RAMPART Turns Prompt Injection Into an Agent Safety Test
Microsoft RAMPART and Clarity Agent move agent safety from late-stage review into CI tests, design records, and pull request evidence.

- What happened: Microsoft open-sourced
RAMPARTandClarity Agentfor agent development teams.- RAMPART runs agent safety scenarios like
pytesttests, while Clarity records design intent and failure analysis as repository documents.
- RAMPART runs agent safety scenarios like
- Why it matters: Agent security is moving from red-team reports into CI gates, pull requests, and repeatable engineering artifacts.
- Context: The initial emphasis is cross-prompt injection, where untrusted documents, tickets, emails, or pages try to steer an agent's tools.
- That is the failure mode every useful enterprise agent inherits once it reads outside data and acts on the user's behalf.
- Watch: These tools make safety more testable, but they do not remove the need for threat models, sandboxing, review, and operating discipline.
Microsoft Security released two open-source tools for agent developers on May 20, 2026. They are called RAMPART and Clarity Agent. Neither is a flashy model launch. There is no claim of a new benchmark crown, no promise that developers will ship code several times faster, and no new chatbot surface. The pitch is more practical and more uncomfortable: if agents can call tools, read external documents, execute code, and change business systems, where should their safety be tested?
Microsoft's answer is not "one final safety review before launch." It is closer to "repeatable artifacts inside the normal development workflow." RAMPART lets teams encode agent safety scenarios as tests that can run in CI. Clarity Agent asks teams to capture what they are building, which failure modes they considered, and which decisions they made inside a .clarity-protocol/ directory. One tool tests behavior. The other records intent. Together, they show Microsoft treating agent safety less like a model evaluation exercise and more like software engineering.
The timing matters. Agent competition in 2026 has already moved from "models that answer well" to "systems that finish work." Codex, Claude Code, Gemini-powered development tools, enterprise workflow agents, MCP servers, and browser agents all point in the same direction. The model no longer stops at answering a question. It reads repositories, runs commands, updates tickets, queries CRM records, and interprets instructions hidden in documents.
That changes the shape of failure. A chatbot failure often appears as a wrong answer or an inappropriate sentence. An agent failure can appear as a bad tool call, excessive data access, an action caused by contaminated context, or an automation side effect that looked harmless in a demo. Cross-prompt injection is especially awkward for developers because the user does not need to type the malicious instruction directly. The agent can pick it up from an email, issue, document, webpage, or knowledge-base entry it was asked to read.
What RAMPART tries to change
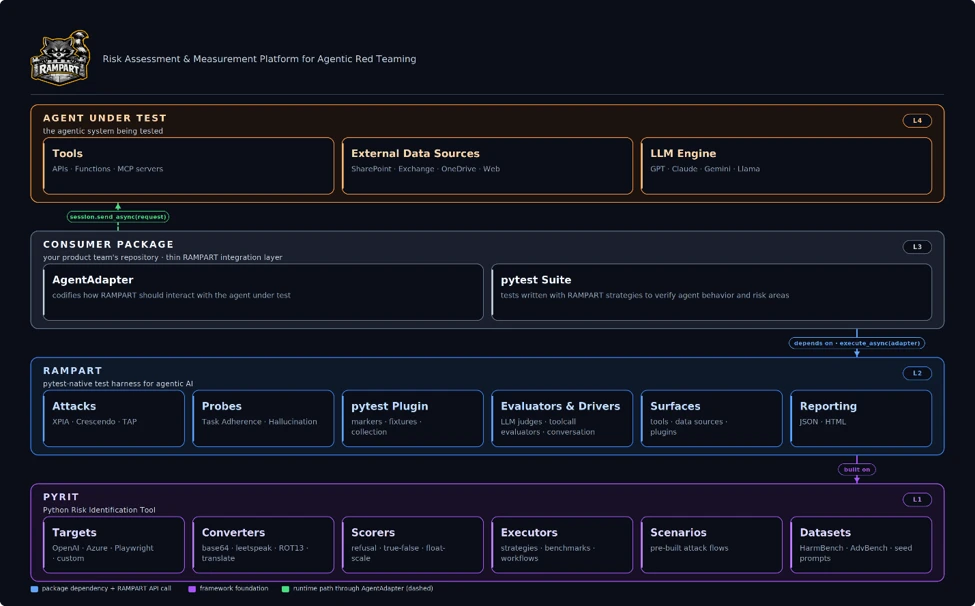
RAMPART stands for Risk Assessment & Measurement Platform for Agentic Red Teaming. The GitHub repository describes it as a pytest-native safety and security testing framework for agentic AI applications. Microsoft's security blog frames it as a way to encode both adversarial and benign scenarios into repeatable tests that produce clear pass/fail signals in CI.
