Copilot turns issue search into an agent work map
GitHub added semantic issue search and task-based auto model routing to Copilot, pushing coding agents from code generation toward workflow operations.

- What happened: GitHub made semantic issue search generally available in Copilot Chat and changed VS Code auto model selection into task-based routing.
- In the same week, GitHub also added review-comment batching, one-click Actions fixes, and cheaper
0.33xCopilot cloud agent models.
- In the same week, GitHub also added review-comment batching, one-click Actions fixes, and cheaper
- Why it matters: Copilot is moving beyond an IDE answer box toward a work surface that connects issues, PRs, CI, model choice, and cost policy.
- Watch: As Copilot shifts to usage-based billing on June 1, model selection auditability may matter as much as routing quality.
GitHub's May 20 Copilot updates look small if you read them as isolated feature announcements. One update brings semantic issue search to Copilot Chat on the web. The other changes auto model selection in VS Code so Copilot chooses a model based on the task in front of it.
Read together with the Copilot cloud agent changes from the same week, the direction is more interesting. GitHub is no longer only trying to make Copilot better at writing code. It is moving Copilot into the surrounding workflow: finding the right issue, batching review comments, fixing failed CI runs, and deciding which model tier should handle each job.
That is the meaningful shift. Early AI coding tools competed mostly inside the editor. Could they complete a function, refactor a file, explain an error, or generate a test? Then the competition widened into agent mode, terminal access, browser control, MCP servers, and cloud sandboxes. GitHub's latest changes target the stages before and after code generation: discovering what work should be done and routing that work through the right model and cost boundary.
Finding issues without exact keywords
GitHub says semantic issue search lets users find, group, and analyze issues in Copilot Chat on the web using natural language. The key ingredient is a semantic issues index. Instead of requiring users to remember an exact title, keyword, label, or manual filter, Copilot can surface related issues based on meaning.
That matters because real issue trackers are messy. One team member writes "docs." Another writes "documentation." Someone else says "onboarding flow," "README gap," or "setup confusion." A keyword search can miss related work when the vocabulary changes across time, teams, and maintainers. Semantic search is meant to reduce that mismatch.
GitHub frames the feature as useful for finding issues expressed in different terms and for narrowing results by platform or environment. It is generally available for all Copilot plan users, not a preview limited to one enterprise tier. For projects that already run on GitHub Issues, the backlog becomes a conversational context surface for Copilot.

The image above comes from the same day's auto model selection update rather than the semantic search post, but the pairing is the point. Once Copilot can find a cluster of issues, the next question is which model should handle the task. Search and routing are starting to sit in the same agent workflow.
Model choice becomes routing
GitHub's auto model selection update is more explicit about operations. The announcement says Auto looks at real-time model availability and reliability signals, then evaluates the task across dimensions such as reasoning, code generation complexity, bug diagnosis difficulty, and tool orchestration needs. It then selects the model that best fits the work.
That can sound like a convenience feature, but it has larger product implications. Developers may still want manual model control, especially for tricky work. But not every task deserves the most expensive reasoning model. A spelling fix, a small test update, a local refactor, a multi-file bug hunt, and a design-level change have different inference and context requirements.
GitHub says Auto can use multiple model families depending on the user's subscription and administrator policy. If an administrator blocks access to a model, Auto respects that policy. Users can hover over the response header to see which model was selected and can switch to a specific model at any time.
That visibility is not a minor UX detail. In the 2026 coding-agent market, model choice is no longer just a dropdown preference. Teams need to know which model was used for which task, whether that choice complied with policy, and how the cost was attributed. For organizations rolling out Copilot across many repositories, this is both a productivity feature and a governance feature.
The important part is the cost boundary
GitHub also described the premium-request behavior behind Auto. For now, Auto is limited to models with a 0x to 1x multiplier. Paid subscribers receive a 10% multiplier discount when Auto is used. If Auto chooses a 1x model, for example, the request consumes 0.9 premium requests instead of 1.
GitHub also says Auto routes along natural cache boundaries to avoid unnecessary cache-related cost and that internal evaluations showed token efficiency gains without quality regression. The public details are not deep enough to independently judge that claim, but the product message is clear: model choice is becoming a cost-routing problem involving quality, cache behavior, availability, multipliers, and billing policy.
This lands just before a larger billing transition. GitHub's Copilot premium requests documentation says Copilot moves from request-based billing to usage-based billing on June 1, 2026. It also says Spark and Copilot cloud agent usage are tracked as separate SKUs. The longer and more autonomous a coding task becomes, the less useful it is to think of Copilot as a single switch. Teams need to ask which feature consumed which usage bucket.
