General Compute targets the GPU tax on agent inference
General Compute is making its ASIC-first inference cloud generally available, challenging GPU-centric serving for agent workloads.
- What happened: General Compute is making an
ASIC-firstinference cloud for AI agents generally available on May 15, 2026.- The company emphasizes purpose-built accelerators, an OpenAI-compatible API, and a roadmap that separates prefill from decode.
- Core claim: Agent workloads are not chatbot workloads. They combine long inputs, short structured outputs, small batches, and repeated tool calls.
- Developer impact: Behind the model-quality race, latency, power, and provider routing are becoming product-level costs for agent systems.
- Watch: Some numbers, including 7x and 950 tok/s, are company claims or projections and should be separated from independent benchmarks.
General Compute is making its inference cloud for agent workloads generally available on May 15, 2026. In an April 18 announcement, the company described the platform as an ASIC-first inference cloud for autonomous AI agents. On the surface, it is another OpenAI-compatible API. The more interesting part is the argument underneath: in the agent era, the bottleneck is not only the model. It is the hardware and serving architecture that sit beneath inference.
General Compute's message is blunt. The company site says GPUs were built for graphics while General Compute was built for inference, then highlights purpose-built ASICs, 1,000 tokens per second, and 7x faster inference. For developers, the integration surface is intentionally familiar. In Python or Node.js, the company says teams can keep using the OpenAI SDK and change the base_url and API key. But the internal thesis is that GPU clouds were optimized around chatbot-era average load, not the small-batch, long-context, repeated-tool-call shape of agent workloads.
That thesis lines up with a larger shift in AI infrastructure. In 2023 and 2024, the market mostly asked who had enough GPUs. By 2026, the question has fractured. Training is still dominated by general-purpose GPUs, but inference is splitting into voice, search, on-device models, long context, agent loops, and batch processing. General Compute is focusing on one of those workload classes: agent inference. This is not a chatbot that answers once and waits while a person reads. It is a system that plans, calls tools, observes failures, and calls more tools across a longer trajectory.
Why agents stress inference differently
General Compute's May 2026 white paper explains the core argument most clearly. A chatbot request is often a user question followed by a longer natural-language answer. The user then reads, which creates natural slack in the system. Providers can use that slack to batch requests and improve throughput. Once an answer streams faster than a person can comfortably read, extra token speed may not change the experience very much.
Agents behave differently. Their inputs include system prompts, tool lists, memory, retrieved context, previous execution logs, and intermediate state. The white paper says tens of thousands of input tokens are common and hundreds of thousands are not rare. The outputs, however, are often short. Agents emit JSON, tool calls, intermediate plans, structured outputs, or compact observations rather than essays. The more important difference is sequential dependency. One tool call has to finish before the next model step can begin. If one step adds 500 milliseconds, a 20-step trajectory adds 10 seconds.
That changes how inference performance should be measured. The usual tokens-per-second contest is not enough. For agents, long-prompt prefill, low-latency short decode, and tail latency across every step all matter. General Compute frames inference as two workloads rather than one. Prefill processes the prompt and is more compute-bound. Decode generates one token at a time while repeatedly reading model weights and the KV cache, making it more memory-bound.
GPUs are strong at prefill. Wide SIMD, high FLOPs, and HBM bandwidth can push long inputs through in parallel. Batch-size-one decode is less friendly. General Compute argues that GPUs leave expensive silicon underused in that mode. This is not a brand-new complaint. Groq, Cerebras, SambaNova, Google TPUs, and hyperscaler custom silicon all respond to similar pressure. General Compute's move is to package the argument as a cloud specifically for agents.
| Dimension | Chatbot inference | Agent inference |
|---|---|---|
| Input | A relatively short user question plus conversation context | Long context made from tools, memory, retrieval results, and prior execution logs |
| Output | Long natural-language responses meant for humans to read | Short JSON, tool calls, structured outputs, and intermediate plans |
| Waiting time | The user's reading time creates a buffer | Every delayed step accumulates across the full trajectory |
| Optimization axis | Throughput, batching, and streaming feel | Time to first token, low-batch decode, and tool-loop latency |
What the numbers say, and what they do not
General Compute publishes aggressive performance claims. Its site compares MiniMax M2.5 at 950 tok/s on General Compute with roughly 100 tok/s on NVIDIA Cloud. It also compares 17 kW racks with 120 kW GPU equivalents and power at $0.035/kWh with a U.S. commercial average of $0.13/kWh. The fine print matters. The comparison notes include projections for next-generation racks and a Together AI benchmark as the NVIDIA throughput reference. Those figures should not be read as proof that every current workload is 9.5x faster.
