The 160ms Action Channel Voice Agents Need
The DuplexSLA paper reframes real-time voice-agent latency around a 160ms action channel where speech, planning, and tool calls share one timeline.
- What happened: Researchers from StepFun and partner institutions published the
DuplexSLApaper.- It is a Speech-Language-Action architecture that puts listening, speaking, planning, and tool calls onto the same 160ms chunk timeline.
- Key number: DuplexSLA-Bench reports 0.64 seconds of tool-call latency, compared with 2.77 seconds for an ASR+LLM cascade.
- Why it matters: The voice-agent race is moving beyond audio quality toward
action channeldesign.- The checkpoint, inference code, benchmark data, and evaluation harness are still marked as coming soon, so independent reproduction remains open.
The long-running weakness of voice agents is not only that they sometimes mishear speech. Real users pause before finishing a thought, give short acknowledgements while someone else is talking, and sometimes change the request while the answer is still being spoken. Many voice AI systems still handle that pattern as a sequence: VAD detects whether speech has ended, ASR turns audio into text, an LLM creates a reply or function call, and TTS reads it back.
The DuplexSLA paper, posted to arXiv on May 20, 2026, attacks that bottleneck directly. The researchers argue that full-duplex speech models can now listen and speak at the same time, but still lack a native channel for planning and tool use during the conversation. That is why the model name includes Speech, Language, and Action. The core idea is that a voice agent should not wait until it has finished speaking before calling a tool. It should be able to emit planning text and JSON tool calls on a separate action channel while speech continues.
That makes this paper feel closer to agent infrastructure than to a conventional speech-model release. Much of the current agent discussion centers on text-based tool use: browsers, editors, terminals, MCP servers, and function calling. DuplexSLA asks a different question. If a user is speaking and the agent is also listening, answering, and acting, what should the model interface itself look like?
Not An LLM After ASR, But One Shared Clock
The baseline architecture is familiar. Audio comes in. VAD decides when the utterance has ended. ASR produces text. The LLM generates a response or function call. TTS turns the result back into speech. This pipeline is easy to build and debug, and each part can be swapped independently. But it has a structural cost in natural conversation.
First, VAD does not understand silence. A one-second gap might mean the user is thinking, has finished the turn, is offering a brief backchannel, or is interrupting with a new command. Semantic VAD can help, but the paper argues that it still inherits the delay and expressiveness limits of an external detector chain.
Second, tool calls do not fit neatly into a turn-based loop. If the assistant calls a tool before speaking, the user waits longer before hearing anything. If it waits until the spoken response is over, the action arrives one turn late. If the tool call is inserted into the same text channel used for speech, the spoken response itself can become unstable. DuplexSLA responds by separating the speaking channel from the action channel.
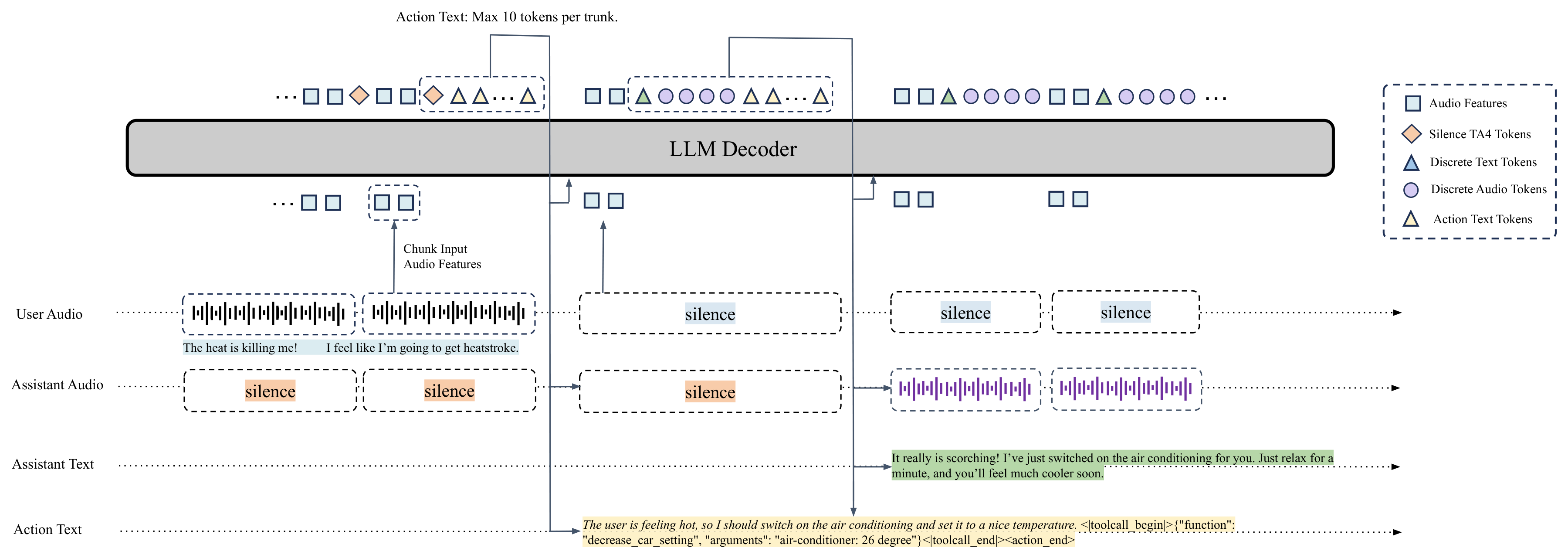
The project's GitHub README describes the same direction. DuplexSLA uses a dual-stream, three-channel formulation: a user audio channel, an assistant audio channel, and an action channel. The user and assistant channels carry audio streams. The action channel is a text-only lane aligned with the assistant timeline. It can contain delayed transcripts, planning text, interaction-control labels, and structured tool calls.
