Agent Timeline Turns Agent Failures Into Traceable Evidence
Honeycomb Agent Observability tries to reconstruct LLM calls, tool use, agent handoffs, and downstream systems as one traceable production event.

- What happened: Honeycomb introduced
Agent Timeline, Canvas Agent, and Canvas Skills for production agent observability.- The announcement landed on May 12, 2026, while O11yCon 2026 on May 20-21 put "agent era" operations at the center of the program.
- Key shift: LLM calls, tool invocations, agent handoffs, and downstream API behavior are being rebuilt as one ordered timeline.
- Builder impact: Debugging agents depends less on average latency charts and more on
gen_ai.*spans that can replay the path to failure.- Honeycomb says it integrated OpenTelemetry GenAI semantic conventions v1.40.0, but those conventions are still moving.
- Watch: Agent Timeline is in Early Access, so teams should evaluate vendor behavior, data redaction, retention, and standard stability together.
Honeycomb's May 12 announcement of Agent Observability can look like a natural product expansion from an observability vendor. It is more useful to read it as a sign that production AI agents are forcing a new operational question. Once a team connects an agent to real work, it is no longer enough to ask whether the model gave a good answer. The harder question is which model call chose which tool, what that tool saw in an API or database, how that result changed the next step, and why another agent inherited a different state.
Honeycomb's answer is to make that question a timeline problem rather than a dashboard problem. The Agent Timeline product page describes a coherent view across multi-agent and multi-trace conversations. That view combines LLM calls, tool invocations, agent handoffs, and downstream system behavior. Traditional distributed tracing reconstructed the route from service A to service B. Agent Timeline tries to place the agent's conversation flow and tool choices on top of that route.
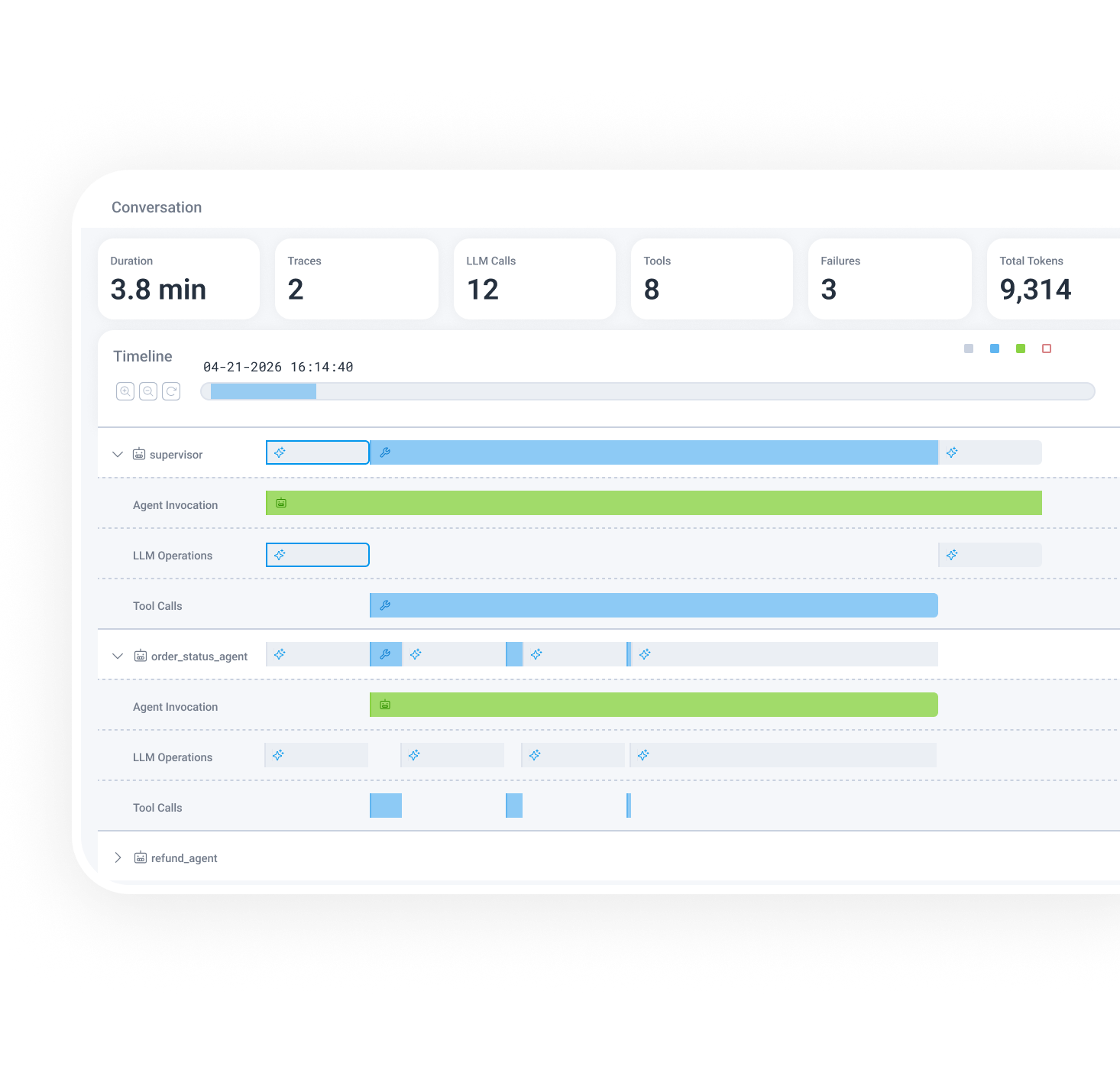
The distinction matters. In a conventional backend incident, an HTTP 500, database timeout, queue backlog, or p95 latency spike is often close to the center of the event. In an agent incident, the visible failure can arrive much later, or never appear as a clean exception. Imagine a customer-support agent calling an order lookup tool twice, masking a partial failure through natural-language reasoning, and then handing a wrong state to another agent. The final API response may still be 200. Average latency may look normal. The user still receives the wrong guidance. What the team needs in that moment is not another aggregate chart. It needs a reconstruction of the decision path.
