Gemini for Science Puts Research Agents on the Nature Test Bench
Google Gemini for Science bundles hypothesis, code, and literature agents, backed by two Nature papers that raise the bar for research-agent validation.

- What happened: Google introduced
Gemini for Scienceat I/O 2026 and began opening three Labs experiments for scientific research agents.Hypothesis Generation,Computational Discovery, andLiterature Insightssplit the workflow across hypotheses, computational experiments, and literature analysis.
- Validation signal: Google paired the product launch with Nature papers on
ERAandCo-Scientist, framing the story around research results rather than a demo alone. - Builder takeaway: Scientific-agent competition is shifting from model answers to the harness that connects literature search, code generation, execution, and evaluation.
- Google is also packaging
Science Skillsfor agent platforms such as Antigravity, tying specialist databases and tool calls into the same workflow.
- Google is also packaging
- Watch: Early access is still centered on Labs and trusted testers, so real-world research quality, reproducibility, and accountability need validation beyond the papers.
Google introduced Gemini for Science at Google I/O on May 19, 2026. The name may sound like a science-flavored Gemini wrapper, but the important part of the announcement is not a single model. Google presented three experimental tools as one research bundle: a system for forming hypotheses, a system for generating and improving computational experiments, and a system for structuring the literature around a research question. It also added Science Skills that can run inside Google Antigravity.
The stronger signal is that two Nature papers arrived with the announcement. The ERA paper covers an AI system that uses and improves scientific software. The Co-Scientist paper covers a multi-agent system for scientific hypothesis generation. Google is positioning Gemini for Science less as a chatbot for scientists and more as a workbench that turns several stages of the scientific method into agentic workflows.
That distinction matters for AI builders. The coding-agent race has already moved beyond "read files and run tests in an IDE" toward questions of safe execution, tool calling, durable state, and evaluation loops. Scientific research faces a similar shift. The model's fluent answer matters less than the evidence trail: which papers supported the claim, which code ran, which metric selected the result, and how failed hypotheses were rejected. Gemini for Science is a useful case study because it shows that shift inside the research lab.
Three experiments split the research workflow
Google's announcement divides the Gemini for Science Labs work into three tracks. The first is Hypothesis Generation, built on Co-Scientist. A researcher defines the problem, and the system uses a multi-agent "idea tournament" that imitates parts of the scientific method: generating, debating, and ranking hypotheses. Google says the resulting claims are linked to clickable citations.
The second is Computational Discovery, based on AlphaEvolve and ERA. This is not merely code completion with a scientific prompt. A scientist provides success metrics, and the agent explores modeling approaches, writes code, evaluates results, and searches for stronger solutions. Google Research's ERA announcement describes a system that combines literature search, code generation, solution search, and result evaluation.
The third is Literature Insights, based on NotebookLM. It searches scientific literature, structures results into tables with user-defined attributes, and lets researchers work inside a corpus through chat, reports, slides, infographics, and audio or video overviews. This part looks familiar because researchers already use many paper-summary tools. Google, however, is placing it as one stage before and after hypothesis generation and computational experimentation, not as a standalone summarizer.
| Experiment | Base system | Research stage | Builder lens |
|---|---|---|---|
| Hypothesis Generation | Co-Scientist | Problem framing, hypothesis generation, review | Multi-agent debate with citation-backed checking |
| Computational Discovery | AlphaEvolve, ERA | Computational experiments, code generation, evaluation | Search and execution loops against target metrics |
| Literature Insights | NotebookLM | Literature collection, comparison, artifact creation | Corpus-aware retrieval and structured result comparison |
| Science Skills | Antigravity, life-science databases | Tool calls, database access | Specialist tool bundles that agents can invoke |
At the surface, Google appears to be wrapping the entire research process in one product family. A more precise read is that Google is decomposing research bottlenecks. The bottleneck in finding a hypothesis is different from the bottleneck in repeating computational experiments, and both differ from the bottleneck in comparing the literature. Instead of claiming that one chat interface solves all of them, Google is attaching agentic tools to each stage.
ERA is a science-coding agent
For developers, ERA is the part to study most closely. According to the Nature abstract, ERA uses LLMs and tree search to generate scientific software that maximizes success metrics. A general coding agent is often optimized for "produce a patch that passes the tests." ERA is aimed at "produce code that improves a scientific metric." The objective is more open-ended, evaluation is more expensive, and the domain knowledge requirement is higher.
