40% of PRs now start in the cloud, Cursor shows the agent operating layer
Cursor Cloud Agent lessons show coding-agent competition moving from models alone to VMs, Temporal workflows, indexing, permissions, and self-healing operations.
- What happened: Cursor published a Cloud Agent operating retrospective and said more than 40% of PRs merged in Cursor now originate in the cloud.
- The official post describes worker pools,
Temporal, VMs, sync servers, and repository indexing as one execution layer for coding agents.
- The official post describes worker pools,
- Why it matters: Coding-agent quality is increasingly decided outside the model call: worktree setup, context sync, live diffs, permissions, and trust.
- Watch: Cloud agents promise parallel development, but they also create new operating risks around repositories, credentials, setup scripts, and production access.
- Cursor writes that trust is difficult and earned, then treats user-provided API keys and GitHub installation permissions as first-class product concerns.
On May 21, 2026, Cursor published "What we've learned building cloud agents". At first glance it reads like a product engineering retrospective. Read more closely and it becomes a useful map of where the coding-agent market is moving. Cursor says Cloud Agents are already used by tens of thousands of developers, and that more than 40% of pull requests merged in Cursor now originate in the cloud.
That number is not a claim about the whole software industry. It describes Cursor's own user base and merged-PR flow. Still, it is a strong signal. A cloud coding agent is no longer just a demo tab beside the IDE. It is creating changes, opening branches, entering review, and contributing to merged work. The more interesting part of Cursor's post is that it does not spend most of its time on model names. It talks about VMs, durable workflows, repository indexers, sync servers, setup scripts, permissions, and trust.
