Modal Raises $355M as Agent Compute Gets a New Price Tag
Modal’s Series C shows AI infrastructure moving beyond model APIs into sandboxes, GPU snapshots, RL loops, and agent runtime control.

- What happened: Modal announced a $355 million Series C at a $4.65 billion post-money valuation.
- The company says it has grown 5x since September 2025 and passed $300 million in annualized revenue.
- Why it matters: This round is less about renting GPUs and more about pricing
Sandboxes, RL, low-latency inference, and agent runtimes. - Watch: Serverless GPU is not magic. The real cost depends on how quickly a platform can reuse model weights, CUDA state, and execution context.
- AI teams now have to budget for runtime isolation, permissions, cold starts, and observability alongside model API fees.
Modal announced a $355 million Series C on May 21, 2026. The company disclosed a $4.65 billion post-money valuation. General Catalyst and Redpoint led the round, with Menlo, Bain Capital Ventures, and Accel joining as new investors. Modal also said it has grown 5x since September 2025 and now exceeds $300 million in annualized revenue.
At first glance, this looks like another AI infrastructure unicorn funding story. But the language in Modal's announcement points to a more specific shift. Modal describes itself not as a single-purpose GPU cloud, but as a cloud for AI workloads. The bundle includes low-latency elastic inference, dynamic agent runtimes, reinforcement learning, and massive batch jobs. In other words, the round is not simply a bet that GPUs are expensive. It is a bet that the bottleneck in AI products is moving into the execution layer around the model call.
That distinction matters for developers. In 2023 and 2024, many AI apps were mostly frontier API calls, prompt iteration, and result storage. In 2026, the shape is more complicated. Coding agents need to execute untrusted code. Research agents need thousands of parallel experiment environments. Commerce and support agents need to call tools without making the user wait through unpredictable latency spikes. As models get stronger, the infrastructure outside the model becomes more visible.
What the Numbers Say
The headline numbers in Modal's announcement are $355 million and $4.65 billion. The more interesting numbers are revenue and workload. Modal says it has grown 5x since September 2025 and crossed $300 million in annualized revenue. In a Reuters report republished by StreetInsider, CEO Erik Bernhardsson said annualized revenue rose from about $60 million in September 2025 to about $300 million, and that the number of cloud companies Modal connects to increased from five last year to 13.
That suggests AI compute demand is not explained by "more GPUs" alone. GPUs are scarce and expensive, but teams building AI products are buying something more operational: how quickly a workload starts when traffic spikes, whether a failed agent can be isolated, whether RL experiments and production inference can share an operating model, and whether developers can avoid managing Kubernetes, image caches, and model loading by hand.
Modal calls this a new infrastructure layer for the AI era. The phrase is broad, but the direction is clear. As open-weight models reach production quality and inference engines such as vLLM and SGLang mature, teams move beyond frontier APIs. They fine-tune their own models, tune latency and throughput, and try to fit costs to their own product curves. Modal describes that transition as a move from frontier APIs to model ownership.
Why Sandboxes Are Now in the Pitch Deck
The most interesting part of the announcement is Modal's emphasis on Sandboxes. Modal says it began seeing users run AI-generated code on the platform in 2023, which pushed it to make isolated environments for untrusted code a first-class primitive. It also says the past six months have made it clear that agents become much more powerful when they have a runtime.
That sentence captures a shared bottleneck across coding agents and business agents. If an agent only returns text, a normal API call is enough. If it reads files, runs code, installs packages, sends web requests, runs tests, and then edits its own output, it needs an execution environment. That environment has to start quickly, stay isolated, avoid runaway costs, and leave enough trace data to debug failures.
Developer tools show this demand first. A coding agent that opens a pull request needs a workspace with the repository and dependencies. Security teams want to know which network requests and file accesses happened inside that workspace. Product teams do not want users waiting several minutes after clicking "fix this." The quality of an agent is no longer determined by the model alone. Latency, permission design, snapshots, logs, and reproducibility in the runtime become part of the product.
The customer examples in Modal's announcement point in the same direction. Cognition says reinforcement learning infrastructure and production inference run on the same platform. DoorDash says scaling agentic commerce for local businesses requires harness control, scale, and reliability. The word "harness" matters. Even when an agent appears to act autonomously, a production system still needs a harness around those actions: tests, limits, approvals, observability, and rollback.
The Real Problem Is Cold Start and State
Modal published a technical post days before the funding announcement titled "How we achieved truly serverless GPUs." It is useful context for understanding why this round is not just a GPU rental story. Modal argues that inference workloads are much more variable than training workloads. Training is usually a planned large job. Inference demand jumps with user behavior, market events, social traffic, and product campaigns. Serverless therefore looks attractive. The problem is that serverless on GPUs is not as simple as CPU-based web functions.
Modal says that naively starting a billion-parameter LLM inference server on a B200 can take tens of minutes, or even hours if GPU availability is constrained. Much of that delay comes from reconstructing state: the application image, model weights, CPU initialization, GPU-side initialization, CUDA graphs, and compiler artifacts. A user may imagine that a platform simply attaches a GPU when a request arrives. In practice, latency depends on how much of the needed state is already prepared.
