Four-Nines Agents on Kafka, Confluent Bets on Real-Time AI
Confluent Intelligence Q2 turns Kafka and Flink streams into real-time context, control, and security infrastructure for AI agents.

- What happened: Confluent bundled
Real-Time Context Engine, Streaming Agents, Managed MCP Server, and Agent Skills into GA releases.- The company is positioning Kafka and Flink operational streams as low-latency context infrastructure that agents can read from and write back to.
- Why it matters: The bottleneck for enterprise agents is shifting from model calls to data freshness and permission boundaries.
- Developer impact: MCP clients such as Claude Code, Cursor, and GitHub Copilot in VS Code can now reach deeper into Confluent Cloud resources.
- Watch: More powerful connectivity also expands operational risk. PII redaction, private links, and regional MCP boundaries now matter as much as prompts.
Confluent's Q2 update, announced on May 19, 2026, looks at first like another feature expansion for a data streaming platform. Read from the perspective of AI builders, it is more specific. Kafka and Flink are being recast not just as event transport, but as the real-time context engine that lets AI agents understand current business state and decide what to do next.
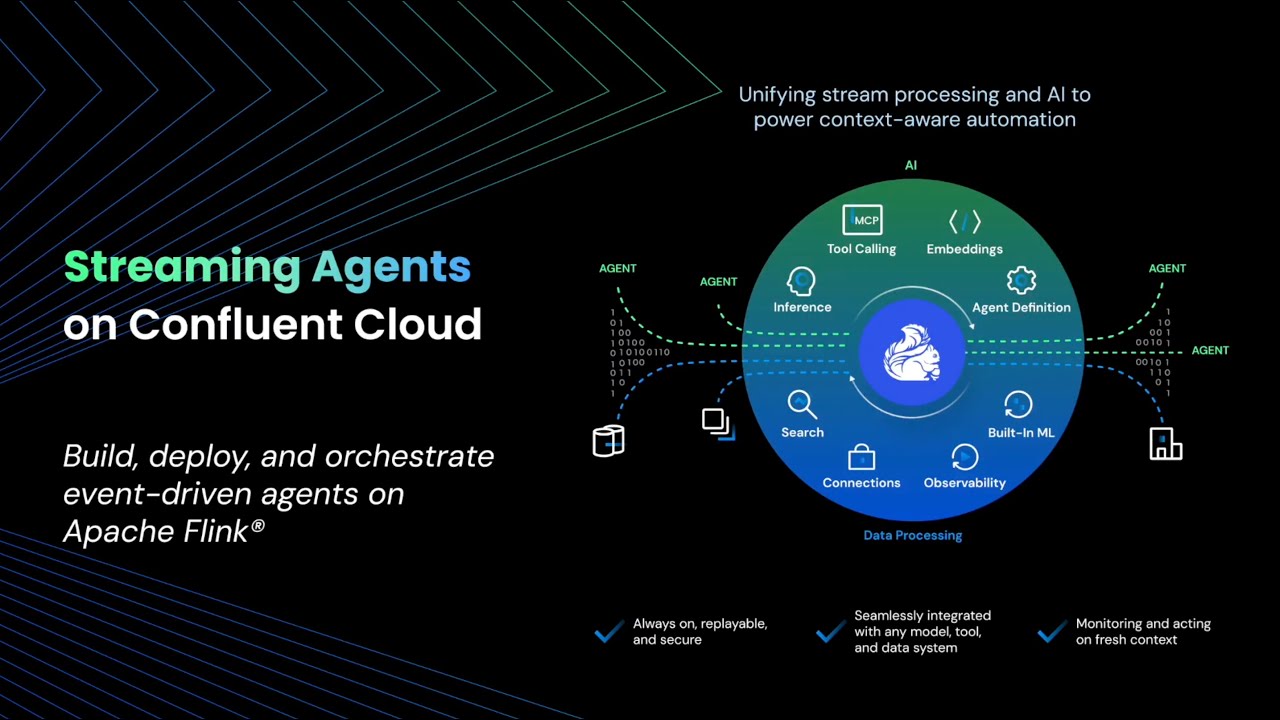
The release centers on four connected pieces. Confluent Intelligence's Real-Time Context Engine moved to general availability. Streaming Agents and Agent Management Console also reached GA. Managed MCP Server and Agent Skills joined them. Confluent described the package as an update for building and securing real-time AI. The product names are numerous, but the message is narrow: agents should operate on live data streams, not stale snapshots.
That distinction matters. Recent agent discussions often concentrate on models, prompts, tool calling, and evaluation benchmarks. In production enterprises, the failure modes are messier. Data is not fresh enough. Personally identifiable information leaks into model calls. Operational permissions are too broad. Failed actions lack the logs needed to reconstruct what happened. Confluent's update reads like an attempt to solve those problems from the data platform side.