For a long time, AI coding tools were mostly compared through the question "which model fixes code better?" Cursor's retrospective shows that the question is changing. Where does the agent clone the repository? Who installs dependencies? How does the branch state stay synchronized with the local IDE? Can the agent recover from a broken setup? Which secrets can it see? What happens when the task spans minutes, tests, logs, review comments, and PR updates? Those are not edge cases around the product. They are the product.
The 40% PR signal
Cursor's "more than 40%" figure needs careful framing. It does not mean 40% of all pull requests in software development are AI-created. It means that inside Cursor's ecosystem, more than 40% of merged PRs are cloud-originated. Even with that narrower scope, the signal matters because it shows cloud agents moving into real team workflows.
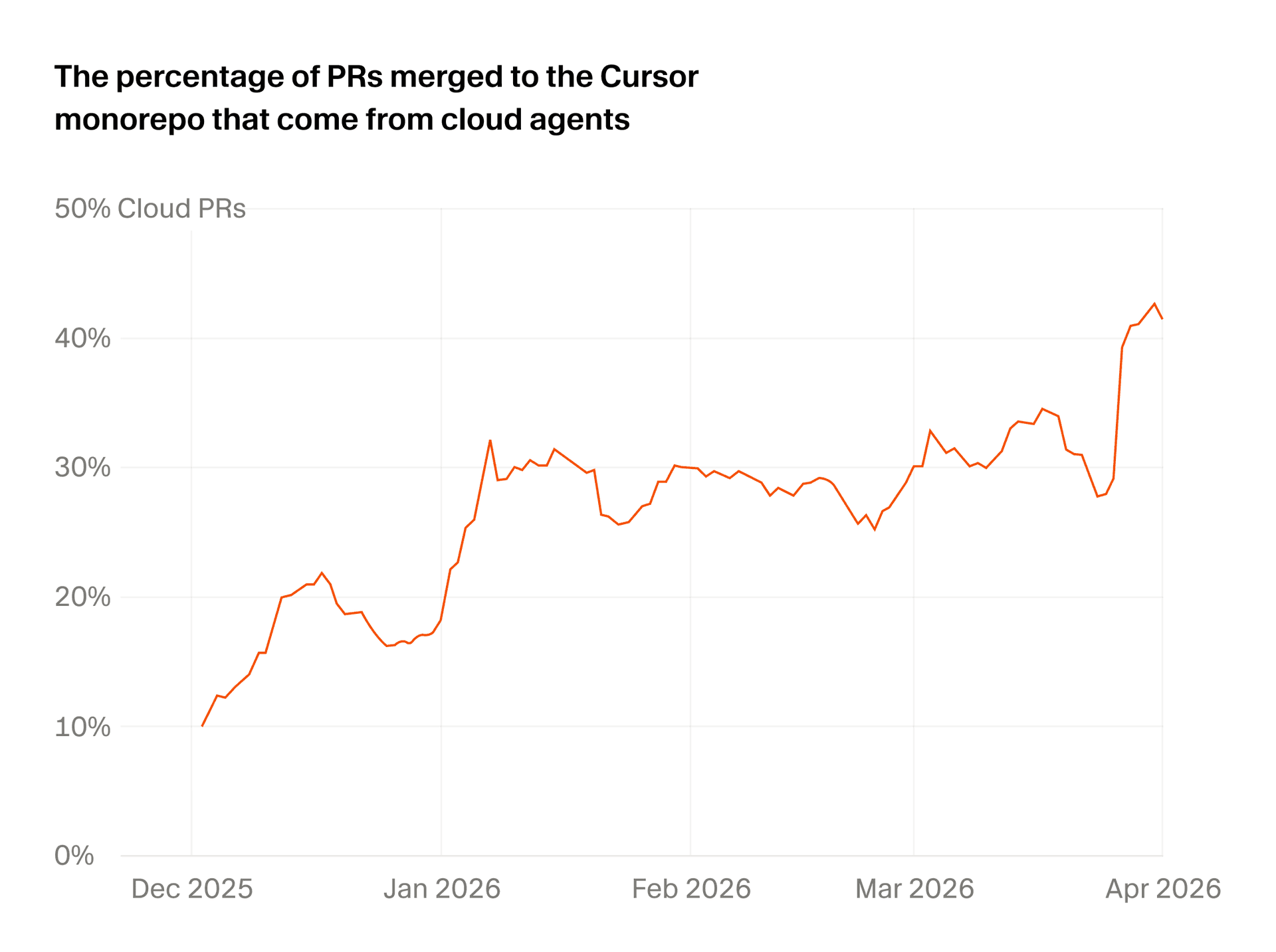
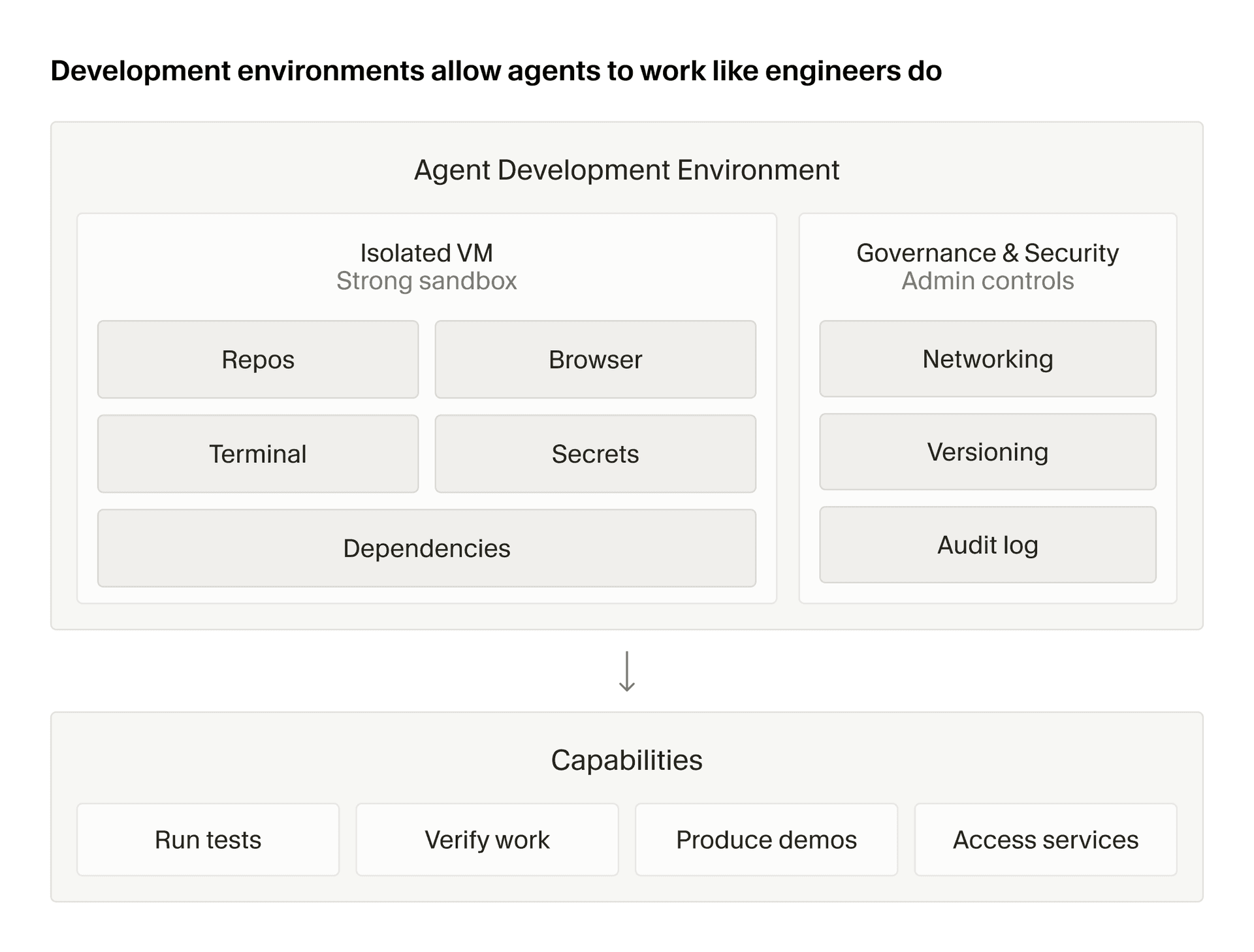
The difference between a local IDE agent and a cloud agent is not just geography. A local agent runs on the user's current machine, current checkout, current terminal, and current credentials. It can start quickly because it inherits a working environment. It also tends to stop when the user closes the laptop or switches attention. A cloud agent runs on an independent VM and durable workflow. It can continue while the developer does something else, and several agents can run in parallel. In exchange, the cloud system must solve initialization, synchronization, security, observability, and cost.
Cursor summarizes the baseline requirements for a strong Cloud Agent experience as five things: an initialized worktree, automatic context, real-time interactivity, consistent behavior, and trust. Each sounds simple until it touches a real company repository. An initialized worktree means cloning the repository, installing dependencies, and getting the project into a state where tests can run. Automatic context means bringing over the relevant IDE state, open files, selections, recent edits, and codebase index. Real-time interactivity means showing the agent's file changes and logs while the work is happening. Consistent behavior needs durable execution, retries, and persisted state. Trust requires a permission model and an environment users can audit.
That list explains why a coding agent is not just a chat feature. A strong model dropped into an empty VM may still fail to produce a useful pull request. A slightly less capable model with accurate repository context, a reproducible environment, and a tight feedback loop may succeed more often in practice. The lesson is straightforward: in agent products, much of the perceived intelligence is built outside the model call.
Architecture reveals the product direction
Cursor's architecture diagram does not present the cloud agent as one remote worker. When a user starts a task, the backend dispatches an action to a worker pool. The worker coordinates long-running work through Temporal actions. Each agent runs inside a VM, while sync servers and repository indexers connect the cloud execution environment back to the local IDE. The core issue is not a single model invocation. It is distributed state across several layers.