Google Research says ERA was tested across benchmarks including bioinformatics, public health, satellite-image analysis, neural-activity prediction, time-series forecasting, and numerical integration. The Nature abstract says ERA discovered 40 new methods that outperformed top human-designed methods for single-cell data analysis, and generated 14 models for COVID-19 hospitalization prediction that outperformed the CDC ensemble and other individual models. Those numbers matter because the claim is not "the model gave a good answer." It is "the system produced repeatable computational results."
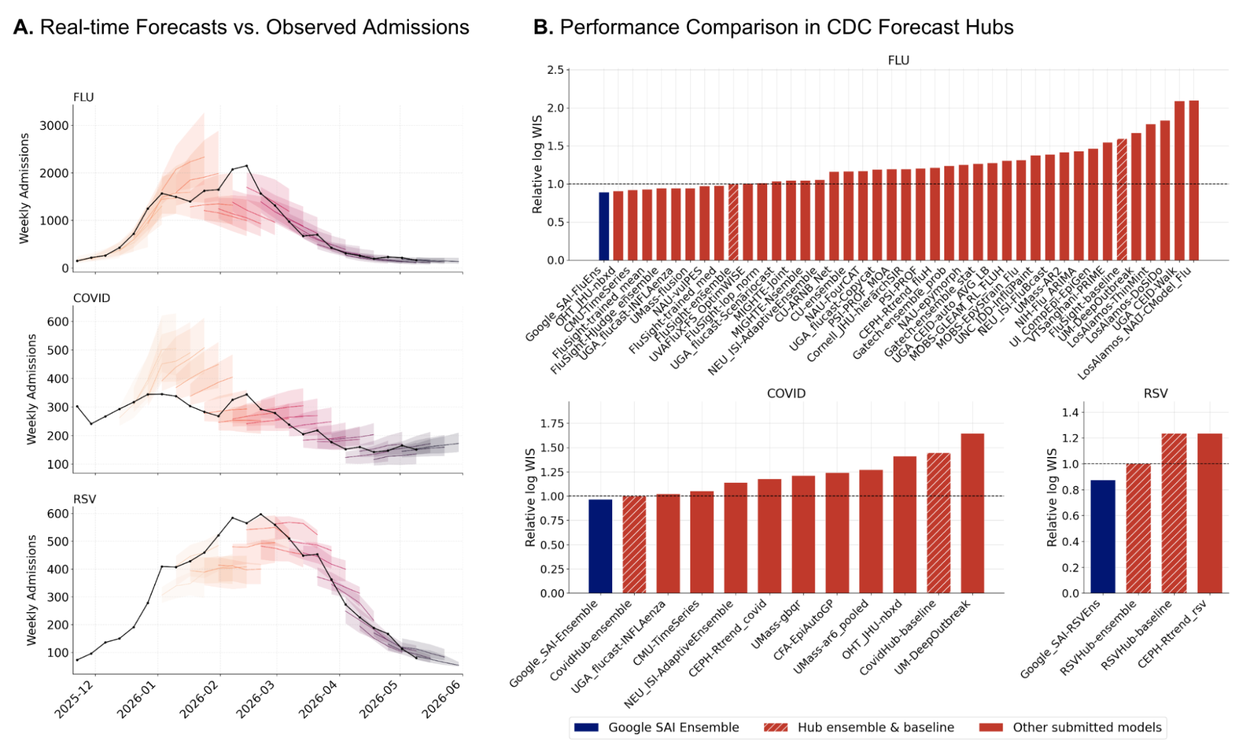
Those results should not be generalized to every scientific field. The Nature page also notes that the public manuscript is an unedited version before final publication. Strong performance on a specific benchmark is not the same as sustained reliability in live research. Still, ERA raises a concrete question for builders: unit tests are not enough to judge whether an agent writes useful code. If the evaluation target is a scientific metric, the agent harness needs to include experimental design, data access, compute cost, and statistical validation.
