an occasional API call into a persistent workload. It may check scheduled tasks while the user is asleep, respond to messages from a gateway, read local files, store traces of tool calls, and refine procedures for the next request. That looks less like a CLI session on a laptop and more like a small AI server that remains online. This is why NVIDIA keeps positioning DGX Spark as an agentic computer.
The DGX Spark playbook makes the pitch more concrete. NVIDIA says Hermes and a local LLM can both run on DGX Spark, keeping conversations and data on the machine while using Ollama-based models without cloud API cost. A Telegram bot can make the same agent available from a phone. NVIDIA emphasizes that DGX Spark is Linux-based, has 128GB of unified memory, and is designed as an always-on device. The operational model is more important than the phrase "small supercomputer." The machine is both a personal computer and a runtime that keeps a personal agent alive.
There is an obvious hardware-sales logic here. NVIDIA says Qwen 3.6 35B can run in about 20GB of memory and outperform previous 120B-class models, and it describes DGX Spark as able to run a 120B MoE model throughout the day. Those claims are attractive for developers. In practice, however, a single benchmark tells only part of the story. Quantization format, tool-call latency, concurrent local agents, local storage permissions, and messaging-gateway isolation can matter as much as raw model size.
Hermes' more important controversy is the phrase "self-improving." It should be read carefully. Many people hear self-improving and imagine a model that updates its own weights and becomes smarter. The public Hermes description points mostly to improvement at the agent layer. It stores experience as skills, reuses those skills, searches memory, and models user preferences and repeated tasks. That can be useful, but it is not the same as model training. If weights stay fixed, the agent has better procedures and context. The base model itself has not changed.
User requests, local files, and messaging input
Hermes orchestration layer: tool selection, sub-agent routing, skill retrieval
Local LLM execution: Ollama, RTX GPU, DGX Spark
Results, failure traces, and user feedback saved as memory and skills
Reuse on the next request, guarded by evaluation and permission policy
That distinction is not academic. If a local agent keeps saving its own experience, it will not only store good habits. It can also preserve bad fixes, environment-specific shortcuts, momentary user feedback, and failed commands. If a self-generated skill is automatically used in later tasks, one poor generalization can spread across many future runs. A self-improving agent therefore also needs self-forgetting, skill pruning, regression tests, and an approval policy. Remembering without forgetting can turn a long-running agent into a larger and larger prompt pile.
Community skepticism is pointing in the same direction. A discussion on r/AI_Agents raised the problem that benchmarks for self-improving agents remain thin. The practical questions are whether error rates fall after repeated interaction, whether an agent stops making the same mistake, and whether learning from one user's workflow transfers to another task. One commenter also warned against confusing memory or skill accumulation with model learning. If the model weights do not change, the system is usually providing better context and procedures rather than training a new model. That criticism is not only about Hermes. It applies to the growing set of products that use the language of self-improvement.
For developers, the pragmatic interpretation is this: when evaluating Hermes or a similar local agent, the first question should not be "will this agent become generally smarter?" It should be "can it safely reuse successful paths for repeated work?" Daily issue summaries, build-log checks, scheduled documentation updates, repository hygiene, and personal knowledge workflows are plausible fits. Long-term memory and local skills can reduce repeated setup and make costs more predictable. Legal judgment, security changes, payments, account mutations, and other high-cost actions are different. In those workflows, an agent's self-created skill should not be trusted just because it has been used before.
Evaluation design becomes the core engineering problem. A credible self-improving loop needs at least three things. First, it needs an external success signal. For code, that can mean tests, type checks, linting, and reproducible commands. For data work, it can mean schema validation and sampled review. Second, it needs versioned skill changes and rollback. If an agent-created procedure gets worse, operators need a way back. Third, it needs permission separation. Reading files, running shell commands, accessing the network, sending messages, and making payments are not the same trust level. Running locally reduces some data-exfiltration concerns, but it also means the agent is closer to the user's real machine.
From NVIDIA's perspective, Hermes is a natural continuation of the local agent-computer narrative that OpenClaw helped popularize. NVIDIA does not need to own every agent. The more local agents run on RTX and DGX Spark, the more demand exists for hardware that can keep capable models online near the user's data. Cloud models will remain stronger in many tasks, but some users and teams will still want sensitive data, persistent workflows, and low-latency tool loops to stay local. Enterprises with restrictions on external APIs may also view local agent runtimes as part of a hybrid architecture rather than a hobbyist experiment.
That does not mean local agents replace cloud agents. The more realistic picture is role separation. Cloud agents are strong at using frontier models, large-scale parallelism, managed sandboxes, team administration, and hosted governance. Local agents are stronger at personalization, data control, always-on access, and low marginal cost. Many development teams will mix both. A local Hermes instance might handle sensitive document organization or routine monitoring, while a cloud agent such as Codex or Claude Code handles large codebase changes and harder reasoning tasks.
The reason the Hermes news is interesting is not simply that another agent exists. There are already too many agents to count. The meaningful change is that the unit of execution is shifting. Agents are moving beyond one chat, one CLI invocation, or one remote task session toward something closer to a small operating layer with long-term memory and a skill store. NVIDIA wants to supply the hardware where that layer stays online. Nous Research is pushing the software pattern in which an agent turns experience into reusable procedure.
So the best question to ask is whether Hermes really learns. The answer is partly yes and partly still unproven. If memory and skills help the agent complete repeated work with fewer errors, then it is learning at the agent level. But whether that produces real performance improvement, merely injects more context, or overfits to one user's habits needs measurement. The winners in the self-improving agent category may not be the teams with the most impressive demos. They may be the teams that can evaluate, roll back, prune, and govern the improvements their agents create.
NVIDIA and Hermes show that this competition can happen on local hardware, not only in cloud control planes. As agents become part of a user's environment rather than just a tool the user opens, more questions matter than model size. Where does the agent run? What does it remember? What skills can it create? Who validates those skills? How is failed learning deleted? Hermes Agent does not answer all of those questions yet. It is better read as a signal that local self-improving agents are becoming the next testing ground.