Frontier AI predeployment review is becoming the new launch gate
CAISI is expanding predeployment evaluation work with Google DeepMind, Microsoft, and xAI, moving frontier AI launches beyond public benchmarks.

- What happened: The U.S.
CAISIis widening frontier-model predeployment evaluation work with Google DeepMind, Microsoft, and xAI.- Microsoft announced agreements with both
CAISIand the U.K.AISI, explicitly covering frontier-model testing, safeguard evaluation, and risk-reduction research.
- Microsoft announced agreements with both
- Why it matters: Frontier launches are starting to depend less on public leaderboard scores and more on private eval access, safety assumptions, and national-security review.
- Builder impact: Model selection now has to include evaluation provenance, safeguard evidence, procurement fit, and launch-delay risk, not just price and benchmark charts.
- Watch: The current system still looks mostly voluntary, and the public record does not yet define release-blocking authority or how much of each evaluation must be disclosed.
The U.S. government's frontier AI evaluation system is beginning to look more concrete. On May 5, 2026, Microsoft announced new agreements with the Center for AI Standards and Innovation, or CAISI, in the United States and the AI Security Institute, or AISI, in the United Kingdom. The core message was that Microsoft will work with those institutes on testing frontier models, evaluating safeguards, and researching ways to reduce national-security and large-scale public-safety risks.
In the same policy current, CAISI, which sits under NIST, is expanding cooperation with Google DeepMind, Microsoft, and xAI for predeployment evaluation and targeted research on frontier models. That can sound like a narrow regulatory item. For developers and AI product teams, it is more practical than that. Trust in a frontier model is no longer formed only by asking which model scored higher on a leaderboard. The more important questions are who evaluated the model, under what access conditions, with which private or semi-private test sets, and under which safety assumptions.
This is not just a problem for model providers. When a company adopts an LLM API, security and legal teams increasingly ask for more than SWE-Bench percentages, MMLU deltas, or demo videos. They ask whether the model has gone through external evaluation, whether national-security or cyber-risk findings exist, whether the result can support procurement or compliance paperwork, and who reevaluates the model if something goes wrong after release. The CAISI agreements signal that these questions are becoming part of the official language of the frontier model market.
What CAISI wants to evaluate
CAISI is a NIST organization. NIST's CAISI page describes it as a U.S. government coordination point for testing and collaborative research on commercial AI systems. Its remit is broad. It works with other NIST teams on guidance for measuring and improving AI-system security, enters voluntary agreements with private AI developers and evaluators, and leads non-public evaluations of AI capabilities that could create national-security risks.
The notable part is that the evaluation scope does not stop at abstract "AI safety." CAISI explicitly names cyber, biosecurity, and chemical-weapons risks. It also includes the capabilities of U.S. and competitor-country AI systems, foreign adoption of AI systems, the state of international AI competition, and the possibility that adversarial AI systems contain backdoors or malicious influence. This is less like a normal model scorecard and more like a strategic-technology assessment system.
Microsoft's announcement points in the same direction. Microsoft does not present the CAISI agreement as a replacement for internal testing. Its framing is that internal testing alone is not enough for national-security and large-scale public-safety risks. Evaluating high-risk capabilities requires a blend of technical, scientific, and security expertise, and some of that expertise lives inside CAISI, AISI, and the government organizations they connect.
For developers, that sentence matters. Frontier-model risk evaluation may not end with a vendor security paper, transparency report, or red-team summary. If your team sells to government, finance, healthcare, defense, or critical-infrastructure customers, external evaluation systems can become part of sales and procurement. "This model is good" is weaker than "this model was evaluated by this institute, in this risk category, under these conditions."
| Area | Older launch race | CAISI-style evaluation race |
|---|---|---|
| Main evidence | Public benchmarks, demos, vendor self-reporting | Predeployment access, private evaluations, government research partnerships |
| Risk categories | General safety, harmful output, product-policy violations | Cyber, bio, chemical, national security, adversarial model influence |
| Builder question | Is this model faster and cheaper? | Where can this model be used under procurement and regulatory constraints? |
| Weak point | Benchmark contamination and cherry-picking | Unclear public disclosure and uncertain release-binding force |
DeepSeek V4 Pro was the preview
CAISI's May 1, 2026 evaluation of DeepSeek V4 Pro shows more clearly how the institute appears to view frontier models. It came a few days before the Microsoft agreement announcement, but the two events should be read together. The agreements show which companies are giving government evaluators model access. The DeepSeek evaluation shows what government evaluation can add beyond ordinary public benchmarks.
