34% fewer revisits, the agent cost of clean code
A 660-run SonarSource study with Claude Code suggests clean code may not raise pass rates, but it can reduce tokens and file revisits.

- What happened: SonarSource researchers ran
Claude Code660 times to test whether code cleanliness changes agent behavior.- They built six minimal-pair repositories and 33 tasks, keeping behavior constant while changing only the internal code structure.
- Key numbers: pass rate was nearly flat at -0.9 percentage points, while input tokens fell 7.1% and file revisitation fell 33.8%.
- Why it matters: clean code looks less like a capability boost and more like cost infrastructure for coding agents.
- Watch: the result is limited to one Claude Code setup with Claude Sonnet 4.6, and token savings are not the same as identical dollar savings.
SonarSource researchers Priyansh Trivedi and Olivier Schmitt posted an unusually practical paper to arXiv on May 19, 2026: Does Code Cleanliness Affect Coding Agents? A Controlled Minimal-Pair Study. The question is simple enough to sound almost old-fashioned. If the code is cleaner, does a coding agent do better work?
The answer is more subtle than the usual clean-code argument. Cleaner code did not meaningfully improve Claude Code's task pass rate in this experiment. The pass rate was 0.913 on the clean side and 0.921 on the messy side, a difference of -0.9 percentage points. If you look only at that number, it is tempting to say that clean code matters less once AI is doing more of the reading and editing.
That is not the actual news in the paper. The more interesting result is cost. The researchers asked the same agent to solve the same tasks while tracking input tokens, output tokens, reasoning characters, conversation length, files read, and how often the agent returned to files it had already read or modified. In the cleaner repositories, input tokens fell 7.1%, output tokens fell 8.5%, reasoning characters fell 11.1%, and conversation messages fell 7.0%. The largest shift was file revisitation: the agent reopened already-touched files 33.8% less often.
That changes the clean-code debate. Even if an agent can read and edit code for us, code structure does not disappear. The reader is no longer only a human developer. It is also a model and the harness around it. Function names, control flow, module boundaries, dead code, and duplicated logic now affect not only human cognitive load but also context cost and agent search loops.
Why this experiment is hard
To test whether code cleanliness affects agents, it is not enough to compare one "clean" repository with another "messy" repository. Different repositories bring different domains, languages, tests, dependencies, frameworks, and task difficulty. If pass rate or token use changes, you cannot tell whether the cause is cleanliness or everything else that changed with it.
The paper therefore uses minimal pairs. Each pair keeps the same architecture, dependencies, tests, and external behavior, while changing only internal code cleanliness. Cleanliness is proxied through SonarQube rule violations and cognitive complexity. This is not a philosophical definition of good code. It is a measurable set of maintainability signals that a static-analysis system can observe.
The researchers used two pipelines. One is Slopify, which turns clean repositories into messier ones. It inlines helpers into callers, duplicates logic, inserts dead code, sometimes merges modules into larger files, and discards passes when tests break. The goal is not cartoonishly broken code. It is plausible messy code that looks like it grew without enough review or linting.
The opposite pipeline is Vibeclean, which cleans messy repositories. It follows SonarQube issue lists module by module, then reruns tests to preserve external behavior. Some changes are mechanical, such as removing duplicated strings, deleting commented-out code, replacing legacy collection idioms, or removing dead branches. Others are structural, such as breaking up a 200-line dispatch switch into helpers or extracting persistence helpers from a 2,800-line class.
Repository with the same external behavior
Same tasks, same Claude Code, different code cleanliness
The study used six repository pairs. Three pairs came from SonarSource private codebases, and three came from public repositories: Apache commons-bcel, Netflix genie, and ckan. The private repositories matter because public repositories may have appeared in model training data. Private code reduces the confound that the model might be solving from memory rather than by exploring the codebase in front of it.
Footprint, not just pass rate
The paper is interesting because it does not stop at pass rate. Coding-agent evaluation has been dominated by whether tests pass, with SWE-bench-style benchmarks as the obvious example. Pass rate matters. But real teams running agents also care about cost, latency, retries, and operational predictability.
