When Flash Beats Pro, Agent Economics Take Over
Gemini 3.5 Flash is not just another fast model release. It points to the cost, latency, and routing fight behind coding agents and AI search.

- What happened: Google introduced
Gemini 3.5 Flashand put it into Gemini app, Search AI Mode, Antigravity, and the Gemini API.- In the same announcement,
Gemini 3.5 Prowas still listed as coming next month, while Flash reached live product surfaces first.
- In the same announcement,
- Key numbers: Google cited Terminal-Bench 2.1 at
76.2%, MCP Atlas at83.6%, and4xoutput tokens per second versus a frontier model. - Builder impact: Signals like GitHub Copilot's
0.25xpremium request multiplier show agent operations becoming a cost and routing problem, not only a peak-intelligence race.- Long-running coding tasks, search interfaces, and managed agents are shaped by repeated calls and recovery cost more than by a single polished answer.
- Watch: Benchmarks do not equal agent experience. Tool calls, log interpretation, context retention, and policy controls still need real-world validation.
The most visible model name in Google's I/O 2026 Gemini announcement was, naturally, Gemini 3.5 Flash. In its May 19, 2026 announcement, Google described Gemini 3.5 Flash as "frontier intelligence with action" and said it was available across the Gemini app, Search AI Mode, Antigravity, the Gemini API, AI Studio, Android Studio, and Gemini Enterprise Agent Platform. In the same post, Gemini 3.5 Pro was still marked as coming next month.
That order matters. Older Flash models were easy to understand as the fast and inexpensive option, while Pro carried the harder work. This announcement blurs that line. The model Google pushed broadly first was not Pro. It was Flash. And Google did not place it only in chat. It connected Flash to execution-heavy surfaces such as Search AI Mode, Antigravity, the Gemini API, and Android Studio. Flash is moving from "lighter assistant option" toward "default engine for daily agent work."
For developers, this is more than another model name in a picker. Agent products are call-heavy. A coding agent reads files, runs tests, interprets failure logs, edits code, and loops again. AI search decomposes a question into sub-searches, compares evidence, and builds a response UI. Managed agents navigate the web and call tools inside a sandbox. In those workflows, the decisive question is not only how good the best single response can be. It is how quickly and cheaply a sufficiently capable model can be called many times.