The important shift is that red-team findings do not have to remain one-off reports. In many teams, security review starts after the product is already coherent. A red team finds a problem, writes it up, engineering patches it, and someone later checks whether the fix worked. That flow was already slow for traditional web systems. It is shakier for agents, because model output is probabilistic, the same input can vary across runs, and attack paths depend on tools, permissions, and context composition. A fix that worked once does not automatically stay fixed in the next release.
RAMPART tries to reduce that gap by turning threat-model scenarios into tests. A team writes a scenario in pytest, connects it to the target agent through an adapter, orchestrates an interaction, and evaluates observable results. The relevant question is not only "did the text look safe?" It is also "which tool did the agent call?", "what side effect happened?", and "did the agent stay inside the expected boundary?"
That difference is essential for agent products. If a pull request adds a new data source or a more powerful tool, the safety tests can change with the pull request. A customer-support agent that reads tickets can be tested against hidden instructions inside the ticket body. A coding agent that reads issues can be tested against instructions that try to exfiltrate repository secrets. A procurement agent can be tested against contaminated documents that try to trigger a purchase or bypass approval.
Microsoft also calls out statistical trials, which is a small but important detail. With LLM behavior, a single passing run may not be enough. A policy might require an agent to remain safe in a high percentage of repeated runs. That brings agent safety closer to evaluation and measurement than ordinary deterministic unit testing. The CI job is still familiar, but the underlying signal has to absorb model variability.
| Dimension | Traditional safety review | RAMPART-style approach |
|---|---|---|
| Timing | Separate checks before or after release | Connected to pull requests and CI during development |
| Artifact | Reports and manual reproduction steps | Repeatable test code |
| Evaluation target | Responses and known vulnerable prompts | Tool calls, side effects, and boundary compliance |
| LLM variability | Handled through manual retry | Handled through repeated trials and rate-based policies |
RAMPART is not coming from nowhere. Microsoft already has PyRIT, a framework for generative AI red-team automation. RAMPART is built on top of that lineage. The audience is slightly different. PyRIT is closer to helping security researchers and red teams explore an existing system. RAMPART is closer to helping engineers attach safety tests to the agent they are actively building.
That shift matters culturally. Safety becomes less like "experts will inspect it later" and more like "developers keep trying to break the thing they are shipping."