A coding agent is not a chatbot that emits one final answer and stops. It searches, reads files, greps for symbols, edits code, runs tests, reads logs, and tries again. Previous conversation and file contents are fed back into later model calls. Tool calls are model output too. Two agents can both solve the same task, but one may form a plan quickly while another repeatedly reopens the same file to make sure it understood the change site. For the user, that becomes slower feedback. For the provider, it becomes token spend. For the team, it becomes less predictable automation cost.
The study ran 33 tasks on both sides of each repository pair, 10 times per side, for 660 trials in total. The reported numbers come from Claude Code using Claude Sonnet 4.6. The researchers also swept Haiku 4.5, but excluded it from the core result because its lower pass rate made footprint differences harder to interpret reliably.
The headline results look like this:
The nearly unchanged pass rate makes the result sharper, not weaker. In this experiment, clean code was not a variable that made the agent "smarter" in a visible pass/fail sense. It changed the path to the same answer. The agent read less input, produced less output, used fewer reasoning characters, and most notably returned to already-edited files much less often.
The paper treats file revisitation as a signal of agent uncertainty. A typical pattern is read -> edit -> do something else -> read again. Human developers behave similarly. When structure is unclear, we reopen the place we just changed to confirm that it still fits. When names are clear, control flow is smaller, and module boundaries are legible, we build a mental model faster and move on. The model appears to pay a similar tax.
The effect grows in multi-module work
An average 7.1% reduction in input tokens may not sound dramatic. The task-level breakdown is more useful. The paper divides tasks into cognitive-hotspot, multi-module, and calibration tracks.
Cognitive-hotspot tasks focus on a complex method or class. Multi-module tasks require crossing two or more module boundaries. Calibration tasks are closer to neutral controls that do not directly touch the cleanliness difference.
The clean side had a much stronger effect on multi-module tasks. Input tokens fell 10.7%, and file revisitation fell 50.8%. The number of files read was almost unchanged. In other words, the agent did not simply explore less. It read a similar scope, but it returned to already-modified files far less often. That points toward an important mechanism: when module boundaries, names, and structure are clearer, the agent spends less time checking whether this was really the right place to change.
