Mistral 3 675B sets a new baseline for open model competition
Mistral 3 packages a 675B MoE model with 3B, 8B, and 14B edge models under Apache 2.0, shifting open AI competition from benchmarks to deployment.

- What happened: Mistral AI released the
Mistral 3model family.- The headline pieces are Mistral Large 3, a 675B total, 41B active MoE model, and Ministral 3 models at 3B, 8B, and 14B parameters.
- Why it matters: Open model competition is moving beyond a single benchmark table toward licensing, local deployment, inference cost, and edge execution.
- Developer impact: Apache 2.0 weights, vLLM paths, Hugging Face distribution, 256k context, and function calling expand the set of models teams can run on their own infrastructure.
- The public benchmark story still comes mostly from Mistral's own material, so independent reproduction and workload-specific evals remain necessary.
Mistral AI has released Mistral 3. On the surface, this is another open model announcement. The more important story is not simply that another model has arrived. Mistral is packaging a large sparse MoE model with 675B total parameters alongside smaller 3B, 8B, and 14B edge models, and it is releasing the whole family under the Apache 2.0 license.
That combination matters. In 2026, model competition is no longer easy to explain with one question: which model scored a few points higher on a benchmark? Companies and developers now have to ask where a model can run, what license governs it, whether it can sit next to internal data, how it fits a GPU budget, how reliably it handles tool calls and JSON output, and whether it works well enough in non-English languages. Mistral 3 aims at all of those questions at once.
The most eye-catching number in this launch is Mistral Large 3's 675B total parameters and 41B active parameters. The model is huge, but it does not activate every parameter for every token. Mistral describes Large 3 as its return to large-scale MoE after the Mixtral line. At the same time, the company is pushing it not as a closed API only, but as open weights with an Apache 2.0 license and several deployment paths.
The more interesting part of Mistral 3 may be the smaller models beside it. Ministral 3 comes in 3B, 8B, and 14B sizes, with base, instruct, and reasoning variants. Mistral says these smaller models support image understanding, multilingual use, agentic tool use, JSON output, and long context. The Hugging Face Ministral 3 14B Instruct model card describes a 13.5B language model paired with a 0.4B vision encoder, and says the FP8 instruct version can fit into 24GB of VRAM.
That is a practical message for developers. Frontier models still live in cloud environments and large GPU clusters. But many enterprise workloads cannot send every request to the most expensive model. Some requests include sensitive customer data and cannot leave a controlled environment. Classification, extraction, document analysis, local agent work, and high-volume internal product calls all put pressure on the cost structure. Mistral's strategy is to use Large 3 to stay in the frontier conversation while Ministral 3 expands the deployment surface.
The bundle matters more than the 675B model
Large model launches usually revolve around one protagonist. This one is different. Mistral Large 3 takes the headline, but the announcement is structured more like a model portfolio than a single model release. Large 3 enters the large open model race. Ministral 3 targets local use, edge deployment, internal serving, and smaller agent runtimes.
