Gemma 4 starts reading ahead for local AI
Google released MTP drafters for Gemma 4, promising up to 3x faster inference. The bigger story is local LLM latency.

- What happened: Google released MTP drafters for the
Gemma 4family.- A smaller drafter predicts several future tokens, then the original model verifies them in parallel through speculative decoding.
- The numbers: Google claims up to 3x faster inference, no quality loss, and Apache 2.0 availability.
- Why it matters: Local LLM competition is shifting from model size toward
latency, runtime support, and hardware fit. - Watch: Real-world speedups still depend on acceptance rate, memory headroom, batch size, and runtime maturity.
Google released Multi-Token Prediction drafters for the Gemma 4 family on May 5, 2026. On the surface, this is a speed update: Gemma 4 can run up to 3x faster under the right conditions. For developers, the more important signal is how Google is attacking the bottleneck around local LLMs and AI agents. Instead of only making the target model larger or asking users to buy more expensive GPUs, Google is using a smaller drafter plus parallel verification to reduce the time a large model spends emitting one token after another.
In the official announcement, Google says Gemma 4 passed 60 million downloads within a few weeks of release. Gemma 4 is an open-weight model family from Google DeepMind aimed at developer workstations, mobile devices, and cloud deployments. The MTP release is the next layer in that story. It is not a new intelligence claim for the base model. It is an inference-layer update meant to make the already released models easier to serve with shorter waiting time.
The bottleneck is token latency, not just intelligence
Anyone who has put an LLM into a product knows that "is the model smart enough?" and "will the user wait for it?" are different questions. In a chat interface, time to first token shapes the first impression. In a voice agent, pauses between turns feel like hesitation. In coding agents and research agents, latency compounds because the system plans, calls tools, reads results, and revises its plan across several loops.
Standard autoregressive inference is sequential by design. The model reads the previous context and generates the next token. That token is appended to the context, and the model repeats the process. This is simple and powerful, but it repeatedly moves billions of parameters from memory to compute units. Google describes this as a memory-bandwidth-bound problem. The processor is not necessarily slow at computation; the cost is often moving model weights through the hardware for every generated token.
The problem becomes sharper in local deployments. In a data center, teams can combine batching, kernel optimization, caching strategies, and specialized hardware. On a personal workstation, laptop, or mobile device, memory bandwidth and power budgets are tighter. Once local models become useful enough, the next question becomes whether they are fast enough. Gemma 4 MTP drafters are Google's answer to that question.
MTP lets a small model write the preview
The core idea is straightforward: a smaller model proposes several future tokens first. The larger Gemma 4 target model then verifies those candidates in parallel. If the target model agrees, several tokens are accepted at once. If it disagrees at some point, generation falls back to the normal path from that mismatch. The user still receives output authorized by the larger target model, but predictable spans can move faster.
Input context and tokens generated so far
The small MTP drafter quickly proposes several future token candidates
The Gemma 4 target model verifies candidates in parallel and accepts approved tokens
Accepted spans are emitted together; generation resumes from the first mismatch
This is not a brand-new research idea. In the 2022 paper "Fast Inference from Transformers via Speculative Decoding," Google researchers showed that a small approximation model plus parallel verification by a larger model could produce 2x to 3x speedups without changing the target output distribution. The difference now is packaging. The idea has moved from a research technique into Gemma 4-specific drafter checkpoints that developers can try in real runtime stacks.
The Hugging Face model card for google/gemma-4-E4B-it-assistant confirms the same structure. It describes the MTP drafter as extending the base model with a smaller, faster draft model for a speculative decoding pipeline. The draft model predicts multiple tokens, and the target model verifies them in parallel. The license is Apache 2.0, matching Gemma 4. In other words, this is not just a demo claim; it is a deployable component.
