Gemini 3.5 Flash 14X and the billing paradox of coding agents
Gemini 3.5 Flash is now in GitHub Copilot, but it arrived with a 14X premium request multiplier. For coding agents, the product meter now matters as much as model speed.
- What happened: Google's
Gemini 3.5 Flashbecame generally available in GitHub Copilot on May 19.- It is available to Copilot Pro, Pro+, Business, and Enterprise users, while enterprise admins need to enable a separate model policy.
- The key number: Google is positioning Flash around speed and agentic work, but GitHub launched it with a
14X premium request multiplier. - Why it matters: The cost of a coding agent is increasingly set by product meters, routing rules, and policy surfaces, not just the model name.
- The same model creates very different operating math in the Gemini API, Vercel AI Gateway, and the Copilot model picker.
- Watch: GitHub says the 14X price is subject to change, but the model-selection calculus is already shifting before Copilot's usage-based billing transition.
The model story out of Google I/O 2026 sounds simple at first. Gemini 3.5 Flash is fast, tuned for agentic work, and strong enough on coding benchmarks to push into territory that used to belong to heavier Pro-class systems. But the number many developers noticed was not a benchmark score. On May 19, 2026, GitHub's changelog said Gemini 3.5 Flash was generally available in GitHub Copilot and would launch with a 14X premium request multiplier.
That number feels counterintuitive. The word Flash usually implies lower latency and a more economical tier. Google also framed Gemini 3.5 Flash as "frontier intelligence with action," emphasizing speed, long-running coding workflows, and agentic tool use. Inside Copilot, though, a user does not see only a fast model. The model picker sits next to plan limits, enterprise policy, premium requests, and a broader shift toward usage-based billing.
That makes this launch more interesting than another model availability notice. It shows how competition in coding agents is moving beyond raw model capability into the product layer that packages, meters, routes, and governs model use. A developer can reasonably assume that Flash means cheap. The product invoice can answer with a different unit of measurement.
Two messages on the same day
Google's announcement was direct. Gemini 3.5 Flash was introduced on May 19, 2026 as the first model in the new Gemini 3.5 family. Google described broad distribution: the default model for consumers in the Gemini app and Search AI Mode, developer access through Google Antigravity, the Gemini API in Google AI Studio, and Android Studio, plus enterprise paths through Gemini Enterprise Agent Platform and Gemini Enterprise.
