Honeycomb moves AI agent observability into the operations layer
Honeycomb Agent Timeline shows how AI agent operations are shifting from model quality alone to traces, cost, policy evidence, and runtime accountability.

- What happened: Honeycomb announced an AI agent observability suite built around
Agent Timeline, Canvas Agent, and Canvas Skills.- The announcement landed on May 12, 2026. Agent Timeline is in Early Access, while the Canvas features were described as rolling out to customers the following week.
- The shift: The product ties LLM calls, tool invocations, agent handoffs, and downstream service traces back to a conversation-level view.
- Honeycomb says it treats OpenTelemetry GenAI semantic convention v1.40.0
gen_ai.*attributes as first-class telemetry.
- Honeycomb says it treats OpenTelemetry GenAI semantic convention v1.40.0
- Why it matters: The bottleneck for production agents is moving from smarter models to evidence about cost, failure paths, permissions, and policy behavior.
- Watch: OpenTelemetry GenAI conventions are still in Development, so teams need schema versioning and raw span retention if they want to avoid vendor lock-in.
Honeycomb announced a bundle of AI agent observability features on May 12, 2026. At first glance, it looks like another product update from an observability vendor. The more interesting reading is that it captures a broader change in the AI agent market. The center of gravity is moving from "which model writes more code" to "can an engineering team explain what an agent actually did in production?"
The official announcement is organized around three features. Agent Timeline renders multiple agents and multiple traces into a coherent view. Canvas Agent starts investigations when alerts, SLO burn, or anomalies appear. Canvas Skills turns a team's debugging knowledge and service-specific runbooks into reusable playbooks. Honeycomb frames the combination as a way for engineering teams to see what AI agents are doing in real time without committing to a proprietary SDK or one specific agent framework.
This story matters because it is not just one Honeycomb launch. IBM Instana announced a public preview for AI Agent and LLM Observability on May 5. OpenTelemetry is separating agent spans, model spans, metrics, events, exceptions, and MCP conventions inside its GenAI semantic conventions. A governance telemetry paper posted to arXiv in April goes further and proposes a telemetry plane that can detect and block policy violations as agent systems run. The direction is consistent: putting AI agents into production requires more than extra logs. Their decision paths have to become first-class operational data.
Why traditional APM is not enough
Traditional APM is built around requests, services, databases, queues, and infrastructure signals. It is very good at answering questions such as whether an HTTP endpoint became slower, whether the error rate rose, or which downstream dependency consumed time inside a request. That model fits deterministic software reasonably well. The same input usually follows the same code path, and failures tend to leave stack traces or error logs.
AI agents behave differently. A single user request can trigger LLM calls, tool calls, memory reads and writes, search, handoffs to another agent, external API actions, permission checks, retries, and evaluation loops. The same request can follow a different path depending on model output and environment state. Failure does not always look like an exception. The agent may choose the wrong tool, resend a large context window every turn, work around a permission denial through an expensive path, or write hallucinated state into memory.
Honeycomb's announcement says existing tools were not designed for nondeterministic, multi-hop agent workflows. Dashboards break down, averages hide the useful details, and when an agent creates an incident, teams cannot easily reconstruct what it decided or why. That is more than marketing copy. The hardest production agent problem is often not "it did not work." It is "we cannot explain where it started going wrong."
Agent Timeline focuses on conversations, not requests
The important point in Agent Timeline is not just that traces get a nicer interface. Honeycomb says Agent Timeline connects LLM calls, tool invocations, agent handoffs, and downstream system impact in real time. The key unit is the conversation ID. A normal web request ID is not enough to represent an agent workflow. An agent may call several tools inside one request, continue asynchronously, hand work to another agent, and mix downstream service traces with LLM spans.
Honeycomb's Innovation Week Day 2 post demonstrates the difference. A support team provides one conversation ID, and Agent Timeline summarizes duration, tool calls, failures, and tokens consumed. The investigation then narrows toward a check_shipping connection error and a shipping service problem. The trace waterfall below the timeline pulls in non-GenAI services called by the agent, putting the full stack in one view. In other words, "the model gave an odd answer" and "the shipping service is down" are not separate incidents. They are part of the same operational event.