What A 160ms Action Channel Changes
DuplexSLA's basic time unit is a 160ms chunk. In each chunk, the user channel provides two causal audio features with an 80ms stride. The assistant channel uses a TA4 layout: one text anchor plus four discrete audio tokens at 40ms intervals. The action channel can emit up to 10 text tokens per chunk. The paper frames that limit as a deployment budget for real-time inference, not as a fundamental architectural ceiling.
The important shift is that tool calls gain timestamps. In conventional function calling, a developer can usually tell which turn produced a tool call, but not exactly when the model reacted to a phrase. In DuplexSLA, an action object is attached to a specific chunk. If a driver says, "Turn up the AC, play something calm, and navigate to a nearby restaurant," the three tool calls can be aligned to different chunks in the semantic order of the user's request.
| Channel | Per-chunk content | Role |
|---|---|---|
| User audio | Two 80ms causal features | Input lane for continuously listening to the user |
| Assistant audio | One text anchor and four audio tokens | Speech output lane for the assistant voice |
| Action text | Up to 10 text tokens | Lane for planning, control labels, and JSON tool calls |
This design also connects to the debate over whether agents should expose their thinking. DuplexSLA's action channel includes planning text. The paper treats that text less as a user-facing explanation and more as an internal lane for aligning tool calls and turn-taking. In a real product, teams would still need to decide how much of that lane is logged, whether any of it is surfaced to the user, and what security policy applies to it.
Backchannel Is A Serious Agent Test
One of the most interesting words in the paper is "backchannel." In conversation, it means the small acknowledgements and short feedback that do not necessarily take the turn away: "right," "yeah," "mm-hm," or "go on." If a user says "right" while the assistant is speaking, should the assistant stop? Or should it treat that sound as permission to continue? Humans use context. Turn-based voice systems often struggle.
DuplexSLA tries to model pause, interruption, and backchannel as semantic state inside the model rather than as an external VAD decision. The action channel can emit labels such as response, interrupt, and backchannel, while the assistant audio channel continues speaking or falls silent according to that label. This matters because voice-agent behavior depends less on whether sound was detected and more on what conversational act the sound represents.
The difference becomes clearer in high-latency-sensitive environments such as customer support or in-car assistants. If a driver says "I'm cold" while the assistant is still giving a navigation prompt, the AC adjustment should not necessarily wait for the sentence to finish. But if the driver interrupts with a safety-related instruction, the assistant should stop immediately. The same short audio event can require a tool call, a pause, or no interruption at all. The action channel is meant to separate those decisions from speech generation.
2,100 Benchmark Cases And 0.64 Seconds
The paper also introduces DuplexSLA-Bench. The benchmark contains 1,200 turn-taking cases and 900 tool-call cases. The turn-taking set covers normal, pause, interrupt, and backchannel examples, with 300 cases each. The tool-call set covers single-action, multi-action, and backchannel-action examples, also with 300 cases each. In other words, the benchmark does not only ask whether a tool call is correct. It asks when that tool call happened in a real-time speech setting.
The tool-call subset provides the headline numbers. The ASR+LLM cascade baseline reports 91.33% average accuracy and 2.77 seconds of average latency. DuplexSLA reports 85.56% average accuracy and 0.64 seconds of average latency. The cascade is more accurate, but DuplexSLA is roughly four times lower latency. That does not translate directly into commercial product performance, but it clarifies the design trade-off: a voice agent may act somewhat less accurately while acting much earlier.
The context-prefill turn-taking results are also notable. DuplexSLA reports 96.00% accuracy on normal cases, 93.33% on pause, 99.33% on interrupt, and 98.33% on backchannel. The paper compares it with Gemini 3.1 Flash Live and two gpt-realtime-1.5 VAD configurations, which score much lower on backchannel: 40.00%, 0.33%, and 13.00%, respectively. There is an important caveat. Closed-source baselines do not expose internal backchannel labels, so the paper treats backchannel delay as N/A and infers some behavior from audio changes or stop/speak events. That is not a perfectly symmetric comparison.
