Honeycomb Agent Timeline Raises the Bar for Agent Observability
Honeycomb introduced Agent Timeline and Canvas Agent. Operating AI agents now depends less on raw logs and more on reconstructing what happened.
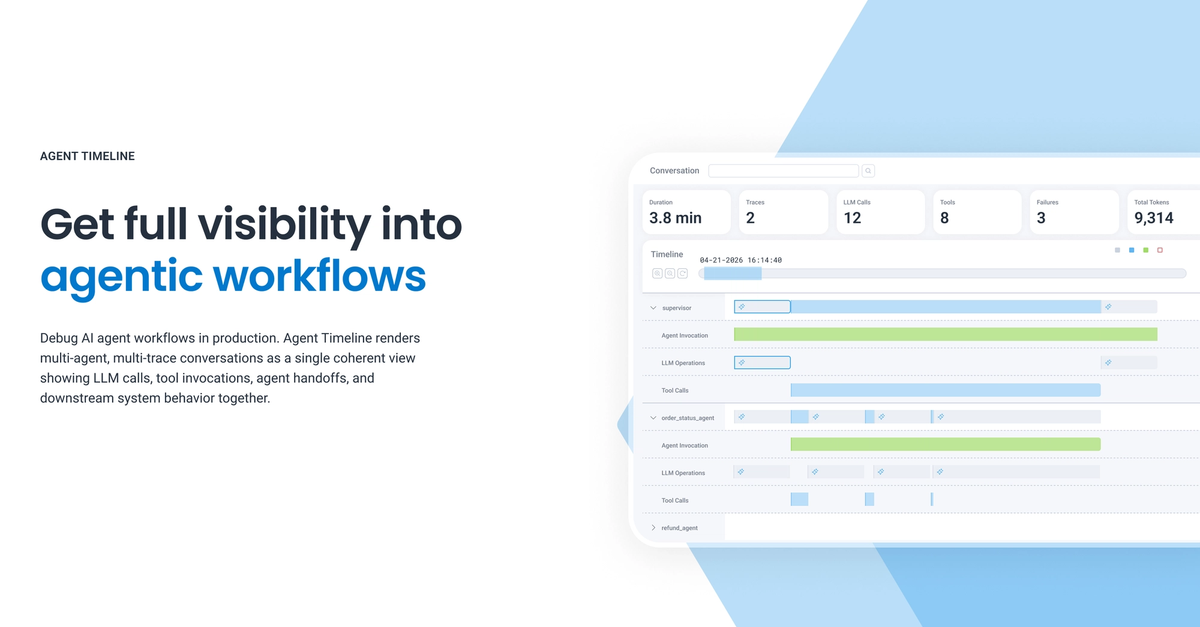
- What happened: Honeycomb announced
Agent Timeline,Canvas Agent, andCanvas Skillson May 12, 2026.- The pitch is an observability surface that reconstructs LLM calls, tool invocations, agent handoffs, and downstream spans as one operational story.
- Why it matters: The operational question is shifting from "did the model answer?" to what did the agent do, and why?
- Watch: Honeycomb highlights
OpenTelemetry GenAIv1.40.0 support, but those semantic conventions are still marked as Development.
Honeycomb announced Agent Timeline, Canvas Agent, and Canvas Skills on May 12, 2026. On the surface, this is a product update from an observability vendor. The more interesting read is that Honeycomb is aiming directly at a gap that appears once AI agents start doing real work inside production systems: conventional APM views and log streams are often poor at explaining what the agent actually decided, executed, and affected.
The AI agent conversation has recently focused on model capability, coding benchmarks, tool calls, and long-running tasks. But once agents move beyond code generation into incident triage, cloud infrastructure deployment, customer service, internal operations, or compliance workflows, the core question changes. "Did the agent produce a plausible answer?" matters less than "what did the agent observe, which tools did it call, which systems did it touch, and why did it move in that order?"
Honeycomb's announcement frames that question as the new observability problem. Agent Timeline is described as a way to render multi-agent, multi-trace workflows in one coherent view, connecting LLM calls, tool invocations, agent handoffs, and downstream system impact in real time. In simpler terms, Honeycomb wants teams to stop reading agent work as a chat transcript or a disconnected list of spans. It wants the operational unit to become the ordered chain of events and consequences.