The white paper's current measurement claim is more specific. General Compute says it runs GPT-OSS-120B on SambaNova SN40L and, with the same prompt sent at the same time, measured a 738 ms time to first token versus 1,899 ms on Together AI. It also reports 1.76 seconds end-to-end latency versus 8.05 seconds. In the company's framing, that is 2.6x faster to the first token and 4.6x faster end to end. This is still a company-provided claim, not an independent benchmark. Model choice, prompt shape, region, queue state, and streaming behavior can all change results.
Even with those caveats, the numbers point to a real question. Many AI teams have chosen model APIs by looking at quality, price, context window, and rate limits. Agent products add per-step latency and trajectory economics. A five-step tool loop can tolerate some slowness. A 30-step tool loop cannot. When a coding agent runs tests, reads failure logs, patches files, and tries again, latency at each step becomes a product limitation.
Prefill on AMD, decode on SN50
The most interesting part of General Compute's roadmap is that it does not try to put every phase on one chip. The white paper says the company plans to move in Q4 2026 to a disaggregated stack using SambaNova SN50 and AMD MI300X. In that architecture, AMD MI300X handles long-prompt prefill while SN50 handles sequential decode. Users still see one API, but different silicon handles different inference phases behind the scenes.
This suggests that inference providers may start to look more like routers. OpenRouter-style layers already route between models and providers. The next step is finer-grained routing inside a single model call: prefill versus decode, long context versus short tool call, batch work versus interactive requests. Developers may still call chat.completions.create() or a Responses-style API. Under the hood, the cost structure becomes more fragmented.
SambaNova's own SN40L materials provide useful context here. SambaNova describes the SN40L RDU as a reconfigurable dataflow architecture and has focused its messaging on reducing the memory wall and model-switching overhead. General Compute is applying that hardware story to agent decode. The white paper also stresses that SN40L, future SN50, and air-cooled MI300X systems can fit into standard colocation power densities. That matters because AI infrastructure bottlenecks have moved beyond GPU allocation into power, cooling, and data-center buildout schedules.
