After DAU comes DAA, why Baidu wants an agent metric
Baidu proposed Daily Active Agents as a core AI-era metric. The useful question is not token volume, but how many agents actually complete work.

- What happened: Baidu used Create 2026 to propose
DAA, or Daily Active Agents, as a core metric for the AI platform era.- Robin Li argued that tokens mostly measure cost and input, while an agent platform should be judged by agents that actually work and deliver outcomes.
- Product context: DuMate, Miaoda, Famou Agent 2.0, Baidu AI Cloud, and ERNIE 5.1 now form Baidu's agent stack.
- Why it matters: AI product metrics are moving from human logins toward execution, results, permissions, and operating cost.
- Watch: DAA is not a standard yet. It still needs rules for failed tasks, duplicate runs, short automations, and human approval.
Baidu put a useful frame on the agent race at Baidu Create 2026. It did not only announce another model or another chatbot. It suggested that the AI industry may need a different growth metric. On May 13, 2026, Robin Li proposed Daily Active Agents, or DAA, as a counterpart to Daily Active Users. If DAU captured the mobile internet's obsession with human visits, Baidu's argument is that the agent era should count software workers that actually perform tasks.
The idea matters because Baidu paired it with a product and infrastructure stack. According to Baidu's official announcement, the company introduced DuMate as a general-purpose agent, Miaoda app and enterprise editions for coding, Baidu Yijing as a digital human platform, Famou Agent 2.0 for closed-loop industrial optimization, and a full-stack AI Cloud for large-scale agent applications. DAA is not just a slogan around one product. It is a signal about how Baidu wants its platform to be evaluated.
The core claim is direct: tokens are cost, not value. They measure input and compute consumption, not whether useful work was done. Today's AI market is comfortable with model API volume, token burn, benchmark scores, monthly active users, and subscriber counts. But if agents are supposed to act on behalf of people, the more important question becomes how many tasks they completed, what results they returned, and how much human supervision was needed.
That makes DAA practical for builders. AI product teams already run into situations that DAU and token volume cannot explain. A user may log in once while a background agent sorts email, drafts a report, opens a pull request, and summarizes an incident log. Another agent may consume millions of tokens and still fail to produce something a human can approve. DAA is Baidu's attempt to separate those two stories.
What Baidu means by DAA
Baidu has not defined DAA with the precision of an accounting standard. The official framing is closer to "agents that are actively working and delivering results." The important shift is that the measured unit is no longer the human user. It is the agent. One person can run multiple agents. One enterprise can operate hundreds or thousands. A temporary workflow can generate short-lived sub-agents. That is why Robin Li could talk about a future in which global DAA exceeds 10 billion.
DAU was built for products where human attention was the scarce resource. Advertising, subscriptions, commerce, social graphs, and app engagement all revolved around people opening screens, tapping buttons, and spending time. Agents change that shape. A scheduled research agent may run overnight. A coding agent may inspect a CI failure while the developer is away. A finance agent may classify transactions in the background. A security agent may watch permission changes without anyone opening a dashboard.
If product teams only count human logins, they can undercount both load and value. A highly automated product may become more valuable precisely because the user spends less time staring at it. That is uncomfortable for the DAU mental model. In the agent era, less screen time can be a success signal when the work still gets done.
Token volume has the opposite weakness. Tokens are a good cost metric. They matter for inference infrastructure, cache design, context policy, routing, and margin. But tokens do not prove output quality. If one agent fails with one million tokens and another finishes the same task with 50,000 tokens, the cost dashboard highlights the first one. A value dashboard should favor the second. Baidu's DAA proposal targets that gap.
| Metric | What it measures | Agent-era limitation |
|---|---|---|
| DAU | People who used a product during a day | It can miss background execution and delegated work. |
| Token volume | The cost scale of model input and output | Failed tasks can look large, while result value remains invisible. |
| DAA | Agents that worked during a day | Active, successful, duplicate, and human-approved work must be standardized. |
The product bundle behind the metric
Baidu's announcement can look crowded because many product names arrive at once. The structure is clearer if we treat it as an agent stack. DuMate is the general-purpose agent layer. Baidu says it can read screens, operate software, process files, and connect business systems end to end. The goal is to let users route search, coding, deep research, data analysis, and app generation through one agent gateway.
Miaoda is the coding-agent layer. Baidu presents it as a way for users without coding knowledge to build applications, and it said that 90% of the Miaoda app's own code was generated by Miaoda itself. That is a product claim rather than an independently audited engineering metric, but it still points to the market Baidu wants: not only developer productivity, but disposable software created for short-lived business needs.
Famou Agent 2.0 is the industrial layer. Baidu positioned it around production scheduling, process optimization, and logistics planning. The most concrete example was an automated port case, where the company said Famou improved berth scheduling, equipment allocation, and cargo-priority optimization by 10.21% over an already optimized baseline. That is where DAA starts to sound less like a count of switched-on bots and more like a count of operational decision-makers inside real workflows.