CAISI described DeepSeek V4 Pro as the strongest Chinese public model it had assessed. At the same time, its published chart placed the model roughly eight months behind U.S. frontier models. The important point is not a simple country-versus-country ranking. CAISI showed that public benchmarks and vendor-reported results can create a different impression from evaluations that include private or semi-private tests.
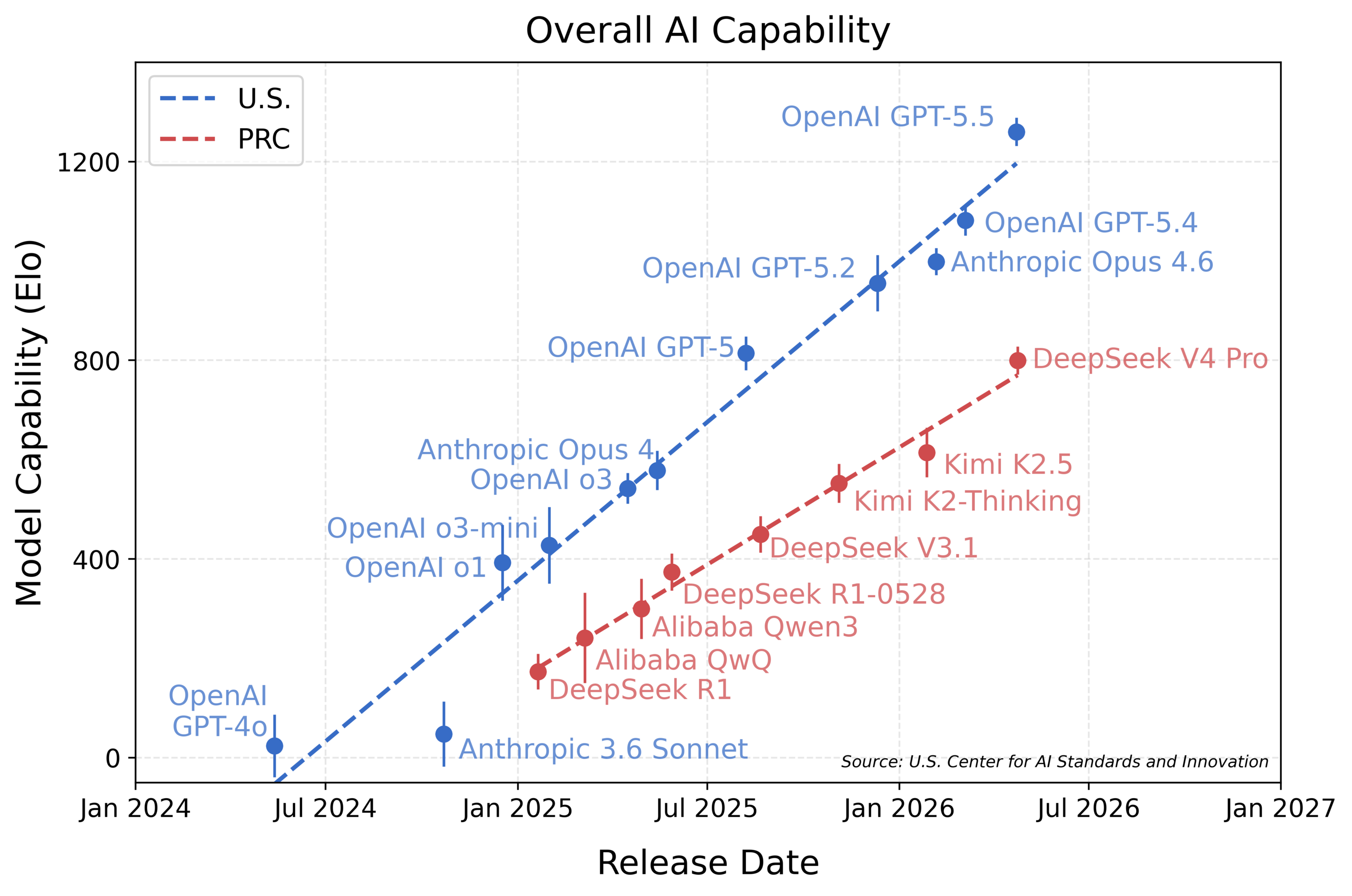
The domains included cyber, software engineering, natural sciences, abstract reasoning, and mathematics. For developers, the most interesting names are SWE-Bench Verified, PortBench, and CTF-Archive-Diamond. SWE-Bench Verified is already treated as a standard coding-model comparison point, but CAISI noted that its scores can differ from other reports because of system prompts, scaffolding, and token-budget choices. PortBench is an internal CAISI software-engineering evaluation. CTF-Archive-Diamond is a cyber-capability evaluation built around difficult CTF problems.
