Gemini File Search shows RAG is learning to read images
Google added multimodal retrieval, metadata filters, and page-level citations to Gemini API File Search, moving RAG closer to an operational layer for agents.

- What happened: Google added image+text retrieval, metadata filters, and page-level citations to
Gemini API File Search.- The official announcement landed on May 5, 2026, and the docs point multimodal File Search users to
gemini-embedding-2.
- The official announcement landed on May 5, 2026, and the docs point multimodal File Search users to
- Why it matters: RAG's bottleneck is shifting from model answer quality to the operational quality of evidence retrieval.
- Builder impact: Agents can start treating PDFs, charts, screenshots, and image assets as part of one searchable evidence layer.
- Watch: Audio and video are not supported in File Search yet, and permission design still belongs to the product team.

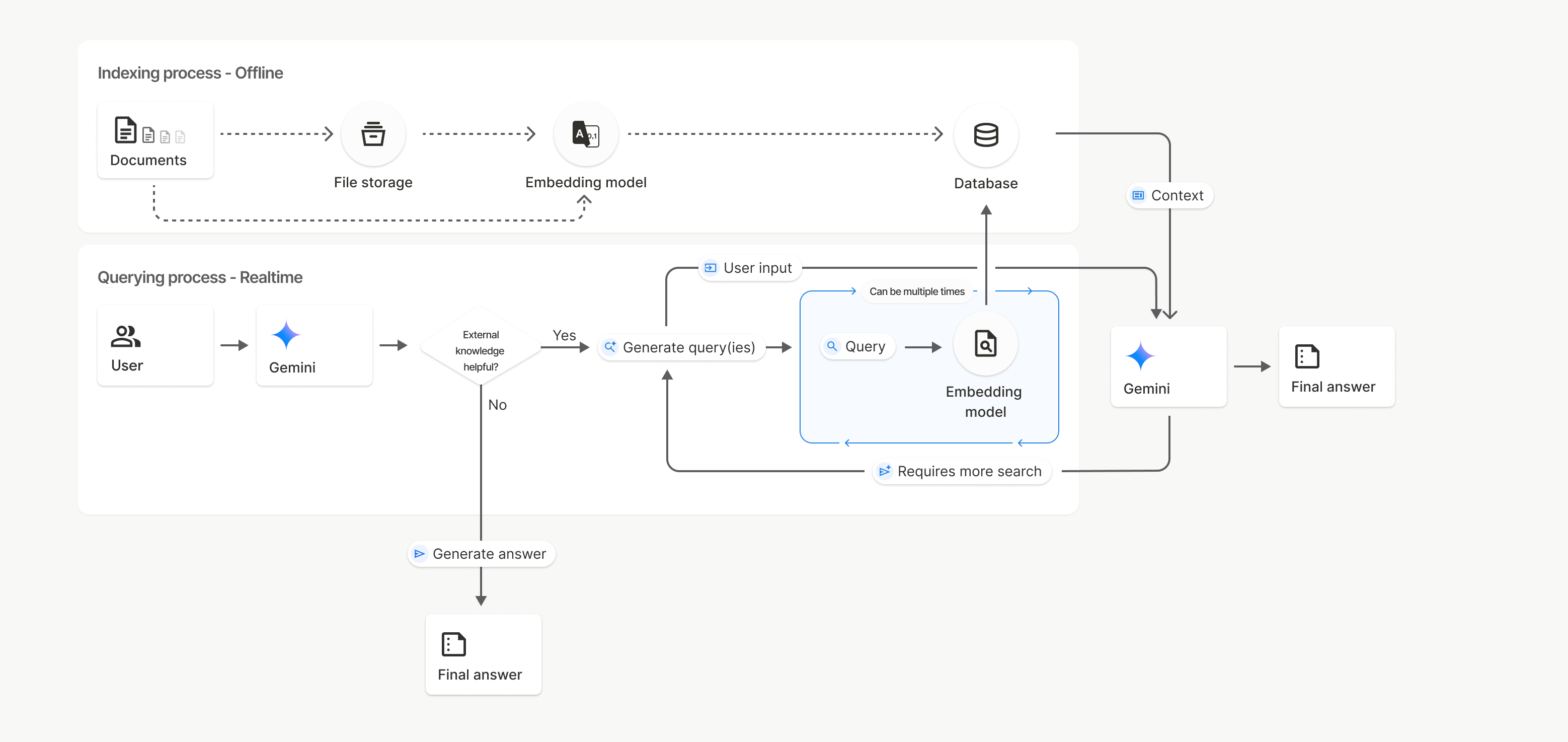
Google expanded the Gemini API File Search tool on May 5, 2026. The announcement itself is compact: multimodal support, custom metadata, and page-level citations. Read together, those three features tell a larger story. RAG is moving from "put a few documents into a vector database and ask questions over them" toward an operational layer that AI agents can use to handle real organizational knowledge.