Honeycomb's release points directly at that gap. The company argues that AI agents are moving into code generation, incident triage, cloud infrastructure deployment, and customer service, while existing observability tools were not designed for nondeterministic, multi-hop agent workflows. The marketing phrasing is sharp: dashboards break down, averages mislead, and when an agent triggers an incident, teams often cannot reconstruct what it decided or why. Strip away the launch language and the practical diagnosis remains. Agent failures do not always behave like ordinary service failures.
What Agent Timeline Treats as an Event
In Honeycomb's framing, the core object is not a single span. It is an agent conversation. A user can start from a conversation ID and see total duration, model-call count, tool-call count, retries, involved agents, and failures at a summary level. From there, the team can drill into spans for LLM operations, tool calls, token usage, prompt details, and then further down into API calls, database queries, and infrastructure behavior.
| Observation unit | Traditional service observability | Agent observability |
|---|---|---|
| Starting point | Request, deployment, service call | Conversation, task, agent run |
| Intermediate event | HTTP span, database query, queue message | LLM call, tool invocation, retry, handoff |
| Failure signal | Error rate, timeout, saturation | Bad tool choice, hidden partial failure, downstream impact |
| Standardization axis | OpenTelemetry trace, metric, log | gen_ai.*, agent span, MCP conventions |
The important point is not only Honeycomb's interface. It is the claim that agent observability needs its own event model rather than a thin overlay on service traces. An agent can call the same tool several times inside one task, reinterpret a failed result in language, and pass an intermediate judgment to another agent. A trace for one request is useful, but it is not enough by itself. Teams need to see how one piece of work moved across model, tool, and system boundaries.
The features Honeycomb highlights match that structure. Horizontal swim lanes show parallel execution and handoffs. Conversation-level failure counts and failing-span highlights make failure a first-class object instead of a footnote. A mode such as "Show Failures Only" sounds like a simple filter, but it is practical for multi-agent systems. Normal spans can be noisy, and failure can be scattered across retries, fallbacks, and bad context transfer rather than concentrated in one stack trace.
Why OpenTelemetry Quietly Matters
The most operationally important sentence in the announcement is Honeycomb's claim that it integrated OpenTelemetry GenAI semantic conventions v1.40.0 and treats gen_ai.* attributes as first-class citizens. OpenTelemetry's GenAI semantic conventions are still marked as Development, but the scope is already broad: GenAI events, exceptions, metrics, model spans, agent and framework spans, and MCP conventions are defined as related areas.
That structure is a signal about the agent observability market. For a while, LLM application observability has been SDK-led. Use LangChain and you may inspect LangSmith. Use a particular gateway and you may inspect that provider's dashboard. Use a particular agent framework and you may read that framework's run log. That can be enough during experimentation. It becomes fragile in production, where an agent may combine a model provider, vector store, MCP server, internal API, queue, database, and browser automation. If telemetry is split by framework, incident reconstruction returns to manual work.
OpenTelemetry is not a complete answer, but it can become a shared language. If gen_ai.* attributes grow from model calls and token usage into agent spans, tool execution, and MCP connections, teams will not have to translate every vendor-specific event by hand. That is the context for Honeycomb's promise of visibility without proprietary SDK or framework lock-in. The actual lock-in reduction still depends on implementation details, but putting standard spans at the front of the product is the right direction.
User request or automated task
Agent span: planning, model calls, tool choice, retry
System span: API, database, queue, infrastructure state
Conversation timeline: failure and decision-path reconstruction
The caution in OpenTelemetry's documentation is also worth reading closely. It advises existing instrumentation not to change the default emission version abruptly, and points to opt-in paths for newer experimental conventions. When a standard is still developing, the dangerous failure mode is operational data changing shape too often under the banner of standardization. AI observability data is already sensitive and complex: prompts, completions, token counts, tool results, exceptions, policy decisions, and retrieval context can all appear. Standardization is necessary, but unstable standardization can become its own production risk.
