Command A+ Turns a 218B Open Model Into a Two-H100 Question
Cohere Command A+ reframes open model competition around agentic inference cost, private deployment, Apache 2.0 licensing, and GPU math.

- What happened: Cohere released
Command A+, a sparse MoE model with 218B total parameters and 25B active parameters, under Apache 2.0.- The W4A4 version is positioned for 2x H100 or 1x B200 inference, with 128K input context and up to 64K generated tokens.
- Why it matters: The open model race is shifting from leaderboard wins toward agentic inference cost, private deployment, tool use, and operational control.
- Watch: Two H100s are still a serious bar for many teams, and some North evaluations rely on LLM-as-a-judge scoring.
Cohere released Command A+ on May 20, 2026. At first glance, it looks like another entry in the crowded open model calendar. But the interesting part of this release is not the familiar claim that a new model is smarter than the last one. It is the deployment math.
Cohere says Command A+ is available under Apache 2.0, uses a sparse Mixture-of-Experts architecture with 218B total parameters and 25B active parameters per token, and can run in W4A4 quantization on two NVIDIA H100 GPUs or one B200. It supports 128K input context, up to 64K generated tokens, text and image inputs, reasoning, and tool use.
That mix of facts matters because the hardest question in enterprise AI is often not whether a model can answer a prompt in a demo. Agents read documents, call tools, plan, retry, inspect failures, keep state, and generate a lot more tokens than a one-shot chatbot. Token bills become harder to predict. Customer data and internal documents are not always allowed to leave the organization. Security teams want audit logs and deployment boundaries. Finance teams want costs that can be modeled.
Command A+ is Cohere's attempt to answer that bill of materials.
218B Parameters, But Not on Every Token
The core specification is clear across Cohere's announcement and the Hugging Face model cards. The model name is command-a-plus-05-2026. The license is Apache 2.0. The architecture is sparse MoE. Total parameters are 218B, while each token activates 25B parameters. The context window is 128K input tokens, with a maximum generation length of 64K. Cohere describes support for text, images, reasoning, and tool use. The model card lists 48 supported languages, including Korean.
The MoE design is not just a large number for a launch post. If every token had to traverse a dense 218B model, self-hosting would be much harder to justify. Command A+ instead routes tokens through a subset of experts, trading off total capacity against active compute. The Hugging Face card says eight experts are activated per token, with shared expert capacity as part of the architecture. MoE itself is not new, but putting that structure at the center of an open enterprise agent model is still a meaningful product decision.
Quantization is the other half of the story. Cohere provides BF16, FP8, and W4A4 variants. According to the Hugging Face model card, BF16 requires 4x B200 or 8x H100 GPUs, FP8 requires 2x B200 or 4x H100 GPUs, and W4A4 brings the minimum down to 1x B200 or 2x H100 GPUs.
