Review comments become run buttons in Copilot Agent Merge
GitHub Copilot app, low-cost model routing, Fix batch, and Agent Merge are turning PR review into an agent execution loop.
- What happened: GitHub is turning PR review into an entry point for agent work through the Copilot app preview and cloud agent updates.
- The sequence was tight: the Copilot app preview on May 14,
0.33xmodel options on May 18, andFix batch with Copiloton May 19.
- The sequence was tight: the Copilot app preview on May 14,
- Why it matters: Coding agent competition is shifting from IDE assistance toward a review-to-merge operating loop.
- Builder impact: Product UI is starting to route simple fixes to cheaper models and harder PR cleanup to stronger models.
- Teams still need explicit policy around cost, limits, branch protection, and who remains accountable for review outcomes.
- Watch: Agent Merge looks less like a replacement for the merge button and more like a way to reduce waiting time around review comments and failing checks.
GitHub quietly moved Copilot into a different part of the software delivery workflow in mid-May 2026. The announcements were not as loud as a new frontier model launch, but the practical change for engineering teams may be larger. On May 14, GitHub published the GitHub Copilot app technical preview. On May 18, it added fast, cost-efficient model choices to Copilot cloud agent. On May 19, it shipped Fix batch with Copilot, which lets users bundle Copilot code review feedback and hand it to the cloud agent.
Reading this as "Copilot got a few new buttons" misses the larger move. GitHub is re-positioning where coding agents start, what unit of work they receive, which checks they must pass, and who carries responsibility up to merge. An issue becomes a task brief. A pull request becomes the status board. A review comment becomes the next agent task. A failing CI check stops being an error log that someone copies into a prompt and becomes queue material for Agent Merge.
The coding agent market has recently been framed around IDEs and terminals. OpenAI Codex has expanded across a local app, CLI, mobile approvals, and remote tasks. Cursor and Claude Code emphasize multiple sessions and longer-running work. GitHub's advantage is different. The place where developers finally accept code - issues, branches, pull requests, reviews, checks, and merge requirements - already lives inside GitHub. The Copilot app and cloud agent updates try to turn that surface into an execution loop.
The Copilot app is a work queue, not just an IDE
GitHub describes the Copilot app as a "GitHub-native desktop experience." The important part of the announcement is not that the app is another editor for writing code. It is that a session can start from an issue, a pull request, a prompt, or a previous session, and each session keeps its branch, files, conversation, and task state separate. The center of gravity is the work item, not the file tree.
The flow GitHub describes is explicit. A user starts from GitHub context. The app's inbox shows issues and pull requests across repositories. A session begins with that context. During the work, the user can inspect the plan and diff, verify behavior through an integrated terminal and browser, and then move back to a pull request. The announcement's product direction is clear: the task is not done just because code changed; it is done when review and tests have made the PR merge-ready.
Most AI coding tools begin with "the agent edits code." The Copilot app starts from a different premise: code must reach a completed state inside the GitHub workflow. That makes issues, pull requests, checks, and review comments first-class inputs. In real teams, the bottleneck often comes after the first patch. Someone has to address review comments, fix failed tests, satisfy branch protection, ask for another review, and get the PR across the line. GitHub is making that final stretch the main stage for the Copilot app.
