Copilot code review double billing makes AI review a CI cost
GitHub Copilot code review will consume both AI Credits and Actions minutes from June 1. AI review is becoming an operational CI workload.
- What happened: Starting June 1, 2026,
Copilot code reviewwill count against both AI Credits and GitHub Actions minutes.- Reviews that run on GitHub-hosted runners in private repositories will consume an organization's Actions minutes entitlement.
- Why it matters: AI review is no longer just a Copilot request. GitHub is pricing it as an agentic workflow that runs on CI infrastructure.
- Practical impact: Teams need to watch
copilot-pull-request-reviewerusage, runner policy, Copilot budgets, and Actions spending limits together. - Watch: Public repositories keep free Actions minutes, but repeated private-repository reviews can pressure both the AI budget and the CI budget.
GitHub Copilot's code-review button is about to change the cost model around pull requests. In an April 27, 2026 changelog, GitHub said that Copilot code review will be billed in two ways from June 1, 2026. One is AI Credits under the new usage-based billing model. The other is GitHub Actions minutes. In particular, Copilot code review runs in private repositories on GitHub-hosted runners will consume the existing Actions minutes entitlement and can roll into standard GitHub Actions rates after that entitlement is exhausted.
At first glance, this looks like another Copilot pricing update. For engineering teams, the signal is more structural. AI code review is being treated less like "a model leaves a PR comment" and more like an agentic workflow that reads repository context, calls tools, and runs on runner infrastructure. When the cost model changes that way, the operating model has to change with it.

Why code review uses Actions minutes
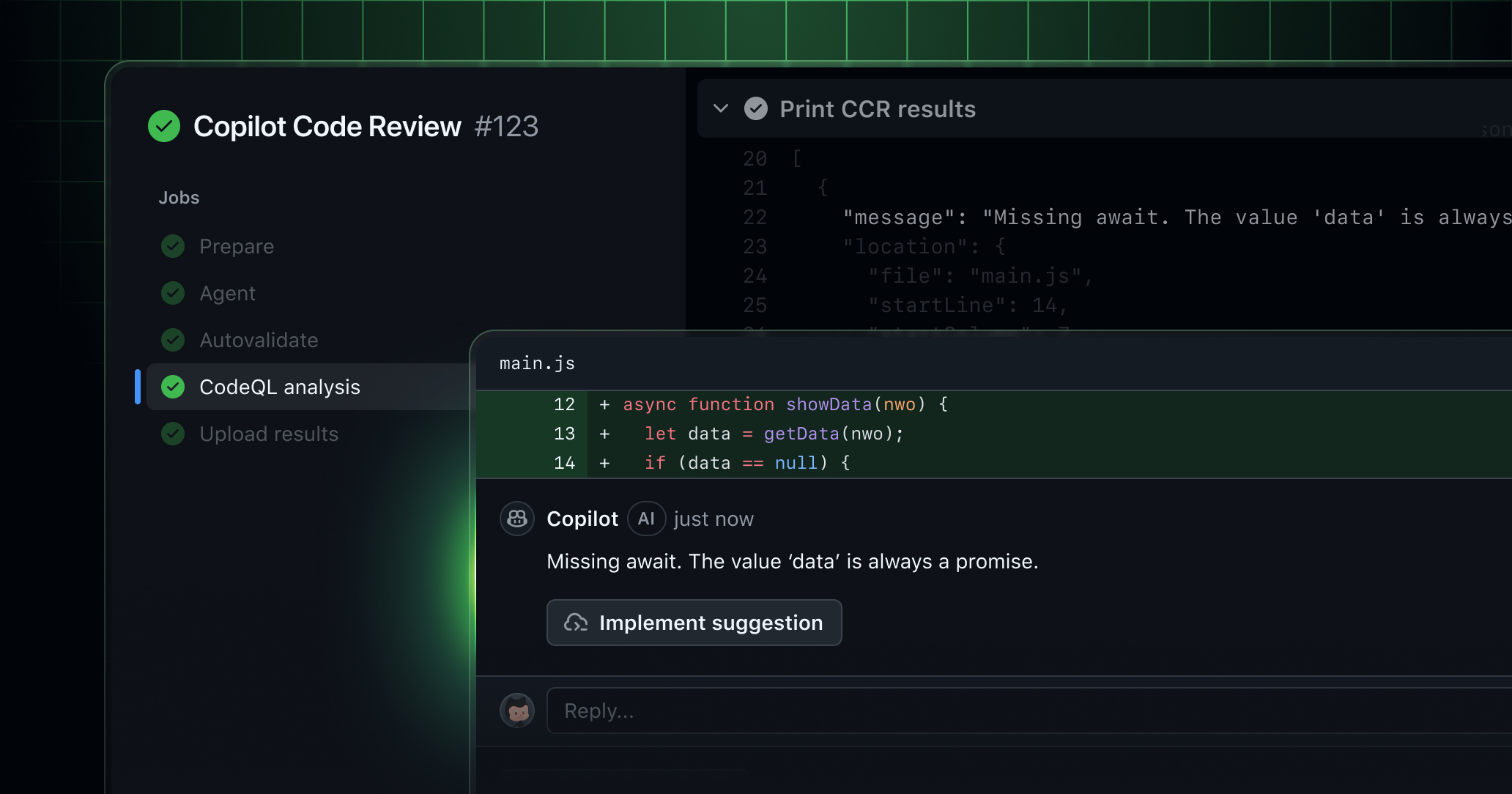
The April billing notice only makes sense if you start with GitHub's March announcement. On March 5, 2026, GitHub said Copilot code review was generally available on an agentic tool-calling architecture. In that architecture, Copilot does not simply look at the diff and generate a few comments. It can pull in broader repository context, directory structure, related code, and reference points when it needs to judge how a change fits into the whole system.