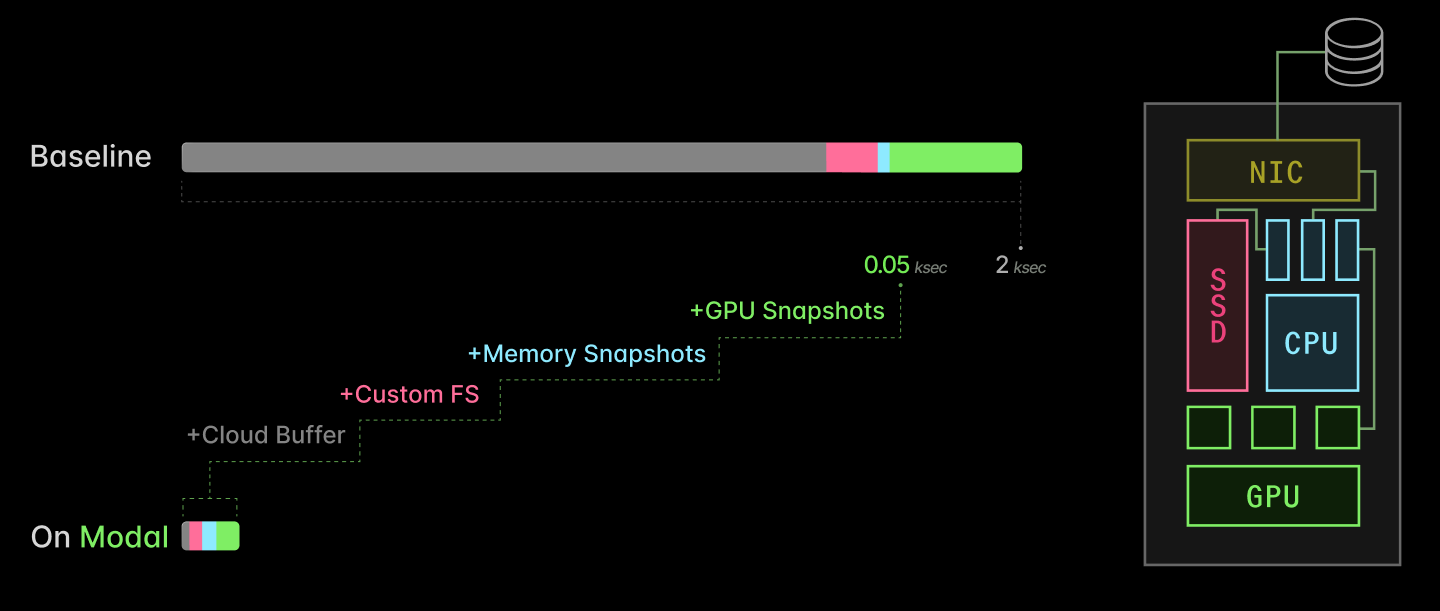
Modal breaks its approach into four ingredients. Cloud buffers keep a small buffer of healthy idle GPUs. A custom filesystem serves container images lazily from a content-addressed cache. Process checkpoint and restore skips CPU-side initialization by restoring memory. CUDA checkpoint and restore reduces initialization work around GPU device memory and CUDA context. Modal claims the combination cuts AI inference server replica scaling from multiple kiloseconds to tens of seconds, and its post includes a chart showing a baseline near 2,000 seconds dropping to roughly 50 seconds.
This technical detail is the news. AI agents often create many short executions rather than one long conversation. They spin up a test environment to fix a line of code, fail, retry, and then try again from another branch. RL runs thousands of environments in parallel. Document processing and multimodal inference produce sudden peak load when a customer uploads a large batch of files. In all of these workloads, cold start is not only a user experience issue. It is unit economics.
State Placement Is the New Competition
Developer discussions about serverless GPU often circle back to the same point. In a LocalLLaMA thread about hosted inference providers, one user argued that most serverless GPU setups still have to reload model weights or keep workers warm when traffic spikes or workers rotate. Another comment said autoscaling pods are not the same as loaded model scheduling without state-aware scheduling. Model weights in VRAM, initialized CUDA kernels, compiled graphs, KV cache, and memory residency are all state.
That does not mean Modal's claims should be accepted uncritically. It means the questions are clearer. "Serverless GPU" is not enough as a label. Teams need to know which state is snapshotted, which state must be rebuilt, how restore time changes with model size and GPU generation, and what limits appear for multi-GPU or long-running stateful agents. Modal's own technical post says GPU snapshots currently have a single-GPU restriction and fit use cases with model sizes from a few GB to a few tens of GB.