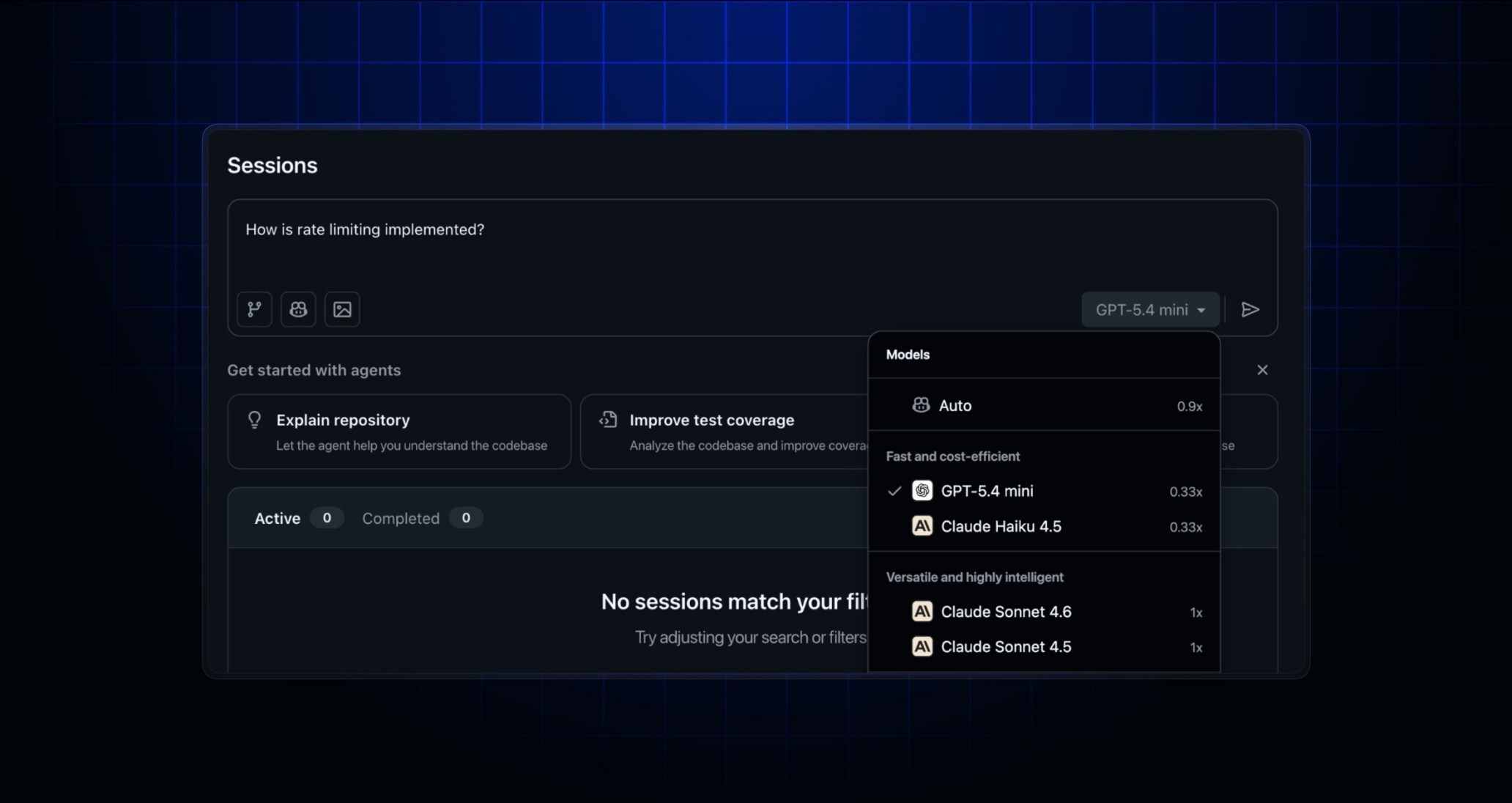
The official model selector image above should be read in that context. If Copilot cloud agent were only a chatbot, model choice would mostly feel like preference. Once PR review handling and CI repair become agent tasks, model choice becomes a cost and throughput control. It becomes natural to send small edits and documentation cleanup to faster, cheaper models while reserving stronger models for complex refactors or hard test failures.
The 0.33x models signal task routing
In the May 18 update, GitHub added Claude Haiku 4.5 and GPT-5.4-mini to Copilot cloud agent. Both are shown with a 0.33x multiplier. GitHub's description is short: users can pick smaller, faster models for simple changes and more capable models for complex tasks.
That number is small, but it matters. If coding agents are one-off autocomplete calls, the cost of a single request can look minor. When a cloud agent opens a PR, processes several review comments, repeatedly fixes failing checks, and keeps a session alive, cost accumulates at the task level. "Use the strongest model for everything" becomes hard to sustain at team scale. The 0.33x option signals that GitHub is beginning to treat agent work as bundles of tasks with different cost classes.
Teams will likely make the same split in practice. Copy edits, import cleanup, snapshot updates, simple lint failures, test name changes, and README improvements may not need the strongest available model. Database migrations, concurrency bugs, security-sensitive changes, flaky test analysis, and broad refactors often do. If Copilot cloud agent puts model choice at the start of a task, teams can manage agent cost by task type rather than only by per-user usage.
