GitHub accessibility agent learned its limits across 3,535 PRs
GitHub accessibility agent pilot shows what AI code review needs when quality assurance depends on data, escalation gates, and human judgment.

- What happened: GitHub published a pilot for a Copilot-based
general-purpose accessibility agent.- The May 15, 2026 post says the agent reviews frontend pull requests and can fix simple accessibility issues before production.
- Key numbers: GitHub says the agent has reviewed 3,535 PRs with a 68% resolution rate.
- Real signal: GitHub emphasized linear process, templates, and escalation gates over free-form parallel agents.
- For complex or high-risk UI patterns, the system is designed to stop generating code and route developers toward the accessibility team.
- Watch: Only 35 of 55 WCAG A/AA success criteria are deterministically checkable by automated code tools, leaving about 36% for manual judgment.
GitHub's May 15 accessibility agent pilot can look, at first glance, like another Copilot extension story. Read the details and a more interesting question appears. If AI coding agents move beyond writing code into quality assurance and organizational expertise, what operating structure do they need?
GitHub's answer is optimistic, but not simple. The agent works inside GitHub Copilot CLI and Copilot's VS Code integration. It can answer accessibility questions, inspect pull requests that change frontend code, catch straightforward accessibility defects before they reach production, and sometimes produce a fix. That surface description sounds close to AI linting.
The numbers and design choices tell a different story. GitHub says the agent has reviewed 3,535 pull requests and reached a 68% resolution rate. At the same time, GitHub did not present the system as a fully automatic accessibility solution. The post is careful about the limits. The agent avoids complex code changes, stops at high-risk patterns, and explicitly acknowledges the parts of WCAG that automated tooling cannot decide.
That is the core signal. The next competitive frontier for AI agents is not only generating more code. It is knowing when not to generate code.
An accessibility reviewer that has seen 3,535 PRs
GitHub's accessibility agent has two goals. First, it answers accessibility questions where engineers already work. Second, it reviews frontend code changes and catches simple, objective accessibility issues before production.
