Command A+ on two H100s, and the cost threshold for sovereign AI
Cohere Command A+ is an Apache 2.0 open model aimed at enterprise agents, private deployment, and the practical cost of sovereign AI.

- What happened: Cohere released
Command A+under the Apache 2.0 license.- It is a 218B total, 25B active MoE model that Cohere says can run in W4A4 form on two H100s or one B200.
- Key numbers: 128K input, 64K output, 48 languages, text/image input, and tool use are bundled into one model.
- Why it matters: Open-model competition is shifting from scoreboards toward deployment cost, control, and operational rights.
- Cohere's claim of 16% better Korean token efficiency makes this relevant to multilingual enterprise-agent economics.
- Watch: The real test is whether 128K context and a large MoE model stay reliable under independent enterprise workloads.
Cohere introduced Command A+ on May 20, 2026. At first glance, the announcement looks like a familiar model release: faster, stronger, more languages, better agent work. The actual signal is not one benchmark number. It is the deployment condition. Cohere released the model under Apache 2.0, uploaded BF16, FP8, and W4A4 versions to Hugging Face, and says the W4A4 variant can run on a minimum setup of two H100s or one B200.
That number matters because the AI competition in 2026 is moving from "who has the smartest model" to "who can place the model inside real business data." Finance, government, pharma, manufacturing, and telecom teams do not move on model quality alone. They care where data sits, who sees logs and permissions, whether inference cost is predictable, and what audit boundary remains when an agent calls tools. Cohere's long-running sovereign AI language is less an abstract political slogan than a procurement, security, cost, and operations story.
Command A+ pushes that strategy at the model layer. Cohere says the model has 218B total parameters and 25B active parameters in a sparse Mixture-of-Experts architecture. Instead of using every parameter on every token like a dense model, it activates only a subset of experts per token to reduce compute. That is the first hook of the launch: the language of a 218B-class model appears next to the operational language of 25B active parameters.
Why Command A+ now
Cohere has been moving more clearly toward enterprise AI over the last several months. North is its enterprise AI workspace. Compass is its enterprise search and discovery system. The Command family handles generation, while Embed and Rerank sit under retrieval-augmented generation. In May, Cohere also acquired Reliant AI, strengthening its position in life sciences literature analysis and regulated workflows. Command A+ is the next piece. Cohere is not only trying to own the application and search layers. It is also giving enterprises a way to own the model that performs the inference.
The open-model market around it has changed too. Qwen, Mistral, DeepSeek, Z.ai, and Reflection AI have already raised expectations for public and open-weight models. "Open" is no longer enough by itself. Teams now ask whether the license works commercially, whether the model runs in familiar runtimes such as vLLM or Transformers, whether quantized versions are actually provided, and whether long context and tool use were designed for agent workflows.
Cohere's announcement is shaped around those questions. Command A+ puts Apache 2.0 licensing, vLLM and Transformers support, Hugging Face distribution, 128K input context, 64K max generation, text and image input, tool use, and reasoning output at the center. It targets teams that do not only want to call a model through an API. It targets teams that want to operate the model in their own environment.
The 218B model that computes like 25B
The most interesting part of Command A+ is that it uses a different grammar from dense-model competition. Cohere labels the model as 218B total and 25B active. The Hugging Face model card describes Command A+ as a decoder-only sparse MoE Transformer with 8 of 128 experts active per token, plus a shared expert applied to all tokens. Its attention layers mix sliding-window attention with global attention.
That does not make the model small. Operators still have to handle large weights and memory demands. The point is narrower: reduce the compute activated during inference while keeping some benefits of a larger model. This is also why Cohere emphasizes W4A4 quantization. According to the announcement, Command A+ ships in BF16, FP8, and W4A4, with W4A4 aimed at a minimum setup of one B200 or two H100s.
The Hugging Face model card adds more implementation detail. The W4A4 version requires vLLM >=0.21.0, and Cohere recommends installing its cohere_melody library for correct response parsing and tool-call handling. This is not the kind of open model that someone casually downloads and runs on a laptop. Two H100s remain far beyond the personal developer threshold. But for enterprises and public institutions, the calculation is different. Instead of sending every call to an external API, they can place the model on internal GPU resources and control permissions, logs, and data boundaries.
vllm serve CohereLabs/command-a-plus-05-2026-w4a4 \
-tp 1 \
--tool-call-parser cohere_command4 \
--reasoning-parser cohere_command4 \
--enable-auto-tool-choice
This example follows the serving shape from the Hugging Face model card. The important part is not just the model call. It is the surrounding options: tool-call parser, reasoning parser, and automatic tool choice. Cohere is signaling that Command A+ is not merely a chat model. It is designed for agent runs that include tool calls and reasoning traces.
