LiteRT-LM WebGPU brings local agents into the browser
Google LiteRT-LM expands Gemma 4 local inference across Android, iOS, WebGPU, and CLI, changing where AI apps can run.

- What happened: Google expanded
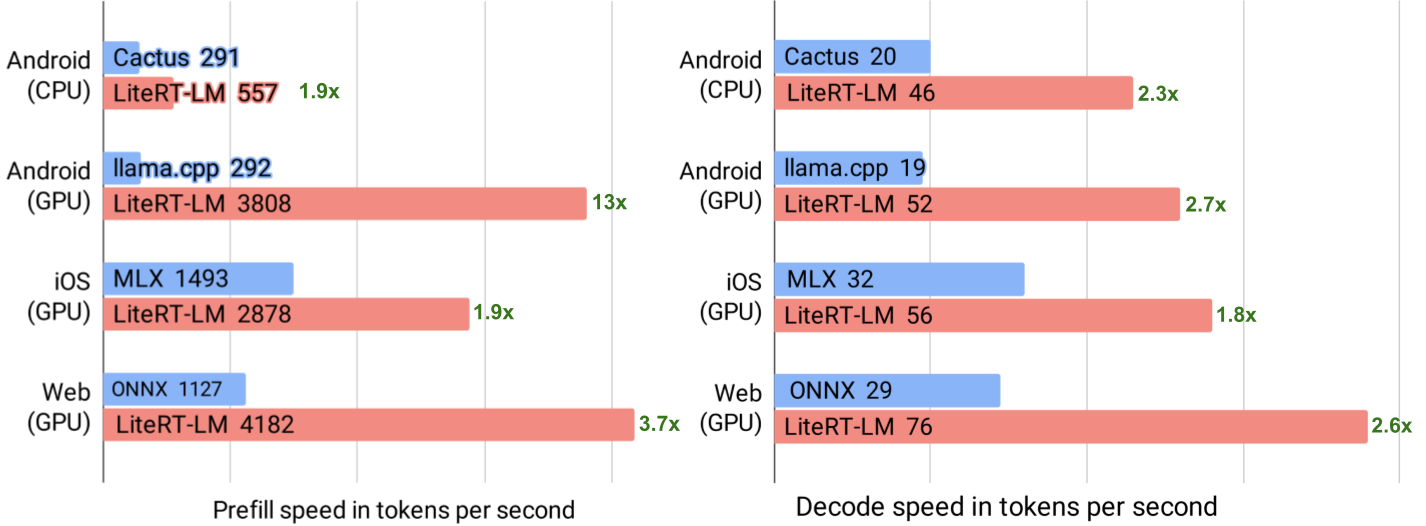
LiteRT-LMso Gemma 4 local inference can run across Android, iOS, WebGPU, and CLI surfaces.- The published figures for Gemma 4 E2B include 52 tokens/sec on Android GPU, 56 tokens/sec on iOS Metal, and up to 76 tokens/sec through WebGPU.
- Why it matters: On-device AI competition is moving from model files alone toward runtime, backend, browser deployment, and agentic I/O.
- Watch: WebGPU performance depends heavily on device and browser conditions, while local tool use still needs a deliberate app permission model.
Google's LiteRT-LM announcement, published on May 19, 2026, looks at first like another on-device LLM performance update. The headline numbers are easy to notice: Gemma 4 E2B reaches 52 tokens/sec on Android GPU, 56 tokens/sec on iOS Metal, and up to 76 tokens/sec on a WebGPU path tested on a MacBook Pro. Google also says the integration of a Multi-Token Prediction drafter can deliver up to a 2.2x speedup.
The more important signal is not the benchmark table. It is the deployment surface. Google is not presenting LiteRT-LM as an Android-only optimization layer. It is placing Android, iOS, the open web, and CLI workflows under one local LLM runtime story. That changes the on-device AI question from "are small models smart enough?" to "where inside a real product can local inference be placed without breaking the user experience?"