This is where ERA becomes a more demanding form of code generation than most general coding agents. In a web application, failure is often visible: the build breaks, a test fails, or the UI behaves incorrectly. Scientific code fails more slowly and more ambiguously. A model can produce attractive numbers with data leakage, overfit a benchmark, or hide an unrealistic simplification that does not match the real phenomenon. The core of a scientific agent is therefore not just coding skill. It is the evaluation system and the verification culture around it.
Co-Scientist sells the debate structure, not just the answer
Co-Scientist shows a different direction. Google describes Hypothesis Generation as a system that collaborates with researchers to define a research task, then uses multiple agents to generate, reflect on, rank, and evolve hypotheses. The interesting part is not a story about a model producing a brilliant idea. Google is emphasizing the process: generate ideas, make them criticize one another, attach sources, and narrow the candidates into a form a researcher can inspect.
That design resembles recent agent patterns. Instead of trying to extract the answer from one prompt, systems split roles and evaluate intermediate work. In coding agents, planner, executor, and reviewer roles are now familiar. In scientific hypothesis generation, roles such as generation, reflection, ranking, and evolution address a similar problem. Because a false hypothesis can be written in a very persuasive style, internal criticism and external citations become product features.
There is still a sharp limit. A citation does not make a hypothesis true. Good literature retrieval and a plausible combination of ideas are starting points, not proof. Science ultimately asks for experiment and reproduction. This is why Google emphasized the Nature papers and validation partners across more than 100 institutions. A claim that AI can widen a scientist's ideation space is not enough. The product and the surrounding process must make clear where an idea was valid and what kind of experiment could refute it.
Science Skills are specialist tool bundles for agents
Gemini for Science is also interesting because of Science Skills. Google says this bundle integrates insights from more than 30 life-science databases and tools, including UniProt, AlphaFold Database, AlphaGenome API, and InterPro. Researchers can use those skills inside agent platforms such as Google Antigravity to speed up manual workflows in areas such as structural bioinformatics and genomics.
This matters from an AI-infrastructure perspective. Trying to solve specialist work with only a general model does not scale well. Real research work brings databases, file formats, APIs, domain-specific validation rules, and institutional permissions. Science Skills look less like a prompt pack for scientists and more like a packaging layer for how an agent reaches specific tools and data sources.
The AI developer-tool market is moving in the same direction. MCP servers, connectors, skill files, sandboxes, and audit logs have become core pieces of agent products. Gemini for Science brings that pattern into scientific research. If a researcher asks for a structural-bioinformatics analysis related to AK2 variants, the agent should not merely write an explanation. It needs to know which databases to query and which analysis code to run. Google says early tests with Science Skills reduced analyses from hours to minutes and led to new insight into rare-disease mechanisms involving mutations in the AK2 gene.
That claim needs a careful reading. "Hours to minutes" is a strong product message, and its meaning depends heavily on the task and data used for measurement. The direction, however, is clear. Productizing scientific agents does not end with a model card. It becomes an operations problem that bundles tool access, data provenance, execution environments, and evaluation results.
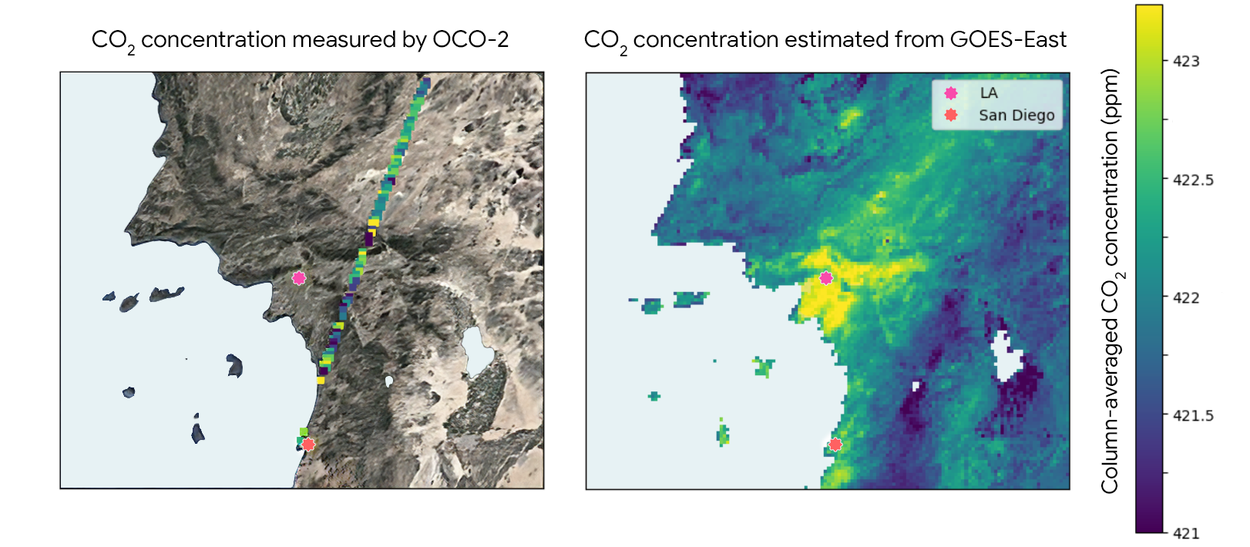
The competition is moving toward validation, not scientist replacement