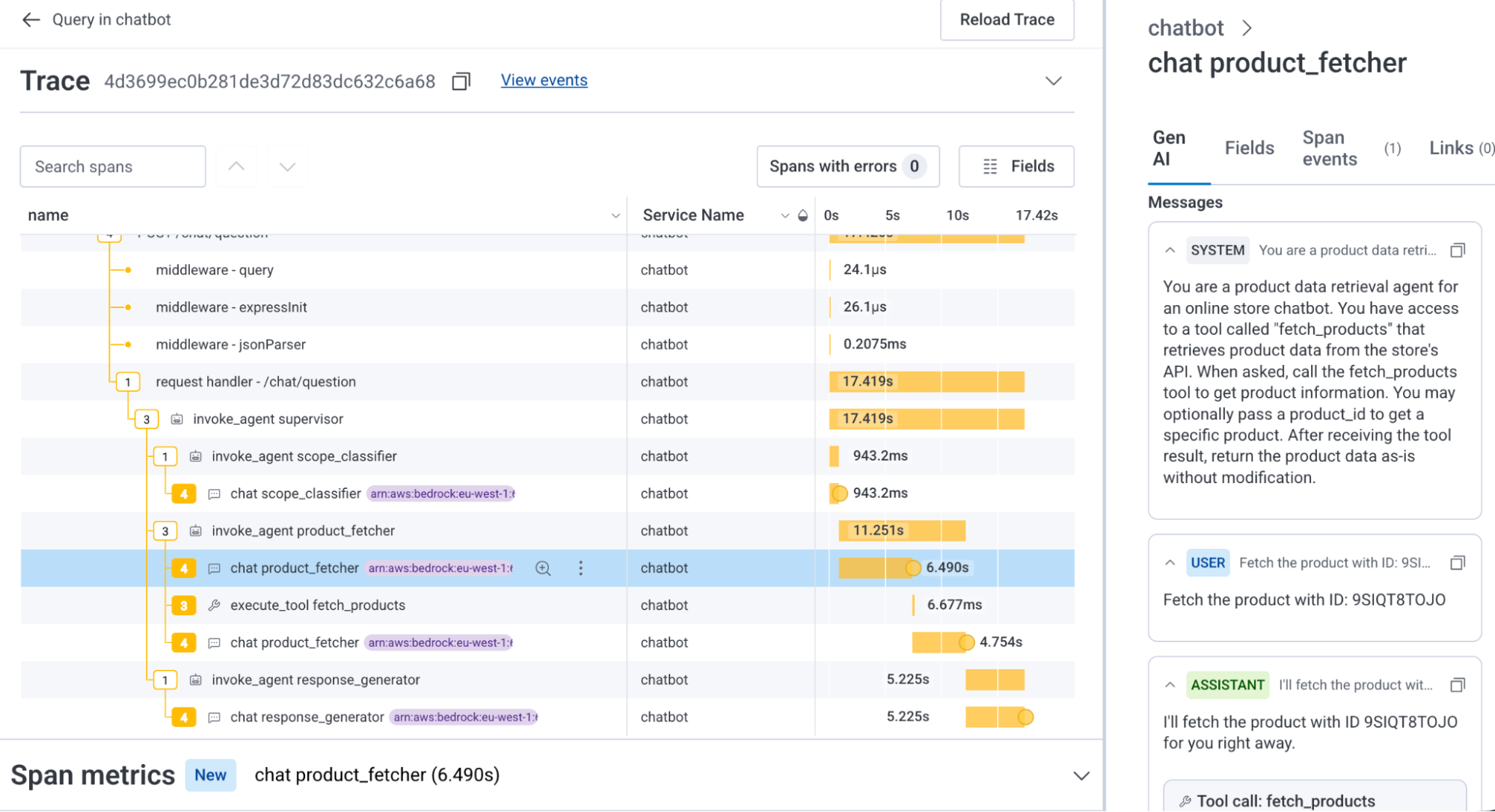
That framing changes the boundary between AI product teams and platform teams. Many LLM observability tools have focused on prompts, completions, tokens, latency, and evaluation scores. Traditional APM looks at API latency and database queries. Once agents start operating real systems, the two views cannot stay separate. A failed tool call may be a permissions, schema, network, or data freshness issue rather than a model quality issue. Conversely, a downstream API can be healthy while an agent explodes cost and latency by injecting the same 145K-token context every turn.
Can OpenTelemetry become the shared language?