Community discussion has already been circling that concern. Threads on r/GithubCopilot and r/ExperiencedDevs have focused on AI Credits, multipliers, cost predictability, and the risk that long agent loops can create surprising bills. Some examples are exaggerated, but the core worry is reasonable. Automation runs longer than a human chat. It retries. It reads logs. It asks for tests. It may inspect several files before producing a patch.
That is why Auto's 10% discount is less important than auditability. Can a user see which model was chosen? Does the routing obey administrative constraints? Are simple tasks kept away from expensive models? When the invoice arrives a month later, can a team explain which repositories, workflows, and agent runs drove the cost? Once coding agents become team infrastructure, those questions are not optional.
Issues, reviews, and CI become one agent lane
Semantic issue search and auto model routing were not the only Copilot updates that week. On May 18, GitHub announced one-click fixes for failed GitHub Actions jobs with Copilot cloud agent. Business and Enterprise users can click "Fix with Copilot" from a workflow run logs page. Copilot investigates the failure, pushes a fix to a branch, and requests review after the work is complete. GitHub says the task runs in a cloud-based development environment.
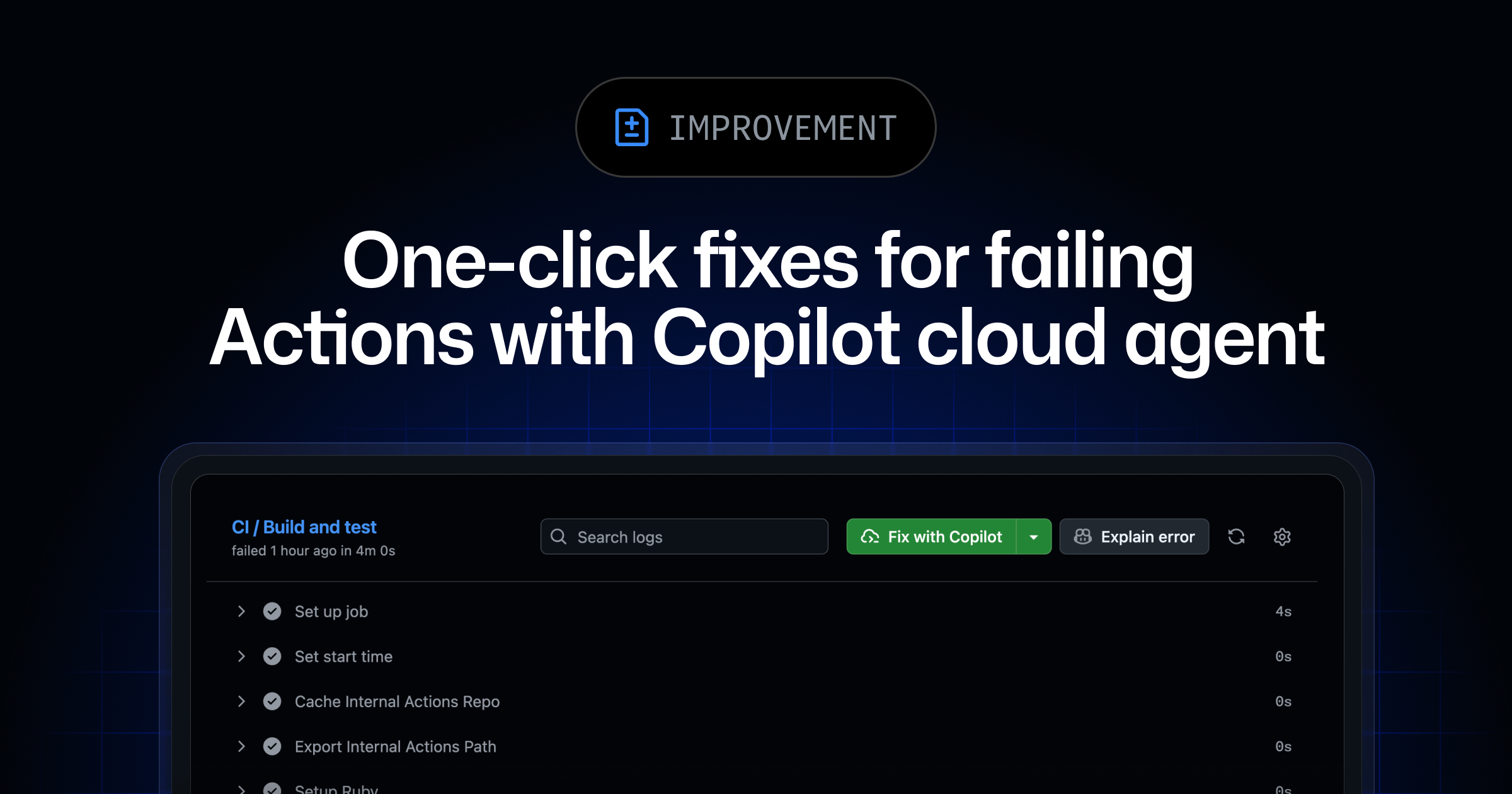
On May 19, GitHub also changed the Copilot code review handoff. The old "Implement suggestion" button became "Fix with Copilot," and a dialog now lets users choose whether the change should be applied to the current PR or opened as a new PR from a selected branch. Users can also choose the model and add additional instructions. From Copilot's pull request overview comment, multiple review comments can be batched and handed to the cloud agent as one job.