The Bottleneck of Data That Moves Slower Than Models
The first generation of generative AI applications had a relatively simple architecture. Put documents into a vector database, retrieve relevant chunks, attach them to a prompt, and send them to a model. That works reasonably well for knowledge bases, FAQ support, and customer service drafts. It is less convincing when an agent has to reason over orders, payments, inventory, security events, IoT status, or user behavior in real time. Yesterday's embedding or a table synced five minutes ago may be a weak basis for an automated decision.
That is the reason Confluent is emphasizing Real-Time Context Engine. The company's Q2 update says the engine supports live queries, filters, range conditions, compound queries, projections, and ordering. The goal is not merely to fetch one record by primary key. It is to let an agent query the latest state maintained in streams, then use that state inside a model call or automation step.
This is less an extension of RAG than a repositioning of the operational data layer. Static document retrieval answers "what do we know?" A real-time context engine answers "what is the state right now?" Agents that do real work need both. Confluent is connecting its existing strengths in Kafka, Flink, Schema Registry, and Stream Governance to the second question.
Kafka topics and Flink streams
Real-Time Context Engine
Streaming Agents and MCP clients
Operational actions, recommendations, detection, automation
What Streaming Agents GA Signals
Streaming Agents is the part of the announcement that most directly targets an agent runtime. Confluent presents it as a set of event-driven agent components that run on top of Kafka and Flink. Developers can build flows that read streaming data, call models, and write results back to streams or external systems.
The important point is that the agent is not confined to a chatbot UI. Many teams still imagine agents as assistants inside a conversation pane. In business automation, the more important shape is often different: a system that watches events without waiting for a user to ask, catches anomalies, drafts actions under policy, and requests human approval when needed. What Confluent calls Streaming Agents is closer to that kind of always-on agent.
Agent Management Console GA points in the same direction. According to Confluent's description, the console is a surface for operating agent inputs, outputs, prompts, models, tools, tables, and logs. If all you observe is the model API call, an agent quickly becomes a black box. Operations teams need to see which event arrived, which prompt and context were assembled, which model and tool were used, and which output left the system. Confluent is trying to pull that observability and operations problem into the streaming platform.
That is also why "four nines" is not just an availability slogan here. Confluent's press release emphasizes reliability and scale for mission-critical environments. Once AI agents move beyond recommendations and touch payments, security, logistics, or customer workflows, predictability of failure modes can matter more than model creativity. Agents running on live operational data need operational contracts before impressive demos.
MCP and Agent Skills Open the Data Platform to Coding Agents
For developers, the most immediate change is the general availability of Managed MCP Server and Agent Skills. Confluent's MCP documentation names Claude Code, Cursor, and VS Code with GitHub Copilot as example clients. In practice, that means there is now an official path for AI coding tools to inspect and, in some cases, act on Confluent Cloud organizations, environments, clusters, topics, schemas, connectors, messages, and metrics.
MCP is now repeated so often that the term can feel tired. In Confluent's case, it has a practical meaning. Data platform work is usually spread across CLIs, consoles, SDKs, Terraform, and REST APIs. To answer questions such as "why did this topic schema break?", "why is this connector failing?", or "how did the recent message shape change?", a developer often has to jump across screens and commands. If the MCP server works well, an AI assistant can package that investigation into a conversational workflow.
The split between global and regional MCP servers is important. The global server handles organization-level resource discovery, connector debugging, and metrics lookup. Regional servers handle access to Kafka clusters, topics, schemas, and messages in a specific region. This is not merely deployment convenience. It is a permission and data boundary. The moment an agent can read both organization metadata and message payloads through the same interaction layer, security review becomes more demanding.
Agent Skills solve a narrower problem than MCP. Confluent provides task-specific guidance for Schema Registry, Apache Flink, Kafka Streams, the Python Kafka Client, CDC to Tableflow, and related workflows. This gives a general-purpose agent product-specific context for how Confluent work should be done. The point is to reduce version drift, missing configuration, and operational convention gaps that appear when a model writes Kafka code from generic memory alone.
| Component | Role | Why developers should care |
|---|---|---|
| Real-Time Context Engine | Exposes live operational state as queryable context | Agents can reason from current state instead of stale snapshots |
| Streaming Agents | Runs event-driven agents on Kafka and Flink | Fits continuous automation and monitoring flows, not just chatbots |
| Managed MCP Server | Connects AI assistants to Confluent Cloud resources | Lets Claude Code, Cursor, and Copilot-style tools assist data platform investigation |
| Agent Skills | Provides agent guidance for Confluent-specific workflows | Steers code and configuration toward product-aware patterns instead of generic LLM guesses |
Why the Security Announcements Are the Main Story
It is not accidental that Confluent also emphasized PII redaction and Azure Private Link in the same announcement. Once live context is handed to models, data protection becomes harder. In document RAG, teams can restrict source collections or strip sensitive fields during indexing. In streaming-agent systems, data keeps moving, and the context supplied to the model can change on every invocation. Poor design can send sensitive fields directly into model requests.
