Gemini 3.5 Flash and the 14x Bill for Fast Agents
Gemini 3.5 Flash pushes speed and agent performance, but Copilot’s 14x request multiplier and early quota complaints expose the new cost bottleneck.

- What happened: Google introduced
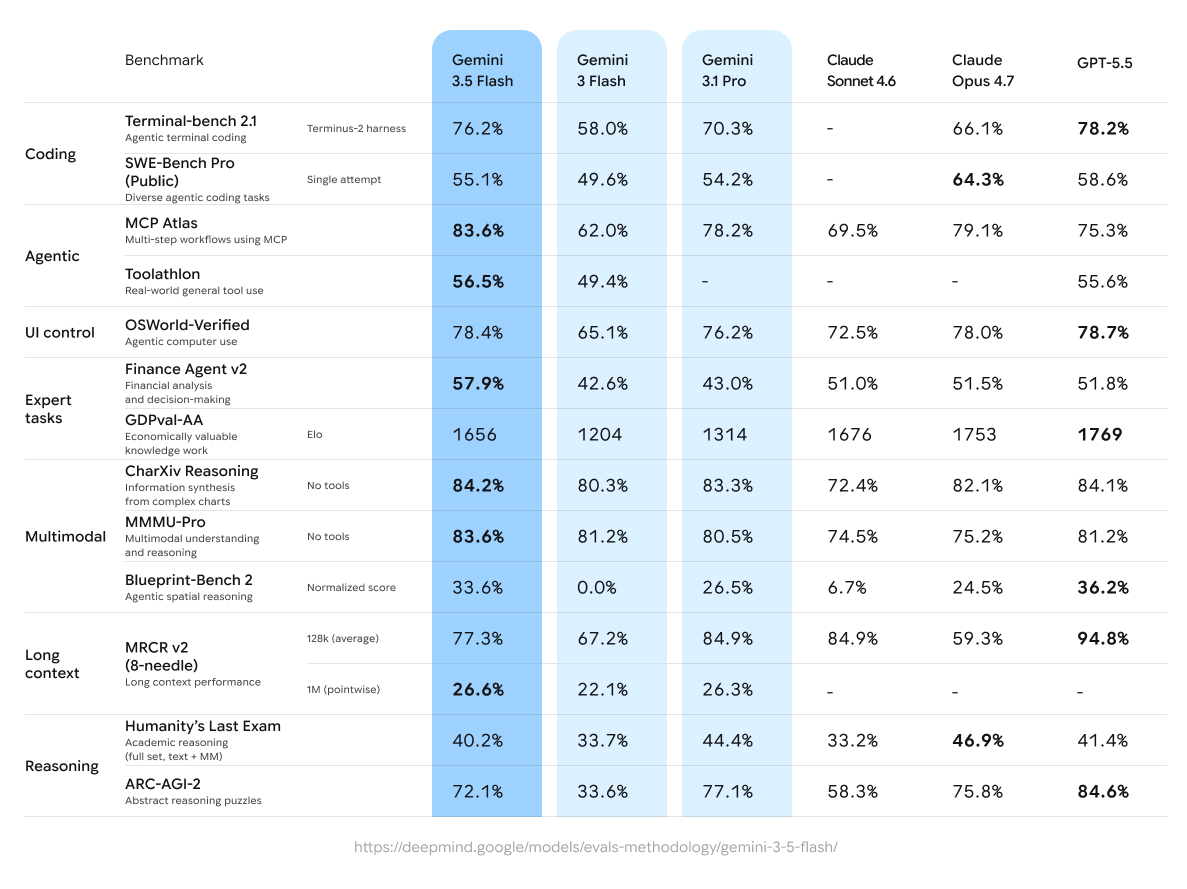
Gemini 3.5 Flashat I/O 2026 and made it available across the Gemini app, Search AI Mode, Gemini API, Antigravity, and Enterprise surfaces.- Google’s published numbers include Terminal-Bench 2.1 at 76.2%, MCP Atlas at 83.6%, and CharXiv Reasoning at 84.2%.
- Why it matters: Google is positioning the Flash tier as a default execution engine for coding and agentic workloads, not just a cheaper assistant model.
- Watch: GitHub Copilot’s 14x premium request multiplier and early quota complaints suggest that fast models can still become expensive when agents loop repeatedly.
- If speed, quality, unit price, and quota policy move separately, the word
Flashdoes not make operational cost predictable by itself.