Over the past few months, local LLM work has split into two closely related tracks. One track is model capability. Smaller models from families such as Gemma, Llama, Phi, and Qwen keep gaining longer context, stronger reasoning, and better tool-use behavior. The other track is runtime. Layers such as llama.cpp, MLX, ONNX Runtime, WebLLM, Transformers.js, Core ML, MediaPipe, and LiteRT decide whether those models can actually run on the hardware users already own.
This LiteRT-LM update belongs mostly to the second track. Google's message is less "Gemma 4 is good" and more "Gemma 4-class local inference needs a runtime that can move across product surfaces with low latency." That distinction matters for builders. Most AI products do not fail because a demo prompt cannot complete. They fail because inference is too expensive, too slow, too private to send away, too hard to ship across platforms, or too unpredictable on customer devices.
The Bottleneck LiteRT-LM Targets
Cloud LLM APIs are convenient for developers. A product can send a request to a server-side model and get access to frontier quality, large context windows, tool calling, safety layers, logging, and billing infrastructure in one place. The tradeoff is that cost, latency, privacy, and network dependence become permanent parts of the product design.
That tradeoff is especially visible in mobile and browser apps. If every keystroke helper, local search rewrite, command palette suggestion, photo organization task, or lightweight classifier requires a server round trip, the experience can become heavy. In regulated or enterprise settings, the moment user content leaves the device it can trigger legal review, data-processing agreements, regional storage requirements, and security approvals.
On-device LLMs can reduce part of that burden. They can process user context locally, keep working when the network is weak, and handle repeated small inferences without per-call API cost. But local inference brings its own bottlenecks. Models are large. Memory is limited. Battery and thermals matter. Android GPU and NPU paths, iOS Metal and Core ML paths, and browser WebGPU paths all behave differently. If each platform needs a separate model format, quantization path, delegate, streaming implementation, safety wrapper, and function-calling layer, local AI becomes a maintenance problem instead of a feature.
LiteRT-LM is an attempt to absorb more of that complexity into the runtime layer. The official LiteRT-LM documentation describes it as the LLM inference API for Google AI Edge. The announcement frames LiteRT as the layer that handles hardware backend optimization, with Android using OpenCL GPU and NPU routes, iOS using Metal, and the web using WebGPU. For AI app teams, the practical takeaway is simple: choosing a local model is not enough. You also need a runtime that can preserve the same product behavior across many device classes.
| Surface | LiteRT-LM path | Question for builders |
|---|---|---|
| Android | GPU/NPU backend, Google AI Edge app ecosystem | How should device accelerators and app permissions be abstracted? |
| iOS/macOS | Swift API and Metal backend | Where should this sit beside MLX and Core ML paths? |
| Web | JavaScript API and WebGPU | How will model download, caching, permissions, and hardware variance be handled? |
| CLI | Local model evaluation and iteration | How close can product code and local experiment loops become? |
What 76 Tokens Per Second In WebGPU Really Says
The most interesting number in the announcement is the WebGPU result. Google says the web path can reach up to 76 tokens/sec decode on a MacBook Pro. That pushes browser-based LLM inference beyond the familiar demo frame. The browser is already a deployed runtime. Users do not need to install an app, and developers can ship updates through normal web distribution. If local LLM inference can fit into that surface reliably, web apps can move some AI features away from server APIs.
That number still needs careful interpretation. WebGPU performance depends on browser implementation, operating system, GPU, driver, power mode, model quantization, context length, and thermal state. Google's number is a maximum under specific conditions. A lower-end laptop or mobile browser will not necessarily feel the same. Product teams also need to treat model file download and caching as part of the user experience. If first run requires hundreds of megabytes before the feature becomes useful, lower per-token latency may not compensate for a heavy onboarding path.
