Copilot Memory now remembers the developer
GitHub Copilot Memory user preferences show coding agents moving from answer quality toward persistent context, work habits, and trust management.
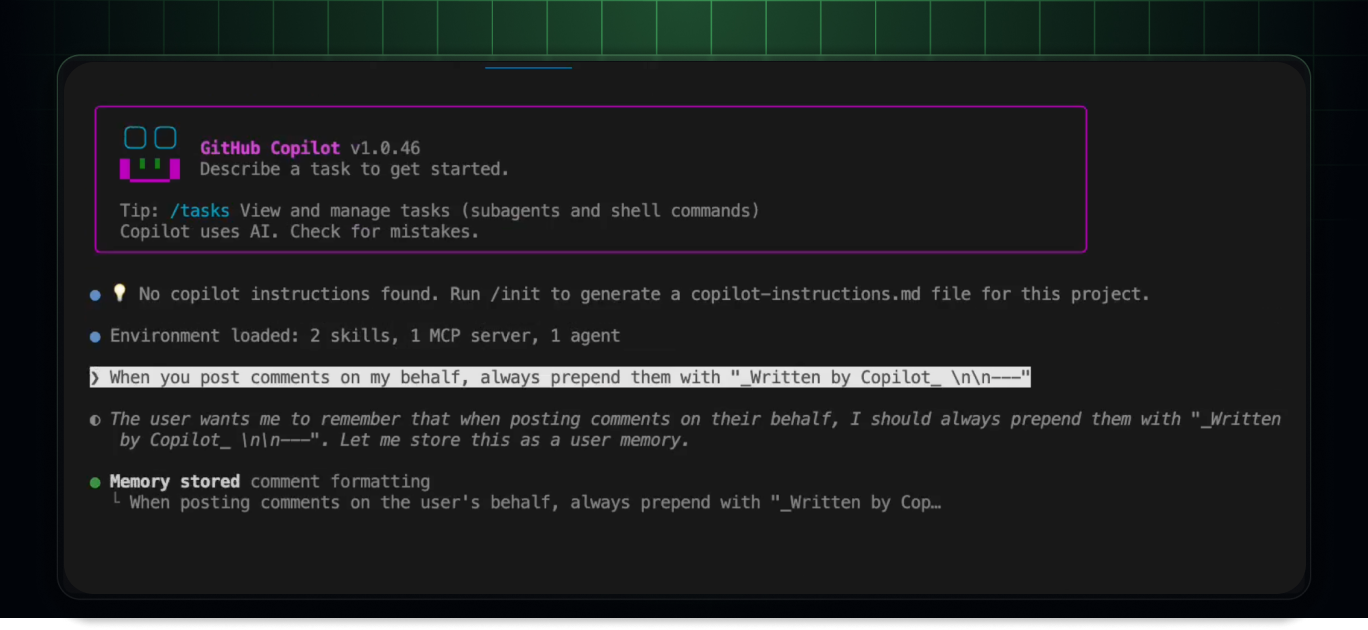
- What happened: GitHub added user-level preferences to
Copilot Memory.- Copilot Pro and Pro+ users can now carry preferences such as commit style, pull request structure, and communication tone across Copilot experiences.
- Why it matters: Coding-agent competition is shifting from single-answer quality to persistent context, work habits, and controllable trust.
- Developer impact: Personal preferences can reduce repeated prompting, but teams still need explicit rules for storage scope, deletion, and memory review.
- Repo policy belongs in version-controlled instructions; personal workflow style can live in user-level memory when the user can inspect and remove it.
- Watch: The feature is in public preview, and user-level preferences are currently limited to Copilot Pro and Pro+.
GitHub added user-level preferences to Copilot Memory on May 15, 2026. The changelog looks small at first glance. Copilot can now remember personal preferences such as a developer's commit style, pull request structure, and communication tone, then apply those preferences later across Copilot experiences. In the broader coding-agent market, however, this is not a small change. GitHub is moving Copilot from a tool that remembers a project toward a tool that follows a developer's working style.
Copilot Memory previously centered on repository-level facts. Those are facts such as build commands, test procedures, architecture decisions, and project conventions that belong to a specific repository. When the repository changes, the relevant memory changes with it. That scope is relatively easy to reason about because the memory describes the shared codebase. User-level preferences are different. They belong to one developer and can travel across repositories and Copilot surfaces.

GitHub's examples are deliberately practical: preferred commit style, preferred pull request structure, and communication or tone preferences. The important phrase in the documentation is "stated or inferred." Copilot can store preferences the user explicitly gives it, but it can also infer preferences from interaction patterns. That can remove repetitive prompting. A developer should not have to say "write commit messages as Conventional Commits," "put risk and tests first in the PR body," or "answer briefly and directly" every time. But inferred preferences also open the trust question: what happens when the assistant remembers the wrong thing?