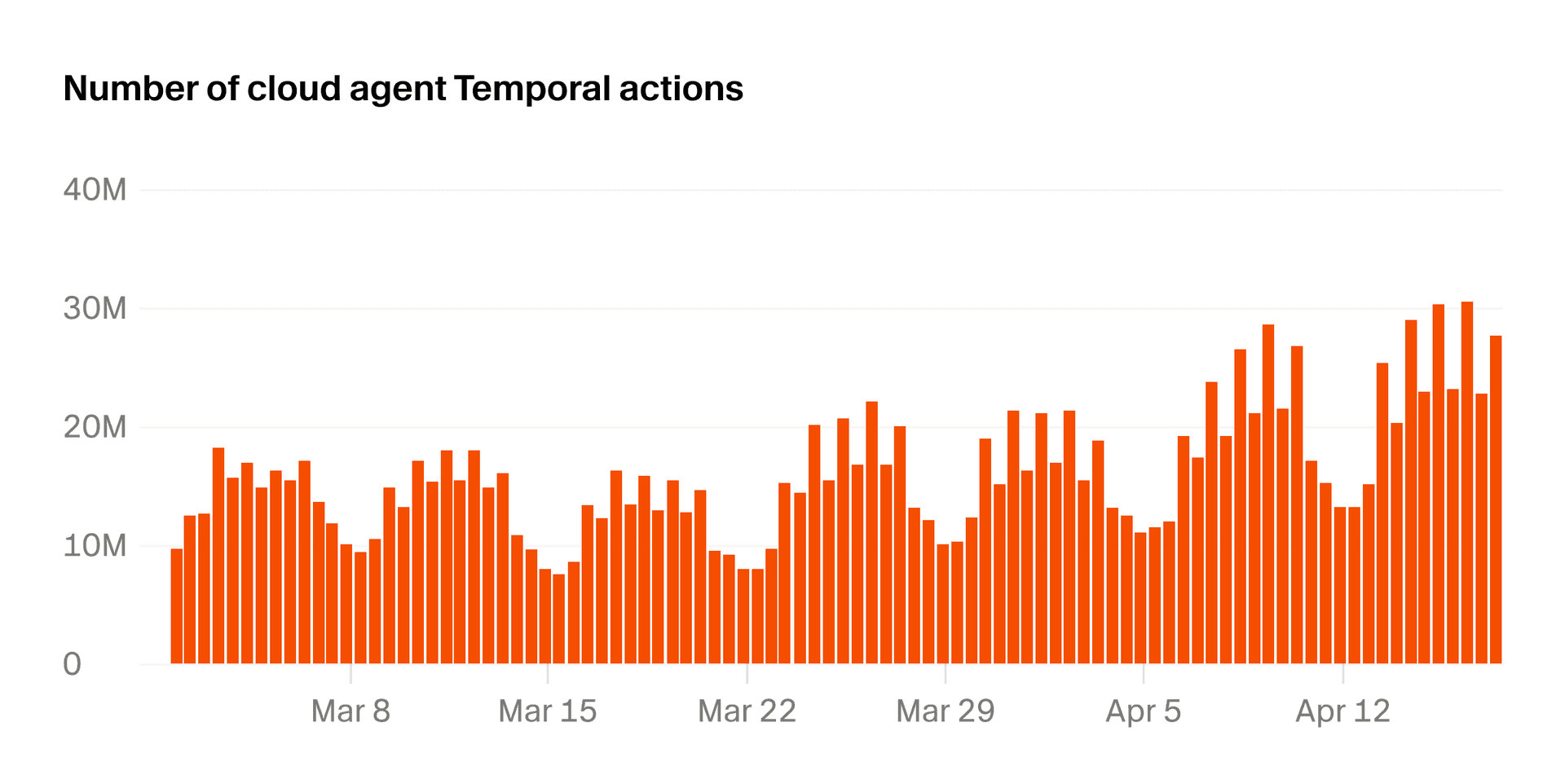
Temporal is important because coding work is not a two-second API call. Dependency installation, test execution, branch pushes, PR creation, user feedback, and follow-up edits form a longer workflow. If a worker dies or a process restarts in the middle, the system needs to resume without making the user feel that the agent simply disappeared. Durable execution turns out to be a product feature.