Confluent announced PII detection and redaction functions in Flink SQL. That is a sign that AI security has moved beyond the prompt layer and into the data processing layer. Telling a model not to expose personal data is weaker than identifying and masking personal data before it enters the model context.
Azure Private Link support belongs in the same frame. Confluent says customers can connect Confluent Cloud with Azure-hosted services such as Azure OpenAI, Azure SQL, and Cosmos DB over a private backbone. If an agent application uses models, databases, and a streaming platform at the same time, network boundaries are no longer a secondary setting. Whether data crosses the public internet, which model provider receives which context, and which region reads the message all become part of the design.
These features are not flashy. They are where real adoption often succeeds or stalls. Companies say they want to use AI with their own data, but the actual questions are more concrete. Which data can the model see? Which fields must be masked? Which resource access should require human approval? What log remains after an agent takes action? Confluent is trying to translate those questions into data streaming platform capabilities.
Model Choice Becomes a Part, Context Becomes the Differentiator
The Q2 update also includes model-related changes. Confluent moved support for Anthropic Claude and Fireworks AI to GA, and it mentioned AI_DETECT_ANOMALIES, an anomaly detection function based on TimesFM 2.5. The combination is telling. On one side, the platform calls external LLMs. On the other, it keeps built-in machine learning functions such as time-series anomaly detection close to Flink SQL.
That architecture does not assume one model solves every problem. In operational data, cost, latency, accuracy, and governance all matter. Some tasks are better handled by a general model such as Claude reading context and making a judgment. Some are better handled by a time-series model finding anomalous patterns. Some should remain SQL and rules without a model call at all. Confluent's position is to let those choices be composed inside the stream processing pipeline.
For developers, this is practical. If every decision is pushed into a prompt, debugging gets hard. If preprocessing, policy enforcement, model selection, and result storage are separated into pipeline stages, each stage has a clearer responsibility. When something fails, the postmortem can identify the event, context, function, and model call involved instead of stopping at "the model behaved strangely."
A Quiet Community Reaction Is Also a Signal
This announcement did not appear to create the same immediate discussion on Hacker News or GeekNews that a major model launch would. That does not make it unimportant. It suggests that much of the AI infrastructure shift is moving in the language of procurement, security review, and operations rather than developer memes. A news item about a model coding better can be tested immediately by nearly anyone. A news item about operating Kafka and Flink streams as an agent context engine speaks most directly to teams already running data platforms.
The indirect developer impact is still large. When Claude Code, Cursor, Copilot, and similar tools can use MCP to reach Confluent resources, coding agents move beyond the code repository. They can inspect schemas, investigate connector status, summarize message flows, and draft Flink queries. The positive case is reduced repetitive operational investigation. The negative case is that a poorly scoped permission model can make mistakes spread faster.
That is why MCP adoption cannot stop at "it connects, so it is convenient." Teams need to define which client connects to which server, which regional server can read which cluster messages, how tokens and API keys are issued, where audit logs land, and whether the agent only proposes actions or can execute them. Confluent's Managed MCP Server and Agent Skills do not remove that review. They make the review target more explicit.
The Next Axis of AI Agent Competition
The wrong reading of this update is "a Kafka company added AI features." The bigger pattern is that data platforms, clouds, coding agents, and the MCP ecosystem are starting to converge into one operational surface. Model providers offer longer context and better reasoning. Coding tools automate more work. Data platforms provide the live state and permission boundaries that let agents act.
Confluent's strength in that pattern is clear. For teams that already run real-time event and stream processing infrastructure, the pitch is to avoid building a separate AI data layer and instead put context engines and agent runtimes on top of existing Kafka and Flink operational data. The weakness is also clear. The value grows with deeper adoption of the Confluent ecosystem, and teams building their first agent application may find the architecture heavy.
The competitive set is broad. Databricks and Snowflake are tying AI and data governance around warehouse and lakehouse centers of gravity. Cloud providers can combine their own models, networks, databases, and security services inside one account boundary. LangGraph, Temporal, and custom workflow engines handle agent execution and retries at the application layer. Confluent's differentiation is the claim that the moment an event happens, and the moment operational state changes, should be usable as AI context.
The practical questions for developers and AI teams are straightforward. Does the agent need documents, current state, or both? If it needs current state, where is that state computed most reliably? Which PII must be removed before a model call? Should the agent read only, or can it write and take action? Confluent's announcement asks teams to pull those questions into the first step of infrastructure design rather than treating them as late-stage compliance work.
The core of the news is not that Kafka is "doing AI." It is that as AI agents enter real workflows, context has to become more real-time, permissions have to become narrower, and observability has to become more detailed. Confluent Intelligence's Q2 update is a data streaming platform version of that argument. As model competition accelerates, the competition over what the model is allowed to see and what the agent is allowed to do is accelerating with it.