Cohere leads with work-shaped metrics
Cohere says Command A+ consolidates the abilities that previously sat across Command A, Command A Reasoning, Command A Vision, and Command A Translate. The company frames it as one model for reasoning, multimodal input, tool use, and multilingual work. The number of supported languages expands from 23 to 48, and Korean appears in the Hugging Face model card's supported-language list.
Cohere's official benchmark chart shows where the company wants attention to land.
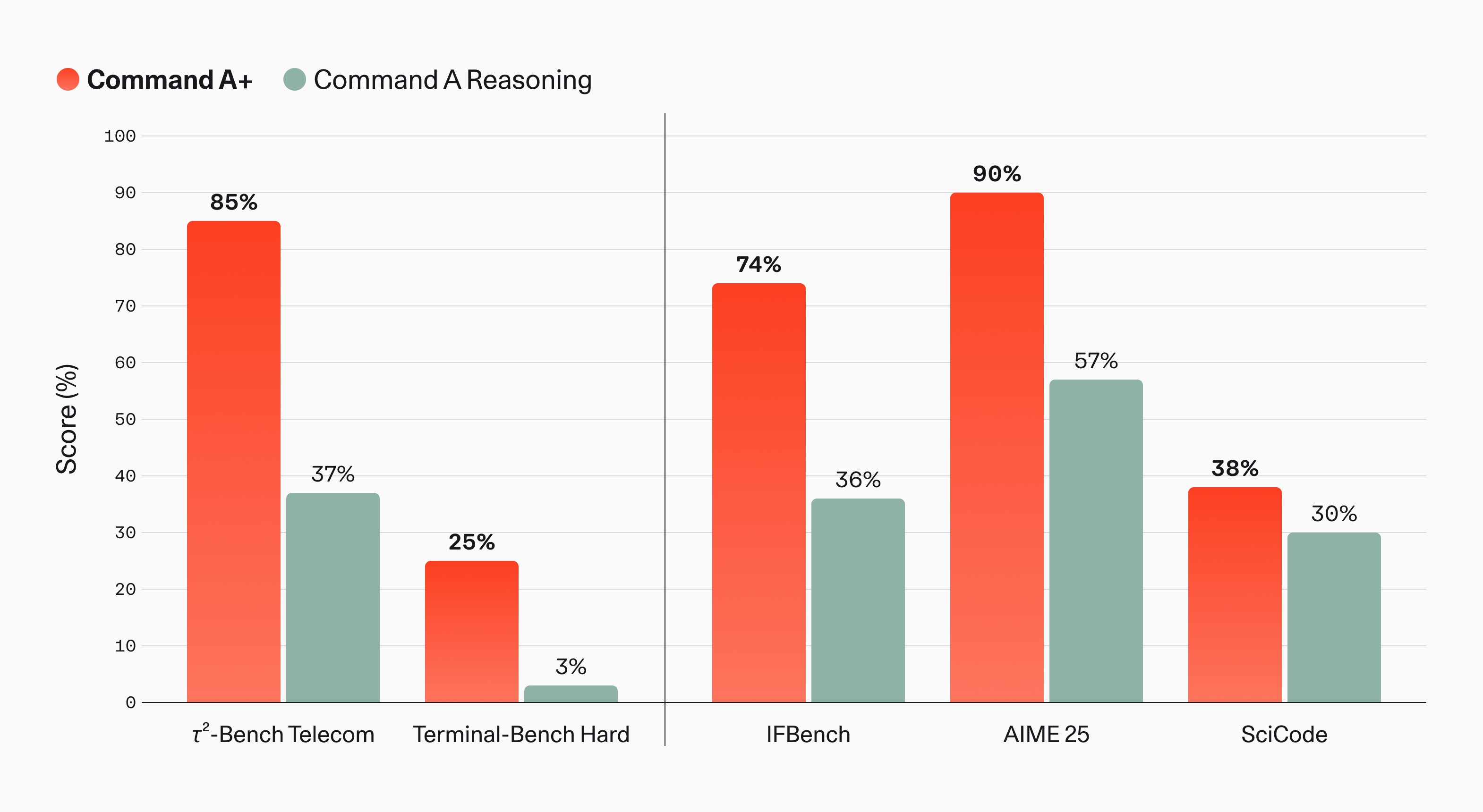
In Cohere's announcement, Command A+ moves from 37% to 85% on Tau2-Bench Telecom compared with Command A Reasoning, from 3% to 25% on Terminal-Bench Hard, from 36% to 74% on IFBench, from 57% to 90% on AIME 25, and from 30% to 38% on SciCode. Read as raw numbers, this could sound like a standard "new model beats old model" story. The chosen benchmarks are more revealing. Telecom task simulation, terminal work, instruction following, math, and scientific coding sit together. Cohere is trying to show whether an agent can survive inside real tools and workflows, not whether a chatbot knows more trivia.