That combination sends a clear message. Frontier-model evaluation will struggle to separate "good at coding" from "capable of dangerous cyber behavior." In an era when agents read files, run commands, use tools, and work for long stretches, software productivity and offensive capability can emerge from the same tool-use skills. That is why a government evaluator may not treat coding benchmarks as simple productivity indicators. They can also serve as indirect signals for automated vulnerability discovery, malware production, or system manipulation.
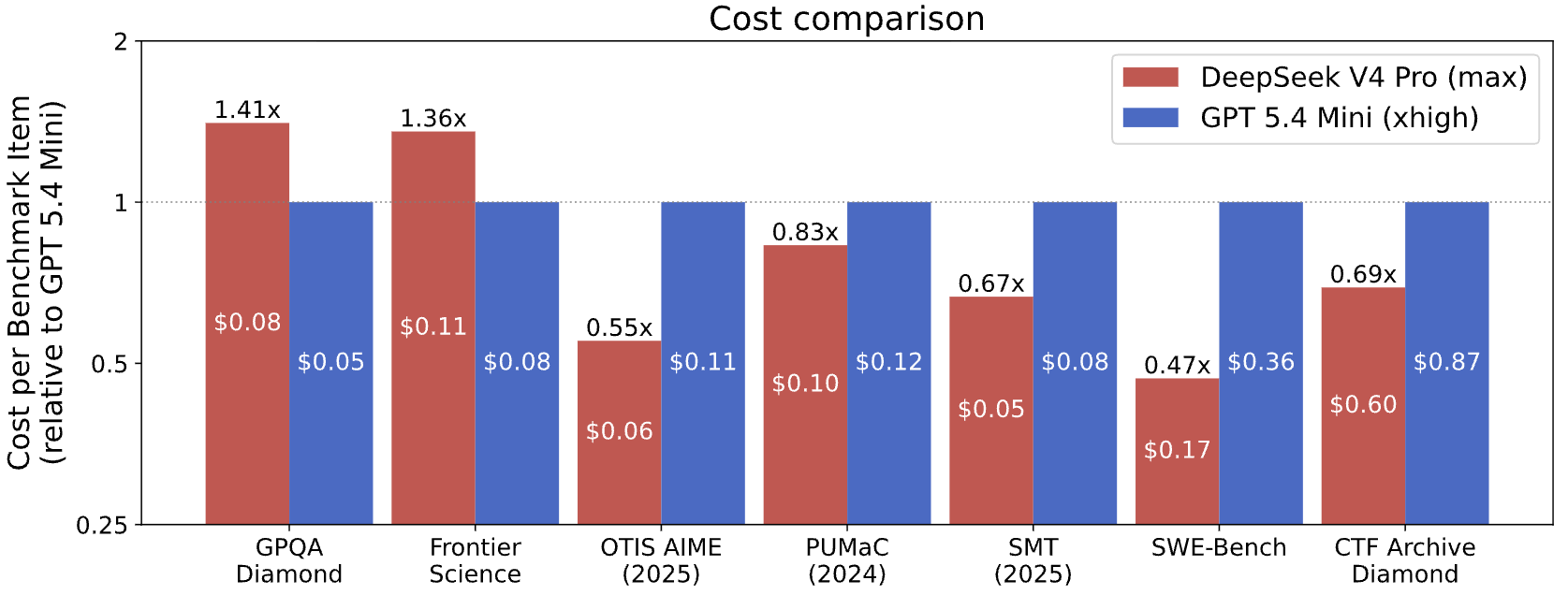
CAISI's cost analysis is also revealing. DeepSeek V4 Pro was compared against GPT-5.4 mini on seven comparable benchmarks, and CAISI found it more cost-efficient on five of them. The range ran from 53 percent cheaper to 41 percent more expensive. For companies looking at open or lower-cost models, that is attractive. But it is also exactly why external evaluation matters. Once a model becomes strong enough and cheap enough, governments and enterprises have to ask more carefully where it should not be used.
Voluntary agreement or the start of a permission layer
The word to read carefully in this story is "predeployment." Predeployment evaluation does not automatically mean predeployment approval. CAISI's public description still looks closer to voluntary agreements, non-public evaluations, and collaborative research with private developers. Based on the public record, we cannot yet say whether CAISI can block a specific model launch, whether evaluation results must be disclosed, or which criteria a model must satisfy before an API release.