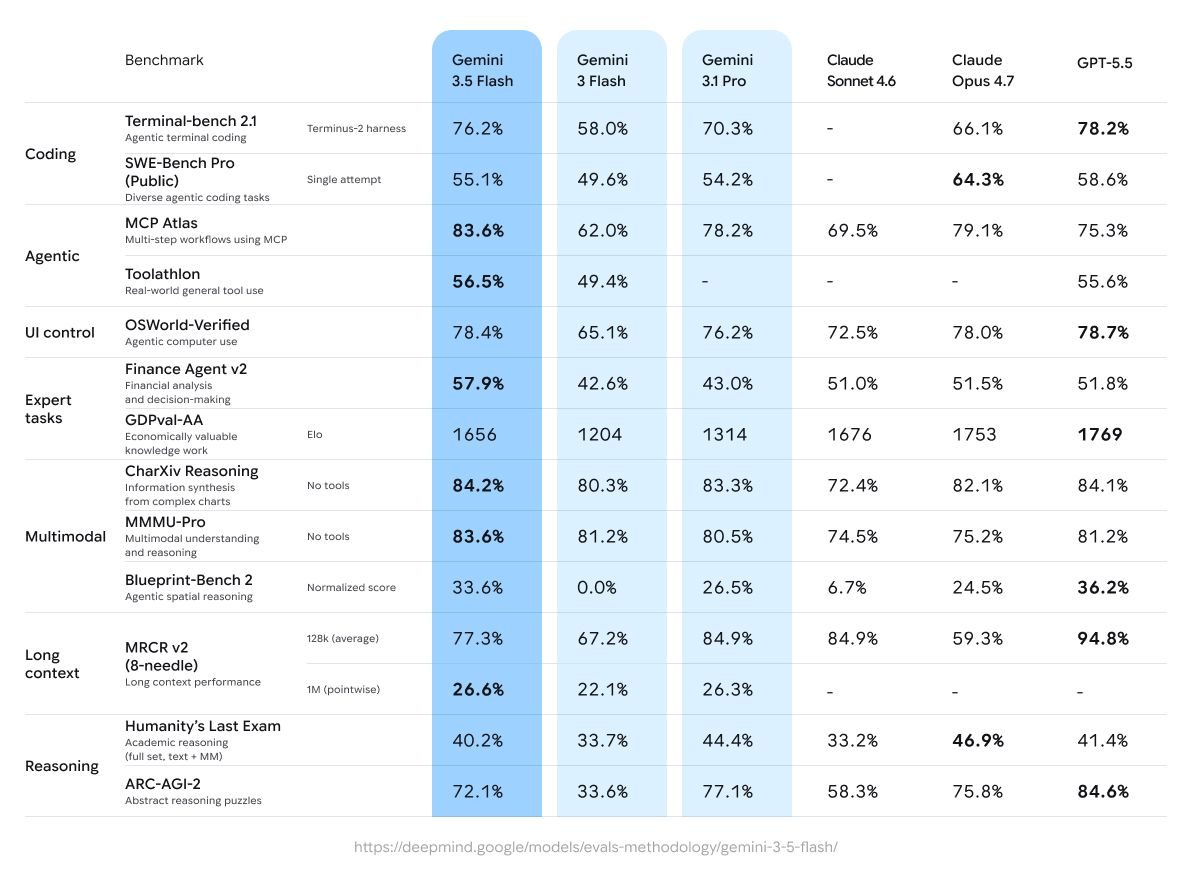
The technical message was "Flash speed with Pro-level work capacity." According to Google's announcement, Gemini 3.5 Flash reached 76.2% on Terminal-Bench 2.1, 1656 Elo on GDPval-AA, 83.6% on MCP Atlas, and 84.2% on CharXiv Reasoning. The Google DeepMind model card says the model was evaluated across reasoning, coding, agentic tool use, multimodal, multilingual, and long-context benchmarks. Its inputs include text, images, audio, and video. Its context window reaches up to 1M tokens, with up to 64K output tokens.
GitHub's message appears aligned on the surface. The GitHub Changelog says Gemini 3.5 Flash in Copilot offers "near-Pro coding quality at Flash-tier speed and cost." It also points to strong tool use, fast responses, and cache efficiency for iterative agentic coding workflows. Supported surfaces include VS Code 1.115.0 or later, Visual Studio 17.14.22 or 18.1.0 or later, JetBrains, Xcode, and Eclipse. Eligible plans include Copilot Pro, Pro+, Business, and Enterprise.
Then the tension appears. GitHub launched the model with a 14X premium request multiplier. The supported models table in GitHub Docs also lists a paid-plan multiplier of 14 for Gemini 3.5 Flash. Existing Gemini 3 Flash is listed at 0.33, and Gemini 3.1 Pro at 1. Within one model family, the intuitive meaning of Flash no longer maps cleanly to Copilot's accounting table.
Why 14X is the story
14X is not a throwaway pricing footnote. A coding-agent request is not like asking a chatbot for one paragraph. An agent reads repository context, compares files, runs tests, parses failure logs, tries another patch, and repeats. To the user, that may look like one task. Inside the product, it can become a sequence of model calls, tool calls, context construction, and runtime decisions.
That is why Copilot uses premium request multipliers. Different models have different inference costs, latency profiles, tool-use patterns, and operational load. Treating every model choice as one identical request would make product economics hard to manage. The risk is that the user's cost intuition comes from model naming, while the product's cost unit comes from a separate platform meter. Flash can signal low latency in the API market and still begin life as a 14X premium request inside Copilot.