The numbers Google chose to foreground
Google's announcement frames Gemini 3.5 Flash as a new model for coding and agentic workflows. The figures are specific: 76.2% on Terminal-Bench 2.1, 1656 Elo on GDPval-AA, 83.6% on MCP Atlas, and 84.2% on CharXiv Reasoning. Google also said the model produces output at 4x the tokens per second of a frontier model, according to Artificial Analysis.
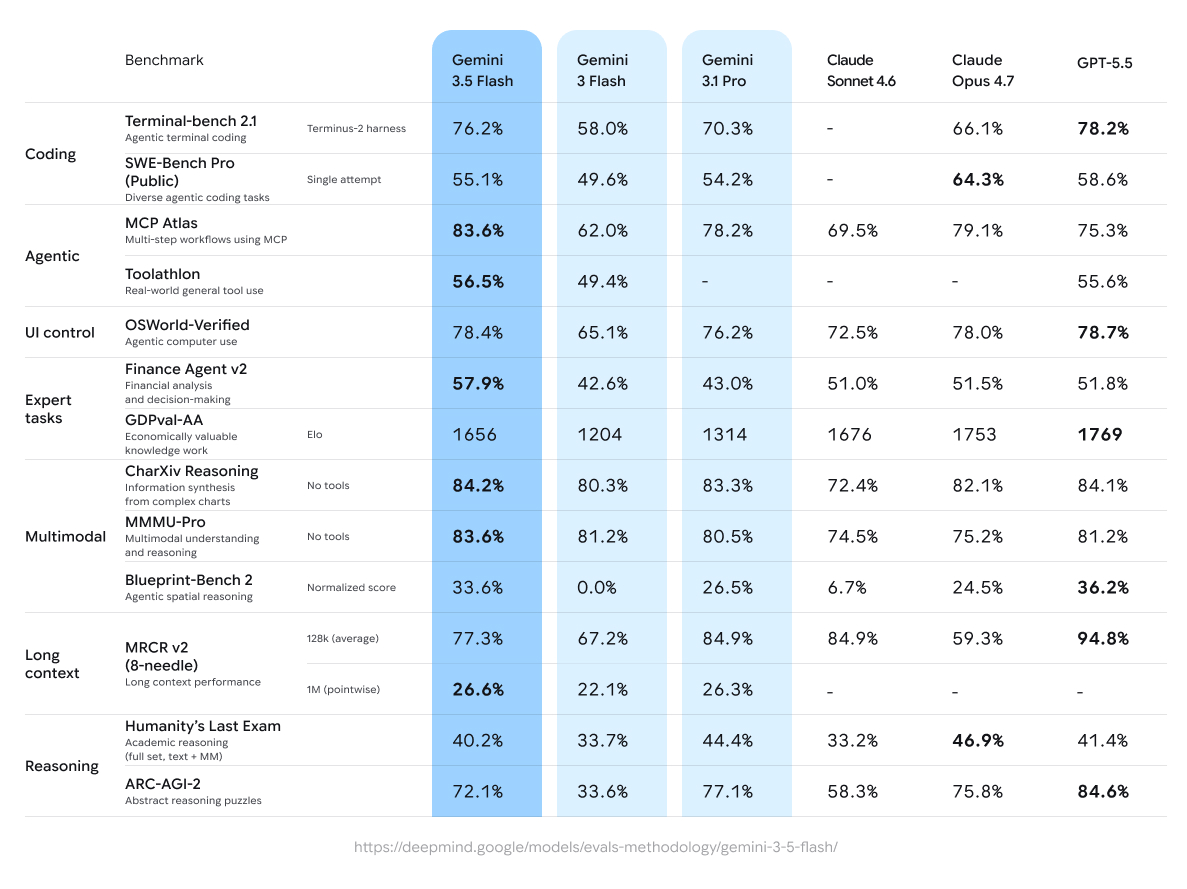
Those numbers point in several directions at once. Terminal-Bench is a signal for how well a model can survive terminal and coding tasks. MCP Atlas is closer to the workflows where agents operate external tools and protocols. CharXiv Reasoning is about reading charts and visual material while reasoning over them. By putting these figures together, Google is positioning Flash not as a simple conversational model, but as one that touches tool use, coding, visual reasoning, and agentic workflow.
The more important word in the announcement, though, is "action." At the same I/O, Google pushed Search AI Mode's generative UI, Search agents, Antigravity 2.0, and Gemini API Managed Agents. These products do not win just because a model writes a long answer well. They need to break a user goal into steps, call tools, preserve state, and return the result as a UI state or a code change. Flash arriving first on these surfaces is a signal that Google is putting baseline agent cost and latency at the center of its model strategy.
Flash arrived before Pro
Model-lineup names make Pro sound higher and Flash sound lower. That makes it easy to shrug at the fact that Flash arrived first. From a product-distribution perspective, the opposite is more interesting. The model installed first across search, IDEs, CLIs, APIs, and enterprise agents shapes the platform's default experience. Pro may become the option for harder work, but Flash is the model that generates usage.
Teams that operate AI products know this tension well. Demos make you want the strongest available model. Production makes you account for average latency, retry behavior, token usage, context length, concurrency, and plan economics. When a user says, "fix the bug in this repository," the model does not answer once. It finds files, reads code, edits, tests, interprets logs, and edits again. One task can contain dozens of reasoning steps and tool calls.