RAG has been explained too cleanly over the past two years. Split documents into chunks, embed them, retrieve the chunks that look similar to the question, and place them into the prompt. That is a good demo mental model. Production systems break in messier places. Documents are not only text. They include screenshots, system diagrams, product images, tables, slide decks, and scanned materials. Once the corpus grows, "relevant-looking" context can flood the prompt. When a user asks where an answer came from, pointing at a 200-page PDF is not precise enough.
The Gemini API File Search update targets exactly those weak points. Google's official post says File Search can now process text and images together, narrow retrieval with file metadata, and return evidence at page granularity. That may sound like a set of incremental options. In practice, it is a product answer to the question production RAG keeps asking: how do we retrieve the right evidence, from the right slice of the corpus, in a way a human can verify?
Text-only RAG sees only half the workplace
Many RAG pipelines were built around text. Extract text from a PDF, convert webpages into Markdown, split everything into chunks, and send the chunks through an embedding model. That works well for contracts, policies, knowledge-base pages, and internal wikis. It fits a world where knowledge is cleanly written down.
Engineering and product teams rarely work in that world. Architecture decisions live in sequence diagrams. Incident writeups include dashboard screenshots. A design system may express more through component captures than prose. Research documents mix graphs, microscope images, formulas, and tables. Customer-support cases often revolve around a user's screenshot, not the text surrounding it.
Text-only RAG builds workaround pipelines for this material. Teams run OCR, ask captioning models to describe images, create a separate visual index, and then stitch text and image retrieval results back together. That can work, but it is brittle. It is especially fragile inside agent workflows. If an agent asks "find previous cases that look like this error screen" and the visual evidence never enters retrieval properly, every later reasoning step starts from a bad evidence set.
Google says the updated File Search uses Gemini Embedding 2 to handle images and text together. The official docs tell developers to specify models/gemini-embedding-2 when creating a File Search store for multimodal retrieval. The important point is not just that images can be uploaded. The retrieval layer is starting to treat visual information as first-class searchable knowledge.
The three updates work as one system
The feature list is easiest to underestimate if each item is read alone. Multimodal search makes a compelling demo. Metadata filters sound like a normal document-search convenience. Page citations look like a small grounding improvement. Combined, they change the shape of the retrieval system.
| Update | Problem it addresses | Meaning for agents |
|---|---|---|
| Multimodal retrieval | Images, diagrams, and screenshots fall outside the search layer. | Text documents and visual assets can be searched from one evidence pool. |
| Metadata filters | Irrelevant context grows as the corpus expands. | Retrieval can narrow first by department, status, product, region, or access scope. |
| Page citations | Users cannot easily verify where an answer came from. | Before an agent acts, a person can inspect the evidence trail. |
Multimodal retrieval widens the evidence pool. Metadata filters narrow it. Citations make the result inspectable. Good RAG is not a system that retrieves the most material. It is a system that finds the right evidence inside the right constraints and lets the user confirm it.
Metadata filtering is easy to underrate because image retrieval is more visible. In operations, the ability to narrow the search scope often matters more. If a legal assistant should search only final contracts, mixing drafts and restricted documents can damage answer quality no matter how strong the model is. If a support agent searches Korean and Japanese documentation at the same time, accuracy and latency can both suffer. Filters such as department: Legal, status: Final, or region: KR become part of retrieval policy, not just labels.
File Search is a Gemini tool, not a standalone vector database
There is a product distinction worth keeping clear. Gemini API File Search is not positioned as an independent vector database. It is a tool inside the Gemini API. The docs describe a flow where imported files are chunked, embedded, and indexed inside a File Search store. A generateContent request can then specify the File Search tool, and Gemini retrieves relevant context to ground its answer.
That structure is convenient. Application teams do not have to build file storage, chunking workers, embedding queues, vector database schemas, retrieval APIs, and citation stitching from scratch. For small teams, internal tools, and early agent prototypes, that matters. Google's post says the same tool can serve a weekend project and production applications with thousands of users. The marketing range is broad, but the target is clear: teams building on Gemini that want retrieval to become an API capability rather than a separate infrastructure project.
The convenience also has a cost. A File Search store is a managed store attached to Gemini API workflows. Ranking logic, embedding strategy, permission modeling, deletion policy, and observability may be less customizable than a team's own retrieval stack. Large organizations that already have a vector database, data catalog, authorization layer, and audit pipeline may not be able to move everything into File Search.
So the update should not be read as a replacement for every RAG architecture. The more accurate reading is that the managed retrieval layer inside the Gemini ecosystem is maturing quickly. If a product is already centered on Gemini models and the Gemini API, File Search may be the first retrieval layer to try. If the important requirements are multi-model routing, strict internal security policy, ranking experimentation, or on-prem deployment, a custom retrieval layer may still need to remain the source of control, with Gemini File Search used for selected workflows.
Page citations are a trust interface
The trust problem in RAG is not only hallucination. Even when the model gives a correct answer, the product is hard to use at work if the user cannot verify the source. In policy, contract, finance, research, healthcare, legal, and regulatory workflows, "which document?" is often less important than "which page, and in what context?"