It is too simple to frame Gemini for Science as "AI replacing scientists." The visible competition is closer to a race to build verifiable research-assistance systems. FutureHouse's Robin, OpenAI's life-science and scientific-reasoning work, Anthropic's enterprise research workflows, and academic search or literature-analysis products all touch parts of the same problem.
Google's advantage is the breadth of its research assets. AlphaFold, AlphaGenome, Google Scholar, Colab, Earth Engine, NotebookLM, Gemini, and Antigravity sit at different layers of the stack. This announcement is a declaration that Google wants to connect those layers into one scientific workflow. The weakness comes from the same breadth. When too many tools are woven together, researchers may struggle to trace where a result came from and which model or database shaped each step. In science, explainability and reproducibility demand a stricter standard than product convenience.
Community reaction shows both sides. In Reddit's r/accelerate, some users described Gemini for Science as one of the most promising uses of AI and argued that bringing knowledge from multiple scientific fields into one problem could change research. In broader Google I/O discussion, however, others remained skeptical because of AI Overview errors and trust concerns around Google's AI products in general. Scientific agents do not escape that trust problem. They face an even higher bar.
Practical signals for development teams
The first signal is that agent evaluation is becoming more concrete. Chatbot evaluation often collapses into user satisfaction or answer accuracy. Coding agents are judged by test pass rates and PR quality. Scientific agents need to go further: experimental metrics, literature evidence, reproducibility, and data-leakage risk. ERA's tree-search structure and metric optimization hint at how specialist-domain agents may be evaluated next.
The second signal is that agent products are increasingly tool bundles. Science Skills emphasize the connection layer more than raw model capability. If your team is building a domain agent, the important pieces are no longer just prompt quality. You need safe data connectors, domain-specific evaluation functions, execution environments, and audit logs for generated artifacts. This is not only a science story. Legal, finance, security, and manufacturing agents are likely to face the same pattern.
The third signal is the pairing of product launch and paper validation. Google showed Labs products on the I/O stage while using Nature papers as evidence. That suggests a change in how AI products are argued for. "Here is a new model" matters less than "here is the benchmark and partner validation this system survived." In science and medicine, where failures are expensive, that standard will be stricter.
Finally, researchers still need to remain in the loop. Google's own announcement frames the system as a way to reduce knowledge-overload and repeated-experiment bottlenecks, not as a way to remove scientists. That is the healthier direction. Scientific agents become useful when they help researchers narrow questions faster, produce more repeatable candidates, and leave transparent evidence for validation. A product that researchers can challenge and trace is more durable than one that asks them to outsource judgment.
Gemini for Science is not yet a finished platform for automating science. It is closer to a starting line. Labs access will open gradually, and validation will continue through trusted testers and institutional partners. Even so, the announcement shows that AI for Science is moving out of paper demos and into developer platforms and product surfaces. Coding agents changed the execution loop of software development. Scientific agents are now asking how much of the hypothesis-and-experiment loop can become a product.
The answer is broader than how smart Gemini is. The important questions are which tools the agent can call, which experiments it can execute, what evidence it preserves, and which failures it makes visible to researchers. That is the real meaning of this Gemini for Science launch. Google did not merely ship a larger chatbot for scientists. It opened a test bench where research agents will have to prove themselves.