GitHub emphasizes the quality upside: better findings, lower noise, and more actionable guidance. That is a meaningful direction for automated review. The most common complaint about AI code review is not that it leaves too few comments. It is that too many comments are not worth fixing. A review agent that can read more repository context has a better chance of moving away from style chatter and toward correctness, architecture integrity, and risk-aware feedback.
But once a review pulls wider context and calls tools, it is no longer just an inference call. It needs an execution environment. GitHub puts that execution layer on GitHub Actions. The March announcement explicitly said that agentic Copilot code review runs on GitHub Actions. The April changelog turns that implementation detail into a billing detail from June 1.
This matters because it exposes where AI feature cost actually comes from. Model tokens are not the whole bill. Repository checkout, context gathering, tool execution, workflow orchestration, log streaming, and runner allocation all cost money too. Copilot code review is both a model feature and a CI workload. GitHub is now asking customers to account for both surfaces.
What changes on June 1
GitHub's scope is fairly precise. From June 1, 2026, the change applies to Copilot Pro, Pro+, Business, and Enterprise. All Copilot usage moves under usage-based billing with AI Credits. Copilot code review also consumes GitHub Actions minutes when it runs in a private repository on GitHub-hosted runners.
Public repositories are different. GitHub says Actions minutes remain free for public repositories, so the Actions-minutes side of this change is limited for open-source projects. The broader move to AI Credits still applies to Copilot usage, but public repositories do not inherit the same CI-minute pressure.
Self-hosted runners are another important exception. GitHub's models and pricing documentation describes Copilot code review as billed through token consumption and agentic infrastructure, and it notes that self-hosted runners do not consume GitHub Actions minutes. That does not mean review becomes free. AI Credits still apply, and the organization takes on runner operating cost, security configuration, network policy, and secret-management responsibility.