Still, the result points in a useful direction. Real-time voice-agent evaluation cannot stop at average latency or word error rate. It needs to ask whether the model understood an interruption, whether a backchannel was allowed to pass without breaking the assistant's speech, whether a tool call came too early or too late, and whether the spoken output stayed coherent while actions were emitted.
The Training Data Shows The Cost Structure
DuplexSLA is initialized from Step-Audio-2-mini, an approximately 7B-parameter backbone. The paper describes two training phases. Continued pretraining uses roughly 500k hours of audio and about 1.92 million text samples. Post-training uses roughly 50k hours of audio. The continued pretraining mix includes 320k hours of duplex dialogue, 90k hours of user-channel ASR, and 90k hours of assistant-channel ASR. Post-training includes 36k hours for interrupt, backchannel, and pause behavior, plus 14k hours for tool-call data.
Those numbers make the point that an action channel is not just a prompting trick. Adding a few instructions to an existing LLM is not enough. The model has to learn a format where speech, assistant audio tokens, and action text are aligned to the same chunk clock. Tool-call examples also carry a semantic trigger offset, then get snapped to a chunk index during training. The data problem is not only "which function should be called?" It is also "when should this function be called?"
There is an infrastructure cost hidden in the design as well. The paper describes a 7B-class backbone generating assistant TA4 units while leaving a 10-token action budget per 160ms chunk. Both speech and action text have to fit into the real-time serving budget. A larger model may improve reasoning or tool accuracy, but if it misses the chunk clock, the full-duplex experience breaks. The bottleneck is no longer model size alone. It is serving latency, token scheduling, and the shape of the tool schema.
Why Builders Should Pay Attention
The reason for AI product teams to study DuplexSLA is not that they can drop it into production today. The repository is currently in technical-report mode. The inference code, deployment recipe, model checkpoint, DuplexSLA-Bench evaluation harness, and benchmark data are all marked as coming soon. This is not an npm install moment.
The architecture is still important. Voice-agent teams may quickly discover that attaching a realtime speech API is not enough once tools become part of the experience. Calendar changes, vehicle controls, music playback, payment approvals, and support handoffs all require a record of when the agent heard, spoke, decided, acted, and received a tool result. DuplexSLA's action channel is one attempt to make those events part of the model interface rather than only an application-layer afterthought.
Observability is the other practical angle. Text agents can usually log tool calls, reasoning traces, function results, and retry loops in a relatively clear sequence. Voice agents need timing. The moment a user says "no, not that," the moment the assistant actually stops, the moment a tool call is issued, and the moment the result arrives all affect the user experience and the safety profile. A timestamped action lane could change how teams evaluate and debug voice agents.
What Still Needs Caution
The biggest caveat is reproducibility. The paper and README are public, but the core artifacts are not yet available. There is no released checkpoint, inference server, benchmark data, or evaluation harness at the time described by the original article. DuplexSLA's numbers should therefore be read as results inside the authors' benchmark and comparison setup, not as independently verified product claims.
The second caveat is baseline asymmetry. Closed-source realtime systems do not expose an internal backchannel label. DuplexSLA does, because that label is part of the proposed architecture. That is a real design advantage, but it also means the evaluation has to bridge different kinds of evidence.
The third caveat is safety and permissioning. If an agent can call tools while it speaks, latency falls, but the surface area for mistakes grows. A brief backchannel could be misread as a command and trigger an unwanted side effect. A real interruption could be misread as a backchannel, allowing the assistant to keep speaking or continue with the wrong action. Confirmation, cancellation, undo, and human approval policies become more important in voice agents, not less.
The Next Voice-Agent Bottleneck
DuplexSLA is interesting because it pushes beyond the familiar phrase "more natural voice" and brings the timing of agent action into the model architecture. Many voice-agent demos emphasize response speed and voice quality. The next layer of differentiation may come from whether the agent can call the right tool at the right moment, interpret a short user intervention correctly, and leave behind a verifiable timeline of what happened.
Seen that way, the 160ms action channel is not a small implementation detail. If voice agents are going to use tools the way text agents do, a tool call cannot remain a post-processing event attached to the end of a sentence. It has to become a first-class object on the conversation timeline. DuplexSLA is a research-system version of that bet.
Once the code and checkpoint are released, the harder questions begin. Does the structure hold up in noisy environments? Does backchannel recognition remain stable in multilingual conversations or with multiple speakers? How should confirmation policies work for side-effectful tools in cars or smart homes? And can a 160ms chunk budget survive larger models and more complex tool schemas?
For now, DuplexSLA is less a finished product than a useful signal. Voice-agent competition is no longer only about models that listen and answer. It is moving toward systems that can plan while speaking, understand conversational micro-signals, and put actions on the same clock as the human conversation.