For many teams, two H100s are not a casual local setup. But for enterprise AI infrastructure, the number moves the conversation from impossible to inspectable. This is not a laptop model. It also weakens the assumption that large enterprise agents must always be consumed through proprietary APIs. The open model market is expanding into the space between "runs on my MacBook" and "only available as a frontier API."
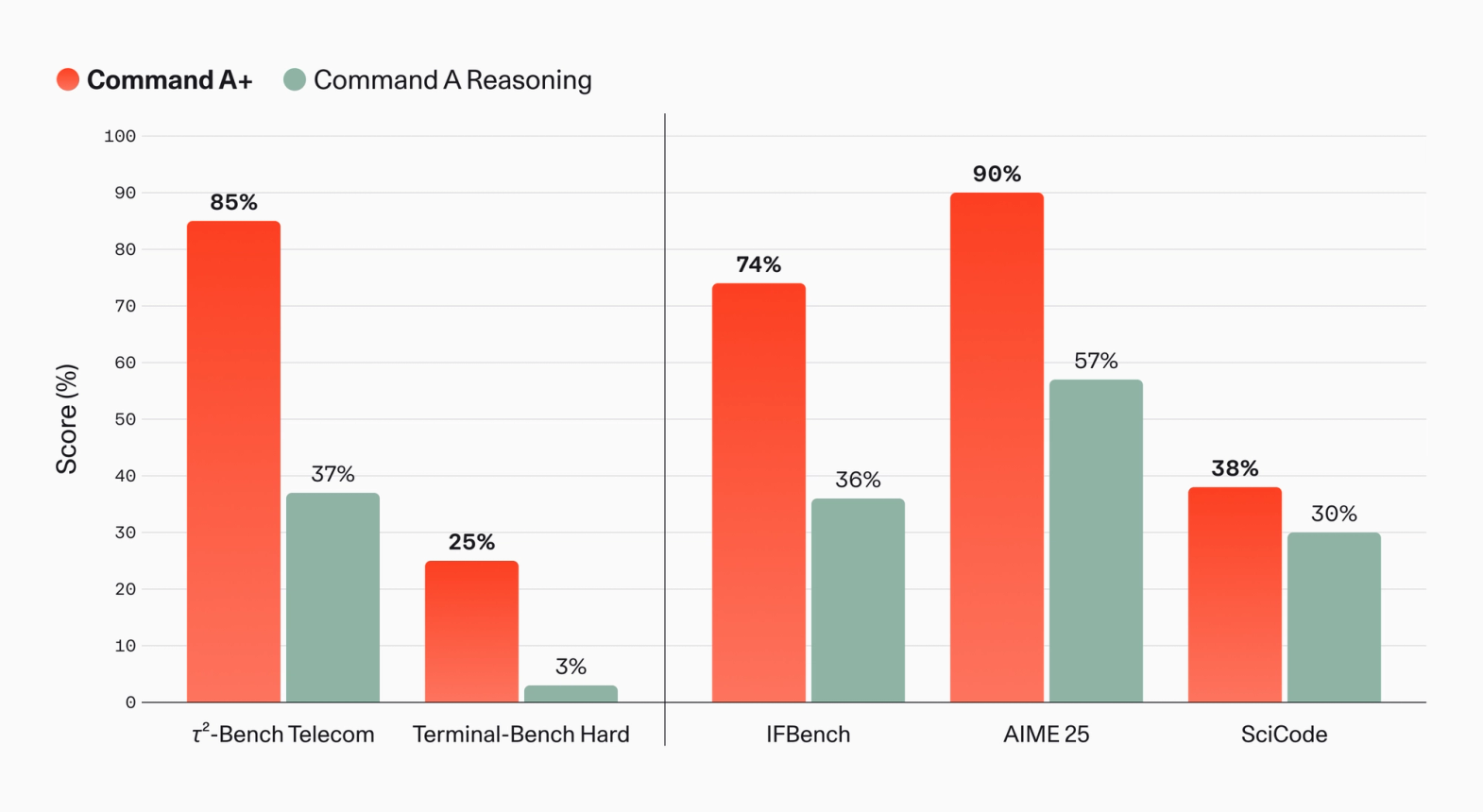
The Benchmarks Point Toward Agents
Cohere's most aggressive numbers are not primarily about general chat. They are clustered around agentic and work-oriented evaluations. Compared with Command A Reasoning, Cohere reports that Command A+ moves ²-Bench Telecom from 37% to 85%, Terminal-Bench Hard from 3% to 25%, IFBench from 36% to 74%, AIME 25 from 57% to 90%, and SciCode from 30% to 38%.
Terminal-Bench Hard is the signal worth lingering on. A terminal environment is closer to coding agents, data operations, and infrastructure automation than a conversational benchmark is. A score of 25% does not mean the problem is solved. In fact, it says the opposite: hard terminal tasks still break agents frequently. But a move from 3% to 25% shows that Cohere is shaping Command A+ around execution, not just response quality.
The same direction appears in Cohere's North evaluation. North is Cohere's enterprise workspace, and the company reports improvements in Agentic Question Answering from 45% to 65%, Data Analysis from 13% to 45%, and Memory Usage Quality from 39% to 54%. Those numbers are interesting, but they need careful reading. Cohere says the evaluation uses LLM-as-a-judge scoring. Because this is an internal product evaluation, teams should still verify reproducibility, dataset fit, judge bias, and failure cost in their own environment.
Still, the target user is clear. Cohere is not aiming this release at people looking for the most entertaining chatbot. It is aiming at enterprise agents that read files, retrieve grounded evidence from connected systems, analyze spreadsheets, remember previous work, and operate across private data. That is why the model specification leans into long context, tool use, citations, multilingual coverage, and multimodal document handling.
Why Apache 2.0 Matters
"Open model" is an imprecise phrase. Some releases are open for research but complicated for commercial use. Some publish weights but attach license terms that create friction for product teams. Command A+ using Apache 2.0 is therefore not a footnote. It belongs near the top of the story.
Enterprise developers do not choose models from benchmark tables alone. They need to know whether a model can be embedded into a product, run beside customer data, fine-tuned or served inside controlled environments, and passed through legal review. Apache 2.0 simplifies that first gate.
The license does not remove every risk. Training data questions, output liability, safety policy, regulated-industry requirements, and customer contracts remain. But it makes the first question easier: can this model plausibly be used in a commercial or internal platform?