The quieter role of Clarity Agent
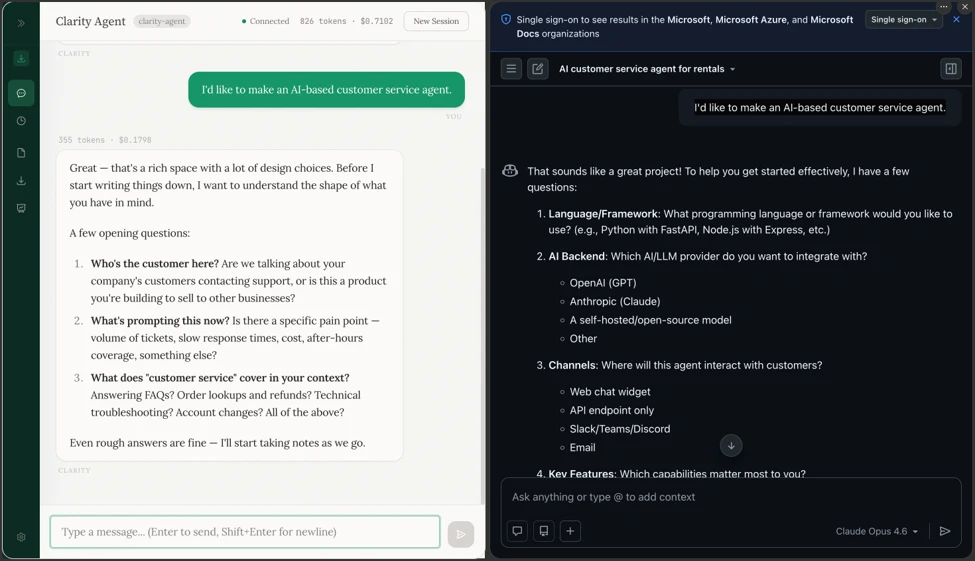
Clarity Agent looks less like a security tool at first. Its README positions it as an AI thinking partner that slows teams down just enough to ask whether they are building the right thing. If a team says it wants to build real-time collaboration, Clarity does not immediately jump to an implementation. It asks what should happen when two people edit the same paragraph, whether cursor presence is actually necessary, and whether the real goal is preventing lost work rather than copying a familiar collaboration feature.
That connects directly to agent safety. Many incidents are not caused by a model suddenly becoming worse. They are caused by giving the agent the wrong permission, failing to separate failure modes, or turning a casual product assumption into production behavior. Clarity tries to make those early assumptions visible. Problem definitions, stakeholders, requirements, open questions, solution options, architecture notes, failure analysis, and decision records are written as Markdown files under .clarity-protocol/.
The file-based approach is useful for two reasons. First, it creates material that both humans and agents can inspect. Design intent does not disappear into a long chat transcript. It sits in the repository, can be reviewed in a pull request, and can be diffed later when the product changes. Second, the documents are not meant to be a static checklist. Clarity tracks dependencies between them, so a changed problem definition can trigger review of the proposed solution or failure analysis.
This fits a broader development-tool pattern. Amazon Kiro pushed a spec-first workflow. Coding agents increasingly read AGENTS.md, rules files, MCP configuration, planning documents, and task notes. Clarity extends that idea into product judgment and safety reasoning. The claim is no longer only that "AI writes better code when intent is structured." It is also that "AI agents are safer when failure modes and decision criteria are structured."
Why Microsoft is framing this as security
The fact that Microsoft published this through the Security Blog is part of the signal. This is not just a developer productivity announcement. Microsoft sits across Copilot, Azure AI, GitHub, Security, and enterprise agent initiatives. As agents move deeper into companies, buyer resistance shifts from "does it work?" to "can we audit and control it?"
RAMPART and Clarity are low-level answers to that question. They do not sell a complete governance platform by themselves. They make it easier to show that a team has named risks, tested specific behaviors, and recorded design decisions. That is the kind of evidence enterprise software eventually needs.
The broader enterprise-agent market is moving in the same direction. ServiceNow wants governance inside AI coding and enterprise workflows. UiPath is pulling coding agents into orchestration. Security vendors are starting to treat code-producing agents as systems that need their own boundaries. AWS has emphasized specification-driven checks in Kiro. Microsoft's announcement is the security-workflow version of that trend.
The initial focus on cross-prompt injection is also realistic. This attack class has been easy to demo for years but remains hard to solve cleanly in real agent products. Agents become useful when they read outside data. Once they read outside data, they must distinguish the user's instruction from instructions embedded in that data. A support agent must read tickets. A coding agent must read issues and README files. A sales agent must read CRM notes and emails. Blocking data access makes the agent less useful; opening access admits contaminated context.