- If speed, quality, unit price, and quota policy move separately, the word
Google introduced Gemini 3.5 Flash at I/O 2026. At first glance, this looks like familiar new-model news: faster responses, stronger reasoning, better coding, more agentic behavior, and immediate placement inside the Gemini app and Search AI Mode. The part developers should watch, however, is less the model name than the deployment pattern. Google is lifting the Flash tier from "small, cheap helper model" into the execution layer for always-on personal agents, coding agents, generative search interfaces, and enterprise automation workflows.
The official announcement landed on May 19, 2026. In its Gemini 3.5 announcement, Google described 3.5 Flash as the first model in a new family built around "frontier intelligence with action." The availability list is broad: the Gemini app, AI Mode in Google Search, Google Antigravity for developers, the Gemini API in Google AI Studio, Android Studio, Gemini Enterprise Agent Platform, and Gemini Enterprise. In the same day’s developer highlights, Google grouped it with the Antigravity 2.0 desktop app, Managed Agents in the Gemini API, and AI Studio’s Android app generation flow.
That bundle says a lot about Google’s direction. Gemini 3.5 Flash is not being presented merely as a model that makes chat feel snappier. It is the model Google wants agents to call repeatedly across many product surfaces while they do actual work. Google says 3.5 Flash reached 76.2% on Terminal-Bench 2.1, 1656 Elo on GDPval-AA, 83.6% on MCP Atlas, and 84.2% on CharXiv Reasoning. The developer post says it beats Gemini 3.1 Pro on nearly every benchmark and runs four times faster than other frontier models. The name says Flash, but the positioning is closer to "default runtime for scaled agent execution" than to "fast budget model."
The timing also matters because Gemini 3.5 Flash is tied to Gemini Spark. In its Gemini app announcement, Google said more than 900 million monthly users use Gemini across 230 countries and more than 70 languages, then introduced Gemini Spark as a 24-hour personal AI agent. Spark uses 3.5 Flash. Google said it would roll Spark out first to trusted testers, then offer a Beta the following week to Google AI Ultra subscribers in the United States. In other words, 3.5 Flash is both an app model and the execution layer for an agent that follows a user’s digital life.
The more direct developer surfaces are Antigravity and GitHub Copilot. Google describes Antigravity as an agent-first development platform that carries ideas toward production-ready apps. Inside that story, 3.5 Flash powers parallel subagents, long-running tasks, codebase maintenance, document work, financial workflows, and other extended loops. The launch material includes examples such as using two agents to synthesize the AlphaZero paper and build a game over six hours, migrating a legacy codebase to Next.js, and spawning subagents to generate parts of a city scene.
This is where the cost question appears. An agent is not a chatbot that answers once and stops. It plans, reads files, calls tools, retries after failures, interprets logs, runs tests, and summarizes results. When the model gets faster, the loop can become tighter. Users invoke it more often, and the agent framework can generate more invisible intermediate steps. Flash-level latency therefore does not automatically translate into low total spend. Even if the per-token or per-call price is lower, the total bill can rise when repetitions, tool calls, context size, and parallel agents expand.
GitHub’s Copilot announcement puts a concrete number on that tension. On May 19, 2026, GitHub said Gemini 3.5 Flash is generally available in Copilot. Users can select it in Visual Studio Code, Visual Studio, JetBrains IDEs, Xcode, and Eclipse across Copilot Pro, Pro+, Business, and Enterprise. The key line is the pricing note: GitHub says the model starts with a 14x premium request multiplier at launch, and that pricing is tentative and may change.
The 14x figure is more than a price tag. In a tool like Copilot, a user may think they clicked "send" once, but the product has to absorb model pricing, context cache efficiency, tool calls, retries, and long-running task behavior. GitHub describes Gemini 3.5 Flash as offering near-Pro coding quality, Flash-tier speed and cost, strong tool use, fast responses, and high cache efficiency. It still assigns a 14x request multiplier. That combination makes the economics less straightforward than the model name suggests. "Flash" does not automatically mean the end user experiences a cheaper workflow.
The early community reaction points in the same direction. As of May 22, 2026, there was not yet a large standalone Hacker News or GeekNews discussion around Gemini 3.5 Flash. Reddit threads around Antigravity and model benchmarks were more active, and they mixed praise for speed with quota anxiety. One r/google_antigravity user said they spent only 42 minutes using 3.5 Flash high mode to fix setup and migration problems before their usage dropped sharply. Other comments claimed that older Gemini 3 Flash could be used for iterative work all day, while 3.5 Flash hit limits in roughly half an hour.
Those Reddit comments should not be treated as controlled measurements. Plans, regions, model settings, task shape, and actual request patterns are all unclear. Still, they are useful signals about where friction appears first. The complaints are not mainly "the model is bad." They are closer to "the model is good, but it burns through quota quickly." In r/mlscaling, users shared claims of more than 280 output tokens per second while debating whether token price and token volume made their calculated cost much higher than Gemini 3 Flash. In r/GithubCopilot, users compared the 14x request multiplier with other premium model multipliers.