That is the practical pivot. One team may start with GitHub-hosted runners because the setup is easy. Another may prefer self-hosted runners because of cost controls, data boundaries, or internal security rules. A third may need larger runners for large repositories. Turning on Copilot code review is no longer only a question of whether AI review is useful. It is also a question of where the review agent is allowed to run.
| Item | AI Credits | Actions minutes | What teams should watch |
|---|---|---|---|
| What it reflects | Model token usage | Review-agent execution infrastructure | Review frequency and PR size |
| Predictability | The model can be selected automatically and vary by review | Depends on runner type and execution time | Billing reports and Actions metrics |
| Control levers | Copilot budgets and plan policy | Actions budgets, spending limits, and runner policy | Repository-level automatic review rules |
The hard part is predictability
The difficult part is not only that billing now has two surfaces. It is that the per-review cost can be hard to predict. For ordinary Copilot usage, a user can often see which model they selected and estimate the pricing table. Copilot code review is an exception. GitHub Docs say the model is selected automatically and is not disclosed for code review, so the per-token cost can differ from one review to another.
That product choice is understandable. A review agent may need different model capacity depending on PR size, programming language, repository context, security signals, and task difficulty. A small documentation edit and a large authorization-system change should not necessarily use the same model path.
Cost management sees the same design differently. If the model is not disclosed, context gathering changes by review, and runner time is added on top, a PR author cannot easily know what a review request will cost before clicking the button. The organizational problem is not only "this costs a few more cents." It is "we cannot explain in advance which work creates which charge."
GitHub's recommended preparation work therefore centers on billing and metrics. Billing managers need to review Actions usage and entitlements, adjust spending limits and budgets, and look across Copilot usage metrics, GitHub Actions metrics, and Billing Usage Reports. The docs point teams to the copilot-pull-request-reviewer workflow in GitHub Actions metrics. After June 1, billing usage reports can also show the dynamic/agents/copilot-pull-request-reviewer workflow path.
Those filter names matter. Once a workflow name becomes part of cost analysis, an AI feature has entered platform accounting. A team needs to know who requested AI review, which repository triggers repeated reviews, and which team is spending Actions minutes on review automation. Without that visibility, AI code review stops being a quality tool and becomes an opaque billing line.
The pricing shift reveals GitHub's product direction
GitHub has been expanding Copilot aggressively through 2026. Copilot app preview, cloud-agent task REST APIs, team-level usage metrics, auto model selection, CLI agent work, and unified sessions views all arrived in the same broader period. In that context, the code-review billing change is not an isolated accounting event. It is another sign that Copilot is moving from IDE assistance into the development operations layer.
Early Copilot was remembered for one-line completions and function generation. The cost model could stay relatively simple. Users paid a subscription, and GitHub absorbed the underlying model calls. Agentic coding changes the unit of work. An agent reads the repository, creates a branch, runs tests, opens a pull request, responds to review comments, and fixes failed checks. That is not a single chat turn. It is a workflow.
Copilot code review follows the same pattern. From the outside, it looks like a PR diff receives comments. GitHub's own architecture framing says the agent can pull broader repository context when needed. To judge architecture integrity, a reviewer may need related files, call paths, directory conventions, and existing patterns. AI review therefore starts to look more like CodeQL, Actions, branch protection, required checks, and security scanning than like autocomplete.
GitHub's advantage is obvious. Pull requests, Actions, Copilot, billing, review UI, and repository permissions already live on the same platform. An external AI review SaaS often needs webhooks, tokens, permissions, check reporting, and comment access. GitHub can route the same work through native objects. The tradeoff is lock-in. Review quality, execution environment, organizational policy, and cost all become tied to the GitHub account and the Actions budget.
What engineering teams should change
The first change is conceptual. Copilot code review should not be treated as a harmless default toggle. AI review can improve PR quality, but not every pull request deserves the same agentic workflow. Documentation edits, simple config changes, dependency lockfile updates, and generated-file churn may produce a weak signal for the cost. Permission models, payment flows, authentication code, data migrations, and API-contract changes are better candidates for more aggressive automated review.