In the official blog post, GitHub lists the most common issue categories the agent found across reviewed pull requests:
- Making structure and relationships understandable to assistive technology.
- Giving interactive controls clear and concise names.
- Making important notifications perceivable.
- Providing alternatives for non-text content.
- Keeping keyboard focus order logical across pages and views.
This list shows where accessibility automation has a natural foothold. Button names, image alt text, and mismatches between DOM order and visual order can often be inferred from a code diff. Full user journeys, complex widgets, and design intent are much harder.
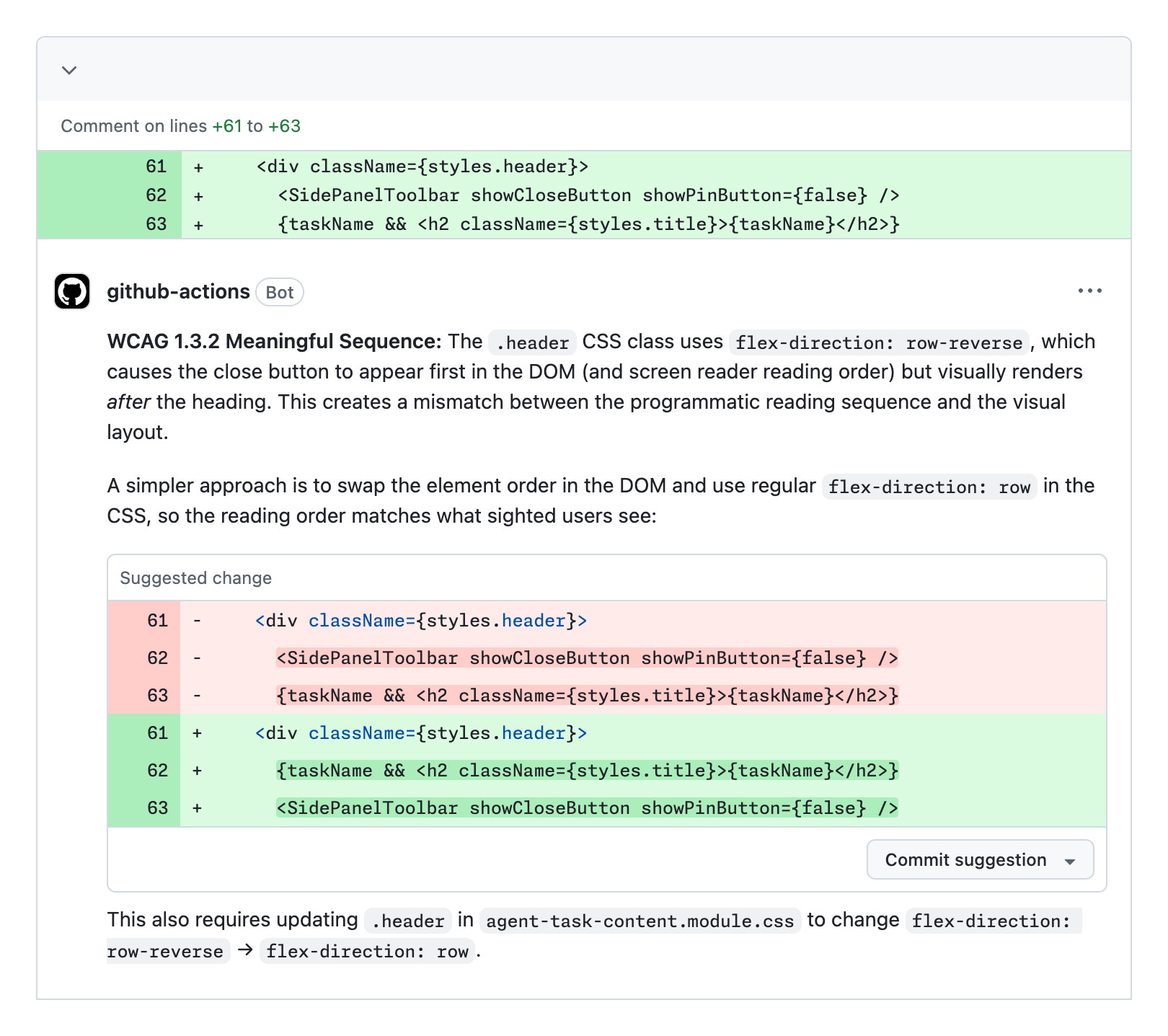
The screenshot from GitHub's post shows the agent flagging a flex-direction: row-reverse pattern that can make DOM order differ from visual order. A close button may appear after a title visually, while a screen reader encounters the close button first. The agent does not merely suggest a CSS tweak. It recommends changing the DOM order.
That example captures the promise of AI-assisted accessibility review. Traditional static analysis can find missing attributes, but it often lacks enough context to reason about how rendered order, reading order, and user experience interact. An LLM agent can read code, descriptions, historical issues, and WCAG guidance together, then attempt a more contextual judgment.
It does not mean accessibility automation is solved. GitHub's point is almost the opposite. The agent is not a replacement for the accessibility team. It is a reinforcing layer that uses the accessibility team's accumulated knowledge to find repeated problems earlier.
Why accessibility is a hard test for AI code review
Accessibility is difficult for agents because syntactically valid HTML or React does not guarantee an accessible experience. An aria-label can exist and still be a bad name. A keyboard handler can exist and still produce an unnatural or unusable focus flow.
The deeper problem is that accessibility is not only a code property. It is shaped by design, copywriting, information architecture, state changes, focus management, error messaging, and assistive technology behavior. GitHub makes this explicit. Accessibility work often requires the whole picture, which means a general-purpose accessibility agent can consume many tokens, become slower, and cost more.