Why Agent Failures Escape Averages
Honeycomb cofounder Charity Majors wrote in March that anomaly detection is not only about finding anomalies; the harder question is deciding which anomalies matter. That framing maps neatly onto agents. The boundary between normal and abnormal is not simple. A model calling a tool three times instead of five is not automatically a failure. A three-second delay is not automatically a failure. The real issue is whether latency, retries, user state, tool response, and prompt branch combined into a wrong action.
Ordinary APM dashboards are good at averages, percentiles, and error rates. Important agent events are often hidden in high-dimensional combinations. The same model, tool, and API can behave differently when retrieval results change, a tool schema shifts slightly, or an MCP server returns a different permission state. That is why agent observability should not mean "log everything." It should mean "record the workflow in a form that can be reconstructed later."
Agent Timeline has value because it expands the event. A dashboard compresses the current state. A timeline unfolds the incident. Operators need to see which tool call the agent selected, where the failing span sat, and how downstream API degradation connected to an agent stall or wrong handoff. This is not only an SRE problem. AI product teams, platform teams, security teams, and data teams need to stop describing the same incident in separate vocabularies.
The Market Is Already Converging
Honeycomb is not entering an empty field. In 2026, observability vendors are broadly pushing AI and agent operations to the front of their roadmaps. Grafana Labs has highlighted AI observability and agentic workflows. IBM Instana has positioned AI Agent and LLM Observability. Datadog, New Relic, and Elastic continue to extend AI assistants, LLM tracing, and MCP-shaped operational experiences. LLM application tools such as LangSmith and Arize already occupy developer workflows.
The difference is the starting point. LangSmith-style tools are strong when a developer wants to debug an agent run. Traditional observability vendors are strong in production systems, SLOs, distributed traces, and incident response. Honeycomb's announcement moves from the second starting point toward the first. Its differentiated claim is not only "we show the agent." It is "we show the agent together with the systems it touched."
That matters in production. The cause of an agent failure may be a slow database, rate-limited API, missing MCP tool permission, stale feature flag, or degraded downstream service rather than a prompt mistake. If an agent is operating real infrastructure, the incident crosses both AI and non-AI systems.
The limits are visible too. Agent Timeline is in Early Access, with general availability expected later. The product description alone does not answer how it handles cardinality cost at scale, prompt and response privacy, retention policy, or sampling strategy in large multi-agent deployments. Treating gen_ai.* as first-class only matters if teams can inspect which attributes are stored, which fields are masked, and how the data can be queried.
What Development Teams Should Prepare
This news should not be read as a simple instruction to adopt Honeycomb. The broader lesson is that agent operational data needs to be designed early. Many teams blur evaluation and observability when building LLM products. Evaluation asks whether answers, tasks, and regressions meet a quality bar. Observability explains what actually happened in production. They should connect, but they are not the same system.
If a support agent gives the wrong refund-policy answer, evaluation can decide whether the answer violated policy. Observability should show which retrieval document entered the context, which tool call failed, whether a fallback model was used, and what downstream system state the agent saw. Either one alone is incomplete. A strong offline score can miss a broken production path, and a perfect trace still needs a quality definition to decide whether the behavior was wrong.
For engineering teams, the checklist is already concrete. First, each agent run needs a stable correlation ID. Second, model calls and tool calls should live inside one traceable workflow. Third, if prompts and tool results cannot be stored in full, teams still need masked summaries, schema versions, token usage, provider, model, and retry reason. Fourth, downstream effects on services should link back to the agent run. Fifth, teams should follow OpenTelemetry GenAI conventions without treating experimental fields as permanent production contracts.
O11yCon Shows the Larger Turn
Honeycomb paired the product announcement with Innovation Week on May 12-14 and O11yCon on May 20-21. The event calendar itself is less important than the shift in subject. Observability conferences are moving from "how do we monitor services?" toward "how do we operate AI-powered systems in production?" That is happening not because agents are merely fashionable, but because operations teams are already starting to work with them.
Agents write code, investigate failed deploys, adjust cloud resources, and handle customer conversations. All of those tasks touch existing systems. Agent operations therefore cannot remain the AI team's private concern. SREs need to read agent spans. AI engineers need to read service traces. Security teams need to inspect tool permissions and prompt leakage. Product teams need to understand how failed conversations changed user experience. Observability vendors are trying to own that intersection.
Honeycomb's Agent Timeline is one scene in that larger transition. It is not a finished answer. The standards are still developing, the product is in Early Access, and every team's agent architecture looks different. The direction, however, is clear. The next competition in AI agents is not only about smarter model calls. It is about whether teams can reconstruct what those model calls caused in production when something goes wrong.
The question for builders is simple. If the agent you are building today creates an incident tomorrow, can your team explain it? Honeycomb's announcement pushes that question into the center of the observability market. The question will outlast any one vendor. As agents move deeper into products, traces become more than performance-optimization artifacts. They become records of responsibility and trust.