This is also why the broader AI infrastructure market is converging on sandboxes, remote runtimes, and agent execution environments. Modal talks about agent runtimes and sandboxes as core primitives for AI workloads. Vercel Sandbox, E2B, Daytona, and similar systems provide places where developer agents can run code with stronger isolation than a user's laptop. Cognition's Devin infrastructure writing emphasizes isolated environments, secure remote access, agent state, and collaboration UX. The implementations differ, but the pattern is consistent: a coding agent does not end at the model API.
Cursor's distinctive choice is to keep the cloud agent tightly connected to the IDE experience. If the files a developer sees locally and the files an agent is editing remotely become two separate worlds, productivity collapses quickly. Cursor therefore treats automatic context and real-time interactivity as central requirements. The product is not just "a bot somewhere else." It is a remote execution layer attached to the developer's workspace.
12,000 setup scripts meet real repositories
The roughest part of operating Cloud Agents is setup. Cursor says more than 12,000 different setup scripts have been used with Cloud Agents. That single number says a lot about why real repositories are harder than benchmarks. Every project has its own package manager, runtime version, database assumption, private registry, environment variable convention, and hidden dependency. Some repositories are well documented. Others quietly assume the state of one developer's laptop.
Most coding benchmarks erase this mess. The tests are present, the environment is prepared, and the task has a known answer. In a company repository, the agent often has to first discover how to make the project runnable. Cursor says it built self-healing setup behavior, where the agent can inspect failures such as missing dependencies, OS packages, or database startup issues, then try to repair the setup script or run extra commands. Cursor gives that self-healing attempt three minutes before timing out.
That design points to a larger shift. Coding agents are becoming environment repair workers as much as code writers. A significant portion of real engineering time is spent understanding local setup, reproducing test failures, resolving dependency mismatches, and narrowing gaps between local and CI behavior. If a cloud agent cannot handle that terrain, a clever patch will still struggle to enter the team workflow.
For engineering teams, this is the practical adoption question. "Will this model perform well on a benchmark?" is less useful than "can a fresh VM run our repository with only documented steps?" Teams should look at whether .env.example is current, setup scripts are idempotent, seed data is available, tests can run without production secrets, and private dependencies are clearly documented. Cloud agents do not magically remove technical debt. They expose setup debt in a form automation can either handle or fail on.
Trust is infrastructure, not copywriting
The most careful section of Cursor's post is about trust. Cursor writes that trust is difficult and earned. That is the right framing. A cloud coding agent clones repositories, executes code, talks to GitHub, and may call external APIs. Trust is therefore not a marketing sentence. It is an infrastructure requirement.
The issue becomes sharper in the cloud than in a local IDE. On a local machine, the developer has some direct sense of control over files, credentials, and network context. In a cloud agent, execution happens inside the vendor's environment. GitHub App installation permissions, user-provided API keys, repository checkout, branch pushes, and PR creation are all separate surfaces. A more useful agent often needs more permission, but each permission expands the blast radius of a mistake.
Cursor treats production-only access as an anti-pattern. That boundary matters. If a team can validate work against staging databases, mock services, and scoped tokens, it can reduce risk while still using cloud agents productively. If the only way to test a feature is to hand a remote agent production credentials, adoption becomes a security architecture problem rather than a developer-productivity tweak.
This connects directly to recent coding-agent security discussions: prompt injection, over-permissioned tools, secret exfiltration, and unsafe tool calls are not only "the model answered badly" problems. They are questions about what the execution environment allowed. Cloud agents are powerful because they can run commands. They are risky for the same reason. Product competition is therefore moving toward permission scopes, audit logs, network policy, sandbox isolation, and approval flows.
UI and real-time state are part of performance
Cursor's emphasis on real-time interactivity is easy to underestimate. Coding agents run long tasks. Users want to see what is happening: which files changed, which tests failed, which command is running, and why the agent chose a particular path. If that feedback is slow or vague, the user stops trusting the agent even if the final patch is decent.