The Gemini API docs explain that File Search can return citation information in grounding_metadata. For documents with pages, retrieved_context.page_number can expose the page number. That looks like a small API field, but it is a large UX primitive. A product can show "source: policy PDF, page 37" next to an answer. The user does not have to trust the model; they can inspect the evidence.
This matters even more for agents. A chatbot can be corrected with another question. An agent may route a ticket, draft an approval request, edit a document, or propose a system change. The more the system acts, the more it needs evidence boundaries. Page citation is not a full audit log, but it is a useful ingredient at the human approval boundary.
Mixed data upload: PDFs, images, documents, diagrams
File Search store: chunking, embedding, indexing
Retrieval constraints: metadata filters and multimodal semantic search
Gemini response: grounding metadata and page citations
Google's larger direction is an agentic backend
One day before the File Search announcement, Google announced Gemini API Webhooks. That feature is aimed at long-running agentic applications where polling is a poor fit. Google gave examples such as Deep Research, long video generation, and Batch API jobs processing thousands of prompts. Requests are signed with webhook-signature, webhook-id, and webhook-timestamp headers, and the system can retry delivery for up to 24 hours.
File Search and Webhooks are separate features, but they point in the same direction. Google is shaping the Gemini API less like a one-shot text completion endpoint and more like an agentic backend: store files, search evidence, wait for long-running work, receive completion events, and continue the workflow.
That direction is practical for developers. Most agent applications are hard around the model call, not inside it. Teams have to decide where input data lives, how retrieval scope is constrained, how long-running work is tracked, how failures and retries are handled, and what evidence the user can inspect before approving an action. As Gemini API absorbs more of those surrounding primitives, Google moves from model provider toward agent application platform.
The open questions remain important
The first question is media coverage. The docs say File Search supports text embeddings through gemini-embedding-001 and image or multimodal embeddings through gemini-embedding-2, but they also state that audio and video are not currently supported. The word "multimodal" can sound broad. In this File Search update, the immediately searchable range is mainly text and images. Teams that need to search long meeting recordings, product demo videos, or audio archives still need preprocessing or another API layer.
The second question is authorization. Metadata filters are useful for narrowing retrieval, but metadata is not an access-control system by itself. Sensitive corpora require upload-time permissions, user roles, tenant isolation, retention rules, deletion behavior, and audit logs. Being able to filter on department=Legal is not the same as proving non-legal users can never retrieve legal data.
The third question is retrieval evaluation. Multimodal search does not make every image query accurate. Small labels in diagrams, dense charts, handwriting, code screenshots, and old scans remain difficult. Production teams should not stop at "images are searchable now." They need to measure recall, precision, and citation correctness against their actual corpus.
The fourth question is lock-in. Managed File Search can accelerate the first version, but the index and grounding metadata are tied to Gemini API workflows. Teams with a multi-model strategy should decide how much of the retrieval layer they want to reuse later with OpenAI, Anthropic, internal models, or on-prem systems. Models can change quickly. Knowledge stores tend to outlive them.
What builders should inspect
Whether or not a team adopts this update immediately, it raises concrete design questions.
First, how much of the knowledge base exists only as images? Architecture diagrams, ERDs, product screens, incident captures, and experiment charts are often invisible to text-only RAG. If those artifacts carry important decisions, multimodal retrieval may create real quality gains.
Second, which dimensions should narrow retrieval before the model sees context? Department, country, product, document status, customer tier, release channel, publication date, and confidentiality level all become retrieval design inputs. File Search metadata filters can express these constraints at the API level, but the schema still has to be designed during ingestion.
Third, is citation part of the user experience? Collecting source metadata is not enough if the UI hides it. A strong product should show source files and pages, let users jump into the original document, and distinguish grounded statements from model inference.
Fourth, where should the managed stack end and the owned stack begin? File Search is a strong starting point for prototypes, internal tools, and Gemini-centered products. Teams with strict access control, cross-model retrieval, custom ranking, or on-premise requirements may be better served by keeping their own retrieval layer and attaching Gemini only where it fits.
The next RAG race is operational
LLM competition is still narrated through model performance. For product teams, the retrieval layer often causes the more persistent failures. When an answer is wrong, the team needs to know whether the model lacked reasoning ability, the wrong document was retrieved, visual evidence was missed, or an outdated draft was treated as final. Without that distinction, improvement becomes guesswork.
This File Search update does not solve the whole problem. It does show what Google thinks matters: multimodal evidence, metadata-based narrowing, and page-level provenance. Those are basic building blocks for agents that operate inside real workflows. They are less flashy than an agent demo, but they matter more once the system is used repeatedly.
The bigger shift is that RAG is being absorbed into managed platform capability. When search, storage, citation, and long-running workflow events come from the API provider, the default architecture of agent products changes. Developers can move faster, but they also have to decide which layers they want to own.
Good RAG is not merely a way to make a model sound better. It is a way to constrain, verify, and record what the model used before it answered or acted. Gemini File Search learning to read images matters because enterprise knowledge was already multimodal. The tools are finally starting to catch up with that reality.