Second, teams need repository-level policy. Public and private repositories have different cost surfaces. GitHub-hosted and self-hosted runners have different cost and responsibility surfaces. If a sensitive private repository uses Copilot code review, the runner environment, secret access, network policy, and log retention policy all need to be considered. The same wider context that can improve review quality also implies wider access and more execution traces.
Third, PR authors need a usable cost intuition. A visible "request AI review" button feels like a normal product feature. For the organization, the click can move both AI Credits and Actions minutes. PR templates or contribution guides should spell out when Copilot review is expected, which repositories have automatic review enabled, and when a large PR should be split before review.
Fourth, cost has to be evaluated with quality. It is not inherently bad that AI review uses Actions minutes. If it catches bugs that humans miss, reduces review turnaround, and slows architecture drift, the cost may be justified. The failure mode is paying for more review count and comment count without better code. Teams should track how often Copilot comments lead to real changes, how often they are false positives, whether reviewer time goes down, and whether security-related findings improve.
Community frustration is about trust
Public reaction in a Reddit r/GithubCopilot thread was negative. Some users saw Actions minutes as one more cost layer after token-based pricing, rate limits, and model multiplier changes. The important point is not that every complaint is a precise pricing analysis. It is that developers increasingly experience Copilot as powerful but harder to reason about.
That is a trust issue. AI development tools already ask developers to judge model changes, request limits, data controls, automatic execution, and the quality of generated review comments. When the billing surface expands, the same trust problem becomes sharper. A team has to understand not only whether the tool is useful, but what it runs, what it reads, what it costs, and who can control it.
GitHub appears aware of the organizational angle. The changelog specifically tells billing administrators and engineering leads to communicate the update before June 1. That framing matters. This is less about a single developer's Copilot experience and more about engineering productivity, developer experience, FinOps, and security sharing a table.
The next AI review competition is not only comment quality
AI code review is already a crowded market. GitHub Copilot code review, CodeRabbit, Graphite Reviewer, Sourcegraph Cody, CodeQL autofix, internal LLM review actions, and many GitHub Actions-based review bots compete in overlapping territory. The first phase of competition asked who could leave the most accurate comments. The next phase will ask who can provide the most predictable operating model.
A good AI review tool is not just a smart model attached to pull requests. It should be able to explain which files it looked at, why a finding matters, how it ranks severity, and how it adapts to a team's standards. It should become stricter around security-sensitive changes and less noisy around routine changes. Now it also has to explain cost. If a one-click review hides a token budget and a runner budget, the product needs to show how those budgets are controlled.
GitHub's position is strong because the relevant objects are already there: PRs, Actions, branch protection, review UI, and billing reports. A strong position also raises expectations. If Copilot code review consumes Actions minutes, users will expect Actions-level observability and controls. They will want to see which workflow ran, why it ran, how much it used, and what result it produced.
A June 1 checklist
Organizations already using Copilot code review should check four areas before June 1.
First, review current Actions minutes usage. If CI budgets are already tight, private-repository Copilot review can pull budget warnings forward. Second, review Copilot usage metrics. Teams need to know which repositories and teams are invoking AI review. Third, inspect runner strategy. GitHub-hosted runners, larger runners, and self-hosted runners have different cost, security, and maintenance tradeoffs. Fourth, set repository-level automation policy. Decide whether AI review runs on every PR, only on certain labels, only on certain paths, or only on higher-risk change classes.
The point is not that teams should turn AI review off. It is that serious use needs operating rules. AI code review can save reviewer time, catch edge cases, and give junior developers faster feedback. Unbounded use can also increase both cost and noise.
GitHub's notice is a sign of AI development tooling maturing. Features that once looked bundled or free are exposing their real execution costs. Agentic architecture is being connected to CI budgets. Engineering teams are starting to treat AI usage as an operational metric.
The June 1 change to Copilot code review is not just another billing line. It marks AI review moving from a developer-screen feature into the CI/CD operating layer. The next round of AI coding-tool competition will not be won by model quality alone. It will depend on who can connect review quality, execution safety, usage predictability, and cost control into one workflow.