OpenAI-compatible APIs and agents as customers
For developers, hardware matters less than migration cost. General Compute's documentation introduction emphasizes OpenAI-compatible SDKs, familiar endpoints and parameters, streaming semantics, tool calling, JSON mode, and vision/audio input. The hardware differentiation stays behind the service boundary. The API surface is meant to feel ordinary.
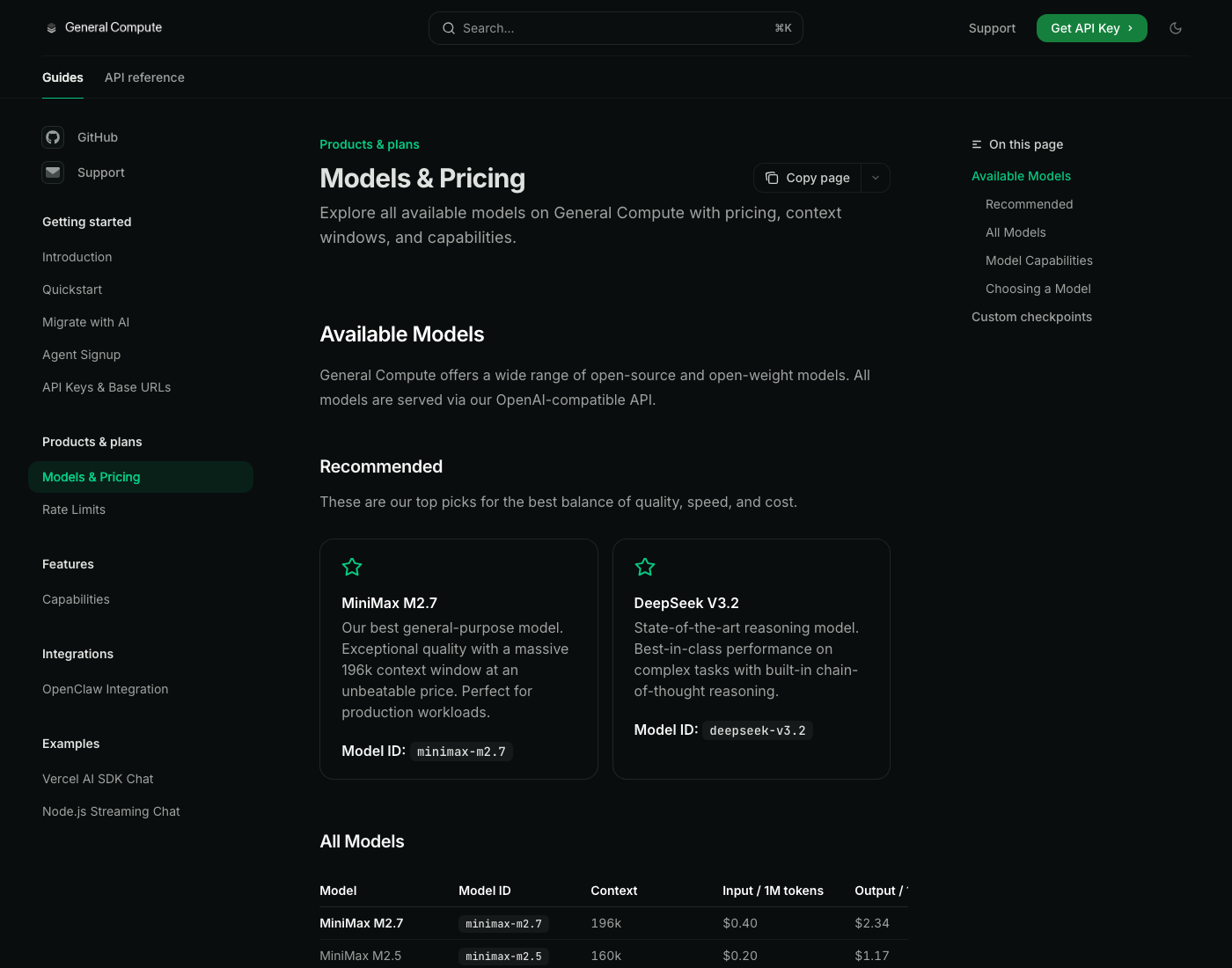
The models and pricing documentation lists MiniMax M2.7, DeepSeek V3.2, DeepSeek V3.1, Llama 3.3 70B, Llama 4 Maverick, GPT-OSS 120B, Gemma 3 12B, and other models. GPT-OSS 120B is listed with 128k context, $0.21 per million input tokens, and $0.79 per million output tokens. OpenAI's gpt-oss help article describes that model family as open-weight reasoning models for agentic, general-purpose production use cases. General Compute is effectively trying to put open-weight agent models on a faster inference substrate and sell the provider layer.
The more unusual document is the OpenClaw integration guide. It does not only explain how a human changes OpenClaw settings. Its "For agents" section walks an OpenClaw agent through requesting a General Compute API key and updating the provider block. The flow asks for the user's email, calls a signup API, waits for a verification code, and writes a provider block into openclaw.json. A person still has to read the verification code, so this is not fully autonomous. But the product message is clear: the customer for an inference cloud may be the agent itself.
That connects this announcement to agentic payment infrastructure, runtime clouds, and coding-agent ecosystems from OpenAI, Anthropic, GitHub, and others. If agents can choose tools, call paid APIs, and switch compute providers, infrastructure is no longer a static background setting that a developer configures once. It becomes something a task planner can select at runtime based on cost, latency, and capability.
Why this matters in practice
First, agent product performance is becoming harder to explain with model quality alone. The same model can feel different depending on provider prefill latency, decode latency, queueing, region placement, tool-calling implementation, and JSON-mode reliability. This is especially true for coding, research, and security-analysis agents where the value comes from completing a long loop rather than answering one prompt well.