This also fits Cohere's broader strategy. Cohere is not primarily trying to capture consumer attention with a mass-market chatbot. It has positioned itself around enterprise AI, controlled deployment, retrieval, and private workloads. Command A+ becomes the model layer in that strategy. Combined with North, Model Vault, and private deployment offerings, the message is less "call our API" and more "run enterprise agents in an environment you control."
| Review area | What Command A+ exposes | What teams still need to test |
|---|---|---|
| License | Apache 2.0 | Product use, customer contracts, regulated-industry responsibility |
| Runtime footprint | 2x H100 or 1x B200 for W4A4 | Concurrency, KV cache pressure, peak traffic, operational cost |
| Agent features | Tool use, reasoning, citations, 128K context | Permission boundaries, tool schemas, recovery from failed actions |
| Multilingual use | 48 languages and claimed Korean token efficiency gains | Internal documents, domain terms, non-English hallucination rates |
Two H100s Are Not Cheap, But They Change the Baseline
One of the most revealing phrases in the launch is "as little as two H100 GPUs." Depending on the reader, that sentence means opposite things.
For an individual developer, it reads like a high bar. Even for many startups, it is not a trivial footprint. H100 servers remain expensive, and production serving needs more than model weights. It needs networking, storage, monitoring, scaling, incident response, access control, and security operations.
From an enterprise perspective, the calculation changes. If an organization already owns GPU capacity, cannot send sensitive documents to external APIs, or has agents that consume large and unpredictable token volumes, two H100s can look like a dedicated workload unit rather than exotic research hardware.
Agents make this especially important. A single user request may require multiple tool calls, retries, retrieval passes, and long context maintenance. API costs can swing with the shape of the task. Self-hosting does not make cost disappear, but it changes the cost structure. Token-variable spending becomes GPU utilization, operations, and capacity planning.
That shift is not automatically better. For many teams, a managed API remains cheaper, faster, and easier to operate. But for teams with sensitive workloads, large internal documents, or repeatable high-volume agent flows, Command A+ gives them a concrete number to put on the spreadsheet. The useful question is not "did an open model beat frontier APIs?" It is "which workloads are now candidates for private inference?"
Tool Use and Citations Are an Operating Contract
The Hugging Face model card describes Command A+ as trained for conversational tool use. It also documents a chat-template flow in which tool descriptions are supplied with JSON schemas. When citations are enabled, the model can attach parts of its response to spans from tool results.
Those details can look small in a demo. In enterprise agents, they are central.
When an agent calls a CRM, database, document store, ticketing system, or deployment pipeline, the key question is not merely whether it can call a tool. The question is when it calls which tool, how it interprets the result, how it avoids overreaching permissions, and whether a human can later understand why it reached a conclusion.
Command A+'s tool use is therefore both a model capability and an operating contract. The model has to follow invocation formats. The host application has to design permissions and schemas carefully. A model that emits citation spans can still produce a well-grounded wrong answer if the retrieved data is stale, the tool result is misleading, or the permission model is too broad.
Agent reliability is not a model-only property. It is the combined behavior of model, tools, data, permissions, logs, evaluation, and human review.
That is the trade that open model operators inherit. Proprietary APIs make the model internals less visible, but they offload part of the operational burden to a provider. Self-hosted open models give teams more control over data and deployment location, but they also make serving quality, safety policy, updates, evaluations, and incident response internal responsibilities.
Is 128K Context Enough?
One repeated community critique is the 128K input context. A few years ago, 128K was an enormous context window. In 2026, with Gemini-class long context, Claude's extended context, and open model announcements moving beyond 256K, it no longer reads as a purely maximal number.
But context length is not a score that improves without tradeoffs. Long context interacts with latency, cost, KV cache pressure, retrieval quality, and actual user workflows. For many enterprise tasks, a million-token window is less important than good retrieval, preserved source attribution, structured tool results, durable memory, and workflows that can recover from failure.
Command A+'s 128K context is best read as a large working area for RAG and tool-using agents, not as a promise that every document should be pasted into the prompt. Cohere's own emphasis on North, agentic QA, spreadsheet analysis, and memory points in the same direction. The product thesis is not context length alone. It is context plus retrieval, tools, citations, and memory.
The Korean Tokenization Detail Matters Globally
One smaller but meaningful claim in the release is tokenizer efficiency. Cohere says the new tokenizer improves tokenization efficiency by 20% for Arabic, 16% for Korean, and 18% for Japanese.
For teams working outside English, this is not a cosmetic metric. LLM cost and latency usually scale with tokens. If Korean documents are split inefficiently, the same business task becomes more expensive and slower. Even in self-hosted inference, token count affects latency and throughput. Customer support logs, contracts, meeting transcripts, policies, and internal manuals can all become more expensive when tokenization is poor.