In that structure, model choice becomes an economics problem. A model that is too weak increases retries and raises end-to-end cost. A model that is too expensive cannot be used at every step. Real systems therefore mix fast models, stronger models, long-context models, and visual-reasoning models by task stage. Gemini 3.5 Flash lives in that middle layer. Google's claim is that Flash is capable enough while remaining fast enough to call repeatedly.
| Task stage | What the agent actually does | Model selection criterion |
|---|---|---|
| Exploration | Scans files, docs, issues, and search results quickly. | Low latency and broad throughput |
| Planning | Splits the work and filters out risky changes. | Reasoning quality and context retention |
| Editing | Changes code and reads test logs again. | Coding accuracy and retry cost |
| Verification | Tracks failure causes and summarizes results. | Tool-trace understanding and long-output handling |
Copilot's 0.25x exposes the price tag
Gemini 3.5 Flash reaching GitHub Copilot on announcement day is a separate signal. In a May 19, 2026 changelog entry, GitHub said Gemini 3.5 Flash was available as a model option for Copilot Pro, Pro+, Business, and Enterprise users. GitHub's model multiplier documentation lists Gemini 3.5 Flash at a 0.25x premium request multiplier.
That figure is not the same thing as a public API price. It is a relative value inside Copilot's plans and request accounting. But as a developer-experience signal, it is very clear. Copilot users are no longer using one generic "AI model." They are choosing among models by task. Some work may fit Claude-family models. Some may fit OpenAI models. Some may fit Gemini 3.5 Flash because low multiplier and fast response matter more than peak reasoning.
As coding agents become normal, this model choice will happen more often. A short refactor, a test-log summary, documentation exploration, type-error fix, or pull request description may not require the most expensive model. A complex architecture change, security analysis, or large migration may still demand a stronger reasoning model. Copilot's model picker makes this reality visible to the user. Model routing is moving from hidden platform optimization into an everyday developer decision.
That shift also raises the bar for AI coding-tool companies. Until recently, "which model we use" was a marketing point. The next question is more operational: which model is routed to which task, under what budget, and with what policy controls. Users may not want the same model for fast autocomplete, a slow agent task, background work, and review-comment generation. Model quality still matters, but product quality will increasingly depend on routing and budget control.
How Flash connects search and agents
If you read Google's recent announcements one by one, they look like separate products. Search AI Mode is a search announcement. Managed Agents is a Gemini API announcement. Antigravity is a developer-tools announcement. Gemini 3.5 Flash is a model announcement. Read together, they point in one direction: Google is trying to put fast models, execution environments, generative UI, developer agents, and search surfaces inside the same economic envelope.
Search AI Mode breaks a user's question into multiple sub-searches, then builds an answer and a UI. Search agents extend that pattern toward monitoring prices, reservations, and changing constraints. Gemini API Managed Agents operate in isolated Linux environments where they can work with files, run code, and browse the web. Antigravity coordinates multiple agents from an IDE and CLI. All of these flows assume many calls, many intermediate states, and many recovery paths.
This is where Flash-style models matter. If producing one search result requires several model calls, and completing one agent task requires many tool loops, then output speed and unit cost define the product's possible surface area. Even a very smart model cannot become the default engine if users cannot wait for it or the product cannot absorb the cost. A sufficiently capable and fast model, by contrast, can be installed in many more places as the default.
From that angle, Gemini 3.5 Flash is not just a teaser for Gemini 3.5 Pro. It is infrastructure for Google's agent product line to handle real usage. If Pro handles the hardest work, Flash creates the floor for frequently called work. In usage economics, the floor matters.
What benchmarks cannot answer
Official benchmarks are still not enough to judge an agent model. The quality of a coding agent is more complicated than one model answer. It depends on choosing which files to read, interpreting test failures correctly, resisting unnecessary large edits, ordering tool calls, knowing when to ask the user for approval, and pausing or resuming long tasks without losing the thread.
Community reaction tends to split around this point. Many developers are optimistic about Google's figures and product placement. If a fast Flash model is strong enough, teams can open up agent calls that were previously constrained by cost. Skeptics focus on the gap between benchmark scores and day-to-day agent experience. IDE ergonomics, model stubbornness, recovery after failure, context loss, and tool permission controls shape what users actually feel.