That is why the early reaction is split. Some observers read the agreements as a clear signal that frontier AI is being treated more like critical infrastructure. Others, especially in security communities, point out that voluntary testing may not stop a launch in practice. Both views can be true. A predeployment evaluation system can gain market power even without formal release-blocking authority. If large buyers start asking whether a model has been evaluated with CAISI or AISI, a voluntary agreement becomes a de facto procurement standard.
For builders, the more operational questions are sharper. What API guarantee follows from the fact that a provider worked with an external evaluator? Does the evaluation cover only a general chat model, or also code-execution agents, tool calling, browser control, and long-running task modes? How close were the evaluated model version, system prompt, safety filters, and tool scaffold to the API customers actually use? Can enterprise customers cite the evaluation during incident response or regulatory review?
If those questions remain unanswered, external evaluation risks becoming a marketing phrase. If the scope and conditions become precise, frontier models gain a new axis of differentiation. The competitive claim will not only be "the smartest model." It will also be "the model that can better prove it is deployable in high-risk environments."
Model benchmarks are becoming political
The DeepSeek V4 Pro report also shows how technical evaluation is acquiring a geopolitical layer. NIST's CAISI page says the center evaluates the capabilities of U.S. and competitor-country AI systems, foreign adoption of AI systems, and the state of international AI competition. Model evaluation is being folded into national technology competition, not just research-community leaderboard culture.
That is awkward for many developers. A developer often wants the best model for the job. Enterprises and governments often want the model that is explainable in their regulatory environment. An open-weight model may have excellent price-performance, but data provenance, supply-chain risk, potential backdoors, and lack of independent non-public evaluation can still create adoption risk. A closed model may be criticized for low transparency, while a documented evaluation relationship with government institutes becomes a procurement advantage.
This means model release notes may become more complex. Until recently, the main fields were context length, price, benchmark scores, tool calling, and multimodal capability. Future release notes may also include evaluation partners, evaluation scope, predeployment access, risk categories, policy modes, and postdeployment monitoring. Agent products will probably feel this shift first because agents have broader permissions and execution environments than text-only chat systems.
What AI product teams should watch
This news does not change API usage overnight. It does change the model-selection checklist. First, teams should scrutinize the source of benchmark numbers. Public benchmarks remain useful, but a vendor-selected chart is not enough. CAISI's DeepSeek evaluation shows that vendor self-reporting and independent evaluation can lead to different conclusions.
Second, teams should ask what scaffold was used during evaluation. Coding agents are strongly shaped by tools, prompts, filesystem access, token budgets, retry strategy, and execution environment. CAISI's SWE-Bench note about system prompts and scaffolding is a reminder that the same base model can behave differently in your agent runtime. A leaderboard result does not automatically transfer to your production setup, either in capability or in risk.
Third, high-risk deployments should not separate external and internal evaluation. Even if CAISI or AISI has evaluated a model, your data, tools, permissions, and business workflow can create different failure modes. External evaluation is a starting point. Product-level authority design, logging, sandboxing, data boundaries, and human approval policies still have to follow.
Fourth, teams should plan for launch-delay risk. If predeployment evaluation becomes a market norm, the strongest model may not arrive immediately for every customer. A model could move through government evaluation, safeguard adjustment, and limited beta before reaching general API availability. Teams that depend heavily on frontier models need fallback model paths and evaluation criteria before the delay happens.
The launch bottleneck is not only GPUs
The AI industry has long explained model-launch bottlenecks through compute. More GPUs, larger data centers, and faster inference infrastructure still matter. But the CAISI agreements and the DeepSeek V4 Pro evaluation point to another bottleneck. Frontier models now have to prove trust before they reach the market.
That trust is not just brand trust. It depends on who saw the model before release, which non-public evaluations were run, how cyber and bio risks were measured, and how developer-agent capability was interpreted alongside high-risk behavior. For model providers, the ability to cooperate with evaluators becomes product competitiveness. For developers, model choice becomes a joint technical and regulatory decision.
The heart of the story is not the broad sentence "governments are regulating AI." The more precise claim is that trust infrastructure for frontier-model launches is being built. If that infrastructure becomes transparent, reproducible, and useful to developers, the model market can mature. If it remains a set of private agreements and press lines, it will become another opaque authority signal.
The next thing to watch is not just the existence of new agreements, but the artifacts that follow them: which evaluation methods CAISI and AISI publish, how providers connect evaluation scope to API documentation, and how customers use the results in procurement and security review. Frontier AI competition is moving beyond model intelligence alone. It is becoming a competition over who can convince enterprises and public institutions that a model is safe enough to put inside real systems.