Even with those caveats, the direction matters. Browser AI has generally fallen into three buckets: calling a server API, using a browser-provided model API such as Chrome built-in AI, or running the model directly over WebGPU through an app-controlled runtime. LiteRT-LM's JavaScript path strengthens the third option inside Google AI Edge. It is not simply a Chrome-only model API. It is a route where the application can manage local inference over WebGPU, a web-standard graphics and compute layer.

For AI product teams, this affects both cost structure and deployment strategy. Features that currently send every request to a cloud model might be split. Private document summarization, form completion, client-side search query rewriting, lightweight classification, local command palettes, and quick routing decisions may not always require a cloud call. The cloud should still own tasks that need current knowledge, long-context synthesis, complex planning, external tool orchestration, or higher reliability. LiteRT-LM is not asking builders to choose local or cloud. It makes a hybrid architecture more realistic.
Runtime Design Matters More Than A 2.2x MTP Claim
Google also says Gemma 4's Multi-Token Prediction drafter is now integrated into LiteRT-LM. MTP is meant to reduce the bottleneck of generating one token at a time. A lightweight drafter proposes future token candidates, and the primary model verifies them. Google presents this path as offering up to a 2.2x speedup.
The interesting detail is that Google does not describe MTP as an isolated speculative decoding trick. The announcement emphasizes running the primary Gemma 4 model and the lightweight MTP drafter on the same hardware IP, such as the GPU, so KV cache and activations can stay in local memory. Moving data across accelerators can create synchronization and transfer costs. In other words, the speedup is not only algorithmic. It depends on model design, runtime scheduling, memory locality, and kernel optimization all lining up.
That is the reality of on-device LLMs. In server GPU environments, many inference improvements can be hidden inside mature frameworks and cluster orchestration. On mobile and web, hardware is far more fragmented, apps run inside OS sandboxes, and the runtime needs to respect a user's thermal and battery budget. The same MTP method can behave very differently depending on where the runtime places the drafter, verifier, KV cache, activation buffers, and fallback paths.
The practical message is not merely "Gemma 4 MTP is fast." It is closer to "local AI runtimes are becoming model-aware schedulers." AI app developers can no longer think only in terms of model and prompt. Streaming latency, context management, tool-call schemas, constrained decoding, local cache behavior, and backend fallback can all affect the perceived quality of the product. LiteRT-LM is Google's attempt to package those layers under a Google AI Edge runtime.
Where Local Agent Behavior Starts
The LiteRT-LM announcement also uses the language of agentic workflows. Google mentions Thinking Mode, constrained decoding, function calling, multimodal input, and multimodal output. That bundle matters. If an on-device LLM only generates chat replies, faster decode is a convenience feature. If the same local model can call app functions, comply with JSON schemas, understand visual context, and handle step-by-step reasoning, a small agent loop starts to live inside the user's device.
Consider a photo app prompt such as "find last week's meeting whiteboards and give them useful titles." A product could narrow candidates locally instead of uploading every photo thumbnail and metadata record to a server. A browser-based document editor could classify paragraphs or suggest small rewrites without sending the open document to an external API. An enterprise mobile app could let a field worker query a checklist while offline, then sync when the network returns.
Local agents, however, require stricter permission design. Function calling does not become safe just because it runs on the device. In some ways, it gets closer to sensitive resources: photos, contacts, calendars, files, browser storage, app databases, and local credentials. Constrained decoding can make output format more stable, but it does not answer which tools the model may call, when the user must approve an action, or how tool results are retained in context. The Google AI Edge Gallery function-calling flow is interesting for that reason. On-device tool use has to be tied to operating system permissions, app sandboxing, and clear user approval surfaces.
User input and local context
LiteRT-LM: streaming, constrained decoding, function calling
Android GPU/NPU, iOS Metal, WebGPU backend
Local response, local tool call, cloud model escalation when needed
The Competitors Are Other Local Runtimes
Comparing LiteRT-LM directly with OpenAI, Anthropic, or Google's own Gemini cloud API only explains part of the story. The more immediate competitive field is local runtime infrastructure. Developers can use llama.cpp for desktop and local server inference, MLX for Apple Silicon applications, WebLLM or Transformers.js for browser inference, and ONNX Runtime, Core ML, ExecuTorch, or MediaPipe for specific deployment targets.