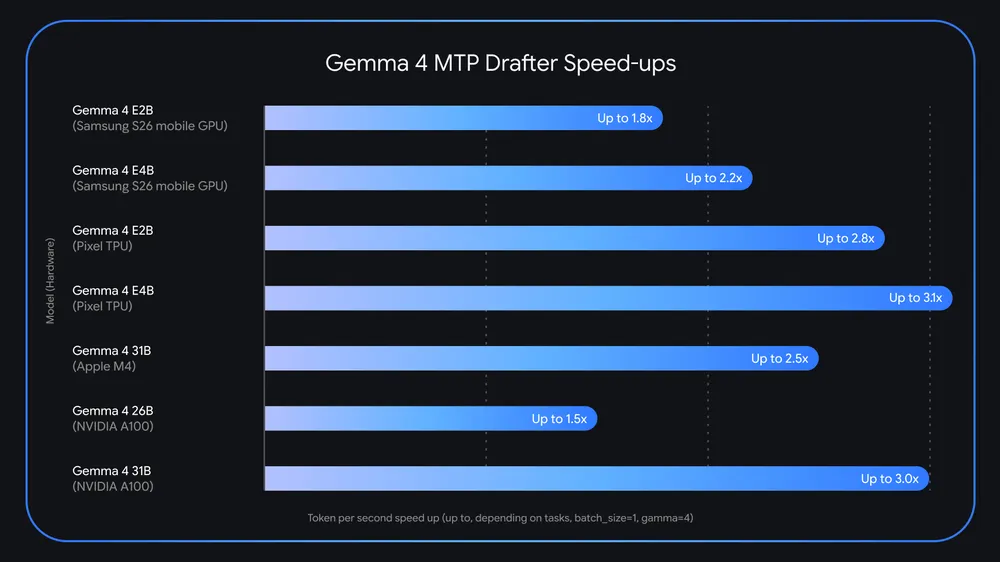
Why "up to 3x" needs a careful reading
Google says the MTP drafters can deliver up to 3x faster inference. The same announcement also includes more grounded details. For example, it says the 26B mixture-of-experts model faces routing challenges at batch size 1 on Apple Silicon, while batch sizes around 4 to 8 can unlock roughly 2.2x local speedups. Google also reports similar benefits on Nvidia A100 as batch size increases.
That means "up to 3x" is not the same as "3x everywhere." Speculative decoding speed depends on how often the drafter is right, whether the system has enough memory to host both drafter and target model, how well KV cache sharing is implemented, and how efficiently the runtime handles the architecture. Predictable continuations can benefit a lot. Hard reasoning paths or high-variance sampling settings can lower the acceptance rate and shrink the gain.
Still, the direction is clear. Open-weight model competition is no longer only a contest over parameter count and benchmark score. The decoding strategy and serving runtime can change the user experience even when the target model stays the same. The smaller model reads ahead, while the larger model remains the final authority. That separates quality responsibility from latency optimization.
Why this matters for local AI
Local LLMs have been improving along two tracks. One is model quality: smaller models now support longer context, better reasoning, and richer multimodal input. The other is runtime quality: MLX, vLLM, SGLang, Ollama, llama.cpp-style stacks, and mobile runtimes such as LiteRT are moving quickly. Gemma 4 MTP sits closer to the second track. It is about making a useful model practical under tighter latency and hardware constraints.
Google says the drafters are available through Hugging Face and Kaggle, and points to experimentation paths across Transformers, MLX, vLLM, SGLang, Ollama, Google AI Edge Gallery on Android and iOS, and LiteRT-LM. That list matters. A model announcement becomes a developer product only when teams can attach it to the serving stack they already use, debug it, and fall back cleanly when the new path does not fit.
For AI agents, token speed turns into both cost and reliability pressure. An agent is not a single response. It drafts a plan, calls a tool, reads the result, updates its plan, and continues. If that loop runs ten times, latency is multiplied across the workflow. A local coding agent reading files, summarizing test failures, writing patches, and explaining changes sees the same compounding effect. Saving a few seconds per step can become a meaningful difference in total task time.
Privacy and cost are part of the story too. If local models become faster, teams can keep more workloads off external APIs. Internal code, private documents, and local files become easier to handle without sending every prompt to a cloud model. Gemma 4 does not replace every frontier model. But if local models stop feeling too slow for common tasks, teams can split workloads more carefully between cloud models and local models.
The Hugging Face model card shows the deployment context
The Hugging Face model card suggests that the drafter is tied to Gemma 4's broader deployment strategy, not just a speed patch. Gemma 4 includes dense and mixture-of-experts variants, with sizes such as E2B, E4B, 26B A4B, and 31B. The card positions smaller models for mobile and edge devices, while larger models target consumer GPUs and workstations.
MTP means different things at different model sizes. For E2B and E4B edge models, battery, heat, and first-token latency matter. For 26B A4B and 31B, the question is whether a workstation can deliver a usable interactive speed. Google also says it used embedder clustering for E2B and E4B to reduce a final-logit bottleneck. Even small models do not automatically escape inference bottlenecks.