The North internal evaluations point in the same direction. Cohere says Command A+ improves Agentic Question Answering accuracy by 20% and spreadsheet analysis quality by 32% inside North. It also says memory usage quality rose from 39% with Command A Reasoning to 54% with Command A+. Cohere identifies this as LLM-as-a-judge evaluation, so it should not be treated like an independent benchmark. But it does make Cohere's target problem clear: enterprise documents, spreadsheets, memory, file systems connected through MCP, and work that continues across prior conversations and stored data.
Why a 16% Korean token-efficiency claim matters
Another small but practical number in the Command A+ launch is tokenizer efficiency. Cohere says its new tokenizer expresses the same response with fewer tokens than previous models, with a 20% improvement for Arabic, 16% for Korean, and 18% for Japanese. For Korean builders, that is not a cosmetic detail.
Most model comparisons lean on English benchmarks and English pricing pages. But real Korean customer support, internal document search, contract analysis, public-service requests, and medical or pharma document summarization live or die on tokenization efficiency. If the same text requires fewer tokens, a team can include more input context or repeat the same workflow at lower cost. Agents make this even more important because they rarely answer once and stop. They plan, retrieve, call tools, review, summarize, and answer follow-up questions. A 16% gain may look small in a single prompt, but it compounds across long workflows.
This is still Cohere's own comparison. Real Korean business documents will need separate checks. Lower token counts do not automatically mean better retrieval quality, table and image understanding, stable tool use, or consistent business tone. Still, the fact that an open enterprise model explicitly highlights Korean cost efficiency is meaningful. It suggests that English-first model competition is being pulled down into multilingual operating cost.
Sovereign AI is an operations question
Cohere's sovereign AI framing can be easy to overstate. It can turn into broad language about national AI independence, control over public-sector data, or data sovereignty in regulated industries. For developers and AI platform teams, the more concrete questions are simpler.
First, where can the model run? Command A+ offers both Hugging Face distribution and Cohere's Model Vault path. That leaves room for self-hosting and managed private inference.
Second, what is the license? Apache 2.0 is easier for enterprises to evaluate than a restrictive research license or a model with noncommercial terms.
Third, how well does it fit existing runtimes? Support for vLLM, Transformers, SGLang, and Docker Model Runner reduces the problem of a good model being trapped behind unfamiliar serving infrastructure.
Fourth, can tool calls be audited? Command A+ emphasizes tool use, reasoning, and JSON-schema tool descriptions in the model card. When an agent calls APIs, databases, or search systems, the call structure and logs matter more than the natural-language answer.
Put together, those four questions explain where Command A+ sits. This is not an attempt to swap the default model inside consumer chatbots. It expands the choices for organizations that say: our data cannot leave, our model must run on our GPUs, our tool-call logs need to remain inspectable, and our non-English cost has to be predictable.
The uneven temperature of open source
The community reaction is not uniformly excited, and that is useful. LocalLLaMA users shared the Hugging Face link on launch day, and some welcomed the Apache 2.0 release and Cohere's Command R/A lineage. There was skepticism too. Some noted that the 128K context window is shorter than Command A's earlier 256K. Others pointed out that a 218B total model remains too heavy for ordinary local users. Some would have preferred Cohere to release Command A Reasoning itself under Apache 2.0 for broader adoption.
That reaction matters because "open-source model" has become too broad a phrase to describe one market. A small model that runs on a MacBook, a model that fits in 24 GB of VRAM with long context, a two-H100 enterprise model with a permissive commercial license, and a research-only open-weight model carry different expectations. Command A+ clearly sits closer to the third category. The personal local-LLM community and enterprise AI infrastructure teams will naturally judge it differently.