The cognitive-hotspot tasks showed the opposite pattern in some metrics. Input tokens rose 1.8%, and files read rose 11.2% on the clean side. That looks odd at first. Why would cleaner code make the agent read more? The paper's explanation is about the cleanup pipeline itself. If a large god method or deeply nested control flow is split into helpers, complexity is distributed across more named locations. Humans often prefer this. Agents may need to open more functions or files to connect the same behavior back together. Clean code does not monotonically reduce every footprint metric.
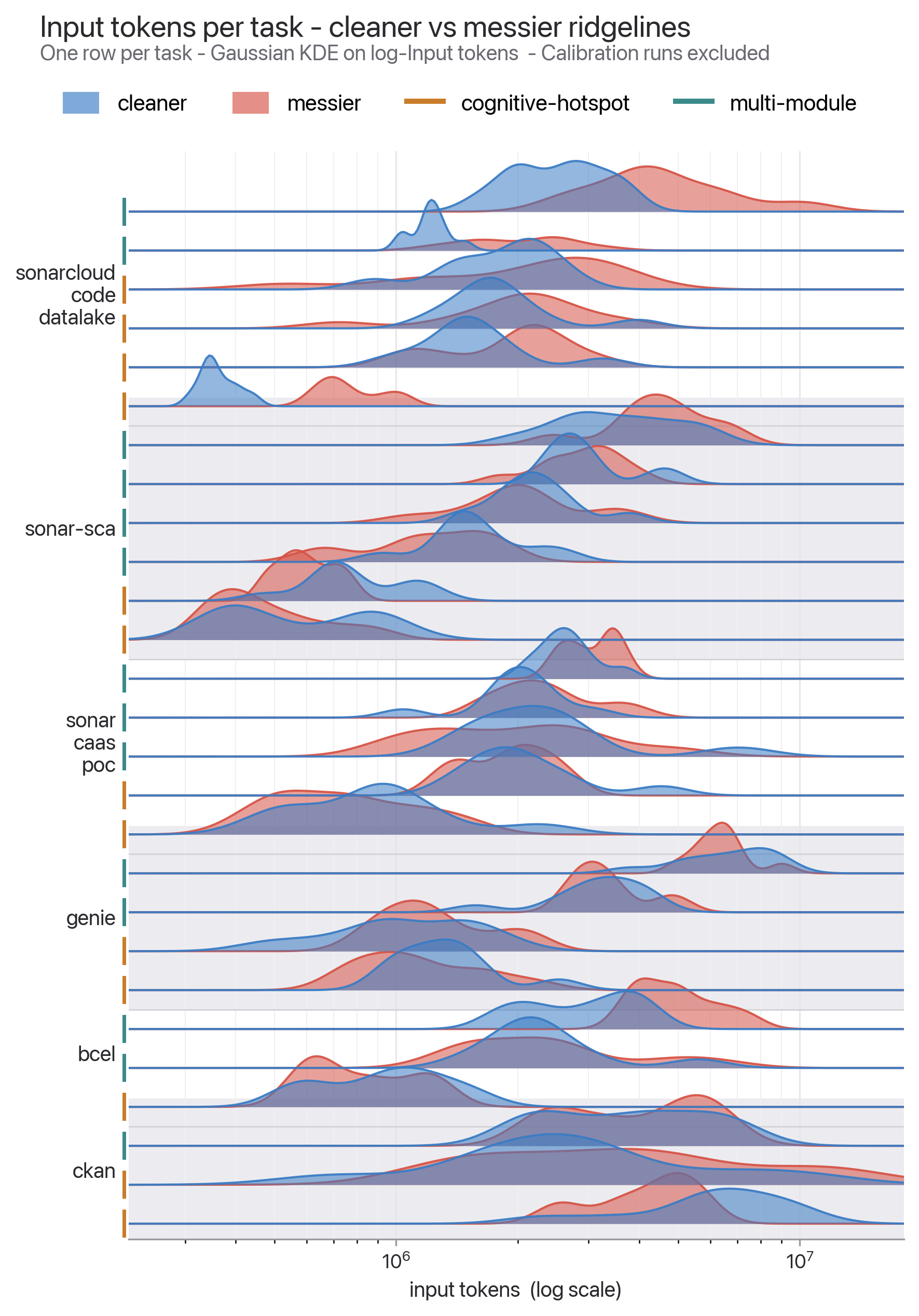
Figure 2 makes the same point from another angle. It shows input-token distributions for 27 non-calibration tasks. Within each task and side, the spread reflects run-to-run variance across 10 repetitions. Across rows, it reflects task-to-task variance. The researchers note that, within a task and side, the most expensive trial is often around 2.5 times as costly as the cheapest trial, and about 72% of groups have at least a 2x spread.
That matters operationally. A single "this run used 10% fewer tokens" anecdote may be noise. But a consistent reduction across 660 trials is worth treating as an operating signal. Coding-agent cost is not determined by a model price sheet alone. With the same model and same task, code structure, harness behavior, tool calls, cache state, and retry patterns can all move the bill.
Clean code is not only human aesthetics
As AI coding tools improve, one argument keeps resurfacing: if people read less code, does clean code become less valuable? This paper is a small but useful counterexample. Even if humans read less, someone still reads. If that someone is a model, the cost appears as tokens, latency, retries, and tool calls.
The result should not be flattened into "clean code improves agent performance." The pass rate was almost identical. A more precise reading is that clean code is a cost lever rather than a capability lever. It may not help the agent solve more problems. It may help the agent solve problems it already can solve with less wandering.
For development teams, that difference can still matter. If an individual occasionally asks Claude Code or Codex to make a change, a 7% token difference may be hard to feel. But when PR review, test repair, migration work, documentation updates, release notes, and security-patch reproduction move into CI or background agents, small footprint changes compound. The same codebase may be touched hundreds or thousands of times by agents.
The 33.8% reduction in file revisitation is especially interesting because it is more than a cost metric. If an agent keeps returning to the same file, it may be carrying uncertainty. Uncertain agents take longer, but they may also create conflicting follow-up edits, chase the wrong cause after a test failure, or add unnecessary changes. The paper does not directly connect revisitation to defects, but it is a plausible metric for agent operations teams to watch.