The other important part of Honeycomb's positioning is OpenTelemetry. The announcement says Honeycomb integrated OpenTelemetry GenAI semantic conventions v1.40.0 and makes gen_ai.* attributes first-class citizens in the platform. That means model evaluations, tool executions, MCP calls, LLMs, and agents are all treated as observable parts of the system.
OpenTelemetry's current GenAI semantic convention documentation is still marked Development in the v1.41.0 docs. The project also describes a transition plan for existing GenAI instrumentation that emits conventions from v1.36.0 or earlier, and it points teams to opt in to newer experimental conventions with environment variables such as OTEL_SEMCONV_STABILITY_OPT_IN. The documentation splits Generative AI operations into events, exceptions, metrics, model spans, and agent spans, with separate conventions for technologies such as Anthropic, Azure AI Inference, AWS Bedrock, OpenAI, and MCP.
That creates a practical tension. Vendors want to say they are built on open standards. Users do not want to be trapped in a vendor SDK. But while the conventions are still moving, attribute names, span structures, and event payloads can change. The immediate job for teams is therefore not simply picking a vendor UI. They need to decide how much raw trace data to retain, how to record schema versions, and which IDs connect agent runtime events with product telemetry.
Honeycomb's implementation guidance treats this realistically. In a Pydantic AI example, it recommends adding at least gen_ai.conversation.id, gen_ai.agent.name, and gen_ai.operation.name to agentic spans. It also suggests putting OpenTelemetry instrumentation guidance directly into agent context files such as CLAUDE.md and AGENT.md. That detail matters. In an era where agents write production code, instrumentation should not be a later cleanup task performed by humans. It should become part of the default quality bar for code generated by agents.
Cost observability is operational observability
Token cost in AI agent systems cannot live only in a separate FinOps dashboard. Cost is a consequence of behavior. To explain it, teams need to know which agent called which tool, which memory was repeatedly included, and which prompt override caused the context size to grow. Honeycomb's Day 2 demo makes this point directly: in a customer service chat agent scenario, 88 conversations exceeded 80,000 tokens, the order status agent consumed 79% of total tokens, and the root cause was a runaway loop around check_shipping.
This kind of incident is not just "the bill went up." It can increase customer response latency, hit LLM rate limits, load downstream services, raise operating cost, and increase the chance of a bad answer at the same time. Token spend needs to be an attribute in the trace, not just a line item on an invoice. Root cause analysis requires knowing which conversation, which agent, which tool call, which model, and which input/output token counts produced the spike.
Honeycomb's pairing of heatmaps and span duration points in the same direction. Expensive calls are often slow calls. Slow calls can trigger retries. Retries produce more cost. Averages hide this path. In multi-agent systems, a small inefficiency in one agent can get amplified through handoffs. For an operations team, "model spend increased this month" is far less useful than "after last Tuesday's system prompt override, the order status agent started reinserting a tool result on every turn."
Canvas Agent and Skills show where observability is going
Canvas Agent and Canvas Skills extend observability from "seeing" toward "investigating." Honeycomb says auto-investigations gather data, form hypotheses, and suggest remediation when alerts, SLO burn, or anomalies appear. Canvas Skills turns debugging knowledge, framework conventions, and service best practices into autonomous playbooks.
This is a familiar engineering organization problem reframed for AI agents. Good SREs and senior engineers do not read dashboards in isolation. They consider recent deploys, traffic shape, feature flags, dependency status, previous incidents, and the team's unwritten knowledge. Canvas Skills is an attempt to store that knowledge as reusable operational behavior.
There is a caution embedded in that approach. If an observability agent can suggest remediation or create triggers, the observability agent itself becomes part of the system that must be observed. Teams need records of what data it accessed, which hypotheses it rejected, which playbook it applied, and which permission it used to create an alert rule. "Agents watching agents" can make operations more powerful, but it also raises the standard for accountability.
The market is moving from LLMOps to AgentOps
IBM Instana's announcement points in the same direction. IBM says its AI Agent and LLM Observability feature can automatically discover AI components, map agents, workflows, LLMs, and service dependencies end to end, and provide output quality evaluation and drift detection. Honeycomb emphasizes OpenTelemetry and high-cardinality trace analysis. IBM leans harder into enterprise AI operations and business context.
| Axis | Honeycomb | IBM Instana | OpenTelemetry and research |
|---|---|---|---|
| Primary unit | Conversation ID and trace | AI component and dependency map | Agent span, model span, MCP signal |
| Emphasis | High-dimensional traces and unknown unknowns | Operational understanding, quality evaluation, business context | Shared schema and policy enforcement |
| Practical question | Why did this agent take this path? | Where is the AI system connected? | Which telemetry should be standardized? |
Langfuse, Datadog, New Relic, Dynatrace, Arize, and Phoenix are also approaching this territory from LLM observability, APM, or evaluation workflows. The durable differentiator is unlikely to be "we show prompts and completions." What matters is how naturally a platform can connect model spans, service traces, permission events, evaluation results, and business outcomes when agents act on real systems.