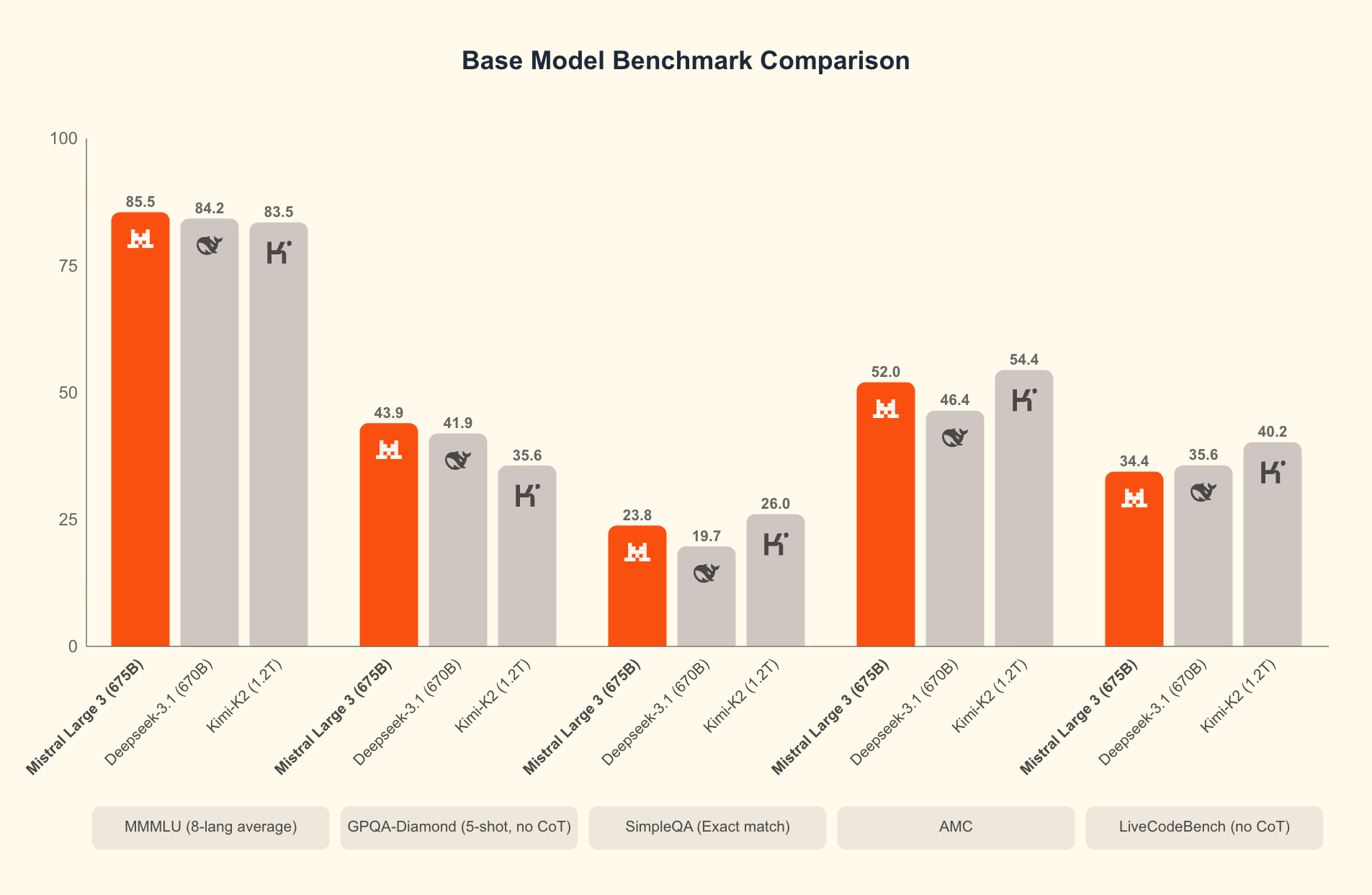
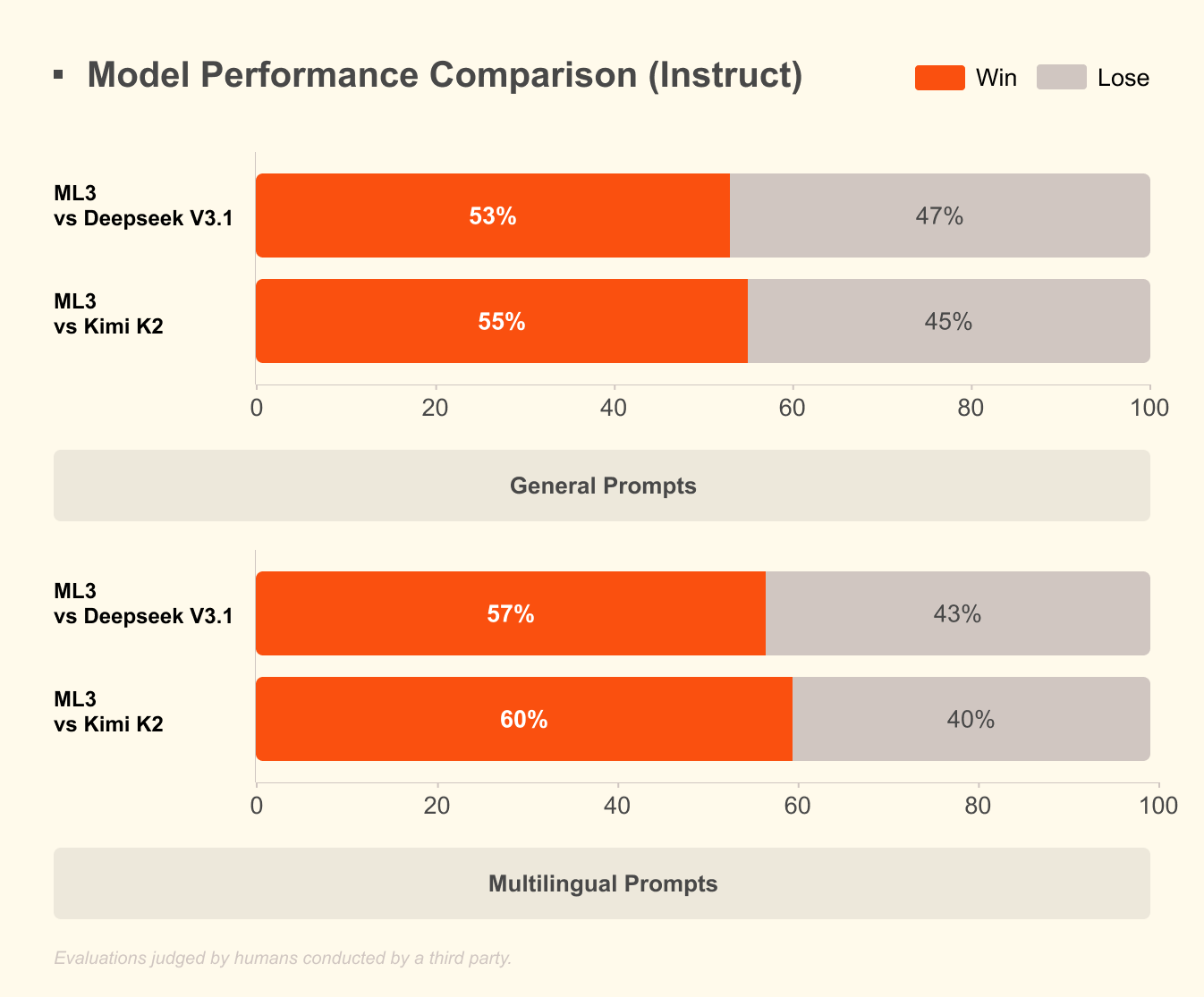
Mistral's announcement says Large 3 debuted second among OSS non-reasoning models on LMArena and sixth among all OSS models. The charts on the announcement page compare Mistral Large 3 with large open models such as DeepSeek 3.1 and Kimi K2. Those comparisons deserve a careful reading. Benchmarks show part of a model's performance, but the quality a team experiences in production depends on prompt type, language, domain, tool use, latency, system-prompt following, and inference cost.
Even with that caution, the release is meaningful. Mistral is not positioning open models as cheap but weak substitutes. Large 3 pushes into frontier-scale open weights. Ministral 3 suggests a path for smaller models to run inside real products. If open models are going to move beyond research checkpoints and hobby projects into enterprise deployment strategies, both axes are needed.
Closed models offer a simple API experience. The provider hides serving, updates, safety policy, routing, and billing. Open models provide more control, but they also shift operational work onto the team adopting them. Teams have to choose quantization formats, serving engines, context lengths, GPU memory layouts, security boundaries, and update policies. That is why the Mistral 3 announcement repeatedly mentions deployment paths such as NVIDIA, vLLM, Red Hat, Hugging Face, Bedrock, Azure Foundry, OpenRouter, Fireworks, and Together AI.
Apache 2.0 is a product message, not just a license
The fact that the full Mistral 3 family is released under Apache 2.0 should be read with the same weight as the technical specifications. The phrase "open model" is often ambiguous. Some models expose weights but restrict commercial use. Some add special conditions for large companies. Some limit derivative distribution. Training data and evaluation procedures may still be closed. Apache 2.0 sends a clearer signal to developers and companies.