The broader context is bigger than adding AI features to an observability product. Traditional observability has been built around services, endpoints, traces, metrics, and logs that humans can query. AI agents are not deterministic programs in the same way. The same input can lead to a different plan, tool calls can mutate external systems, and an intermediate judgment becomes part of the context for the next judgment. Average latency or error rate will not explain why an agent proposed the wrong remediation or why it chose different execution paths for the same alert.
Honeycomb states this problem fairly directly. Its release argues that existing software observability tools were not designed for nondeterministic, multi-hop agent workflows; dashboards break down; averages obscure important outliers; and when an agent contributes to an incident, teams often cannot reconstruct what it decided and why. The language is product marketing, but the diagnosis is practical. Agent failures rarely fit cleanly into one HTTP 500 or one exception stack.
Take an incident-response agent. The first step may be receiving an alert. The next steps may be checking recent deploys, querying logs, comparing traces, searching a runbook, updating Slack or Jira, and proposing a feature flag change. In that workflow, it is not enough to know whether each API call returned a 200. The team needs to know which hypothesis the agent formed, what data it inspected to test that hypothesis, which tool result changed the next action, and where a human approved or rejected the plan. That is the empty space Agent Timeline is trying to occupy.
| Observation target | Common unit in traditional APM | Unit needed for agent operations |
|---|---|---|
| Execution flow | Service-level traces and spans | A timeline of prompts, tool calls, handoffs, and downstream impact |
| Failure cause | Exceptions, latency, and error rate | Bad hypotheses, missing context, risky tool choices, and broken approval boundaries |
| Improvement loop | Alert tuning and dashboard refinement | Turning failed trajectories into eval cases, runbooks, and policy updates |
The second pillar in the announcement is Canvas. Honeycomb describes Canvas as a collaborative workspace that combines a chat interface, visual investigation, and an autonomous agent. Users can ask questions in natural language, work with people and agents in the same investigation space, and produce shareable visualization snapshots. The important word is "workspace," not "chat." A chat box attached to an observability product does not automatically solve production debugging. Queries, charts, traces, hypotheses, refutations, and conclusions need to stay in the same context.
Canvas Agent and Auto-investigations push that idea further. Honeycomb says that when an alert fires, an SLO burn appears, or an anomaly is detected, Canvas Agent can gather data, generate hypotheses, test them, and suggest remediation before a human opens a laptop. That is attractive for operations teams because early investigation is often slow and repetitive. It is also risky. A confident but wrong automated hypothesis can anchor a team on one explanation while other causes receive less attention.
That is why Canvas Skills matter. Honeycomb positions Skills as a way to encode a senior engineer's debugging knowledge and best practices for frameworks or services such as Kafka into reusable playbooks. This is more than a prompt template. If an agent is interpreting production telemetry, it needs domain-specific rules about what to inspect first, which metric combinations are suspicious, and which remediations require human approval. From a product strategy perspective, Honeycomb is trying to move from storing observability data to helping execute the investigation process.
Honeycomb is not alone in seeing this market. Datadog, New Relic, Grafana-adjacent tools, LangSmith, Langfuse, Arize Phoenix, Helicone, and others already cover pieces of LLM tracing, prompt and version tracking, evaluation, cost analysis, and latency analysis. The difference is the center of gravity. LLM application tools often start with prompts, model calls, evals, and datasets. Traditional APM vendors tend to add LLM workloads on top of existing traces and metrics. Honeycomb's message here is closer to tying production telemetry and the agent's reasoning trail into the same investigation flow.
This is where OpenTelemetry enters the story. Honeycomb says it has integrated OpenTelemetry GenAI semantic conventions v1.40.0 and treats gen_ai.* attributes as first-class citizens in the platform. That is a small sentence with large implications. If agent observability stays trapped in vendor SDKs and proprietary schemas, teams will have to re-instrument systems when they change agent frameworks or observability backends. If instrumentation lands on OpenTelemetry conventions, the collection layer has a better chance of surviving tool changes while analysis surfaces evolve.