Tokenizer efficiency does not guarantee better Korean reasoning. A model can use fewer tokens and still miss domain terms, implicit document structure, dates, or numerical constraints. Teams evaluating Command A+ for Korean or other non-English work should build tests around their own documents: policy QA, table extraction, contract review, customer log summarization, issue analysis, and multilingual retrieval.
The point is that open enterprise models now have to compete on language economics as well as English benchmark scores.
Community Reaction Is Split for Good Reasons
The LocalLLaMA reaction has been mixed, and that is expected. The Hugging Face model card drew meaningful attention, and some users welcomed the Apache 2.0 release, especially given Cohere's history with Command R and Command R+. Others were skeptical. Some argued that 128K context feels conservative in the current model market. Others pointed out that two H100s are still too heavy to call a local model in the hobbyist sense. Some wondered whether releasing Command A Reasoning as well would have generated a stronger response.
Both sides are reading the model through different deployment lenses.
Open model enthusiasts often ask: can I run this myself? By that standard, Command A+ is a large model. Enterprise AI teams ask a different question: can I run this in a controlled environment? By that standard, Apache 2.0, W4A4, vLLM, Transformers, and 2x H100 are unusually concrete deployment ingredients.
Command A+ is not designed to satisfy everyone. It is heavy for personal local LLM use. It may feel operationally burdensome for teams that are happy with frontier APIs. But for organizations that combine private data, existing GPU capacity, multilingual documents, agent workflows, and cost predictability requirements, it creates a new baseline worth testing.
The Open Model Battle Is Becoming an Operations Battle
The larger question around Command A+ is how open models now compete.
For a long time, open model coverage focused on how close a model came to closed frontier systems. That still matters. But enterprise adoption brings different questions to the front. Is the serving stack stable? Does vLLM handle tool-call parsing well enough? How are updates rolled out? How are evaluations automated? Does latency hold up under real concurrency? How are data permissions and audit logs preserved?
Command A+ does not answer all of those questions. It makes them more concrete.
W4A4 lowers the hardware requirement, but quantization can change failure patterns in long reasoning and tool-heavy workloads. The model card notes that reasoning models can suffer greater degradation at lower-bit quantization, and that Cohere uses selective quantization and distillation to reduce the loss. That is a reasonable approach. It is not a substitute for workload-specific evaluation.
The same applies to the two-H100 claim. Running a model and serving a production agent are different tasks. A single slow test request is not the same as dozens of analysts processing long documents concurrently. If users often generate long outputs near the 64K limit, latency and cost rise again. If agents repeatedly call tools, external system latency may dominate GPU time.
The headline number is useful because it makes the discussion real. It is not the final answer.
Who Should Care Most?
Regulated-industry AI platform teams should pay attention first. Financial services, healthcare, public sector, manufacturing, and defense organizations often care deeply about data location and access boundaries. An Apache 2.0 model that can be evaluated inside controlled infrastructure expands the pilot space.
Companies with large multilingual document workloads should also look closely. The 48-language support and Korean token efficiency claim deserve verification. If non-English documents are driving up costs or latency, tokenizer behavior and retrieval quality should be evaluated together.
Agent product builders get another practical option. Tool use, citations, long context, image input, and open weights in one model can change product architecture. But the product does not become reliable the moment the model is attached. Permissions, UI, observability, retries, human-in-the-loop review, and rollback paths still determine whether the agent is useful.
Organizations already paying for GPU capacity may have the clearest immediate reason to test it. If internal GPUs are underutilized, if inference workload is predictable, or if API costs are rising quickly, Command A+ belongs on the comparison sheet. Smaller teams without GPU operations experience may still be better served by managed APIs.
Conclusion
Command A+ is not just another "Cohere released a model" story. It is a case study in what open models need to look like in the agent era.
They need a usable license. They need inference economics that can be discussed in GPU units. They need tool use and citation support. They need long enough context for real work, not just chat. They need multilingual document handling. And they need a serving story that makes private deployment plausible.
There are still open questions. Are two H100s a low enough barrier? Will the North evaluation gains hold in customer workloads? Is 128K context enough for complex enterprise agents? What failure patterns does W4A4 introduce in long reasoning and tool calls? Does Korean document quality improve as much as tokenizer efficiency suggests?
The strongest message in this release is that open model competition is no longer only about being small and free. Enterprise agents force the model weight, license, GPU footprint, serving stack, permissions, citations, and audit trail into the same calculation. Command A+'s most important number might be 218B, 25B, or 2x H100. Taken together, they point to the same conclusion: the next phase of agent model competition will be fought on operating budgets and security review sheets as much as on benchmarks.