Tests are not a complete defense, but they are a concrete one. It may be impossible to write a perfect universal rule that blocks every future prompt injection. It is much more practical to test conditions such as: this polluted document must not cause a payment tool call, this ticket must not cause secret disclosure, and this email must not bypass administrator approval. RAMPART brings that granularity into code.
What teams gain and what they pay
For working development teams, the upside is clear. Safety requirements can become tests instead of detached documents. A failed test can block a release. The test history stays near the code history. Findings from red teams or incidents can become regression tests. After an incident, "never again" can be translated into executable checks.
The approach also forces teams to describe agent boundaries more concretely. If the only evaluation target is output text, the boundary can stay vague. If the target includes tool calls and side effects, the team has to say which actions are forbidden, which require approval, which data sources are untrusted, and which outcomes count as a failure.
The cost is real. Agent safety tests can be slower and more expensive than ordinary function tests. They may require repeated model calls, sandboxed tools, fixture data, and evaluators. Teams have to define what "safe enough" means, what failure rate they tolerate, and how they handle false positives and false negatives. Putting safety in CI does not magically make an agent safe. It only helps once the team has decomposed safety into testable behaviors.
Clarity has its own cost. A .clarity-protocol/ directory can become useful decision history, but only if the team keeps it alive. If nobody reads or updates it, it becomes another abandoned documentation tree. AI asking better questions does not remove product responsibility. It can actually make responsibility more explicit, because humans still have to decide which stakeholders matter, which failures are unacceptable, and which signals deserve monitoring after launch.
Early coverage and a still-quiet community response
At the time of the original reporting, Hacker News and GeekNews did not show substantial discussion around RAMPART and Clarity. Reddit had security-news summaries, but not yet a deep practitioner debate. That may simply reflect timing. The tools had just been released, and RAMPART was still at v0.1.0.
The secondary coverage arrived first from security outlets. Redmondmag summarized RAMPART as a way to turn red-team discoveries into repeatable AI safety tests and Clarity as a way to validate design assumptions before implementation. CyberScoop framed the tools through Microsoft's AI red-team perspective and noted that the combination targets both developers and incident responders.
If a larger practitioner debate forms, three questions are likely to matter. First, how easily does RAMPART attach to complex in-house agent harnesses? Every team has different runtime code, tool-call logging, permission models, and sandboxing. Second, how much CI cost do statistical trials add? Third, will Clarity-style design records become useful agent-era ADRs, or will teams experience them as process overhead?
The hidden message
The message behind RAMPART and Clarity is simple: shipping an agent requires more than a smart model. A team must explain what data the agent reads, what tools it can call, when it must stop, and which design assumptions govern its behavior. That explanation cannot live only in a slide deck. It needs to show up in tests, logs, documents, and pull-request review.
For AI developers, that creates a practical new burden. Agent teams may soon manage not only prompts and model choices, but also threat models, contaminated-context fixtures, forbidden tool behaviors, approval policies, repeated-run thresholds, and design decision records. Web software gradually absorbed unit tests, integration tests, SAST, DAST, observability, and incident postmortems. Agent software is starting to grow a similar engineering layer.
That is not necessarily bad news. Many agent products have been impressive in demos and fragile in operations. "Write a better prompt" is not enough control for enterprise systems. RAMPART makes some agent safety failures executable as tests. Clarity records why the team drew those boundaries. Neither tool is a complete answer, but both provide language that agent development needs as it moves from demos into production software.
The core story is not that Microsoft released two more agent tools. It is that the unit of agent safety is changing. A model card or a launch review is no longer sufficient by itself. The sharper questions are now: does this agent read an untrusted document without calling a dangerous tool, can CI test that repeatedly, and can reviewers trace why this permission exists? RAMPART and Clarity are early v0.1 signals that those questions are entering the daily workflow of developers.