The license does not solve every problem. Running a model in production still requires safety evaluation, privacy handling, data location decisions, prompt logging, output review, vulnerability response, and model update governance. But a clear license changes the internal approval path. Legal and security teams can answer the first question, "can this model go into a product?", more quickly. AI infrastructure teams gain room to reduce API dependency and place a model in specific regions, on-prem environments, or controlled cloud accounts.
This is where Mistral 3 connects to the broader open model race. China's Qwen, DeepSeek, Kimi, and Z.ai GLM families are putting pressure on performance and cost. Meta's Llama ecosystem has reach through derivatives and deployment familiarity. Google's Gemma line keeps showing up in small-model and edge contexts. Mistral is layering a European company identity, Apache 2.0 licensing, enterprise custom training, multilingual capability, multimodality, and MoE scale into that field.
For developers, the competition is useful. Teams do not have to depend on one API vendor, and they can choose models around cost and control. The tradeoff is that the design problem gets harder. The old question, "which single model is smartest?", is being replaced by a more architectural one: which model, size, deployment location, and license fit this workload?
Small models are no longer just fallbacks
Ministral 3 matters because smaller models are no longer only fallback options. A 3B, 8B, or 14B model used to read like a compromise for teams that could not afford a large model. That framing is now too narrow. For tasks called millions of times a day, internal documents containing private data, local voice and vision workflows, field environments with weak connectivity, and embedded agent flows, a smaller model can become the primary model.
According to the Hugging Face model card, Ministral 3 14B Instruct supports a 256k context window. It also lists multilingual support including English, French, Spanish, German, Italian, Portuguese, Dutch, Chinese, Japanese, Korean, and Arabic. Native function calling and JSON output are also presented as core features. That is closer to agentic and structured workflow automation than simple chat.
The 24GB VRAM note is especially notable. Mistral says the FP8 instruct version can fit into 24GB of VRAM, with further quantization potentially lowering memory requirements. A 24GB GPU is not universal, but it is realistic for high-end consumer GPUs, workstations, and some internal servers. If a team can run a 14B model with vision and tool calling locally, it does not have to price every experiment as an external API call.
There is still a caveat. Model-card benchmarks are measured under particular conditions. In real products, results change with document length, domain terms, tool schemas, mixed-language input, image quality, latency targets, GPU concurrency, and caching. A small model can lower cost, but if the task is split poorly, it can create more retries and review work than a larger model would have required.
The practical value of Ministral 3 therefore depends less on whether a 14B model beat another model in a benchmark and more on which tasks can be safely pushed down to it. Document classification, support routing, internal codebase summarization, short tool-call planning, image-based inspection, local RAG preprocessing, and structured JSON extraction are plausible candidates. Long reasoning, high-stakes legal or medical judgment, complex code modification, and uncertain research questions still require larger models, stronger verification, or human review.
vLLM and NVFP4 point to the operational reality
The Mistral 3 announcement is as much about serving as it is about model quality. Mistral emphasizes collaboration with vLLM, Red Hat, and NVIDIA. For Large 3, it points to NVFP4 checkpoints and vLLM execution paths. The announcement also discusses running Large 3 efficiently on Blackwell NVL72 systems or on a single 8xA100 or 8xH100 node. NVIDIA support includes TensorRT-LLM and SGLang, Blackwell attention and MoE kernels, prefill/decode disaggregation, and speculative decoding collaboration.
That may look like implementation detail to a general reader. For an AI infrastructure team, it is the launch. Receiving open weights and serving them reliably are different problems. Large MoE models create challenges around memory, networking, token batching, routing, kernel optimization, and failure recovery. Smaller models have their own issues: GPU memory, drivers, context length, concurrent requests, prompt template compatibility, and runtime behavior.
Mistral's emphasis on vLLM is not accidental. vLLM has become close to a default serving layer for open models. Developers can pull a model from Hugging Face, serve it behind an OpenAI-compatible API, and experiment without rewriting the rest of their application stack. The model cards also show vLLM serve commands and OpenAI-style clients.