Second, "OpenAI-compatible" is now a commodity surface. A new provider often asks developers to change a base URL rather than replace the SDK. That lowers switching costs. It also means provider claims need more independent verification. When the API surface is interchangeable, benchmarking becomes easier. Marketing claims become easier too.
Third, power and cooling are moving closer to the user experience of AI products. General Compute's emphasis on 17 kW racks, air-cooled silicon, and hydroelectric power is partly a cost story and partly a capacity story. If liquid-cooled GPU clusters are blocked by construction schedules, an air-cooled inference rack may be easier to deploy. The company's real capacity and demand still need to be proven, but the direction is clear: AI infrastructure competition is shifting from "who bought the chips" to "who can install usable inference capacity quickly."
Fourth, routing strategy becomes a practical concern for small teams. Sending every step to the strongest frontier model gets expensive fast in a long tool loop. Sending every step to the cheapest model can create failed tool calls and retries that cost more overall. The promise of a provider like General Compute is not merely cheaper tokens. It is lower latency and cost per agent step. Whether that promise holds has to be tested against each team's own workload.
Where skepticism is necessary
The biggest caution is the nature of the metrics. The site's 7x faster, 950 tok/s, 17 kW versus 120 kW messaging is powerful, but some of it is based on next-generation rack projections. The white paper's 4.6x end-to-end latency claim is also a company measurement. Until independent benchmarks cover different models, real agent trajectories, peak traffic, failure rates, and JSON/tool-call stability, it is too early to say that this replaces GPU clouds.
The model ecosystem is another variable. ASICs and dataflow architectures can be strong on specific workloads, but the model market changes quickly. Support breadth and optimization speed matter. The white paper mentions Llama, Qwen, DeepSeek, Mixtral, and MoE-style models, but customers will still need to check their own models, quantization schemes, LoRA or custom checkpoint needs, guardrails, observability, and region requirements.
There is also a question about whether agent workloads are standardized enough. General Compute's target profile is long prompt, short output, sequential trajectory, and batch size one. That fits many coding and research agents. It does not describe every agent system. Voice agents, browser agents, support agents, and batch document agents can have very different bottlenecks. In some products prefill dominates. In others, retrieval or external API latency dominates. In others, the model's reasoning failure is the real cost. Hardware optimization may be necessary, but it is not sufficient.
Why this signal matters now
General Compute is not a market-share shock. The signal for AI builders is narrower and more useful: as agents grow, inference is no longer a simple "send prompt, receive answer" API call. One task becomes an execution graph with dozens of model calls, searches, file reads, code executions, tests, and retries. The cost of that graph is more complicated than a model price sheet.
The 2026 AI infrastructure race is splitting into three layers. The first is the quality race between frontier models and open-weight models. The second is the orchestration layer that deploys, observes, and governs agents. The third is the inference substrate that reduces the latency and power cost of each call underneath. General Compute is arguing from that third layer that agents demand different hardware than chatbots.
If the argument is right, provider selection will become more workload-aware. Short chat responses, long report generation, coding agents, voice agents, and security-analysis agents may all use different inference backends. A model router will not simply choose the cheapest API. It will optimize across prefill, decode, context length, tool-call reliability, region, and power cost.
If the argument is overstated, General Compute should be tested quickly. The OpenAI-compatible surface makes it easy for customers to enter. It also makes it easy for them to leave. Agent developers can compare providers on real repositories, real tests, and real tool loops. The important metrics are time to complete a task, failed-tool-call rate, retry cost, and reliability during peak demand.
The point of this news is therefore not that another inference API exists. It is that agents are breaking AI infrastructure into smaller pieces. In the chatbot era, GPU throughput and model quality occupied most of the discussion. In the agent era, small-batch decode, long-context prefill, accumulated tool-loop latency, power density, and provider portability move together. Whether General Compute really cuts the GPU tax by 7x still needs proof. But teams building agent products should now ask a more concrete question next to the model name: what hardware path does this trajectory take?
Sources
- General Compute announcement: ASIC-first inference cloud for autonomous AI agents
- General Compute official site
- General Compute white paper
- General Compute documentation introduction
- General Compute models and pricing
- General Compute OpenClaw integration
- SambaNova SN40L RDU paper
- OpenAI help center: gpt-oss open-weight models