GitHub's architecture choice is therefore notable. A common instinct in agent design is to add more specialized sub-agents in parallel. GitHub says this was not the right fit for the accessibility workflow.
Instead, the pilot uses two specialized sub-agents. One acts as a manual reviewer and researcher. The other acts as an active implementer. A parent agent handles routing, code and skill discovery, complexity scoring, output verification, escalation gates, and a re-audit loop. The sub-agents do not talk to each other directly. They pass structured template outputs back to the parent.
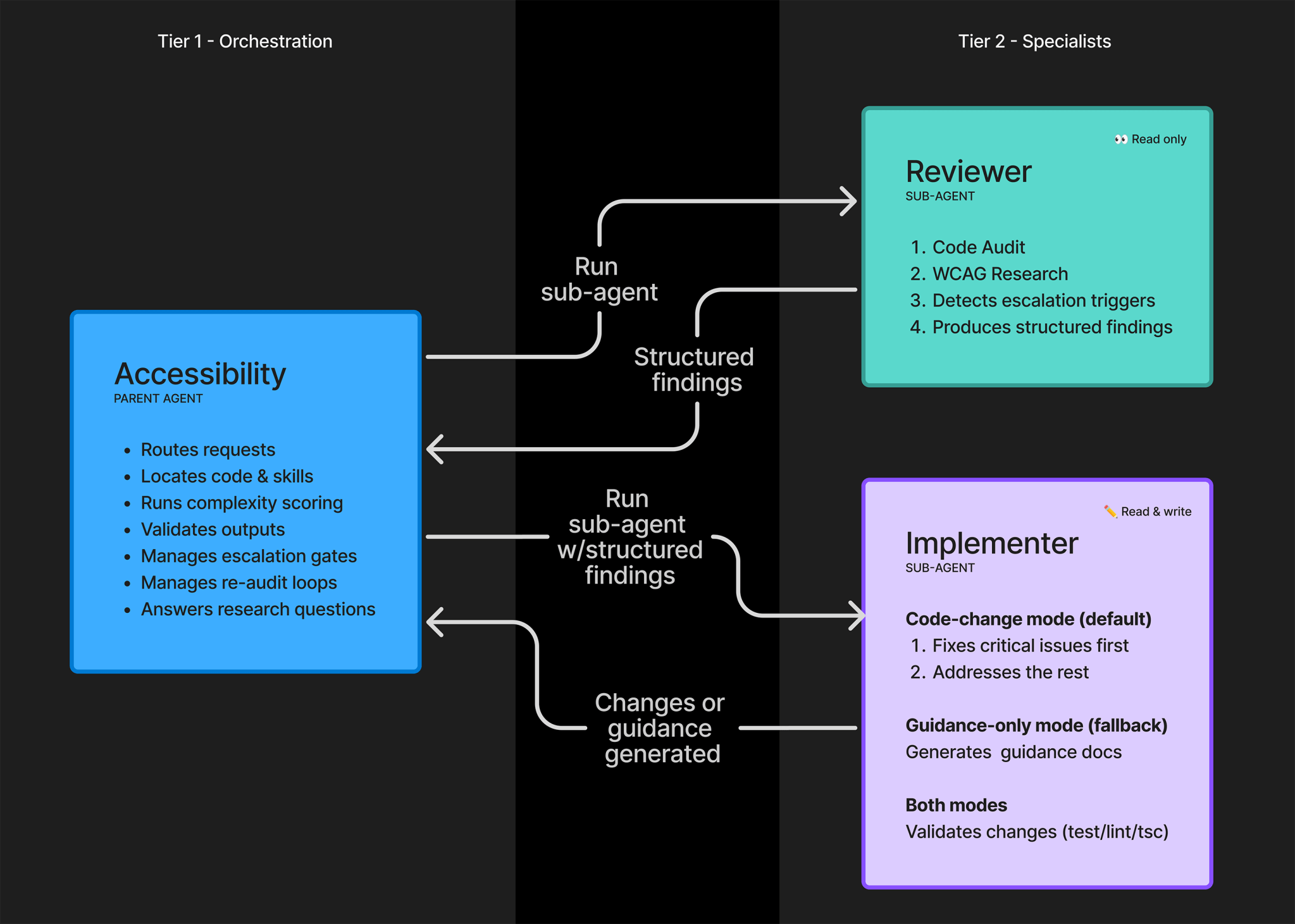
This design prioritizes auditability over speed. Accessibility fixes cannot be treated as "close enough." A wrong automatic fix can make a product harder to use and create more expensive rework later. GitHub therefore chose traceable decisions over unconstrained sub-agent conversation.