For developers, that becomes a practical checklist. Do not treat MTP as a single switch that always makes a model fast. Check whether the target model and matching drafter line up, whether the runtime supports the architecture, and whether quantization and cache settings are compatible. In local deployment, the draft model and main model must coexist. VRAM and system memory may become the limiting factor before the promised speedup appears.
The community is experimenting quickly, but the measurement bar is still forming
The LocalLLaMA community started discussing llama.cpp-style experiments and GGUF conversions soon after the announcement. One post reported Gemma 26B on a MacBook Pro M5 Max moving from 97 tokens per second to 138 tokens per second with MTP, roughly a 40% gain. That is far from Google's maximum 3x number, but it may be the more useful signal. Runtime, quantization, hardware, prompt shape, and sampling settings can all change the result.
The more interesting part is that the comments did not stop at speed. One user argued that quality claims should be tested with the same seed and temperature 0.0. The original poster replied that model answers can still vary and that a judge may be needed. This is exactly the question speculative decoding raises for product teams. "Faster" and "same quality" are separate claims that need separate measurement.
Google's official argument is that the target model performs final verification, so output quality and reasoning logic are preserved. The speculative decoding literature also supports the idea that the larger model's distribution can be preserved. In production, however, sampling settings, implementation details, quantization, fallback behavior, and tokenizer handling can all matter. Teams should ship MTP behind a feature flag and watch latency, acceptance rate, errors, and user-facing quality together.
Runtime competition gets rougher than model competition
Recent open-model competition is increasingly about runtime announcements as much as model announcements. Models such as Qwen, GLM, Nemotron, and Gemma arrive with different architectures and decoding strategies. Runtimes such as vLLM, SGLang, MLX, Ollama, and llama.cpp then race to absorb those patterns. The question "which model is better?" now decomposes into which runtime, which quantization, which batch shape, and which hardware backend.
MTP makes that comparison more complicated. When people compared only target models, one model file and one benchmark could carry a lot of the discussion. Now the package includes the target model, the drafter, cache sharing, draft length, acceptance policy, memory layout, and hardware backend. The right combination can noticeably improve the experience. The wrong combination can consume extra memory while delivering only modest gains.
So the practical conclusion is not that Gemma 4 is always 3x faster. A more accurate reading is that Google is making local and edge inference acceleration part of the official Gemma 4 distribution path. Model providers are being pulled toward responsibility for not just checkpoints, but also inference strategy and runtime adoption.
Small delays are expensive in agents
For coding agents and business agents, latency is both a UX problem and an operating-cost problem. The benefit of faster token generation is larger when a system performs multiple reasoning and tool-use turns than when it writes a single answer. If an agent reads a codebase, runs tests, analyzes failure logs, writes a patch, and tests again, token generation speed affects the full completion time.
Voice agents are even more sensitive. If the system goes silent for more than a second after the user speaks, it feels uncertain. Drafter-based approaches such as MTP can help predictable continuations move faster and improve the rhythm of the first response and intermediate turns. That is why Google explicitly mentions near real-time chat, immersive voice applications, and agentic workflows in the announcement.
But agent teams should not confuse speed with judgment. A faster model that calls the wrong tool will do the wrong thing faster. MTP does not replace planning quality or tool-use safety. It is an execution strategy for reducing the latency of a model that is already good enough for the task. Product teams should evaluate it as a way to speed up the same target model, not as a smarter model.
What to watch next
Three metrics will probably determine the real value of Gemma 4 MTP. The first is acceptance rate: how many of the drafter's proposed tokens the target model accepts. That is the core driver of speedup. The second is memory overhead. Even a small drafter has to sit beside the target model, which matters on laptops and phones. The third is runtime portability. Google lists several runtimes, but equal stability and ease of use across them is a separate question.
Developers should test against their own workloads. Prompt length, output length, temperature, batch shape, and concurrent users may differ from public benchmarks. Coding agents with long context may run into KV cache and memory pressure. Short, repetitive responses, voice turn-taking, autocomplete, and simple summarization may see larger gains because the next tokens are easier to predict.
This release clarifies the next bottleneck for local AI. Once model quality rises, deployment technology becomes a competitive advantage. Gemma 4 MTP drafters are a sign that this competition has already started. Good local AI products will not stop at picking a model. They will match target models with drafters, choose runtimes carefully, and measure acceptance rate and latency on the hardware where users actually run the system.