Cursor says it placed the PR page and background-agent page on top of the same persistent agent state model. That choice shows that UI is not only a presentation layer. It is part of agent orchestration. The user watches state, interrupts work, adds feedback, changes direction, and reviews output. The cloud agent is not a fully autonomous colleague as much as a long-running participant in a human-in-the-loop development flow.
Good UX here is less about visual polish than precise state transfer. The interface needs to show which changes the agent made, which commands ran, which failures were handled, and which files may still be unstable. This becomes more important when multiple agents run in parallel. Two agents editing the same files create merge conflicts. Two agents fixing the same bug in different ways increase review cost. As cloud agents multiply, orchestration UI and task queues become part of engineering management.
Cognition and GitHub are asking the same question
Cursor is not alone in this direction. Cognition described similar cloud-agent infrastructure requirements while launching Devin 2.1 and its API. Isolated compute, shell and browser access, persistent state, collaboration UX, and secure credential handling are table stakes for Devin-style products. GitHub Copilot coding agent is pushing a workflow where work starts from an issue and ends in a branch and pull request. OpenAI Codex has also been strengthening remote repository-based coding experiences.
The difference is distribution. GitHub already owns the repository and pull-request workflow. Cursor owns IDE attention and live developer context. Cognition owns a product position around autonomous software engineering. OpenAI owns model infrastructure and agent platform momentum. But all of them run into the same operating problem. To change code well, an agent needs execution, permissioning, state, validation, and review.
That means the competition will not be settled by model benchmarks alone. The more durable question is which control plane best matches a team's workflow. GitHub can use issues, PRs, Actions, and repository permissions. Cursor can connect IDE context, local edits, background agents, and cloud VMs. Cognition can focus on long-running sessions and a task API. Teams should evaluate which control plane creates the least friction and the clearest accountability.
What to check before adopting cloud agents
Teams considering Cloud Agent-style workflows should start with repository reproducibility. Clone the repository into a fresh VM and check whether documented steps are enough to run tests. Look for stable lockfiles, explicit system dependencies, private registry setup, automated test databases, and useful validation paths without production secrets. Any setup step that only one person remembers is also an agent bottleneck.
Second, split permissions deliberately. Avoid giving agents production credentials. Prefer read-only tokens, scoped GitHub App permissions, temporary secrets, staging-only resources, and network egress controls. Third, define review boundaries. An agent may open a PR, but automatic merge should require much stricter conditions. Fourth, track cost. Cloud VMs, model calls, indexing, test runs, artifact storage, failed retries, and long sessions all accumulate.
Finally, write better tasks. Cloud agents tend to perform best when the context is clear and the verification criteria are concrete: small bug fixes, dependency upgrades, test repairs, documentation-linked implementation, and reproducible issues. They are weaker when the work depends on ambiguous product direction or domain decisions that need human judgment. In those cases, more generated code can simply move the cost into review.
The real race is the remote workspace
Cursor's Cloud Agent retrospective changes the lens for coding-agent competition. Better models still matter. But the quality developers feel in a product is the product of model capability and execution layer quality. Agents enter the team workflow when repositories are initialized, context is automatic, changes are visible in real time, workflows are durable, and permissions are controlled.
The 40% PR number is a Cursor ecosystem metric, not an industry-wide statistic. But the direction it points to is broader. Coding agents are becoming an operating layer: remote VMs, workflow engines, indexers, sync layers, and permission systems wrapped around model calls. The important question for development teams is shifting from "which AI writes code best?" to "is our repository a safe and reproducible workspace for AI to operate in?"
That shift is uncomfortable but useful. In a well-maintained codebase, a cloud agent can feel like a parallel worker. In a tangled repository, it exposes hidden setup knowledge, fragile credentials, and permission debt. Cursor's post is interesting because it starts as a product lessons article and ends up reading like an operating report from the point where coding agents meet real software factories.