So this launch is only partly about open-model democratization. A more precise label is the enterprisization of open models. The model is public, but it is not lightweight. It is commercially usable, but it requires GPU and runtime expertise. It talks about model quality, but its deeper message is security, cost, permissions, and deployment.
Agents are moving outside the API boundary
Recent agent competition is not happening only inside model APIs. Google has pushed Gemini API Managed Agents with isolated cloud sandboxes and stateful agents. Anthropic's Stainless acquisition points toward SDK generation, MCP server generation, and API connection plumbing. OpenAI is platformizing long-running work and development workflows through Codex and workspace agents. Cohere is asking a different question: can that model run in your environment?
Command A+'s competitors are therefore not just Qwen or Mistral. Managed frontier APIs, cloud private endpoints, enterprise agent platforms, and open-weight serving stacks all become comparison points. Some teams will still be better served by using the latest Claude or Gemini model through an API. Others will need self-hosted open models because of sensitive data and regulatory constraints. Many will route between both: send the hardest reasoning to a frontier API, but keep repetitive internal document processing and tool calls on a private model.
Command A+ tries to make that second scenario more plausible. Forty-eight languages, multimodal document processing, RAG, tool use, reasoning, and 128K context are all ingredients for internal enterprise knowledge work. Sovereign AI sounds large, but in practice it often becomes a smaller question: can an agent process this bundle of PDFs and spreadsheets without sending them outside our boundary?
What still needs checking
Command A+ arrives with strong claims and several caveats. First, most performance figures come from Cohere. The company also mentions a 37 score on the Artificial Analysis Intelligence Index, but developers will care more about stability on their own workload. Tool-use models are especially hard to judge by benchmark score alone. The failure mode matters: whether the model chooses the wrong tool, follows JSON schemas reliably, remembers earlier decisions in long conversations, and separates retrieval results from its own reasoning.
Second, the hardware threshold is still high. Two H100s may be realistic for an enterprise trying to reduce cloud API dependency, but it is not a broad open-source community threshold. Even if W4A4 claims near-lossless quality, reasoning-heavy models can accumulate small quantization errors across long reasoning paths. Cohere's model card says reasoning models are sensitive to quantization loss and describes a selective approach where MoE experts are quantized while the attention path, KV cache, and some other components remain at full precision. Whether that holds up across diverse work will take time.
Third, context length is a tradeoff. A 128K input window is long, but some community users compared it unfavorably with the earlier 256K Command A. In enterprise RAG, search, summarization, memory, and permission filtering can matter more than stuffing everything into a long context. Still, for use cases that want entire document sets in one pass, teams will need to compare whether 128K is a strength or limitation against alternatives.
The practical questions for builders
For AI developers and platform teams, the useful takeaway is a set of questions rather than an immediate verdict.
First, what is the real bottleneck in your organization's AI cost: model pricing, data movement restrictions, or GPU operations? Command A+ matters more to organizations that already have or are willing to build the third capability.
Second, how sensitive are the tools your agents call? If CRM, ERP, databases, code repositories, or document stores are connected, model placement becomes a security and audit decision.
Third, is multilingual cost a real problem? If a workflow uses Korean, Japanese, Arabic, or other languages where tokenization changes cost, Cohere's tokenizer claim is worth testing on actual documents.
Fourth, who owns the responsibility boundary when you operate a public model yourself? Compared with an API provider that manages model updates, security patches, and serving stability, self-hosting gives more control and more operational burden at the same time.
A release of deployment rights
The shortest version of Command A+ is this: Cohere opened the deployment rights for an enterprise-agent model. Open source is an accurate term, but the launch feels closer to enterprise infrastructure than hobbyist local AI. Apache 2.0 licensing, the two-H100 minimum setup, 48 languages, 128K input, tool use, and vLLM/Transformers support all point in the same direction. It is aimed at teams moving from renting model access toward operating models.
That does not settle the question. Real tool-call quality, Korean enterprise-document performance, W4A4 quantization stability, and memory consistency across long agent loops still need independent verification. But the question raised by the launch is clear. As enterprise AI touches more internal systems, "the strongest model" becomes only part of the decision. "The model I can control" starts to matter just as much. Command A+ puts that threshold at two H100s. The next test is whether that cost is low enough, and whether that control is valuable enough to beat the convenience of frontier APIs in real work.