The practical lesson is not "use Modal." The more useful lesson is that AI application cost cannot be calculated from token prices alone. Agent runtime costs, sandbox isolation, startup latency, loaded-state reuse, GPU allocation utilization, retries after failed executions, and observability all belong in the budget. For customer-facing agents, p90 latency and tail latency decide whether the product feels trustworthy.
| Layer | Old default question | Question in the agent era |
|---|---|---|
| Model | Which API is smartest and cheapest? | When do we use an API, and when do we operate our own model? |
| Inference | How many GPUs should we reserve? | Can we absorb spikes without tail-latency damage? |
| Execution | Can we run code in a container? | Can we isolate untrusted agent code quickly and safely? |
| State | Do we cache images and dependencies? | Do we reuse weights, CUDA graphs, and memory state? |
| Permissions | Do we separate API keys by user? | Can we grant only the capabilities an agent needs? |
Why the Money Is Arriving Now
AI infrastructure funding already looked overheated in 2024 and 2025. Modal's valuation still makes sense as a signal because demand has changed shape. Early generative AI demand was mostly described through API tokens and training compute. The current wave includes agentic coding, document automation, multimodal extraction, RL post-training, synthetic data generation, and robotics inference. Those workloads behave differently from one another.
They all make the same question harder: where does compute sit, and for how long? A coding agent may be idle most of the time, then suddenly need a repo clone, dependency install, tests, browser automation, and artifact upload. A document processing service may stay quiet until a customer uploads a large corpus and demands hundreds of GPUs. An RL experiment can tie training, evaluation, inference, and sandboxed environments into one loop.
Modal argues that these workloads can run on the same primitives: elastic compute, safe isolation, and programmatic control. Those three ideas look close to the minimum requirements for agent infrastructure. Agents need elastic compute to act when work arrives. They need isolation when actions go wrong. They need programmatic control because a human-operated cloud console is not the right interface for automated systems.
Where Modal Differs From Hyperscalers
AWS, Google Cloud, and Azure already sell GPUs, containers, serverless runtimes, IAM, logging, storage, and networking. So why does an independent platform such as Modal have room? The answer is in the combination of primitives. Hyperscalers provide many raw materials. AI teams often want a higher-level execution grammar assembled from those materials.
Modal hides much of that assembly behind a Python function decorator, sandbox APIs, and developer-oriented workflow. That creates a tradeoff. Building on a provider abstraction means delegating some low-level control and cost optimization. Running your own Kubernetes and GPU pool gives more control, but the team pays the infrastructure tax directly. Modal's customer language about reducing mental overhead sits on one side of that tradeoff.
The selection criteria are practical. If demand is stable, large, and capable of saturating GPUs for long periods, an owned cluster or committed capacity may be better. If workloads are spiky, models and execution environments change quickly, and agents or RL require many sandboxes, a Modal-style platform can reduce total cost. That cost includes the cloud bill, but it also includes operational complexity and release speed.
Permissions Are the Next Gate
Modal says its roadmap includes granular RBAC so customers can give agents capabilities without unnecessary risk. This is a critical point. Once agent infrastructure enters enterprise environments, the biggest question is not merely whether code can run. It is what code can run, where it can run, which data it can touch, and how much it can spend.
A coding agent may need network access to install dependencies. The same network access can become a path for secret exfiltration. A document agent needs to read object storage without crossing tenant boundaries. An RL agent may need to create thousands of sandboxes, but budget and quota controls have to prevent cost accidents. Agent runtime is therefore both a compute product and a security product.
From that angle, Modal's Series C connects to several broader AI industry trends. Coding agents are writing more code. Enterprise agents are calling more internal systems. Automated AI research is running more experiments without direct human intervention. The shared requirement is no longer just a better model. It is an execution control plane: who had which capability, in which sandbox, through which data plane, for how long.
What Builders Should Take From This
For AI startups and internal AI platform teams, this funding round raises practical questions. First, are you still measuring AI cost mostly by token price? User-perceived latency includes preprocessing, tool execution, sandbox startup, postprocessing, and retries. Second, if an agent executes code or calls external services, sandboxing and permission design should be part of the product from the beginning.
Third, teams operating open-weight models need to budget for everything after "download the model and run vLLM." Model-weight loading, graph compilation, autoscaling, idle capacity, region placement, observability, and rollback all become operational costs. Fourth, provider evaluation should use your own workload traces, not just public benchmarks. Document processing, speech conversion, image generation, coding agents, and RL have different peak-to-average ratios and state-reuse patterns.
Modal is not the only answer. The round is more interesting because the answer is still unsettled. RunPod, Baseten, Replicate, Together AI, Fireworks AI, CoreWeave, hyperscaler ML platforms, Vercel Sandbox, and E2B compete from different angles. Some are strong in hosted inference. Some focus on sandbox developer experience. Some win on raw GPU capacity and enterprise contracts.
The Bottleneck Is Outside the Model
AI news usually revolves around new models and benchmarks. Real product bottlenecks are moving outside the model. Modal's $355 million Series C turns that shift into a number. Investors are not only buying access to GPUs. They are buying the ability to turn GPUs into an execution layer for agents, RL, inference, and sandboxes.
The developer question is simple: in your AI system, is the expensive part the model, or the execution around it? Early on, the model looks like the whole cost. Over time, data movement, cold starts, sandbox isolation, permissions, observability, retries, and human approval show up on the cost sheet. Modal is productizing that cost sheet. That is why this round is not just another AI infrastructure funding headline. It shows where agent-era compute is being metered, and where infrastructure companies will try to differentiate.