Google's advantage is that it can connect model work, runtime work, Android, Chrome/WebGPU, and AI Edge documentation inside one ecosystem. Gemma 4 models can expose features such as MTP and Thinking Mode. LiteRT-LM can run those models across Android, iOS, and the web. Google AI Edge Gallery can demonstrate function calling and app patterns. This is a kind of vertical integration. It is different from Apple's OS-level push with Foundation Models and Apple Intelligence, Meta's open model and ExecuTorch strategy, or the community's fast experimentation through llama.cpp and MLX.
That strategy also has weaknesses. Depending on a Google runtime can mean inheriting the priorities of Gemma and Google AI Edge. The WebGPU path remains sensitive to browser compatibility and device variation. On iOS, teams still need a clear reason to choose LiteRT-LM over Apple's Core ML, MLX, or Foundation Models routes. On Android, NPU access is not always uniform across devices. The engineering choice is not "which demo is fastest?" It is "which deployment path is predictable enough for the users we have?"
What Product Teams Should Measure Now
Teams that want to bring this announcement into a roadmap should first divide their AI features by workload. Moving every LLM task local is not realistic. Good local candidates are usually short, repeated, privacy-sensitive, less dependent on current external knowledge, and easy to escalate to a server model when uncertainty is high. Legal judgment, complex planning, long-document synthesis, and high-stakes external tool execution still benefit from larger models, server observability, and stronger operational controls.
Second, teams need their own measurement loop. Google's 52, 56, and 76 tokens/sec numbers are a useful starting point, but they do not measure a product's real prompt length, context reuse, streaming UI, model download time, cold start, battery cost, or heat. On the web in particular, model caching and first-run experience are core product concerns. If a user waits through a long download to use a small feature once, the local runtime may be technically elegant and still commercially awkward.
Third, permissions and audit behavior need to be designed early. Local function calling has the advantage that data does not have to leave the device, but it also means the model may initiate real actions on that device. A product team needs to decide which tools are read-only, which tools can write, when confirmation is required, and how long tool outputs remain available to the model. In browsers, that also includes origin boundaries, storage policy, permission prompts, and enterprise controls.
Finally, the architecture should probably be hybrid by default. The next generation of AI apps is unlikely to be a single model call in a single place. A small local model can handle privacy-sensitive routing and quick drafts. A server model can handle difficult reasoning and up-to-date information. A verifier or policy layer may sit between them. LiteRT-LM's significance is not that it replaces the cloud. It adds a stronger local runtime axis to AI product architecture.
A Quiet But Durable Signal
This LiteRT-LM update is not as flashy as a frontier model launch. It does not announce a new chatbot product or claim a benchmark win over every competitor. For AI developers, that may be exactly why it matters. Real AI products do not run on model scoreboards alone. They run inside browsers, phones, batteries, networks, permission prompts, app stores, and update channels.
By expanding LiteRT-LM across Android, iOS, WebGPU, and CLI, Google is pulling local LLMs out of the demo lane and into the deployment problem. The 76 tokens/sec WebGPU result and the 2.2x MTP speedup are useful numbers, but the bigger question is where those numbers can be used. If document editors, mobile enterprise apps, private search, offline assistants, and browser-based developer tools move some inference onto the user's device, the cost and privacy boundaries of AI apps start to shift.
The core takeaway is not "local LLMs beat the cloud." A more practical conclusion is that AI apps no longer have one execution location. LiteRT-LM is Google's attempt to organize that multi-location future through a runtime. Builders should look beyond the size of the benchmark number and ask which decisions in their own product can responsibly move off the server, and which runtime and permission model can carry that responsibility.