The lesson travels beyond accessibility. In complex organizational work, agent autonomy can be less important than preserving the path of a decision. Security, privacy, legal, and accessibility workflows all have high costs when automation quietly makes the wrong call. Linear process and templates may look less exciting than a swarm of agents, but they are often the practical design.
Old accessibility issues became the agent's data
One of GitHub's most useful lessons is that a good skill file is not enough. A vague instruction such as "follow accessibility best practices" does not reliably work. GitHub notes that LLMs have learned from decades of inaccessible code on the web, which means they can reproduce accessibility anti-patterns unless given stronger context.
The key asset was GitHub's internal accessibility issue history. Those records include issue templates, reproduction steps, severity, service area, applicable WCAG success criteria, fixing pull requests, and acceptance criteria. That corpus gives the agent examples of how GitHub's own product teams diagnose and repair real UI problems.
The type of data matters. Public WCAG documents explain standards, but they do not answer which fix a particular product team prefers inside a specific component system. Historical issues and PRs reviewed by human accessibility experts contain the missing organizational context.
In other words, the agent's quality is not only a model-quality story. It depends on how well the organization previously recorded, classified, and verified accessibility work. This pattern keeps appearing in enterprise AI adoption. Agents work better in organizations with disciplined knowledge management. Where documentation and issue history are scattered, agents tend to fall back to generic advice or risky fixes.
Accessibility makes this especially clear. The standards are public, but the implementation is tied to component architecture, product language, user flows, and design system constraints. "Give the button a name" is universal. Whether the name is clear depends on product context.
The stop condition matters more than the 68% resolution rate
The most practical part of GitHub's post is how the system handles limits. The accessibility agent is not designed to fix everything. If the complexity score crosses a threshold, the agent avoids code changes and advises the developer to consult the accessibility team.
It also avoids generating code for high-risk patterns such as drag and drop, toast, rich text editor, tree view, and data grid interfaces. These patterns combine assistive technology behavior, keyboard interaction, live region announcements, focus movement, and ARIA semantics. A change can pass an automated check and still fail real users.
This matters for productizing AI agents. Many coding agents are optimized to produce some kind of patch. Users expect an answer, and models are biased toward making one. GitHub treats that bias as a problem. The post says the team added anti-gaming guidance so the agent would not route around expert review when human judgment was needed.
A useful quality assurance agent has to distinguish three cases:
- A problem it can fix automatically.
- A problem it can detect but should only guide.
- A problem it should escalate to a human expert.
As AI tools mature, the third category becomes more important. "I cannot safely handle this" is not an exciting demo line. In a real organization, it can be more valuable than one confident but wrong patch.
About 36% of WCAG remains outside deterministic automation
The other important number is 55 and 35. GitHub says WCAG level A and AA contain 55 success criteria, and only 35 can be detected by deterministic automated code checkers. That leaves about 36% outside automation-only coverage.
This number helps place the accessibility agent correctly. LLM-based agents may reach parts of that 36% because they can read code and UI context, consult past issues, and reason about assistive technology behavior more broadly than a static checker. But GitHub does not frame this as a solved science.