GitHub notes that the price is preliminary and may change. So it would be too strong to say GitHub has permanently made Gemini 3.5 Flash an expensive Copilot model. But the timing matters. GitHub has been moving Copilot toward GitHub AI Credits, usage reporting, model-specific multipliers, and enterprise controls. Right before the usage-based billing transition, a high-multiplier model turns model selection into budget design.
The lesson for builders is not "do not use Gemini 3.5 Flash." The sharper lesson is that the API position of a model and its product position inside Copilot are separate facts. Calling the same model through the Gemini API, routing it through Vercel AI Gateway, and selecting it in the GitHub Copilot model picker can create three different cost structures and three different control surfaces.
| Route | What builders get | The calculation to watch |
|---|---|---|
| Gemini API | Direct model calls, token-based pricing, and a custom harness. | You design context collection, tool execution, and policy layers yourself. |
| Vercel AI Gateway | A unified API, usage tracking, retries, failover, and BYOK paths. | Gateway rules and provider-level pricing both matter. |
| GitHub Copilot | IDE integration, repository context, enterprise policy, code filters, and agent UX. | The 14X multiplier and post-transition AI Credit usage need separate tracking. |
Flash's direction and Copilot's direction
For Google, Gemini 3.5 Flash is an important positioning move. In earlier generations, Flash models were broadly associated with faster responses and better cost efficiency. With this release, Google is pushing that tier upward: not a small chat model, but a serious work model for coding and agentic workflows. Google connects it to Antigravity collaborative subagents, UI generation in AI Studio, 24-hour information agents in Search, and personal agents in Gemini Spark.
The model card points in the same direction. Terminal-Bench 2.1 measures agentic terminal coding. MCP Atlas tests multi-step workflows that use MCP. OSWorld-Verified measures computer-use capability. These are closer to agent execution than simple question answering. Google is making the case that Gemini 3.5 Flash is built to push long jobs forward quickly, not just chat lightly.
GitHub Copilot is solving a different problem. GitHub is not only a model provider in this context. It is a developer workflow platform. Users select among OpenAI, Anthropic, and Google models in one surface. Enterprise admins decide which models are allowed. Repository context, public code matching, harmful-content filters, IDE compatibility, plan entitlements, and usage reports all attach to the model. In Copilot, a model is not a standalone SKU. It is a managed resource.
That is why the 14X multiplier is hard to read as simply "Google's model is expensive." It is also a platform signal about the load and product promise GitHub expects when operating Gemini 3.5 Flash inside Copilot. GitHub highlighted strong tool use, cache efficiency, and iterative agentic workflows. Those strengths can return as higher metering when the product has to support them at scale. The better the agent gets at iterating, the more likely users are to hand it larger jobs, and the more precisely the platform needs to measure that work.
Why enterprise admins should care
For an individual developer, 14X may simply mean a quota drains faster. For an enterprise admin, it is a governance event. Copilot Business and Enterprise admins need to enable the Gemini 3.5 Flash policy before users can access it. That turns a model launch into an allow-list, cost-control, and audit decision.
This fits the shape of recent Copilot updates. GitHub has added ways to audit Copilot cloud-agent settings through REST APIs, has introduced lower-cost model options for cloud agents, and has continued to refine usage metrics and billing previews. Model choice is no longer only a developer preference. It is an operating policy: which model appears in which IDE, which agent tasks may use it, what multiplier applies, and how AI Credits are consumed after the billing transition.
Coding agents also accumulate failure cost differently from chat. If a normal chat answer is wrong, the user may stop. If a coding agent is wrong, it might run a test, read the failure, generate another patch, expand context, and try again. Better models can reduce failed loops, but better models also invite bigger delegated tasks. Total cost is not determined by token price alone. It emerges from task size, retry behavior, context strategy, and the platform meter.