Put those updates on one line and Copilot's position changes.
| Work point | GitHub update this week | What changes for development teams |
|---|---|---|
| Backlog discovery | Semantic issue search | Find and group related issues through natural language instead of exact keywords. |
| Model choice | Auto model selection | Route tasks by difficulty, availability, reliability, and cost tier. |
| Review follow-up | Fix with Copilot, batched comments | Hand multiple review comments to a cloud agent as one implementation task. |
| Verification failure | One-click Actions fix | Send CI logs directly into an agent repair workflow. |
This makes Copilot more deeply GitHub-native. Cursor, Claude Code, and Codex have strong positions in local workspaces, terminals, and agent execution. GitHub's advantage is that issues, pull requests, Actions, review comments, billing, and organization policy already live in the same platform. Whether or not Copilot is the best code-generating model in a given month, GitHub has a dense map of what work exists and when a task is ready for review.
Semantic issue search is the entrance. It helps users find the relevant backlog and see which problems may be related. Auto model selection is the router. A small documentation cleanup and a complicated concurrency bug should not necessarily use the same model or the same cost tier. Fix with Copilot and Actions repair are the exits. The agent pushes a branch, returns to the pull request workflow, and asks for review.
What teams should check
The first thing to check is issue quality. Semantic search can reduce keyword mismatch, but it cannot turn an empty issue into a useful work unit. If an issue has no reproduction path, environment detail, expected behavior, or acceptance signal, an agent will still struggle. In the agent era, issue hygiene is not just label maintenance. It is the process of accumulating task specifications that future agents can read.
The second thing is model policy. GitHub says Auto respects administrator model policy, so organizations need a real answer for which model families are allowed, which repositories can use higher-reasoning models, and how personal and enterprise subscriptions are separated. "Let each developer choose" works only while usage is small and costs are easy to ignore.
The third thing is workflow-level cost visibility. Copilot cloud agent, code review, Actions fixes, semantic search, and chat may feel like one product inside the UI, but they can produce different usage patterns in billing and audit logs. The Actions failure flow is especially convenient, but in a flaky test suite or large monorepo, repeated automatic repair attempts could consume both inference and compute.
The fourth thing is review responsibility. The Actions failure feature pushes a fix to a branch and requests review. That leaves a human review boundary before merge, and teams should preserve it. An agent-generated patch can make tests pass while still fixing the wrong layer, weakening a policy, adding a brittle workaround, or hiding a deeper reliability problem.
The fifth thing is the approval step between search and execution. It will be tempting to take a semantic cluster of similar issues and hand the whole batch to an agent. But issues that sound related may not share the same root cause. Human triage may shrink, but it does not disappear. It shifts toward defining clean work units that are safe to delegate.
Quiet updates, clear direction
This was not a splashy model launch. There are no benchmark charts in the center of the story. But coding-agent markets may increasingly be shaped by these workflow features rather than by model announcements alone. Models change quickly. GitHub itself added Claude Haiku 4.5 and GPT-5.4-mini to Copilot cloud agent on May 18 as cheaper 0.33x multiplier options for simpler tasks. The best model for a task will keep moving.
Issues, pull requests, reviews, CI, billing, and policy move more slowly. They are embedded in how software teams actually operate. That is where GitHub has leverage. If Copilot can search that context more effectively, route work more cheaply, and hand tasks into agent execution more naturally, the competition shifts from "which model is smartest" to "which platform owns the team's work graph."
For teams already using GitHub Issues, the backlog is becoming input data for AI agents. For teams using Copilot through company accounts, model routing and AI Credits are becoming part of the engineering budget. For teams that depend heavily on GitHub Actions, CI failure repair may be one of the easiest entry points into agent automation.
The right response is neither panic nor blind adoption. Copilot will not suddenly understand every issue or safely repair every failed build. But the signal is clear: work discovery is moving from files to issues, model selection is moving from preference to routing, and verification failures are moving from manual debugging toward agent handoff.
The next advantage in coding agents may not live only in the chat box. It will come from reading the issues, reviews, logs, policies, and cost boundaries that teams already leave behind. GitHub's May 20 updates quietly show that path. Copilot is becoming less like a tool that writes code on demand and more like a layer that lets agents walk across GitHub's map of work.