That skepticism is reasonable. A high Terminal-Bench or MCP Atlas score does not guarantee a stable coding agent in every repository. Enterprise environments add even more constraints: codebase permissions, secrets, network policy, log retention, and audit traces. A faster model can attempt more work, but it can also scale the wrong work more quickly.
So the practical question for development teams is not "Is Gemini 3.5 Flash always better than Claude or GPT?" A better question is "Which stages of our workflow can move to a faster and cheaper model?" Log summaries and file exploration may fit Flash. Architecture decisions and security reviews may need another model. Model routing is starting to look less like winner-take-all competition and more like portfolio management.
A practical checklist for development teams
First, split model budgets by task type. Autocomplete, chat, pull request descriptions, test-failure analysis, long-running coding agents, and documentation search have different cost structures. A model with a low multiplier or high output speed, such as Gemini 3.5 Flash, is most realistic in high-repeat sections of the workflow.
Second, measure latency and success rate together. If a fast model fails once and retries three times, total latency and cost can be worse. If a strong model is used for every exploration step, the quota may disappear before users feel the quality difference. Agent products should measure the whole path to task completion, not only average response latency.
Third, preserve tool traces. Once model routing enters the system, failure analysis gets harder. You need to know which model read which files, which commands it ran, and which test failure shaped its decision. "The model was wrong" is not enough information to improve the next routing policy.
Fourth, do not push every model choice onto the user. GitHub Copilot's model picker is powerful, but not every user wants to read a model scorecard before every task. Products need default routing while still allowing explicit model and budget changes for sensitive or expensive work.
Fifth, redefine the role of Pro-class models. As Flash becomes more capable, Pro models may become less of an "always-on default" and more of an escalation path for difficult judgment. Complex design changes, ambiguous bugs, security reviews, and long-term planning can move upward, while repetitive exploration and summarization stay on Flash-style models.
Competition is moving into the operations layer
OpenAI, Anthropic, Google, xAI, and Mistral will keep pushing model performance upward. But the fight over coding agents and AI search will not end on benchmark scores. The differences users feel often happen lower in the stack: whether work starts quickly, whether intermediate state is visible, whether failures are explainable, whether quota disappears unexpectedly, and whether a company can restrict model use according to policy.
Gemini 3.5 Flash makes that competitive axis visible. Google did not wait for the highest-end model announcement before placing Flash into Search, Antigravity, the Gemini API, and Copilot. It paired speed, coding benchmarks, agentic benchmarks, and Copilot multiplier signals. That combination looks less like "a smarter model" and more like "an agent engine that can be called more often."
That does not mean Google automatically wins. Claude Code and OpenAI's Codex line already have strong developer mindshare. GitHub Copilot is becoming a routing hub that can absorb multiple model providers. Cursor and similar tools are trying to own the actual daily workflow inside the IDE. Google has wide surfaces across Search, Android, Workspace, the Gemini API, and Antigravity, but the agent experience developers trust every day will be validated through repeated use, not benchmark slides.
Conclusion: Flash is the usage model
Reading Gemini 3.5 Flash as a simple model launch misses the more interesting signal. Flash reached real usage surfaces before Pro, and that exposes the cost structure of agent products. Search now builds generative UI. Coding agents operate terminals. Managed agents call tools inside sandboxes. In all of these settings, the model is called again and again.
The useful question about Gemini 3.5 Flash is therefore less "Is it the top-performing model?" and more "How widely, how often, and at what predictable cost can it be used?" Google's 4x tokens/sec claim, Terminal-Bench and MCP Atlas numbers, and GitHub Copilot's 0.25x multiplier all point in the same direction. The model race in the agent era is not only fought at the top of the leaderboard. It is also fought in the operational layer that can sustain usage.
Developers and AI product teams should not treat this as a routine model swap. AI calls inside products are less likely to be explained by one model name. A fast model explores, a stronger model decides, a long-context model consolidates, and policy restricts sensitive work. Gemini 3.5 Flash is Google's most practical card in that routing fight. It does not simply replace Pro. It reduces the number of moments where Pro is necessary and widens the base where agent usage can happen.