There is an important caveat. OpenTelemetry's GenAI semantic conventions are currently marked as Development. The documentation also warns that instrumentation using conventions from v1.36.0 or earlier should not immediately change the default emitted version, and that teams wanting the latest experimental conventions should use an opt-in path such as OTEL_SEMCONV_STABILITY_OPT_IN. The market may be moving toward a standard, but this should not be read as a fully stabilized one.
OpenTelemetry's 2025 writing on AI agent observability points in the same direction. It distinguishes between AI agent applications and AI agent frameworks, then argues that standardized metrics, traces, and logs make integration and comparison easier. It also notes a tradeoff: when frameworks provide baked-in instrumentation, adoption becomes easier, but teams can be stuck with outdated OpenTelemetry dependencies or vendor-specific conventions. Honeycomb's announcement is a sign that this standards conversation is moving into product competition.
For builders, the useful question is not simply "should we buy Honeycomb?" A better question is "can we reconstruct an agent failure when it happens?" Minimum viable telemetry for a production agent is not just model name, input tokens, output tokens, latency, and cost. Teams also need prompt template version, retrieved context, selected tool, tool input and output, external side effects, human approvals, policy decisions, retry reasons, handoff targets, and downstream trace links. Without those, a failure remains a story people tell from memory instead of an artifact that can become an eval case or a runbook update.
Sensitive data is the other operational constraint. Good agent observability creates pressure to store prompts, completions, tool results, and parts of retrieved documents. Those fields may contain customer data, internal code, security tokens, production logs, or incident details. OpenTelemetry can help normalize the schema, but it does not decide what should be collected, redacted, retained, or deleted. A team that improves observability by expanding the blast radius of sensitive data will lose trust quickly.
At this point, agent observability becomes a security and governance concern. If an agent can call tools that change a real system, a trace is not just debugging evidence. It is also an audit record. Teams need to know who launched the agent, which permissions were used, what evidence supported a proposed change, where humans approved the action, and whether autonomous execution stayed inside policy boundaries. Honeycomb's announcement is not a security product launch, but a surface like Agent Timeline becomes a prerequisite for that kind of auditability.
Community response has not yet concentrated into one large public thread. The prior Honeycomb observability and AI discussion on GeekNews summarized the direction as one where LLMs make analysis more accessible, OpenTelemetry normalizes instrumentation, and the core value of observability moves toward faster feedback loops. In Reddit and observability circles, the repeated theme is that agent observability cannot stop at LLM tracing. It needs state transitions, parent-child spans, tool call results, and portable incident artifacts. Honeycomb's announcement shows that those ideas are turning into a market with product names and pricing pages.
There are reasons to stay critical. First, automated investigation tends to look better in demos than in messy production systems. False positives and stale context are common, and a plausible early explanation can narrow the team's search too quickly. Second, because OpenTelemetry GenAI conventions are still in Development, version compatibility and attribute interpretation will remain moving targets. Third, vendor-provided AI investigation surfaces are convenient, but data and workflow may become strongly tied to the product's internal representation. "Uses a standard" and "fully portable" are not the same claim.
Even with those caveats, the direction is clear. As AI agents move from side tools into active development and operations roles, observability changes from dashboards for humans into an event record that humans and agents can both use. The first generation of LLM observability was often about which model answered, how much it cost, and how quickly it responded. The next phase is about which chain of actions produced which outcome. In that sense, the name Agent Timeline is precise: the thing being observed is no longer a single call, but behavior over time.
Teams can start preparing now. Identify every point in the agent workflow where side effects happen: file edits, deploys, ticket creation, customer replies, permission changes, data deletion, feature flag changes, or database writes. Those actions need traces and approval boundaries. Next, evaluate agent frameworks and observability vendors for OpenTelemetry compatibility, but read the fine print on GenAI convention versions. Finally, build a loop that turns failures into eval datasets, runbook updates, and policy changes. Observability creates value when it changes the next execution, not when it merely records the last one.
Honeycomb has not answered every question. Agent Timeline is in Early Access, and the Canvas family of features is being rolled out to customers after the announcement. The real test will come in long incident investigations, multi-agent handoffs, sensitive data redaction, large trace volumes, and convention changes from OpenTelemetry. Still, the news is meaningful. The competition in agent-era observability is moving beyond model-call logs and into reconstructing production AI behavior accurately enough to debug, audit, and improve it.