Many accessibility problems also begin in design and prototyping. Catching issues in a pull request is useful, but by then the information architecture and interaction model may already be set. That is why GitHub still emphasizes early collaboration between accessibility experts and designers.
An AI agent does not remove that need. Used poorly, it can create the false impression that teams can postpone accessibility because an agent will review the PR later. Accessibility is product structure, not decoration. An agent can detect some structural problems late, but it cannot replace designing the structure well in the first place.
Copilot is moving from code generation into quality systems
This pilot also shows where GitHub Copilot's competitive surface is moving. Early Copilot competition centered on completion, function generation, and tests. More recent competition has shifted toward agent mode, PR creation, issue handling, CLI workflows, mobile control, and cloud agents. Now GitHub is attaching Copilot to an organizational quality process through accessibility review.
The move resembles Copilot Autofix in security. Security vulnerabilities and accessibility defects both become expensive when found late and cheaper when caught early. Both depend on expert knowledge, standards, organizational exceptions, and auditable decisions. That means an AI agent entering these areas needs a stricter operating design than a normal code generator.
The meaning of GitHub's accessibility agent is not simply "Copilot fixes accessibility." A more accurate reading is that Copilot is being embedded into quality systems. It catches repeated PR issues, consults historical issues, collects reviewer sentiment, and uses manual review results to refine instructions. That is not a one-off chatbot. It is an operating system that keeps being tuned.
For engineering teams, the first question is not "can we add an AI accessibility agent?" The first question is "do we have accessibility records an agent can learn from?" If past issues are not structured, fixing PRs are not linked, and acceptance criteria are missing, the agent will struggle to do more than summarize WCAG.
Practical takeaways for product teams
The GitHub pilot is directly relevant to teams outside GitHub. Accessibility requirements continue to rise across finance, commerce, education, public services, and enterprise software. Frontend release velocity is also increasing, and design systems allow many screens to be produced quickly. Accessibility experts remain scarce.
An AI accessibility agent is therefore tempting. GitHub's example suggests the order should be reversed. First, make accessibility issues structured. Record the affected screen, related WCAG criterion, severity, reproduction steps, fixing PR, and assistive technology verification. That record becomes the agent's future context.
Second, start with review assistance and guidance rather than full automatic fixing. Missing alt text, unclear button names, and DOM order issues may be good candidates for automated suggestions. Data grids, rich text editors, complex modal flows, and drag-and-drop interfaces should keep human review close.
Third, define stop conditions as a product requirement. A quality agent should have explicit complexity thresholds, high-risk UI patterns, and escalation paths. It should also produce structured outputs that a reviewer can audit.
That is not a conservative reading of AI. It is how the agent remains useful for longer. Once developers stop trusting accessibility comments, they begin ignoring them. Scope control is part of reliability.
The open source question comes later
GitHub says it hopes to open source the accessibility agent someday. For now, it is a pilot that depends heavily on internal records and organizational process. Even if the implementation becomes public, another organization will not automatically get the same result by running it unchanged.
The design principles are already useful:
- Turn accessibility issues and fixing PRs into a structured corpus.
- Split roles instead of relying on one large prompt.
- Restrict sub-agent outputs to auditable templates.
- Stop code generation for complex and high-risk patterns.
- State which WCAG areas remain outside deterministic automation.
- Feed reviewer sentiment and manual review results back into the system.
These principles are not limited to accessibility. Security review, privacy review, performance budgets, design system enforcement, and legal copy review all share similar constraints. Once an AI agent enters expert work, the central question becomes less "is the model smart?" and more "how has the organization structured its judgment?"
GitHub's accessibility agent pilot is not a flashy product launch. It is a useful case study in how much human knowledge, stop logic, and auditability good automation requires. The 3,535 reviewed PRs and 68% resolution rate are real progress. But the number that may matter more is 36%. Recognizing what automation cannot cover is exactly how an AI agent becomes part of a real quality system.