Why memory matters now
The timing is the signal. In 2026, GitHub Copilot is no longer only an IDE autocomplete product. Copilot cloud agent can take a task in GitHub, work in the background, change code, and open a pull request. Copilot code review can read a PR and leave review comments. Copilot CLI helps from the terminal. JetBrains unified sessions, the Copilot app technical preview, and REST APIs for cloud-agent tasks add more entry points. A developer increasingly meets the same assistant across several surfaces.
If every surface starts from zero, the experience becomes inconsistent. A new colleague needs explanations: how the project builds, what the team avoids, which test command matters, what kind of PR description the maintainer expects, and which architectural shortcuts are off limits. AGENTS.md, README files, .github/copilot-instructions.md, Cursor rules, Claude Code instructions, and Codex instructions all attack this same problem from different angles. GitHub's path is to pull some of that working context into a managed Copilot memory layer.
Officially, Copilot Memory has two levels. Repository-level facts are tied to a repository. GitHub says these facts are stored with citations, and when Copilot uses a fact it verifies the citation against the current branch. If the branch no longer supports the fact, stale memory should not be applied blindly. In other words, repository memory is meant to stay anchored to evidence in the codebase rather than becoming a loose note pile.
User-level preferences are tied to the individual. GitHub's documentation says these preferences can be stored with citations that may include direct user quotes. If a developer says, "I want test results first in PR descriptions," that sentence can become the evidence for a preference. GitHub says the preference is provided only to that user's later interactions. It does not automatically affect other people working in the same repository.
That separation is important in practice. Repository rules are a shared contract: formatter rules, lint commands, test flows, architectural boundaries, security requirements, release procedures. Personal preferences are part of the user experience: short answers versus detailed tradeoffs, Conventional Commits versus a different commit style, risk-first PR descriptions versus narrative summaries. If those two categories collapse into one memory store, personal taste can look like team policy, or team policy can be treated as optional preference.
| Category | Repository-level facts | User-level preferences |
|---|---|---|
| What it stores | Build commands, architecture decisions, project rules | Commit style, PR structure, response tone |
| Scope | Copilot work inside the same repository | The same user across repositories and Copilot experiences |
| Validation model | Citation checked against the current branch | Copilot decides whether a relevant preference still applies |
| Main risk | Stale project facts or obsolete architecture assumptions | Wrongly inferred personal style or confusing surface-by-surface behavior |
Not every Copilot surface should use every memory
One detail in GitHub's documentation deserves attention. Copilot Memory is currently used by Copilot cloud agent, Copilot code review, and Copilot CLI. But code review uses only repository-level facts, not user-level preferences. That boundary makes sense. Code review should be anchored in team standards and repository evidence, not one developer's taste.
A user may prefer a softer review tone, a shorter summary, or a particular ordering of comments. Those are useful presentation preferences. But security bugs, missing tests, race conditions, and broken migration logic should not be evaluated differently because one user prefers a certain style. By declining to apply user-level preferences everywhere, GitHub is implicitly acknowledging that memory is part of product safety, not just product convenience.
Retention is also part of the design. GitHub's docs say unused facts or preferences may be automatically deleted after 28 days. When a memory is successfully verified and used, that timer can reset. That makes Copilot Memory closer to recent working context than an infinite personal knowledge base. It reduces the chance that old project rules or old preferences keep distorting agent behavior. Still, users need review and deletion controls because even recent memory can be wrong.
Activation policy differs by customer type. For individual Copilot Pro and Pro+ users, Copilot Memory is on by default and can be turned off in personal Copilot settings. For enterprise and organization-managed subscriptions, memory is off by default and must be enabled by an administrator. If a user receives Copilot subscriptions from multiple organizations, GitHub says the most restrictive setting applies. That default split is telling: convenience leads for individual users, while governance leads for managed organizations.
The upside is real
From a developer-experience perspective, the benefit is straightforward. Repeated prompts are friction. "This repository uses pnpm." "This service needs two config files changed together." "Write PR descriptions with risks before the summary." "Keep answers short unless I ask for detail." These instructions are small individually, but they become noise when repeated across tasks and tools.
As agent surfaces multiply, persistent preference becomes more valuable. A developer might start a task with Copilot cloud agent in GitHub, inspect it later from a terminal, and expect a similar commit style in another repository. In that world, a personal preference layer is not decoration. It is part of the continuity that makes an assistant feel like the same assistant.