The GAAT paper posted to arXiv in April pushes this idea further. It argues that tools such as OpenTelemetry and Langfuse collect telemetry but treat governance as downstream analytics. That creates an observe-but-do-not-act gap where policy violations are noticed only after damage occurs. The proposed architecture combines an OpenTelemetry-based Governance Telemetry Schema, an OPA-compatible policy engine, a Governance Enforcement Bus, and a Trusted Telemetry Plane with cryptographic provenance. It is not a mainstream product feature yet, but it shows how observability could evolve from seeing agent behavior to enforcing policy during execution.
Defaults engineering teams should change now
The practical conclusion is not that every team must immediately buy Honeycomb. The stronger conclusion is that agent instrumentation cannot be postponed. If an AI agent touches customer data, payments, deployments, infrastructure, internal tickets, or code repositories, telemetry is not decoration added after launch. It is a product requirement.
A minimum baseline is straightforward. First, every task or conversation needs a stable ID. Second, agent name, operation name, model, provider, prompt version, tool name, permission result, token count, latency, and evaluation result should be connected inside the same trace. Third, memory reads, memory writes, and external actions should be auditable events. Fourth, teams should record schema versions so their data remains interpretable as OpenTelemetry GenAI conventions evolve.
User request or operational alert
Connect agent spans and model spans with a conversation ID
Record tool calls, MCP calls, permissions, and memory events
Combine downstream traces, token cost, eval score, and business outcome
The same baseline applies to coding agents. As Codex, Claude Code, Cursor, and similar tools generate more production code, it will become more natural to put rules such as "new agentic workflows must emit OpenTelemetry spans" into AGENTS.md or CLAUDE.md. Honeycomb's own Agent Skills for AI Coding Assistants fit this pattern. The company provides skills and MCP guidance so an AI assistant can understand production debugging, OpenTelemetry instrumentation, and Honeycomb usage while it works.
Observability is a lower layer of AI safety
AI safety discussions often start with alignment, jailbreaks, and red teaming. In production systems, there is a lower layer of safety that has to exist first. Teams need to know who asked for an action, which tools an agent invoked, what data it accessed, how it routed around failures, where cost increased, and when a policy violation might have emerged. Without that evidence, incident response cannot even begin.
Honeycomb's launch is a productized example of that lower layer. As agents become more autonomous, teams will ask for more control points. A kill switch alone is not enough. Before pressing it, operators need to know what happened. After pressing it, they need to know which customer requests and workflows were interrupted. Observability becomes the shared prerequisite for governance, security, cost management, and quality evaluation.
The market is still early. OpenTelemetry GenAI conventions are in Development, vendors have different span structures and UI models, and standards for agent memory or multi-agent handoffs are harder still. A trace also does not fully answer the question of "why." In environments where model chain-of-thought is not exposed, teams still need to decide how much decision context can be recorded. The right near-term discipline is not believing every promise of autonomous operations. It is leaving an evidence trail that makes later investigation possible.
Conclusion
Honeycomb Agent Observability is a signal that AI agents are becoming part of production software. In the demos, agents handle support workflows, connect to shipping services, consume tokens, fall into tool loops, and suffer from system prompt regressions. That is no longer just a chatbot log problem. It is an operations problem.
The maturity of AI agent platforms will become harder to judge from model benchmarks alone. A good agent runtime is not one that pretends failure will not happen. It is one that can reconstruct the failure path, calculate cost and impact, and provide evidence for policy behavior when something goes wrong. Honeycomb, IBM, OpenTelemetry, and agent telemetry research are moving in the same direction because that layer is becoming unavoidable.
The question for AI teams is simple: when an agent accessed customer data and called an external API yesterday, can you explain the reason, path, cost, and result in one operational view? If not, the next bottleneck is not the model. It is operational evidence.