Baidu Yijing, the digital human platform, extends the same idea into visible interfaces. Robin Li described digital humans as "visible agents." Once a face, voice, and gesture layer is attached, an agent's output is no longer just a text response or background job. It can host a livestream, produce video, respond to customers, and operate as a front-stage worker.
The common thread is that Baidu is not defining agents as one narrow UI pattern. The same portfolio contains a screen-operating assistant, a coding agent, an industrial optimization loop, a cloud runtime, and a video-facing digital worker. DAA is the metric Baidu wants to place across that whole surface.
ERNIE 5.1 is the infrastructure argument
DAA only becomes plausible if agents can be run at scale. Baidu assigns that role to ERNIE 5.1 and Baidu AI Cloud. In the official ERNIE 5.1 blog post, published May 9, 2026, Baidu says ERNIE 5.1 continues the pretraining base of ERNIE 5.0 while reducing total parameters to roughly one third and active parameters to roughly one half. It also claims pretraining cost is about 6% of comparable models.
Those efficiency claims connect directly to DAA. A world with more agents than humans has a very different cost curve from a chatbot used a few times per day. If an enterprise keeps thousands of agents running across software development, customer operations, finance, logistics, and security, small changes in latency and inference cost become structural business questions.
Baidu also emphasizes agentic post-training and a fully asynchronous reinforcement learning infrastructure. The ERNIE 5.1 write-up describes separated training, inference, reward, and agent-loop control planes, with each subsystem deployable and scalable independently. That matters because a long-running agent is not simply a one-shot answer generator. It interacts with an environment, calls tools, evaluates rewards, recovers from failed paths, and may need to revise its plan.
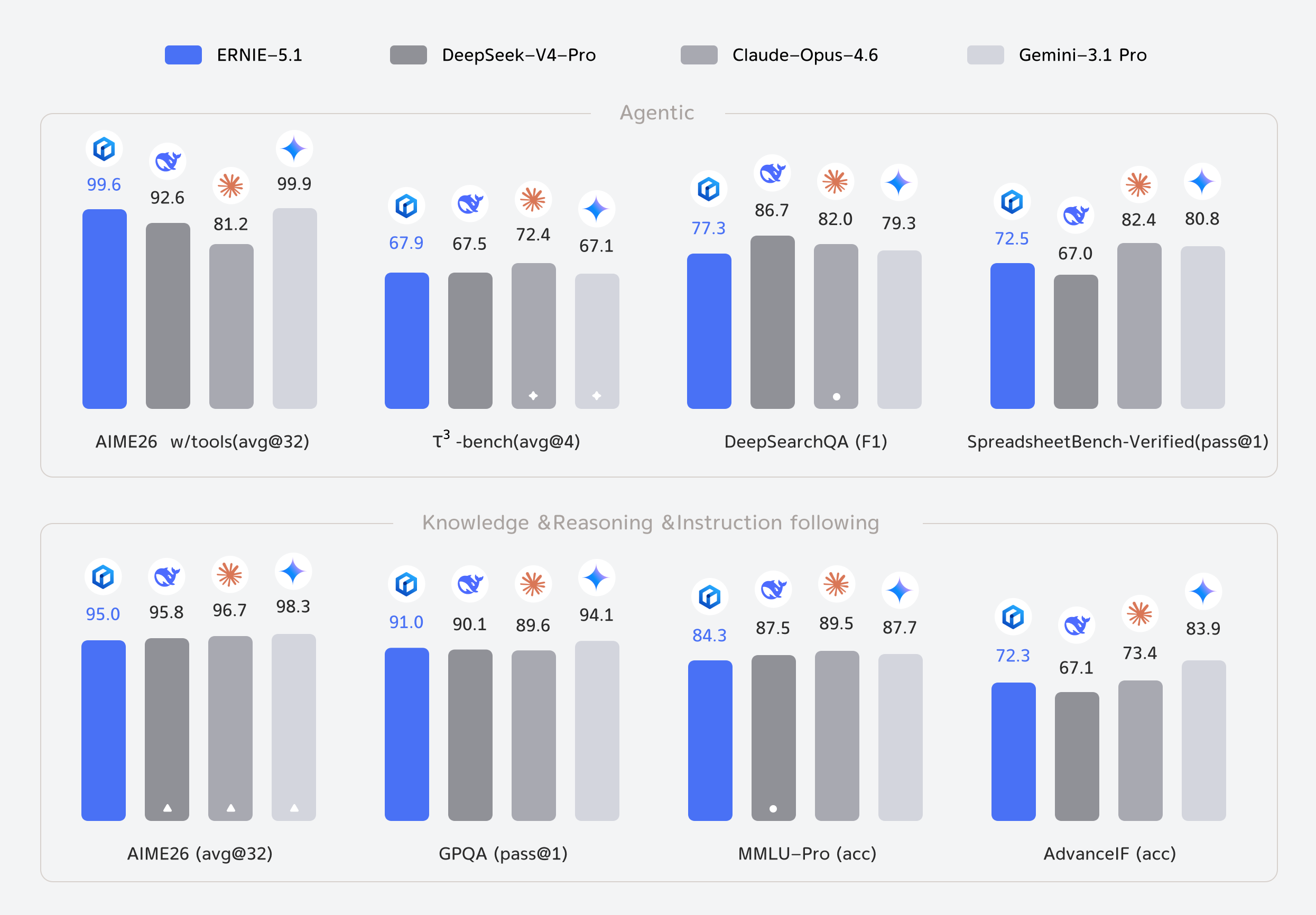
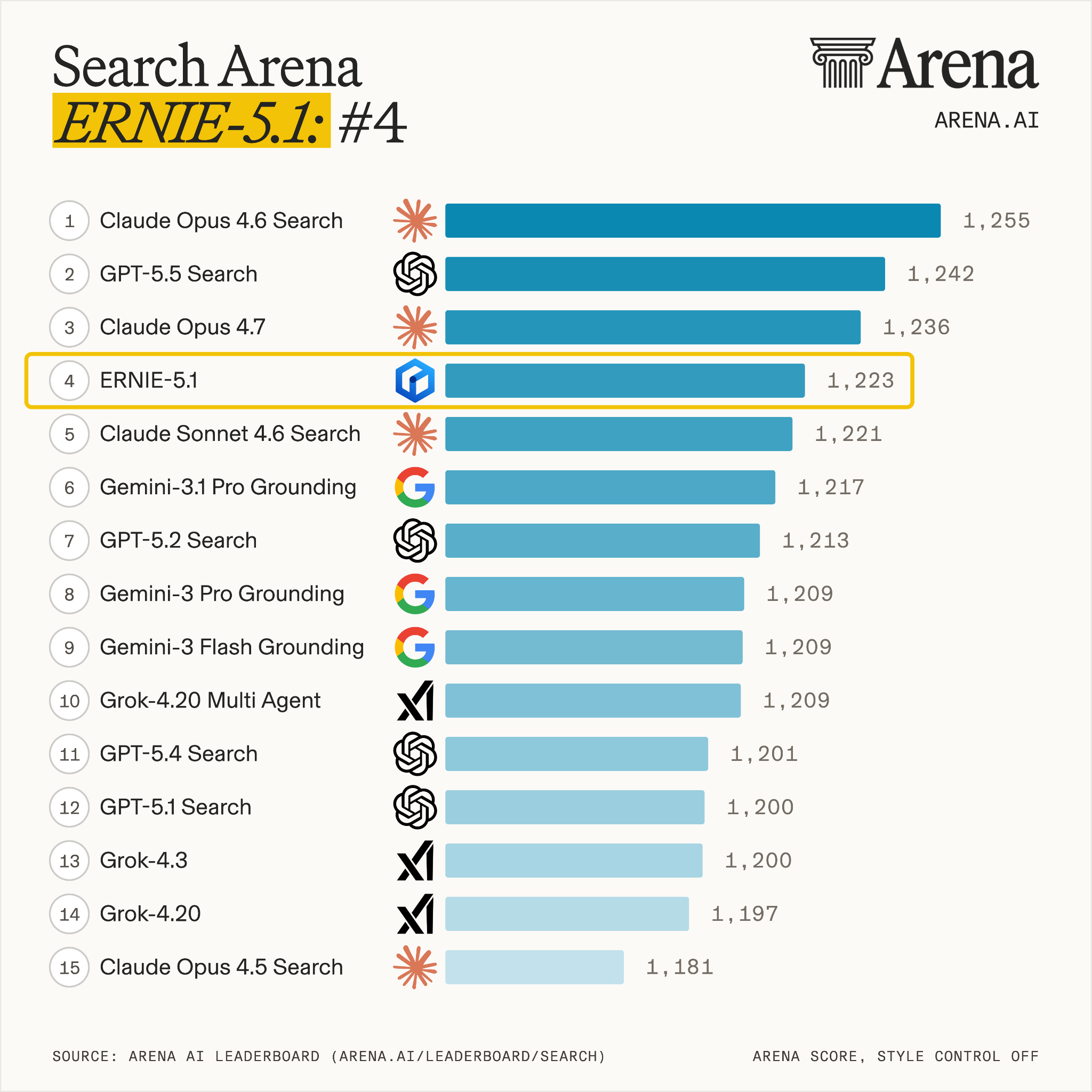
The benchmark numbers should still be read carefully. Baidu says ERNIE 5.1 reached 1,223 on the Arena Search leaderboard, ranking fourth globally and first among Chinese models. It also highlights a 99.6 score on AIME26 with tools, below Gemini 3.1 Pro in its comparison. Those numbers support the technical story, but they do not prove that DAA will grow. Agent success depends on model quality, tool permissions, data access, workflow integration, human approval UX, and error recovery.