This is why reading Gemini 3.5 Flash as just another Google model launch misses the bigger movement. The AI development-tool market is shifting from "who has the strongest model" to "which platform can place the right model into the right task automatically." GitHub Copilot is strengthening model pickers and routing. OpenAI Codex is spreading across app, CLI, IDE, cloud tasks, and automation. Anthropic Claude Code is pushing into long-running enterprise development. Google is tying together Antigravity, Gemini API, AI Studio, Android Studio, and the Flash tier as an execution model.
Fast models play two roles in that shift. First, they reduce human-facing latency. In a coding tool, the difference between two seconds and twenty seconds changes how people work. Second, they are an attempt to lower the cost of internal agent loops. If every planner, researcher, builder, and reviewer call goes to the largest model, costs can explode. Platforms therefore want a hierarchy: fast models, smaller models, and cache-efficient models as the default, with more expensive models reserved for harder steps. Gemini 3.5 Flash matters because it is one of the largest tests of that hierarchy.
Agent economics, however, are not determined by model unit price alone. Real costs depend on how long context is kept alive, how effectively cache is reused, how many times the model reasons before and after each tool call, how often failed tests trigger another loop, how many subagents run in parallel, and how much validation happens outside the user’s view. Even if Google offers a fast and capable Flash model, Copilot’s 14x multiplier and Antigravity quota complaints tell teams to measure total workflow usage, not just benchmark scores.
The questions for development teams are practical. First, where would Gemini 3.5 Flash actually run? One-shot code completion, file-level refactoring, test repair, browser control, and long migrations have very different usage profiles. Second, should humans select the model explicitly, or should a platform’s automatic routing make that decision? Routing is convenient, but it can make costs harder to explain. Third, is the success metric benchmark score, or completed work per dollar? In agent operations, "did the model answer correctly once" matters less than "how many loops, how much spend, and how much human intervention did it take to finish safely."
The Flash tier becomes especially powerful, and risky, inside coding agents. A fast model can be excellent for small edits, test-error interpretation, log summaries, repository exploration, and repetitive code generation. It is less obviously safe for large architectural changes, ambiguous product requirements, security-sensitive work, and tasks with destructive data risk. Running multiple subagents in parallel can improve the chance of finding a working path, but it increases token usage and request count at the same time. The faster the model, the more important permissions, sandboxing, validation, and budget limits become.
Google’s announcement is interesting because the same economics run through consumer apps and developer tools. In the Gemini app, 3.5 Flash becomes a default model and Spark becomes an always-on agent for everyday work. In developer surfaces, Antigravity and AI Studio use the same model to execute tasks. In enterprise surfaces, Gemini Enterprise Agent Platform aims at workflow automation. One model tier is becoming a shared execution engine for search, personal assistance, coding tools, and enterprise workflows. At that scale, small differences in unit cost and quota policy can shape the entire product experience.
Competitors face the same issue. As OpenAI Codex attracts more users and more automation, rate limits and promotional usage policies become part of the product itself. As Anthropic Claude Code moves deeper into enterprise development teams, the distribution of work between Opus and Sonnet, the cost of long sessions, and team-level usage management become important. GitHub Copilot is already exposing model economics through premium request multipliers. Gemini 3.5 Flash has become one of the clearest tests of the proposition that fast models can make agent execution cheaper.
The heart of this launch is not whether Gemini 3.5 Flash beats Gemini 3.1 Pro. The sharper question is whether the Flash tier can become the default unit of agent operations because it is fast enough, capable enough, and predictable enough. Google’s benchmark claims and distribution strategy support the first two conditions. Copilot’s 14x multiplier and early quota reactions keep the third condition open.
For builders, the practical lesson is to evaluate Gemini 3.5 Flash with real workloads rather than a model table alone. Measure 100 small file edits, 20 automated test repairs, or 10 browser-based regression tasks. Track success rate, average loop count, request multiplier, token usage, cache hit rate, and human interventions together. A fast model can reduce developer waiting time, but automated repetition can spend the budget just as quickly.
Gemini 3.5 Flash is a signal of how Google wants to reorganize model tiers for the agent era: near-Pro quality in a Flash model, default placement inside search and app experiences, an execution role inside Antigravity, and a new option inside Copilot. The most important part of the news is the tension between the numbers. When 76.2% on Terminal-Bench, a claimed 4x speedup, and a 14x Copilot request multiplier sit on the same screen, the question changes. The agent model race is no longer only about who answers faster. It is about who can make fast repetition operationally predictable.