The model split does not automatically solve the problem. Smaller models handle simple work cheaply only when the task boundary is clear and the escalation path is defined. Otherwise, a 0.33x task that fails repeatedly can become slower and more expensive than using a stronger model once. Low-cost model routing is a cost control, but it also demands better work decomposition and verification policy.
Fix batch turns review comments into a task queue
The May 19 changelog is more direct. The existing Implement suggestion button in Copilot code review became Fix with Copilot. The Implement all suggestions action in the PR Overview comment became Fix batch with Copilot. A user can select multiple Copilot review comments and send them to Copilot cloud agent in one batch.
The new dialog GitHub describes is also important. Users can choose whether the changes should be applied directly to the current pull request or whether a new pull request should be opened against the current branch. They can choose the model the agent will use and add extra instructions. A review comment is no longer only static feedback. It becomes a selectable work item, and the cloud agent becomes the executor.
This changes the nature of code review. AI code review has mostly been understood as a tool that finds potential problems. Finding a problem does not move the PR forward by itself. A developer still has to read the comment, judge the scope, write a patch, run tests, and push again. Fix batch is the button that delegates that middle stretch to an agent. For repetitive comments around style, null checks, test updates, and small refactors, batching may be more natural than asking a human to process each one manually.
That convenience introduces accountability questions. If AI writes a review comment and AI then fixes it, where should the human reviewer step in? Is it enough to send every comment to a batch and inspect the resulting diff? Or should comment selection itself remain a deliberate human decision? GitHub's dialog asks about application mode, model, and extra instructions because this point matters. Review-to-fix automation is useful, but deciding which comments belong in automation is still a design choice.
Agent Merge targets the last 20 percent
The most interesting name in the Copilot app announcement is Agent Merge. GitHub describes it as follow-through that can process review comments, fix failing checks, and continue toward merge when the user's conditions are satisfied. The key idea is not simply "AI presses the merge button." It is more precise to say that GitHub wants to move the repetitive cleanup people do right before merge into an agent loop.
In many teams, the difficult part of a PR starts after the first commit. CI breaks. A reviewer leaves a small nit. Fixing one thing breaks another test. The merge base gets stale and creates a conflict. These small follow-up tasks create waiting time. A developer has to come back from another task after a notification. A reviewer has to check again. A release branch keeps drifting. Agent Merge is aimed at reducing that waiting loop.
GitHub has an advantage here because it already owns the state. It knows which check failed, which review comment is unresolved, which branch protection rule applies, who the reviewer is, and whether a PR is draft or ready. External IDE agents can reach much of this through GitHub APIs, but an agent inside GitHub can treat the workflow as the product default.
Issue, PR, prompt, previous session
Copilot app session: branch, files, conversation, task state
Fix with Copilot, Fix batch, model selection
Checks pass, review comments resolved, merge condition satisfied
As the diagram suggests, GitHub's direction is not "from chat to code." It is "from work item to mergeable PR." That is why the Copilot app overlaps with IDEs but is not quite the same product. The IDE remains where a developer reads and writes code. The Copilot app becomes a place to see which work is in progress, reopen the right session, and decide which PR follow-up an agent should handle next.
The docs show how many entry points GitHub wants
GitHub Docs on starting Copilot sessions show that Copilot cloud agent has multiple entry points. On GitHub.com, a user can ask for a pull request through /task. In an IDE, they can use Delegate to Cloud Agent. In GitHub CLI, they can run gh agent-task create. In hosts that support the remote GitHub MCP server, they can call the create_pull_request_with_copilot tool. The Raycast extension can also start tasks and show session logs.
That expansion is not accidental. If coding agents are going to be used in real work, users cannot be required to sit in the same IDE at every moment. They need to start a task while reading an issue, reviewing a PR comment, working in a CLI, or using another agentic coding tool through GitHub MCP. GitHub is connecting cloud agent to GitHub.com, IDEs, CLI, MCP, and Raycast because it wants the agent task to become a GitHub workflow primitive rather than an editor feature.