This changes how model providers compete. The old pitch was "use our API." The new pitch is also "our model runs inside your infrastructure." That matters in finance, public sector, healthcare, manufacturing, defense, and large internal enterprise workflows where data boundaries come before raw intelligence. Mistral 3 is trying to lower that deployment threshold.
The multilingual question is practical, not decorative
Mistral lists multilingual support, including Korean, in the Ministral 3 model card. That is good news for teams outside English-first markets. But a line item for multilingual support is not enough. Products in Korean, Japanese, Arabic, or mixed-language enterprise environments need to handle honorifics, domain vocabulary, English-language code and product names, legal and financial phrasing, OCR noise, policy documents, and search snippets with uneven quality.
A team evaluating Mistral 3 for Korean or other multilingual use should start with its own eval set. The average score on a public benchmark is less important than the model's mistakes on actual customer tickets, internal documents, codebases, product names, policy text, and regulated expressions. If a small model is attached to an agent, function calling and JSON stability need to be evaluated separately. A model can understand the user's language well enough and still fill the wrong tool field.
This is not unique to Mistral 3. Every open model faces the same question when it becomes a product dependency. The important metric is not whether the model can produce one good answer. It is what failure looks like after ten thousand repetitions of the same workflow. Small models can fail quietly: plausible JSON with shifted field meanings, image descriptions that infer unseen details, or long-context instructions dropped near the end of a prompt.
That is why Mistral 3 adoption will depend on evals and observability more than benchmark screenshots. Teams need to define which tasks each model is allowed to handle and route high-cost failures to larger models or human review. Open models increase control, but they also increase responsibility.
The next front in open model competition
Mistral 3 shows that open model competition is splitting into three fronts. The first is frontier-scale open weights. Large 3 pushes closed API providers by making a very large model available outside a purely closed serving path. The second is local and edge models. Ministral 3 gives smaller models a role in repeated product workflows and sensitive workloads. The third is the operating ecosystem: vLLM, NVIDIA kernels, Hugging Face, cloud marketplaces, API routers, and enterprise custom training determine how valuable the model is in practice.
When those fronts converge, model selection changes. Teams no longer choose one model for everything. A frontier model handles complex reasoning and high-risk judgment. A mid-sized model handles everyday automation. A small model handles local preprocessing and repeated calls. Some requests stay on internal servers. Some go to external APIs. Some fall back when cost thresholds are hit. Model strategy becomes part of application architecture.
That is probably why Mistral put Large 3 and Ministral 3 into the same announcement. A large model alone cannot answer the cost and deployment question. A small model alone cannot answer the frontier-capability and brand question. Together, they make the "open AI stack" message more coherent.
What development teams should check now
Regardless of whether a team adopts Mistral 3 immediately, the questions are concrete. Which parts of the workload cannot be sent to an external API? Which of those tasks are small-model candidates? Can the team measure model quality with its own evals rather than relying on public benchmarks? Does the team have GPU capacity, logging, security controls, update procedures, and rollback paths for open model operation?
If the answer is yes, Mistral 3 becomes an interesting option. Apache 2.0 licensing and multiple deployment paths lower the cost of experimentation. Hugging Face and vLLM routes are familiar to teams already operating open models. The small-model family creates a way to move more calls into local or controlled environments while keeping cost under pressure.
If the answer is no, Mistral 3 may become just another checkpoint in a folder. Open models look easy at the download button, but production operation is hard. Once an agent and tool calls are attached, the model is no longer just a text generator. It becomes an actor inside a system. Permissions, audit logs, failure handling, sandboxing, and sensitive data boundaries have to be designed with it.
The real meaning of Mistral 3 is not that open models have fully beaten closed models. That would require more independent reproduction and more production feedback. The more precise reading is that the open model field is now competing on size, license clarity, edge deployment, multimodality, agent features, and serving infrastructure as a single package.
Mistral 3 draws a new baseline for that competition. The next question is not which model is most famous. It is which teams can design a model portfolio that fits their data boundaries and cost structure.