This is also a platform move. Copilot can route across different models and product surfaces, but GitHub needs a context layer it controls if the experience is going to remain stable. Model providers can change. IDE extensions can change. The GitHub layer contains repositories, issues, pull requests, reviews, Actions, billing, organization policy, and now memory. If those pieces connect, Copilot becomes less dependent on any single model's stateless behavior.
The risk is also real
Memory is always double-edged. First, implicit storage is convenient but less predictable. If Copilot infers a preference the user never meant to express, that preference can quietly shape future work. Second, the boundary between individual preference and team rule can blur. "I like it this way" is not the same as "this repository requires it." Third, different Copilot surfaces can apply memory differently, which may leave users wondering why one interface remembers something and another does not.
The fourth risk is documentation decay. The better memory becomes, the easier it is for teams to avoid writing explicit instructions. That is dangerous. Agent memory can help with discovered facts and repeated habits, but it should not replace version-controlled policy. A repository rule that affects everyone belongs in a file the team can review, diff, and update. Memory should assist that process, not become an invisible substitute for it.
| Context layer | Strength | Risk to manage |
|---|---|---|
| AGENTS.md / instructions | Explicit and version-controlled | Can become stale if nobody maintains it |
| Repository memory | Accumulates codebase facts as agents work | Needs review and deletion when a fact is wrong |
| User preferences | Carries individual style across repositories | Must stay separate from shared team rules |
| Local IDE memory | Fast and close to the user's machine | May not connect cleanly to cloud agents or review tools |
This is why Copilot Memory should be seen as an additional layer, not a replacement for repository instructions. AGENTS.md and .github/copilot-instructions.md are explicit policy surfaces. They can be reviewed in code review, changed in a branch, and shared by the whole team. Copilot Memory is a managed store for facts and preferences discovered during use. It can adapt quickly, but it does not carry the same visible agreement as a file in the repo.
A strong team will probably divide the roles. Team rules go into version-controlled instructions. Repeated repository facts can be allowed into repository memory if the team can inspect and delete them. Personal working style can live in user-level preferences if it stays personal. That separation matters more as agents gain more authority.
The governance questions for companies
Enterprise adoption raises harder questions than individual convenience. What information is allowed to become memory? If citations can include direct user quotes, could they include sensitive internal phrasing, customer names, or incident details? What can repository owners see? Can administrators inspect user preferences, or only enforce whether the feature is enabled? How does a personal Pro account behave inside a managed organization repository when the organization disables memory?
GitHub's documentation explains the high-level scope and defaults, but security reviews will go deeper. Teams will ask about audit logs, data retention, deletion guarantees, eDiscovery, incident response, cross-organization boundaries, and how memory interacts with data policies. Those are not edge concerns. Memory is a new place where agent context can live, and context often contains the most sensitive operational details.
For individual developers, the practical rule is simpler. Let memory handle repeated personal preferences. Keep team rules, security requirements, deployment procedures, and legal constraints in explicit files and docs. Expecting an agent to remember something for your convenience is different from declaring a rule the whole repository must follow.
The larger market signal
GitHub is not alone in seeing this problem. Cursor uses rules, workspace context, and background agents to keep context inside the development environment. Claude Code uses instruction files, settings, and memory-like flows to shape project and user behavior. Codex-style tools use AGENTS.md, session instructions, and remote task control to solve similar continuity problems. The difference is that GitHub already owns code hosting, issues, pull requests, Actions, reviews, billing, and organization policy. A memory layer across those surfaces has a different strategic weight.
This is why the changelog matters beyond personalization. Coding agents are becoming workflow systems. They do not only answer questions; they inspect repositories, create branches, run tests, open pull requests, and participate in review. Once an agent can act across that workflow, memory becomes both UX and governance. The product has to decide what to remember, who can use it, how it can be deleted, when it should expire, and which surfaces are allowed to apply it.
Copilot Memory's user-level preferences may look like a small convenience feature. In the coding-agent market, personalization is persistence, and persistence is a trust problem. Developers want tools they do not have to explain themselves to every time. They also do not want tools that silently remember the wrong thing. GitHub's update sits on that tension. The next coding-agent race will not be won only by the model that writes the best snippet. It will also be won by the platform that remembers enough to be useful and exposes enough control to be trusted.
Sources
- GitHub Changelog: Copilot Memory supports user preferences for Pro, Pro+ users
- GitHub Docs: About GitHub Copilot Memory
- GitHub Docs: Managing and curating Copilot Memory
- GitHub Changelog: Agentic memory for GitHub Copilot is in public preview
- GitHub Changelog: Copilot Memory now on by default for Pro and Pro+ users in public preview
- VS Code Docs: Memory in VS Code agents