Builders should not adopt DAA raw
DAA asks the right question, but it is not ready to be used as a raw KPI. The first missing piece is the definition of an "active agent." Does a scheduled agent count if it wakes up but produces no result? Does a task count if the user cancels it? If one top-level task launches 12 short-lived sub-agents, should the system record 12 active agents or one active workflow?
The second issue is success. Baidu's wording focuses on agents that deliver results, but "result" is domain-specific. For coding agents, teams can look at tests, review approval, merge rate, deployment, and regression rate. For customer support agents, they can look at resolution, escalation, repeat-contact rate, and satisfaction. For research agents, source quality and correction rate matter. A raw execution count can become the agent version of inflated page views.
The third issue is cost. Baidu is right that tokens are incomplete as a value metric, but they remain essential as a cost metric. A good DAA dashboard should not replace token tracking. It should join it with measures such as tokens per successful agent task, agent runs per human approval, inference cost per automated completion, and the share of tokens spent on recovery after failure. If DAA rises while cost rises faster, the platform may simply be running more expensive automation.
The fourth issue is security. More agents means more permission-bearing objects. Each agent may need rules about which APIs it can call, which files it can read, whether it can approve payments, and whether it can send external messages without review. DAA is therefore both a growth metric and an exposure metric. If active agents grow from 100 to 10,000, security teams need audit logs, secret controls, permission expiration, workload isolation, and human intervention paths to scale at the same time.
Why Baidu is pushing this now
Baidu has search, advertising, cloud, autonomous driving, AI models, and enterprise channels. For a company with that shape, agents are not just app features. They can become a connection layer across the platform. Search APIs, coding agents, business-system operation, digital humans, and logistics optimization can all sit under the agent label. In that context, "how many agents worked on Baidu's stack" becomes a more ambitious story than "how many people opened a Baidu app."
The Chinese AI market is also part of the background. DeepSeek, Alibaba Qwen, Zhipu, Moonshot, and Baidu's ERNIE family have been competing on model quality, efficiency, and cost. DAA tries to move the conversation away from pure model scoreboards and toward application and cloud operations. ERNIE 5.1's efficiency claims and agentic RL infrastructure serve that same message: Baidu wants to say it can run large numbers of agents cheaply and reliably, not only produce a capable model.
The same shift is visible outside China. Microsoft emphasizes agent management across Agent 365 and the Copilot ecosystem. Google is placing Gemini into Workspace and developer workflows. OpenAI and Anthropic are expanding coding agents, workplace agents, and enterprise deployment paths. Everyone is moving beyond "a user asks a chat window a question" and toward "AI operates inside work systems." Baidu's differentiator is that it put a measurement label on the shift.
What DAA would need to become real
For DAA to become an industry metric, at least four things need to be defined. First is agent identity. Teams need to decide how to count agents created by the same user, copied inside the same organization, or spawned temporarily by a parent agent. Second is activity. A meaningful tool call, completed task, user-approved result, and mere scheduler wake-up are not the same.
Third is separation between success and failure. A high DAA number alone does not prove platform health. Failed agents can retry in loops and inflate counts. Fourth is adjustment for cost and risk. One read-only summarization agent is not equivalent to an agent that can deploy code, change accounts, or authorize payments. A mature metric needs to account for permission level and business criticality.
For most product teams, the practical version is not a single DAA number. It is an operational dashboard: active agents, successful tasks, pending human approvals, automatic completion rate, cost per task, high-permission agent share, retry rate, and recovery rate. Baidu's term is DAA, but the useful outcome is a family of metrics that forces teams to measure work instead of only attention or compute burn.
The agent era still needs its numbers
Baidu's DAA proposal is not a finished standard. It is a well-timed provocation. AI product value is shifting from "how long did a person stay in the product" toward "what work did AI finish on that person's behalf." If that becomes the dominant product shape, DAU, MAU, token volume, and API calls will not be enough to explain growth.
The risk is that DAA becomes another vanity metric. Counting agents is easy. Counting useful, approved, cost-efficient, recoverable, and properly permissioned agent work is harder. That hard version is the one builders should care about.
For developers and AI product teams, the deeper lesson is that building agents is becoming a measurement problem as much as a model-integration problem. The question is not simply how many agents were switched on today. It is what authority they had, what cost they consumed, what result they left behind, and whether a human could trust the chain of work. Baidu's DAA is interesting because it shows that the operating language for agent platforms is still being invented.