The result described in the docs is consistent. Copilot starts a session, creates or updates a branch and pull request, pushes work, and adds the user as a reviewer when it finishes. The final artifact is not a chat answer. It is a reviewable PR. That distinction matters. For teams to trust AI coding tools, the output cannot remain trapped in a conversation transcript. It needs to become a diff with checks, review, and audit trail around it.
The community is asking about cost and reliability
Community response is harder to summarize as simple excitement. In the r/GithubCopilot discussion around the Copilot app, some comments focused on the value of starting from GitHub context and carrying work through PR review, CI failure, and Agent Merge. Other threads in the same community raise frustration around Copilot's agent workflow maturity, rate limits, and usage billing. Some users still see Copilot as closer to a coding assistant than the agent delegation experience they expected.
That reaction is a product weakness, but it also shows how the market now evaluates coding agents. Users are no longer satisfied by the claim that AI can write code. They ask whether the agent actually finishes work, whether cost is predictable, whether failures are visible, whether multiple sessions can be managed, and whether repository policies still hold. GitHub's 0.33x models, Fix batch, and Agent Merge are product answers to those questions. Whether those answers are good enough will depend on real usage and failure cases.
Teams should not ignore the skeptical part of the response. Sending review comments to a batch can be fast, but selecting the wrong comment can send the agent into an unnecessary refactor. A low-cost model can be economical, but using it in a high-risk area may increase reviewer time. Agent Merge can reduce waiting time, but weak merge conditions can lower a team's quality threshold. Adoption is less about turning on a feature and more about defining boundaries by task type.
Teams need to think of Copilot as a PR operator
The practical interpretation of these updates can be reduced to three questions. First, which review comments should be delegated to an agent? Second, which tasks should use a 0.33x model and which need a stronger model? Third, which failing checks can Agent Merge handle and which must remain human-reviewed?
Documentation typos, lint formatting, small unit test updates, and similar changes may be good candidates for Fix batch. Authorization logic, payment flows, migration scripts, security policy, and concurrency fixes should probably start with a human narrowing the scope, a stronger model, and separate verification. In repositories with strict branch protection, Agent Merge may satisfy mechanical merge requirements while a human still makes the final approval. In internal tools or low-risk automation repositories, teams may delegate more of the follow-up loop.
| Task type | Agent delegation fit | Operating rule |
|---|---|---|
| Docs, lint, simple test updates | High | Candidate for 0.33x models and Fix batch |
| Ordinary bug fix, small refactor | Medium | Require passing tests and reviewer re-check |
| Security, payments, authorization, data migration | Low | Human-scoped, stronger model, separate approval |
| CI failure follow-up | Conditional | Separate flaky tests from real regressions |
Auditability is another important piece. If Copilot cloud agent opens pull requests, pushes commits, and adds reviewers, the team should be able to inspect what prompt the agent received, which comments it handled, which model it used, and which checks passed. GitHub's workflow position makes it easier to attach that information to the PR. Whether the available detail is sufficient will depend on repository policy and enterprise configuration.
The battleground for coding agents is moving
GitHub's updates show where coding agent competition is going. At first, completion quality mattered most. Then chat and agent modes became the focus. Now the key question is how an agent's changes move through review, tests, CI, and merge requirements until the work is actually done.
From that angle, the Copilot app does not only compete head-on with OpenAI Codex, Cursor, and Claude Code. GitHub is using its workflow surface to control the final stretch of work completion. Developers may still read and write code in an IDE. But when a PR is blocked by review comments or failing checks, GitHub can turn that blocker itself into Copilot cloud agent input. That is GitHub's unusual position.
Success is not guaranteed. The Copilot app is still a technical preview, and teams will adopt Agent Merge at different speeds. Complaints about cost and limits may continue. The real quality of low-cost model routing needs evidence. There is also a valid concern that an AI-reviewing, AI-fixing loop can blur reviewer responsibility unless the product makes control and visibility explicit.
Still, the direction is clear. Coding agents are no longer just windows that generate code. They are moving into the operating loop that starts from an issue, creates a branch, opens a pull request, handles review comments, fixes failing checks, and waits for merge conditions. GitHub Copilot's new buttons look small, but their placement is not small. When a review comment becomes a run button, the coding agent battlefield moves from inside the IDE to the PR operations layer.