Code quality tools get a new role
The SonarSource authorship matters. A study that uses SonarQube rule violations as a cleanliness proxy naturally aligns with the perspective of a code-quality tools company. That does not invalidate the work, but it does suggest two things should be kept in view at the same time. The experiment is carefully controlled. Also, SonarQube issues are not the whole of clean code.
The paper acknowledges this. Clean code is hard to define, and the study uses static-analysis rule violations plus cognitive complexity. Some good design properties are not easy for static analysis to capture. Conversely, reducing rule violations does not always produce a more readable design. The cognitive-hotspot result, where the clean side read more files, is a useful reminder of that limit.
Even with that caveat, the role of code quality tooling expands. Static analysis used to be framed mainly as a way to reduce reviewer burden. In an agent-heavy workflow, it can also become preconditioning for cheaper model exploration. Linting, type checks, dead-code removal, function extraction, naming consistency, and module-boundary cleanup are no longer only about making code pleasant for people. They can make the surface that agents grep, read, and edit more predictable.
This changes the strategy question for AI coding adoption. Teams often start with "which model should we use?" Then they ask "which IDE or CLI should we use?" Over time, another question becomes just as important: can our codebase be explored cheaply by agents? Model routing and prompt caching cannot erase every cost if the code itself forces long search loops.
The limits are real
The study should not be overread. First, all headline numbers come from one Claude Code configuration using Claude Sonnet 4.6. It is not yet known whether OpenAI Codex, GitHub Copilot coding agent, Cursor, Gemini CLI, or other harnesses would show the same magnitudes. The paper suggests the mechanism may transfer, but treats that as conjecture within the study.
Second, tokens are a proxy for cost. The actual bill depends on provider pricing, cache hit rates, cached-token pricing, queue delay, plan quotas, and priority processing. A 7.1% input-token reduction does not mean a bill falls exactly 7.1%. It does mean there is room to reduce both cost and latency if the rest of the stack lets those savings pass through.
Third, pass rate is measured against hidden tests created for the paper. It does not prove that the agent preserved every existing repository behavior outside those tests. Two solutions can both pass hidden tests while still differing in maintainability or hidden regressions. This is not unique to the paper. It is a shared weakness of most coding-agent benchmarks.
Fourth, the experiment is short-horizon. Reducing footprint on a single task is not the same as proving what happens over a year of agent-authored changes. Clean code could make agent work cheaper, and cheaper agent work could enable more cleanup, creating a virtuous cycle. Or long-running agent edits could drift and erode the initial cleanliness. The paper leaves that compounding question for future work.
The question teams should ask
It would be too easy to read this paper and stop at "write cleaner code." The more useful question is more specific: in our own workflow, which code structures make agents spend tokens, reopen files, and retry?
If Claude Code, Codex, Cursor, Copilot, or Gemini CLI is already part of your team's workflow, agent logs should not be reduced to success or failure. Track input and output tokens per task, files read, same-file revisits, turns to first edit, test reruns, and final diff size. If those metrics repeatedly spike around a particular module, the bottleneck may not be the model. It may be the structure the model is forced to navigate.
This also changes the return-on-investment case for refactoring. In the pre-agent workflow, refactoring was justified through review time, bug reduction, and onboarding speed. Now agent execution cost belongs in the equation. If cleaning a module makes agents read less and revisit less on repeated tasks, refactoring becomes an inference-cost reduction project, not only a code-quality project.
That does not mean every codebase should be split into the smallest possible functions. The cognitive-hotspot result shows the risk. Extracting helpers can increase the number of places an agent must inspect. Good structure is not simply small functions. It is code where the likely change site is findable, names carry meaning, and module boundaries line up with the way tasks are actually assigned.
The paper's message is practical. Even when AI writes more of the code, the codebase remains the work environment. A workspace that is easier for people to read may also be cheaper for agents to operate in. The value is less "higher success rate" and more "less wandering." If the next bottleneck in coding agents is not just model intelligence but operating cost and predictability, clean code returns as an infrastructure problem.