Why the community reacted to the multiplier first
In the GitHub Copilot community, the arrival of Gemini 3.5 Flash was quickly framed around the 14X multiplier. That reaction is not just reflexive complaining. Over the past several months, Copilot users have been debating usage-based billing, premium requests, model removals, free-model limits, and cloud-agent cost. In that context, the first impression of a new model is not the benchmark table. It is the multiplier table.
The Google and Gemini communities are having a different argument. There, the focus is more on benchmark strength, real coding consistency, and whether the new Flash tier still feels like the older cost-efficient Flash line. The two reactions do not cancel each other out. Gemini 3.5 Flash may genuinely be a stronger and faster coding model. At the same time, its Copilot price signal can still feel heavy to developers.
The shared point is that agent-era users are not only choosing the smartest model. They are choosing where the model lives, how long it can run, what it costs to retry, whether organization policy blocks it, and what audit trail remains. Model selection is becoming an operations decision rather than a benchmark choice.
Direct APIs and productized agents are diverging
Vercel adding Gemini 3.5 Flash to AI Gateway on the same day is worth noting. Vercel's changelog listed the google/gemini-3.5-flash model name and highlighted coding proficiency, parallel agentic execution loops, instruction following, and multi-turn coherence. AI Gateway wraps model calls, usage and cost tracking, retries, failover, and BYOK into a single API layer.
That is a different bet from Copilot. Copilot is tightly attached to GitHub repositories and IDE surfaces. A direct API or gateway path requires teams to design more of the product integration themselves, but it gives them more control over routing and cost tracking. Enterprise teams may end up splitting usage: everyday IDE assistance and small edits in Copilot, while large repeated evaluations or internal agent harnesses run through direct APIs or a gateway.
The important point is not that one route is always better. The important point is that each route has a different cost unit. Copilot's 14X is a premium-request calculation inside GitHub's product. Gemini API economics depend on tokens, caching, thinking settings, and input-output ratios. A gateway adds routing, observability, retries, and provider failover. One model name can hide three different economic systems.
What to watch next
First, watch whether GitHub adjusts the Gemini 3.5 Flash multiplier. The changelog says pricing is subject to change, so the initial 14X figure may move after operational data or user feedback. If it holds, the model may become a special-purpose Copilot choice for harder agentic tasks rather than an everyday default.
Second, watch auto model selection. A user manually picking a 14X model is different from Copilot auto-routing a task into a high-multiplier model. Under usage-based billing, explainability around automatic routing becomes part of product trust.
Third, watch whether Google's Flash strategy creates pricing pressure in the API market. Google is positioning Gemini 3.5 Flash as a primary model for coding and agents. If it is fast and good enough, many teams will want to run large workloads directly through APIs or gateways. Productized coding agents like Copilot then need to make the value of convenience, policy, audit, and repository integration very explicit.
Fourth, watch how well benchmarks explain real agent cost. Terminal-Bench, SWE-Bench Pro, MCP Atlas, and OSWorld are important signals. But organizations pay for resolved issues, reduced review time, failed retries, policy-compliant execution, and operational visibility. That is why 76.2% and 14X belong in the same story.
Bottom line
Gemini 3.5 Flash is a meaningful launch for Google's model strategy. The Flash tier is moving beyond lightweight chat and into serious coding and agentic workflows. Google's announcement and model card support that claim with numbers: 76.2% on Terminal-Bench 2.1, 83.6% on MCP Atlas, and a context window of up to 1M tokens.
Once it enters GitHub Copilot, however, the same model faces a different set of questions. Which plan exposes it? Does an admin have to enable it? How many premium requests does it consume? What happens after the usage-based billing transition? Can automatic routing explain when a high-multiplier model was chosen?
Model selection in the coding-agent era no longer ends with "fastest" or "smartest." The same model can be a work engine in an API, a routing target in a gateway, and a governed resource inside Copilot. Gemini 3.5 Flash entering Copilot makes that distinction unusually visible. Flash-class speed is attractive, but teams that read the multiplier next to it will make better operating decisions.